阿里开源语音理解和语音生成大模型FunAudioLLM
CSDN 2024-08-21 12:31:02 阅读 80
近年来,人工智能(AI)的进步极大地改变了人类与机器的互动方式,例如GPT-4o和Gemin-1.5等。这种转变在语音处理领域尤为明显,其中高精度的语音识别、情绪识别和语音生成等能力为更直观、更类人的交互铺平了道路。阿里开源大模型FunAudioLLM,一个创新的框架,旨在促进人类与大型语言模型(LLMs)之间的自然语音交互。FunAudioLLM的核心是两个开创性的模型:用于语音理解的SenseVoice和用于语音生成的CosyVoice。
1 FunAudioLLM 模型
FunAudioLLM 模型家族包含两个核心模型:SenseVoice 和 CosyVoice,分别负责语音理解和语音生成。
链接:https://github.com/FunAudioLLM
1.1 SenseVoice:语音理解模型
SenseVoice 是一个功能强大的语音理解模型,支持多种语音处理任务:
自动语音识别 (ASR): 将语音转换为文本。语言识别 (LID): 识别语音所属的语言。语音情绪识别 (SER): 识别说话人的情绪。音频事件检测 (AED): 识别语音中的特定事件,例如音乐、掌声、笑声等。
1.1.1 SenseVoice 模型特点
多语言支持:SenseVoice 支持多种语言的语音识别,包括 SenseVoice-Small 支持的 5 种语言和 SenseVoice-Large 支持的 50 多种语言。低延迟:SenseVoice-Small 具有极低的推理延迟,比 Whisper-small 快 5 倍以上,比 Whisper-large 快 15 倍以上,适用于实时语音交互应用。高精度:SenseVoice-Large 支持超过 50 种语言的语音识别,并具有高精度识别能力,适用于需要高精度识别的应用。丰富的语音理解功能:SenseVoice 还可以进行情绪识别和音频事件检测,为更复杂的语音交互应用提供支持。
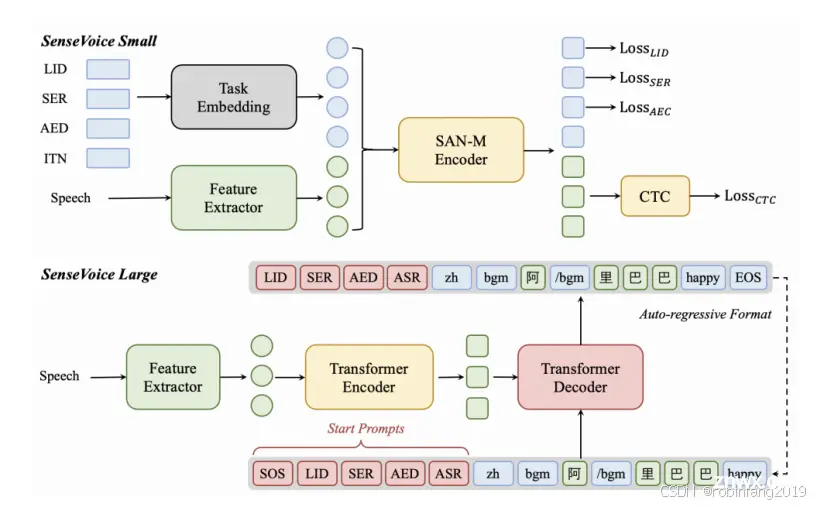
1.1.2 SenseVoice 模型架构
SenseVoice 包含两个版本,分别针对不同的需求:
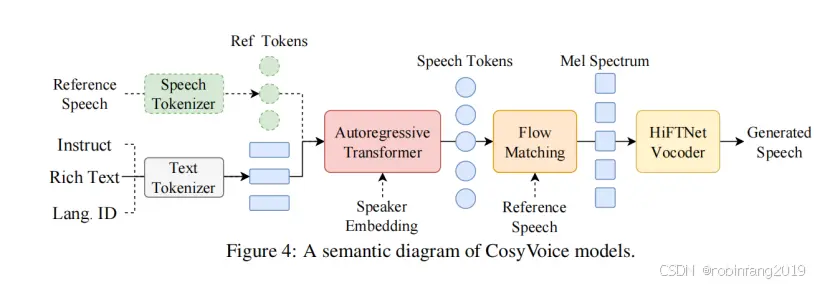
