CosyVoice - 阿里最新开源语音克隆、文本转语音项目 支持情感控制及粤语 本地一键整合包下载
昨日之日2006 2024-08-25 10:01:01 阅读 94
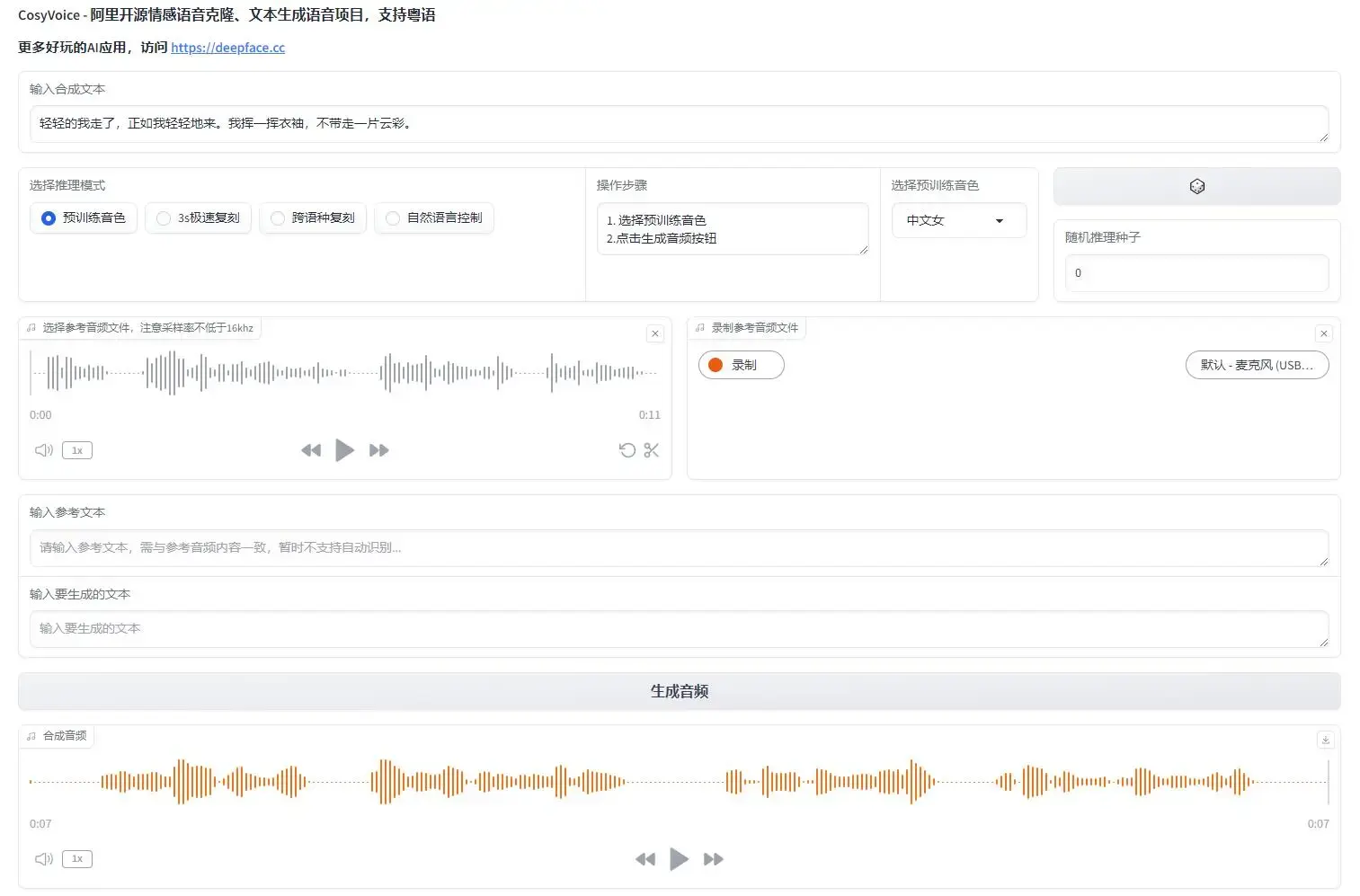
近日,阿里通义实验室发布开源语音大模型项目FunAudioLLM,而且一次包含两个模型:SenseVoice和CosyVoice。
CosyVoice专注自然语音生成,支持多语言、音色和情感控制,支持中英日粤韩5种语言的生成,效果显著优于传统语音生成模型。
仅需要3~10s的原始音频,CosyVoice即可生成模拟音色,甚至包括韵律、情感等细节,包括跨语种语音生成。
而且CosyVoice支持以富文本或自然语言的形式,对生成语音的情感、韵律进行细粒度的控制,生音频在情感表现力上得到明显提升。
研究团队提供了基模型CosyVoice-300M、经过SFT微调后的模型CosyVoice-300M-SFT、以及支持细粒度控制的模型CosyVoice-300M-Instruct,可满足不同场景下的使用需求。CosyVoice-300M本身具备一定从文本内容中推断情感的能力,经过细粒度控制训练的模型CosyVoice-300M-Instruct在情感分类中的得分更高,具备更强的情感控制能力。
CosyVoice很好地建模了合成文本中的语义信息,达到了与人类发音人相当的水平。此外,通过对合成音频进行重打分,能够进一步降低识别的错误率,甚至在内容一致性和说话人相似度上超越人类。
项目地址:https://github.com/FunAudioLLM/CosyVoice
在线体验:https://www.modelscope.cn/studios/iic/SenseVoice
一键包下载:CosyVoice - 阿里最新开源语音克隆、文本转语音项目 支持情感控制及粤语 本地一键整合包下载
之前在线体验过,效果和之前爆火的ChatTTS有一比,因为官方原版只支持linux系统,所以一键包一直没做。今日国内大佬v3ucn基于原版改良的版本,支持win系统了。不仅支持各种情感生成,还支持3秒钟语音样本极速克隆,测试几轮,效果还是非常榜的。
应用场景
陪伴场景:利用复刻的家人声音提供个性化陪伴,用于智能助手和车载导航语音,以及家庭娱乐项目,如为家人朗读绘本、控制家用电器或提供教育辅导。
教育场景:使用复刻老师的声音,加强师生互动,丰富教学视频和课件的内容,打造更亲切、更生动的学习体验。
音视频产业:通过复刻主播的声音,方便后期补录、配音等应用场景,提高音视频的制作效率。
智能客服:借助复刻的客户经理声音,提供语音服务,包括但不限于客户回访和市场营销电话,以赋予服务更加个性化、人性化的特点。
产品优势
低样本音频要求:仅需短短10~20秒的录音便能完成声音复刻,显著降低了录制成本,提升了效率。
高度拟真:利用阿里通义语音实验室自研的CosyVoice生成式神经网络语音大模型算法,结合前沿的零样本学习技术,能够在语调、韵律以及情感表达上高度还原真人声音,很难与真实录音相辨。
即时合成:秒级还原真实音色,提供高效、实时的声音复刻服务。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。