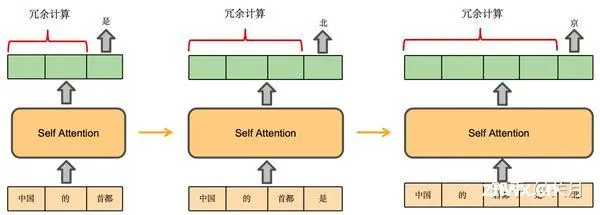
大模型推理加速的目标是高吞吐量、低延迟。吞吐量为一个系统可以并行处理的任务量。延时,指一个系统串行处理一个任务时所花费的时间。调研了一些大模型推理的框架。_大模型推理框架加速...

根据OpenAI联合创始人AndrejKarpathy在微软Build2023大会上公开的信息,OpenAI使用的大语言模型构建流程如图1所示,主要包含四个阶段:预训练、有监督微调、奖励建模和强化学...

假设我们企业的私有知识存储在链接对应的文档中,我们希望大模型能根据这个文档的内容,回答“LUA的宿主语言是什么?”这个问题。_ollama根据文档回答...
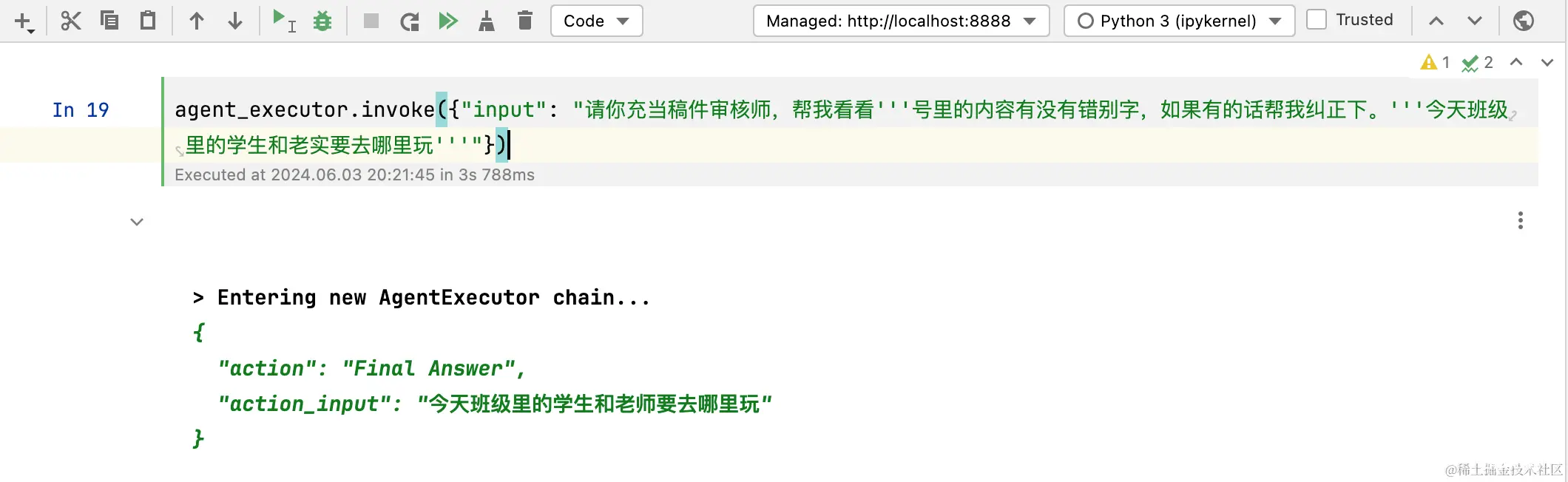
在各个大厂纷纷卷LLM的情况下,各自都借助自己的LLM推出了自己的AIAgent,比如字节的Coze,百度的千帆等,还有开源的Dify。_reactai...