1.2.2 CosyVoice 模型架构
SenseVoice-Small:非自回归编码器模型,采用内存增强的自注意力网络 (SAN-M) 架构,具有快速推理的能力。SenseVoice-Large:自回归编码器-解码器模型,采用 Transformer 架构,具有高精度识别的能力。
1.2 CosyVoice:语音生成模型
CosyVoice 是一个功能强大的语音生成模型,可以生成自然流畅的语音,并可以控制多种语言、音色、说话风格和说话人身份。
1.2.1 CosyVoice 模型特点
多语言语音生成:可以生成中文、英文、日语、粤语和韩语等多种语言的语音。零样本学习:可以通过少量参考语音进行语音克隆,例如 3 秒的参考语音。跨语言语音克隆:可以将语音克隆到不同的语言中。情感语音生成:可以生成情感丰富的语音,例如快乐、悲伤、愤怒等。指令遵循:可以通过指令文本控制语音输出的各个方面,例如说话人身份、说话风格和副语言特征。CosyVoice 包含三个版本,分别针对不同的需求:
CosyVoice-base-300M:专注于准确表达说话人身份、零样本学习和跨语言语音克隆。 CosyVoice-instruct-300M:专注于生成情感丰富的语音,并可以通过指令文本进行精细控制,例如说话人身份、说话风格和副语言特征。 CosyVoice-sft-300M:在 7 位多语言说话人上进行微调,可直接部署。
2 数据集
2.1 SenseVoice 训练数据
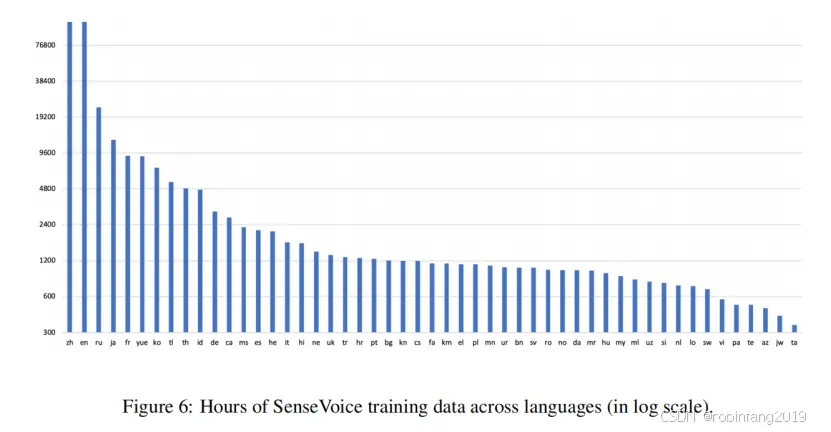
SenseVoice-Small 模型使用了大约 30 万小时的语音数据,涵盖了中文、粤语、英文、日语和韩语 5 种语言。SenseVoice-Large 模型在 SenseVoice-Small 的基础上,又增加了 10 万小时的多样化多语言数据,以增强其多语言能力。
为了获得丰富的语音识别标签,SenseVoice 模型使用了开源的音频事件检测 (AED) 和语音情绪识别 (SER) 模型来生成伪标签,从而构建了一个包含大量丰富语音识别标签的数据集。其中,AED 数据集包含 1.5 亿条记录,SER 数据集包含 3000 万条记录。
2.2 CosyVoice 训练数据
