
WebSocket和Socket.io为前端实时通信提供了强大的支持。通过本文的学习,你应当对这两种技术有了全面的理解,并掌握了其实现细节和实际应用。在未来的开发中,无论是构建实时聊天系统还是其他需要实时数据...
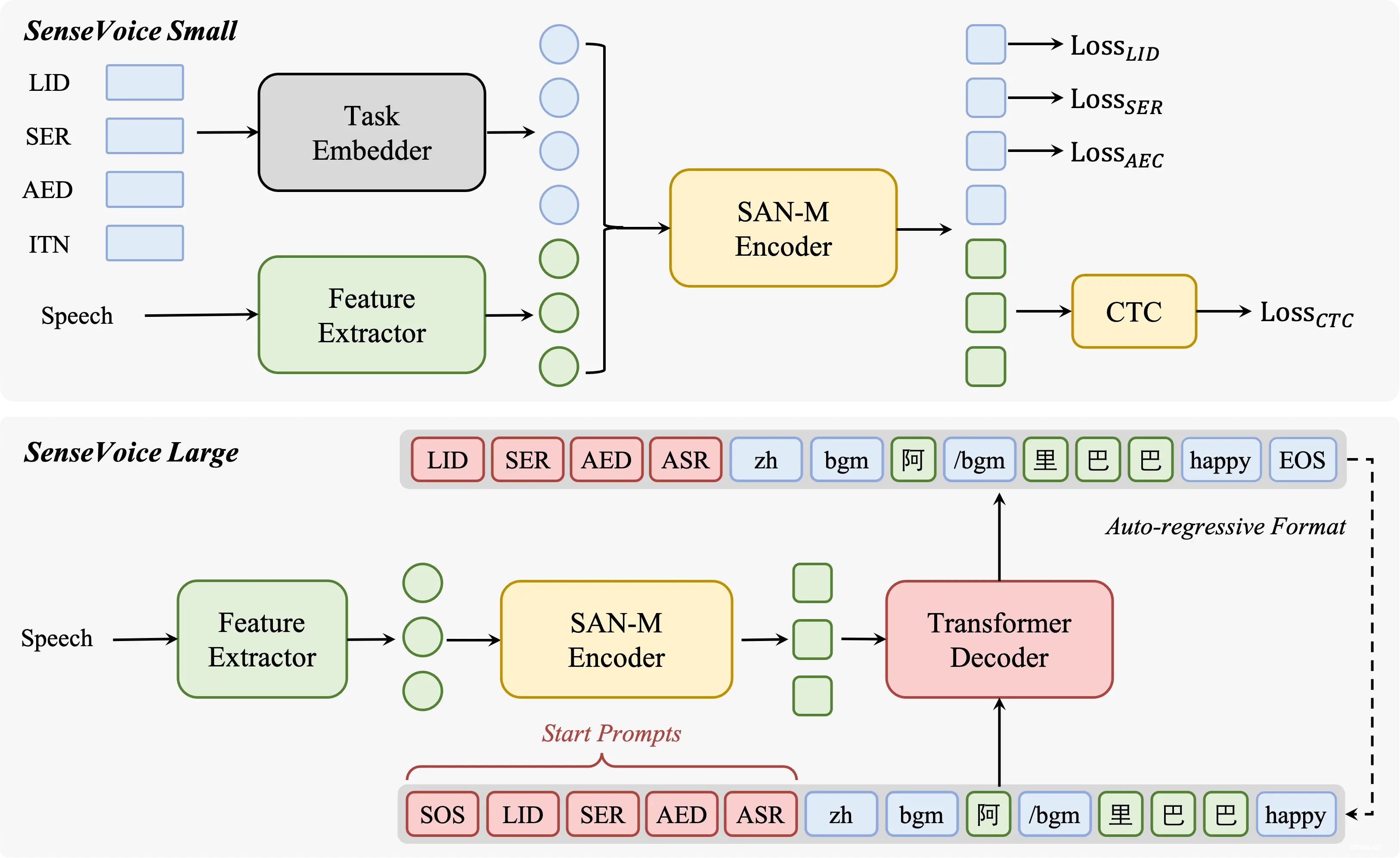
深入了解FunAudioLLM,阿里巴巴通义实验室开源的先进语音技术项目。SenseVoice和CosyVoice两大模型,以其高精度多语言语音识别、情感辨识和自然语音生成能力,引领语音交互的新时代。本文详细解析...