使用方法:将hfd.sh拷贝过去,然后参考下面的参考命令,下载数据集或者模型。欢迎大家关注笔者,你的关注是我持续更博的最大动力。或克隆此存储库,然后授予脚本执行权限。这个代码不能保持目录结构,见下面的改进版。获取hug...
如果不在意耗电的情况下(个人跑满的话,功率大概在250W-300W之间),选取退役服务器还是性价比非常高的。其他方面比如CPU,内存,硬盘位置方面,个人觉得应该不存在太大的限制空间,但GPU的可扩展要尤其注意。比如我...
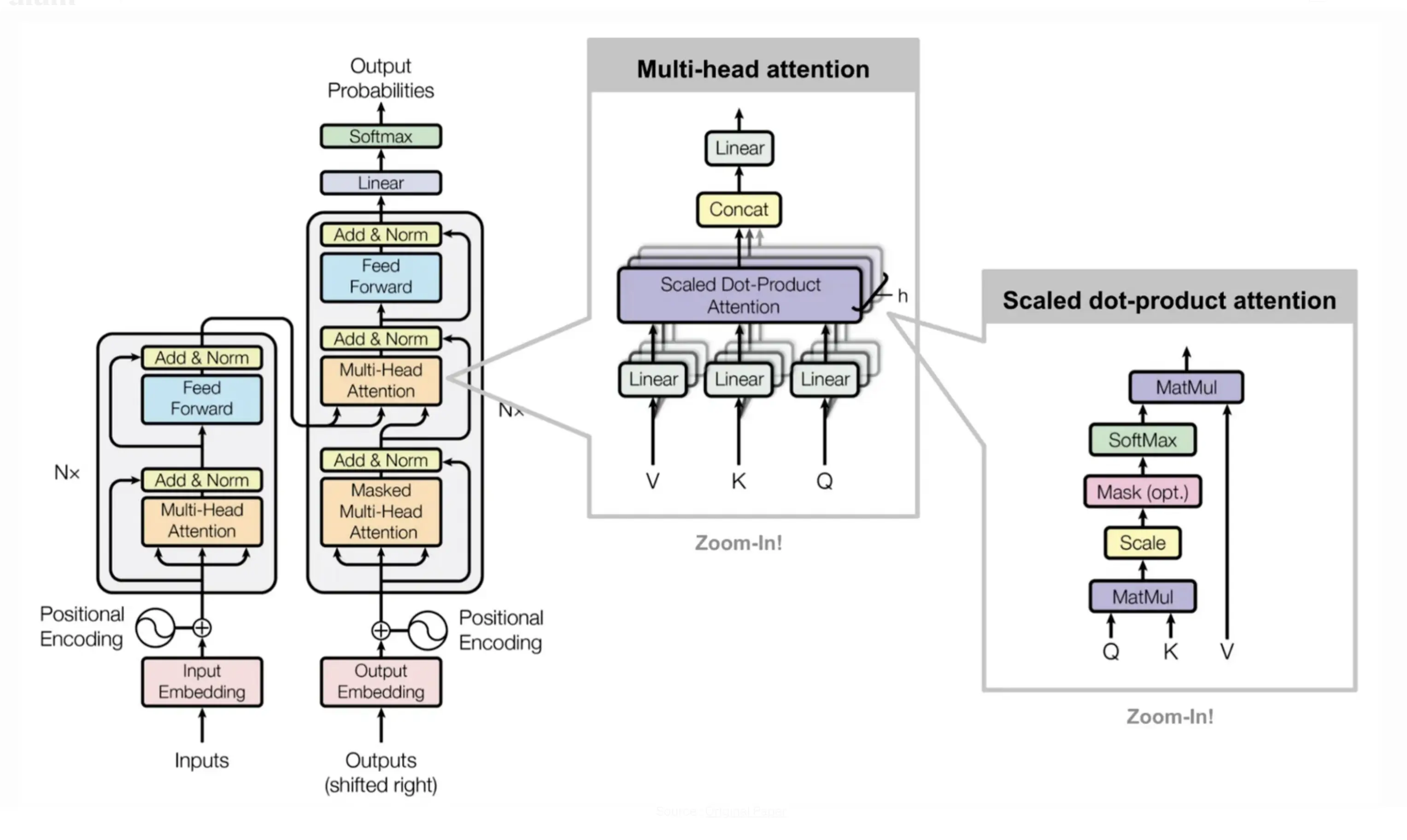
随着人工智能在自然语言处理(NLP)领域的快速发展,对大规模预训练模型的需求日益增长。这些大型模型不仅需要具备广泛的语言理解能力,还需要能适应各种下游任务需求。传统上,针对特定任务训练的较小模型往往无法达到所需的...