CosyVoice 模型使用了包含多种语言的语音数据集,用于训练语音生成模型。在数据收集过程中,使用了专门的工具进行语音检测、信噪比 (SNR) 估计、说话人分割和分离等操作。然后,使用 SenseVoice-Large 和 Paraformer 模型生成伪文本标签,并通过强制对齐 (FA) 模型进行优化,以提高标签的准确性和消除低质量数据。
CosyVoice-instruct 模型使用了指令训练数据,对 CosyVoice-base 模型进行微调,以增强其指令遵循能力。指令训练数据分为三种类型:说话人身份、说话风格和副语言特征,分别用于控制语音输出的各个方面。
3 实验结果
FunAudioLLM 的实验结果表明,SenseVoice 和 CosyVoice 模型在语音理解和语音生成任务上取得了优异的性能。
3.1多语言语音识别
我们使用字符错误率(CER)来评估模型在五种语言上的表现:中文、粤语、日语、韩语和泰语,以及使用词错误率(WER)来评估所有其他语言。
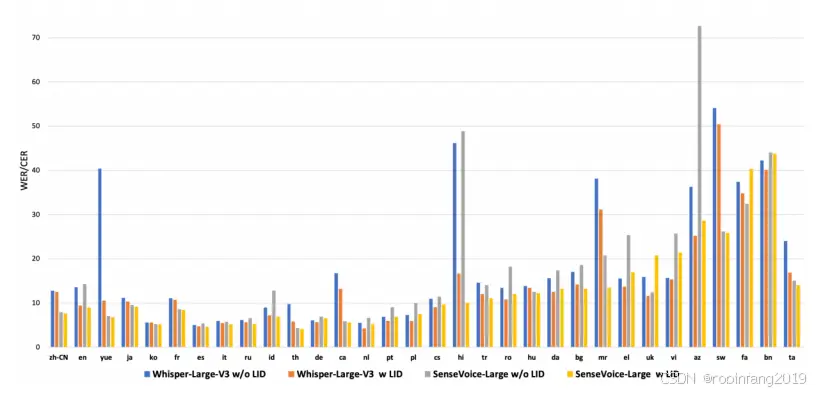
识别准确率:SenseVoice-S 和 SenseVoice-L 在大多数测试集上均优于 Whisper 对应模型,尤其是在 Cantonese 和其他低资源语言上表现更佳。识别效率:SenseVoice-S 采用非自回归架构,具有极低的推理延迟,比 Whisper-small 快 5 倍以上,比 Whisper-L-V3 快 15 倍以上。
3.2 语音情绪识别
我们在7个流行的情绪识别数据集上评估了SenseVoice的SER能力,包括CREMA-D、MELD、IEMOCAP、MSP-Podcast、CASIA、MER2023和ESD。这些语料库涵盖了中文和英文,以及表演、电视剧和日常对话等场景。我们报告了未加权平均准确率(UA)、加权平均准确率(WA)、宏观F1得分(F1)和加权平均F1(WF1)。
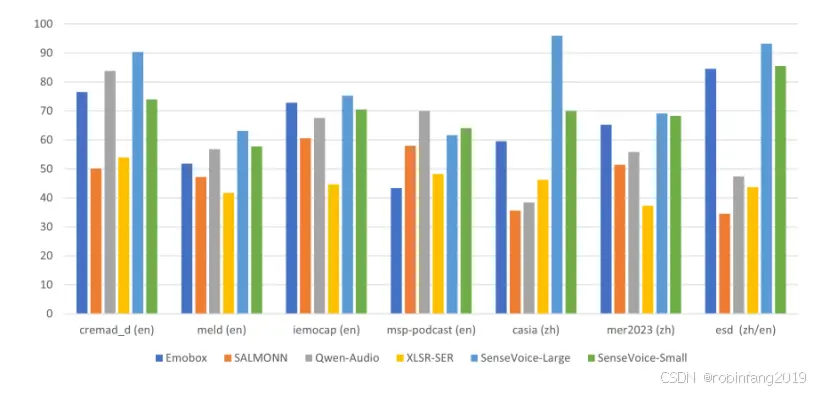
识别准确率:SenseVoice 在 7 个流行的情绪识别数据集上均取得了良好的性能,无需针对目标领域进行微调即可获得高准确率。与其他模型的比较:SenseVoice-Large 在几乎所有数据集上都取得了最佳结果,SenseVoice-Small 也优于其他基线模型。