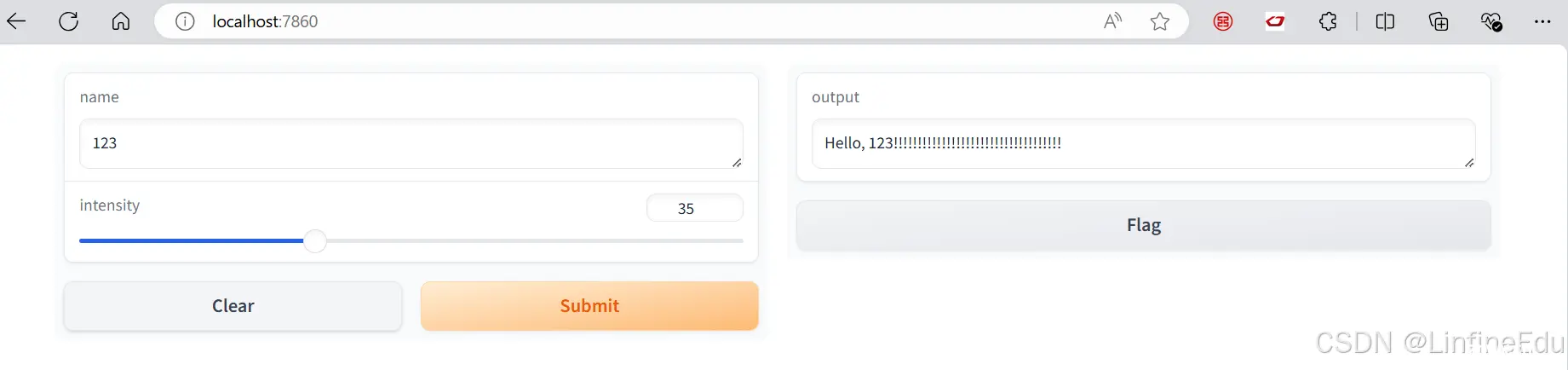
Gradio是一个开源Python包,允许您为机器学习模型、API或任何任意Python函数快速构建演示或Web应用程序。然后,您可以使用Gradio的内置共享功能在几秒钟内共享指向演示或W...

除了这位博主的修改方法(此方法对我无效),个人的修改方法如下问题可能是使用MicrosoftVisualStudio的cl编译器尝试编译代码,但遇到了找不到errno.h的问题。安装GCC9.5.0运行...

vit的使用,读者可以自己修改超参数用到自己的数据集上面_transformer调用cifar-10...

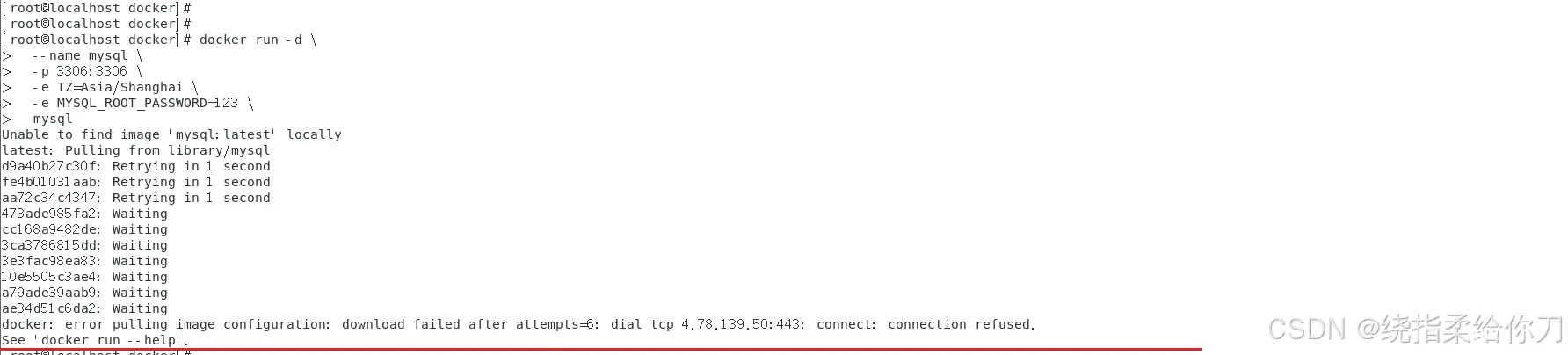
【代码】docker拉取镜像失败docker:errorpullingimageconfiguration:downloadfailedafterattempts=6:dialtcp。_69...