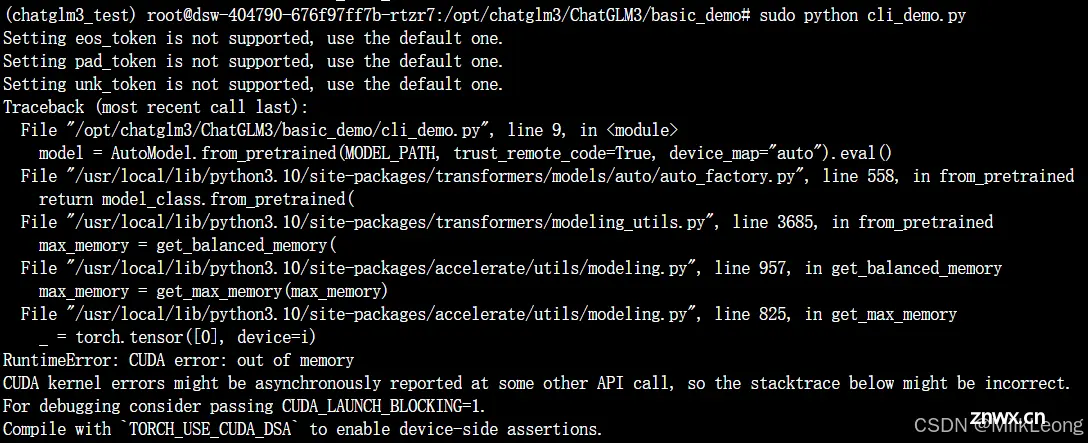
想学习怎么部署大模型,跟着部署了一个星期,然而没有成功。失败的经历也是经历,记在这里。我一共创建了3个实例来部署chatglm3,每个实例都是基于V100创建的(当时没有A10可选了),其显存只有16G。每个实例分...
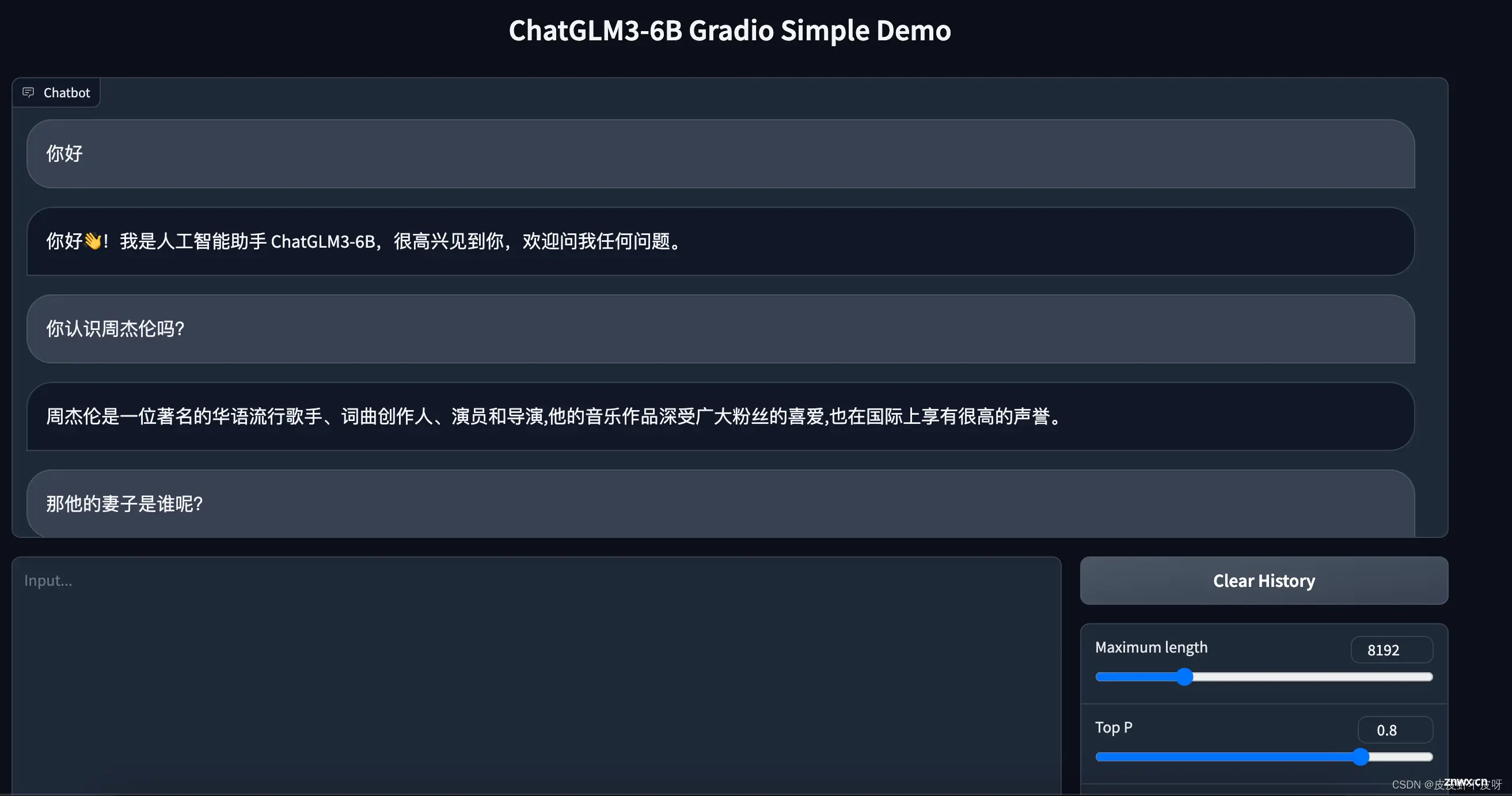