3.3 音频事件检测
SenseVoice-Small和SenseVoice-Large模型都能够对语音中的音频事件进行分类,包括音乐、掌声和笑声。SenseVoice-L可以进一步预测音频事件的开始和结束位置,而SenseVoice-Small只能预测音频中发生了什么,每个话语最多一个事件。SenseVoice-Small可以检测更多种类的事件,例如咳嗽、打喷嚏、呼吸和哭泣,这些事件可能发生在人机交互中。
我们在不同的任务中将SenseVoice与最先进的音频事件检测模型BEATs和PANNs进行比较,包括环境声音分类(ESC50)、婴儿哭泣/笑声检测、咳嗽检测(Coswara)和家庭脱口秀事件检测。
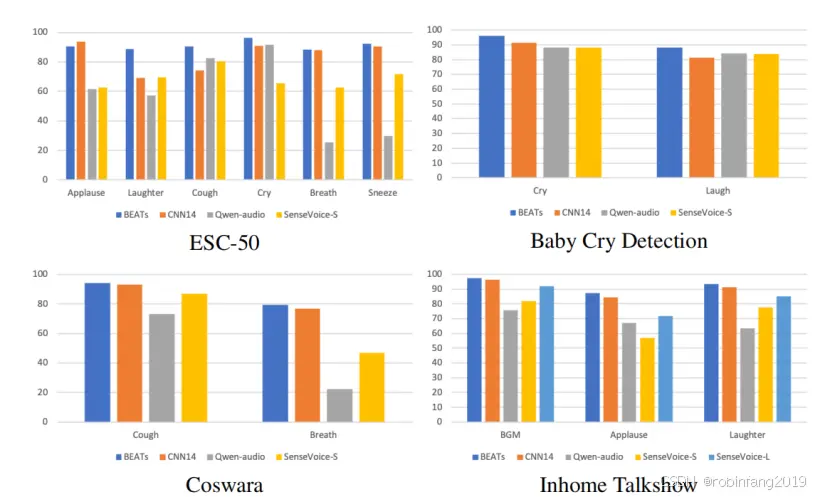
识别准确率:SenseVoice-S 和 SenseVoice-L 能够识别语音中的音频事件,例如音乐、掌声和笑声。SenseVoice-L 还能够预测音频事件的起始和结束位置。与其他模型的比较:SenseVoice 在音频事件分类或检测方面表现出色,尽管其他模型可能具有更好的 F1 分数。
3.4 S3 Tokenizer 保留语义信息
为了评估S3分词器保留语义信息的能力,我们比较了增强量化器的SenseVoice-L与其原始版本和Whisper-Large V3模型的识别性能。这些模型使用Common Voice zh-CN和en基准进行了评估。

识别准确率:S3 Tokenizer 在中英文测试集上均表现出稳健的识别性能,其中在 common voice zh-CN 集上,S3 Tokenizer 的错误率比 Whisper-Large V3 模型降低了 4.14%。
3.5 CosyVoice 语音生成质量
我们通过检查内容一致性和说话者相似性来评估CosyVoice语音合成的质量。分别使用LibriTTS的“test-clean”子集和AISHELL-3的测试集来构建英语和中文的评估集。对于这些集中的每段文本,我们随机选择一段提示语音。使用Whisper-Large V3评估英语的内容一致性,使用Paraformer评估中文。通过计算生成语音和提示语音的说话者嵌入之间的余弦相似性来量化说话者相似性,这些嵌入是使用ERes2Net提取的。
