FunAudioLLM:阿里通义实验室的开源语音大模型项目 - SenseVoice与CosyVoice模型介绍
MeoAI 2024-09-01 17:31:01 阅读 67
FunAudioLLM是由阿里通义实验室发布的开源语音大模型项目,它包含两个模型:SenseVoice和CosyVoice。
一、模型功能特色
SenseVoice
高精度多语言语音识别:支持超过50种语言,尤其在中文和粤语上识别效果显著。情感辨识:能够识别多种情绪和交互事件,如音乐、掌声、笑声、哭声等。音频事件检测:能够检测咳嗽、喷嚏等常见音频事件。模型版本:提供轻量级和大型基础语音模型,适应不同应用场景。
CosyVoice
自然语音生成:能够生成自然流畅、逼真的语音。多语言支持:支持中文、英文、日语、粤语和韩语。音色和情感控制:通过少量原始音频生成模拟音色,包括韵律和情感细节。细粒度控制:支持以富文本或自然语言精细控制生成语音的情感和韵律

二、CosyVoice技术原理
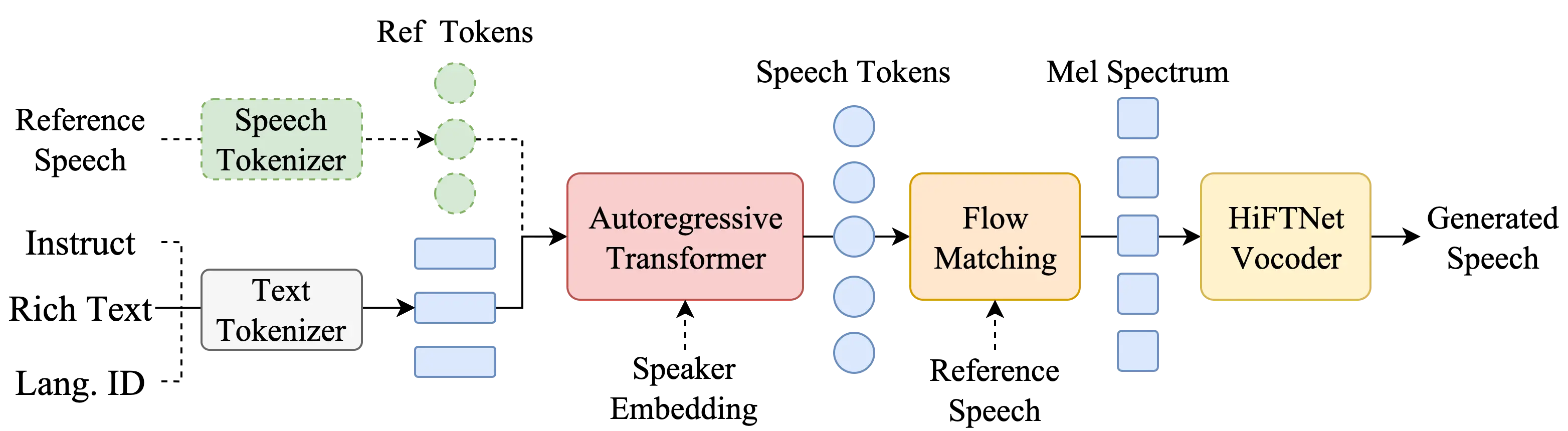
1. 语音生成模型
CosyVoice使用自回归变换器生成输入文本的相应语音标记。CosyVoice能够生成具有逼真韵律和音色的语音。这种技术通常涉及到大量的参数和复杂的网络结构,以学习和模拟人类语音的复杂性。
2. 语音量化编码
CosyVoice模型采用语音量化编码技术,将连续的语音信号转换为离散的编码表示。在这个过程中,原始的模拟语音信号被转换成一系列可以代表该语音的数字值。这些离散的编码能够捕捉到语音中的关键特征,例如音高、音量、音色等。量化编码是语音信号处理的第一步,它为后续的处理和分析提供了基础。
3. 流匹配(Flow Matching)
流匹配(Flow Matching)是一种在语音合成中使用的优化技术,特别是在基于深度学习的文本到语音(TTS)系统中。它通常用于调整和优化生成的声学特征,如Mel频谱,以确保它们更自然、流畅,并且更准确地反映原始语音信号的特性。作为Mel频谱重建过程中的一个环节,确保了生成的Mel频谱在动态范围和频域特性上更接近自然语音,为最终的语音合成提供了高质量的输入。