云服务器部署chatglm3阿里云人工智能平台PAI_阿里paicuda...
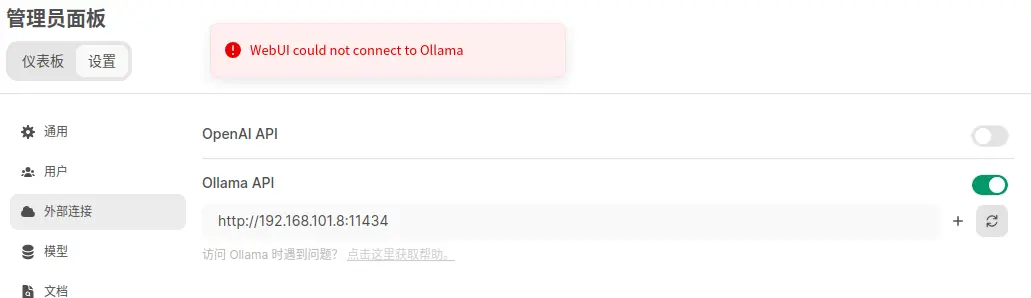
随着人工智能技术的飞速发展,AI已经不再是遥不可及的高科技概念,而是逐渐融入到我们的日常生活中。从智能手机的语音助手到家庭中的智能音箱,再到工业自动化和医疗诊断,AI的应用无处不在。然而,要想真正掌握并应用这些技术...