内容一致性:CosyVoice 生成的语音与原始语音在内容上高度一致,与 ChatTTS 相比,WER 更低,插入和删除错误更少。说话人相似度:CosyVoice 生成的语音与原始语音的说话人相似度很高,表明其具有有效的语音克隆能力。
3.6 CosyVoice 情绪可控性
情绪控制准确率:CosyVoice-instruct 在情感指令下表现出更高的情绪控制准确率,优于 CosyVoice-base 和 CosyVoice-instruct 无情感指令的情况。
3.7 CosyVoice 作为数据生成器
数据质量:CosyVoice 生成的语音数据质量很高,可以作为其他任务(例如语音识别和语音翻译)的训练数据,从而提高模型性能。
4 应用与限制
4.1 应用
FunAudioLLM 的 SenseVoice、CosyVoice 和 LLMs 的集成,可以实现多种应用,例如:
语音翻译:将输入语音翻译成目标语言,并使用目标语言生成语音。
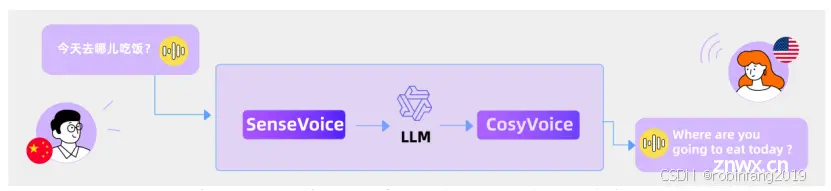
情感语音聊天:识别输入语音的情绪和音频事件,并生成与情绪相符的语音。
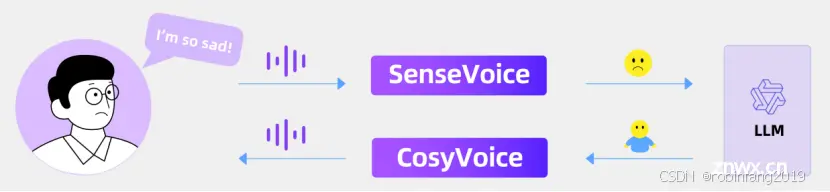
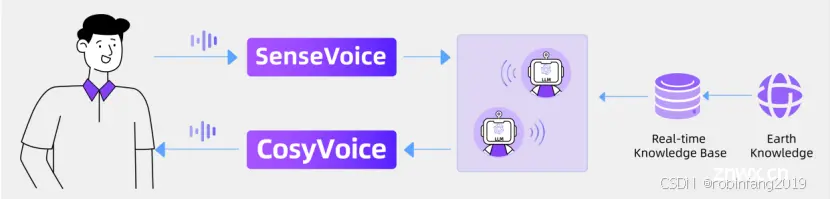
交互式播客:根据实时世界知识和内容生成播客脚本,并使用 CosyVoice 合成语音。
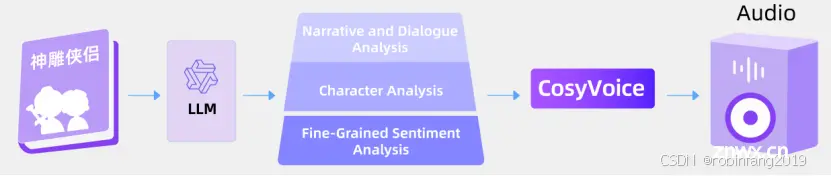
有声读物:分析文本中的情感和角色,并使用 CosyVoice 合成具有丰富情感的有声读物。
4.2 限制
FunAudioLLM 的 SenseVoice 和 CosyVoice 模型也存在着一些限制,例如:
低资源语言:SenseVoice 在低资源语言上的语音识别准确率较低。流式识别:SenseVoice 不支持流式语音识别。语言支持:CosyVoice 支持的语言数量有限。情感和风格推断:CosyVoice 需要明确的指令才能生成特定情绪和风格的语音。唱歌:CosyVoice 在唱歌方面表现不佳。端到端训练:FunAudioLLM 的模型不是与 LLMs 端到端训练的,这可能会引入误差传播。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。