4. 基于ODE的扩散模型
Mel频谱重建:从生成的语音标记中重建Mel频谱,使用基于ODE的扩散模型和流匹配技术,Mel频谱是一种表示语音信号的频域表示,它将声音的频率内容映射到人类听觉感知的Mel尺度上。
5.HiFTNet基础的声码器
使用HiFTNet(High-Fidelity Transformer Network)基础的声码器从Mel频谱合成最终的语音波形。它使用深度学习中的变换器(Transformer)架构来生成高度逼真的语音。在CosyVoice中,声码器接收来自前一阶段的Mel频谱作为输入,然后生成连续的语音波形。
6. 多语言和情感控制
CosyVoice支持多语言的语音生成,并通过细粒度控制技术,能够根据文本内容或用户指令调整生成语音的情感和韵律。这包括但不限于高兴、悲伤、生气等情感状态的模拟。
7. 情感和韵律的细粒度控制
CosyVoice模型能够根据文本中的情感标签或指令,调整语音输出的情感色彩和韵律特征。这种控制能力是通过在模型训练过程中引入情感标注数据实现的。
8. 定制化语音:通过微调技术,使CosyVoice能够模仿特定说话人的声音特征
9. 声音混合:在两个或多个说话人之间进行声音特征的插值,创造出中间的声音效果
三、SenseVoice技术原理
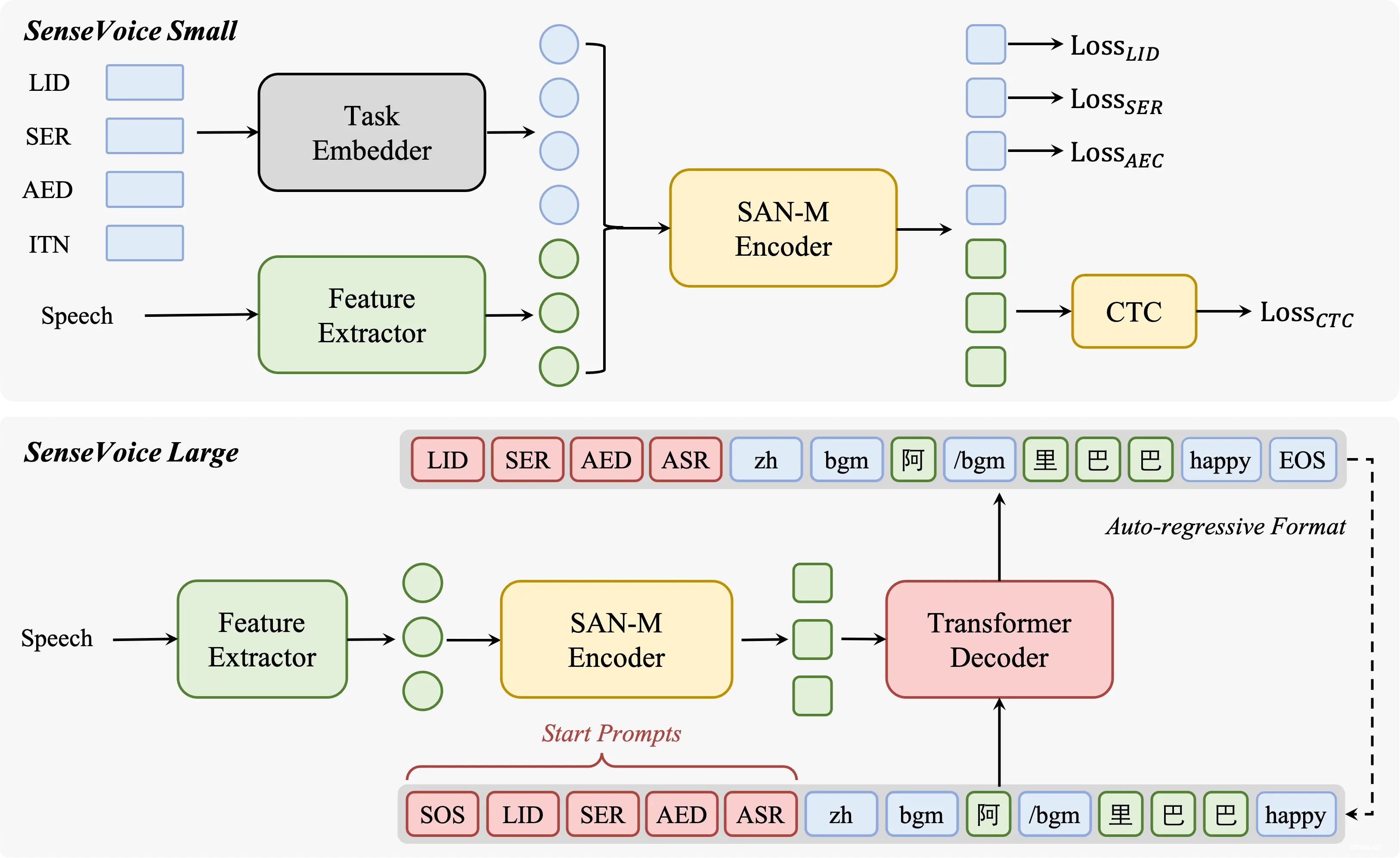
1. 自动语音识别(ASR)
SenseVoice模型具备自动语音识别能力,能够将输入的语音信号转换为文本信息。这通常涉及到声学模型和语言模型的联合训练,以提高识别的准确性。
2. 语言识别(LID)
模型能够识别并区分不同的语言,这是通过训练数据中包含多种语言的语音样本实现的。语言识别功能有助于在多语言环境下确定语音输入的语言类型。
3. 情感识别(SER)
SenseVoice能够识别语音中的情感状态,这通常涉及到对语音信号的音调、节奏、强度等特征的分析。情感识别可以用于提升人机交互的自然性和响应性。
4. 音频事件检测(AED)
模型还能够检测语音中的特定音频事件,如音乐、掌声、笑声等。这通常需要模型能够区分语音信号中的非语言声音,并识别其类型和发生的时序。