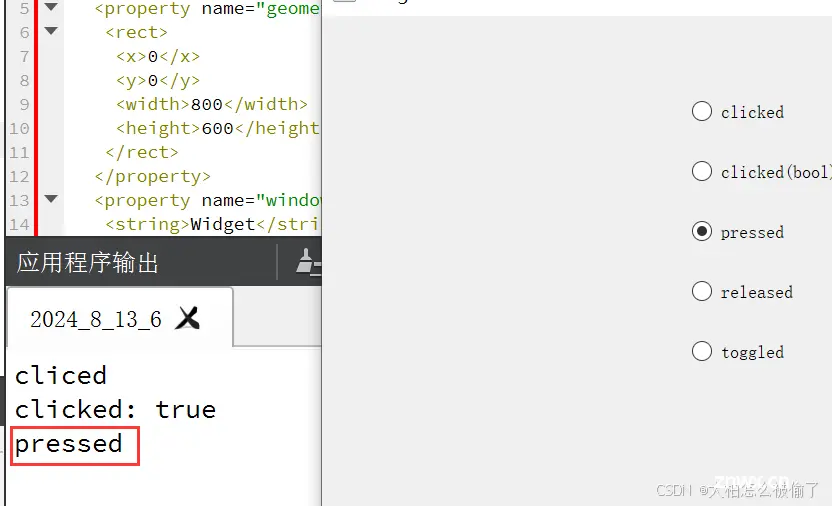
QRadioButton是单选按钮,可以在多个选项中选择一个。_qtqradiobuttoncheckable...

LoRA作为一种创新的微调技术,通过低秩矩阵分解方法,实现了对大型生成模型的高效微调。在StableDiffusion模型中,LoRA技术被广泛应用于角色、风格、概念、服装和物体等不同分类的图像生成中。通过结...
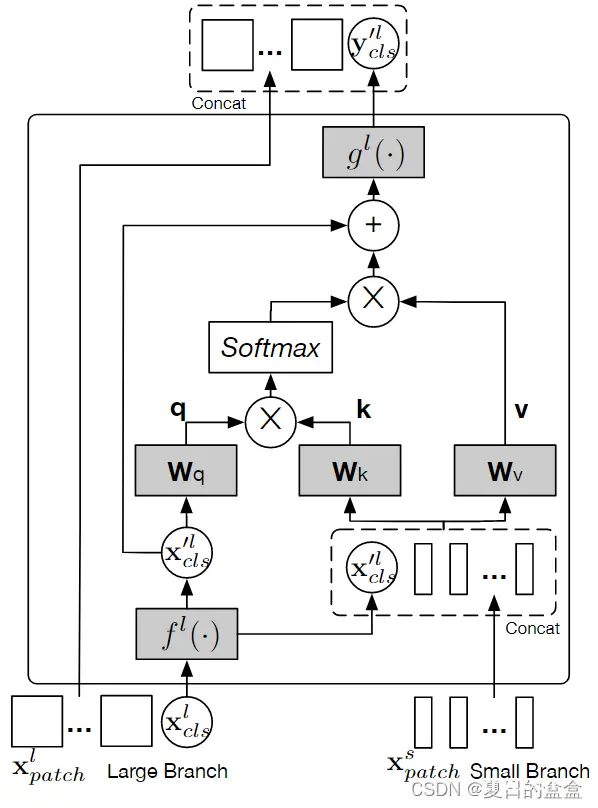
本文提出一个双分支transformer,来组合不同尺寸的图像块(即transformer中的token),以产生更强的图像特征。该方法处理具有不同计算复杂度的两个独立分支的小块和大块token,然后纯粹通过注意力多次...