5. 端到端架构
SenseVoice-Small模型采用非自回归端到端架构,这种设计减少了模型在推理过程中的延迟,使得模型能够快速响应实时语音输入。
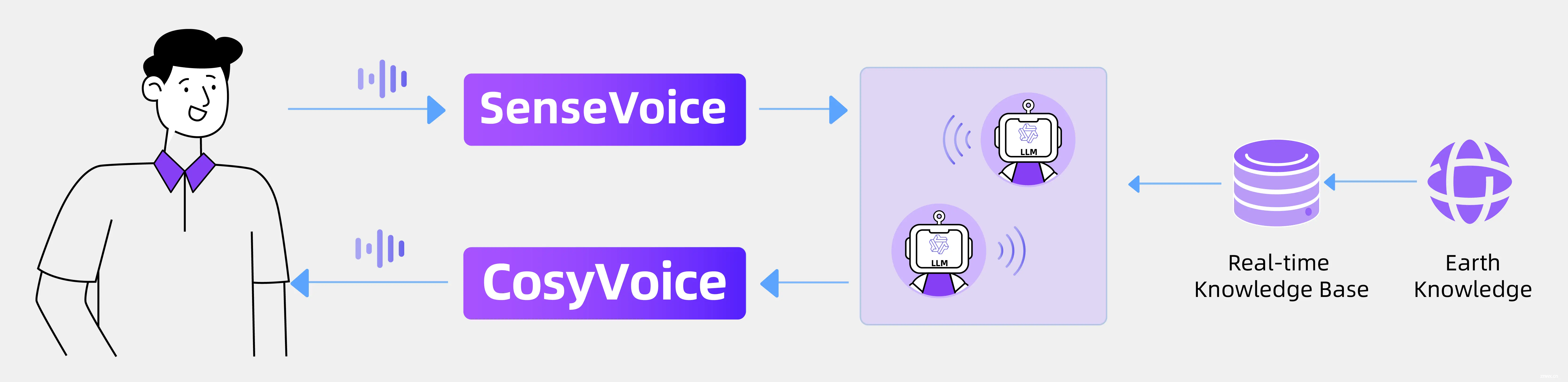
四、模型训练与微调
1. 训练数据
FunAudioLLM的模型训练依赖于大量的标注数据,包括语音、文本、情感标签等。这些数据用于训练模型识别语音特征和生成自然语音。
2. 微调(Fine-tuning)
在特定应用场景下,可以通过微调技术对预训练模型进行调整,以适应特定的语言、口音或情感表达。微调通常涉及到在特定数据集上的额外训练。
3. 社区贡献
FunAudioLLM项目鼓励社区成员贡献数据、模型改进和应用案例,以促进模型的持续优化和创新应用的开发。
五、模型评估
1. 客观指标
通过在标准数据集上评估模型的语音识别准确率、情感识别准确率和音频事件检测准确率等客观指标,来衡量模型性能。
2. 主观听辨测试
除了客观指标外,还通过主观听辨测试来评估语音的自然度、情感表达的准确性和用户满意度。
六、模型部署与应用
1. 本地部署
用户可以根据自己的需求,在本地环境中部署FunAudioLLM模型,进行语音处理和生成任务。
2. 云服务
FunAudioLLM也可以部署在云平台上,提供API服务,方便开发者和企业用户快速集成和使用。
3. 应用开发
开发者可以基于FunAudioLLM模型开发各种应用,如智能助手、语言翻译器、有声内容创作工具等。
通过深入理解FunAudioLLM的技术原理,开发者和研究者可以更好地利用这一工具,开发出更加智能和人性化的语音交互应用。

原文链接:FunAudioLLM:阿里通义实验室的开源语音大模型项目 - SenseVoice与CosyVoice模型介绍

https://www.meoai.net/funaudiollm-sensevoice-cosyvoice.html
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。