EchoMimic - 一张照片生成说话视频,可用于AI数字人生成,阿里最新开源 本地一键整合包下载
昨日之日2006 2024-07-31 12:31:01 阅读 61
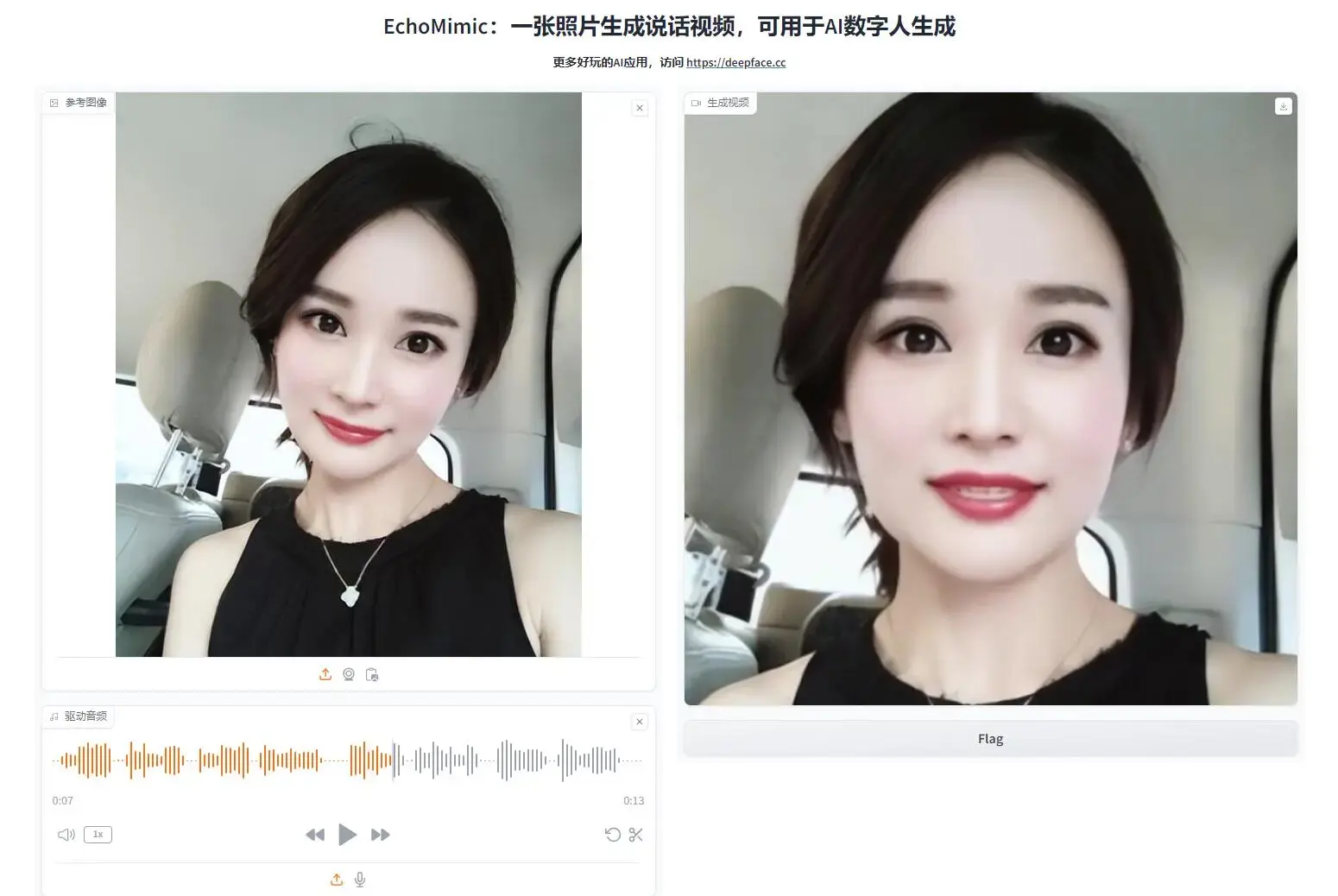
EchoMimic是阿里巴巴达摩院推出的一个AI驱动的口型同步技术项目。这项技术能够通过给定的音频和一张或多张人物的面部照片,生成一个看起来像是在说话的视频,其中的人物口型动作与音频中的语音完美匹配。这种技术在娱乐、教育、虚拟现实、在线会议等领域有广泛的应用前景,可以用于创建更加真实和互动的视频内容。
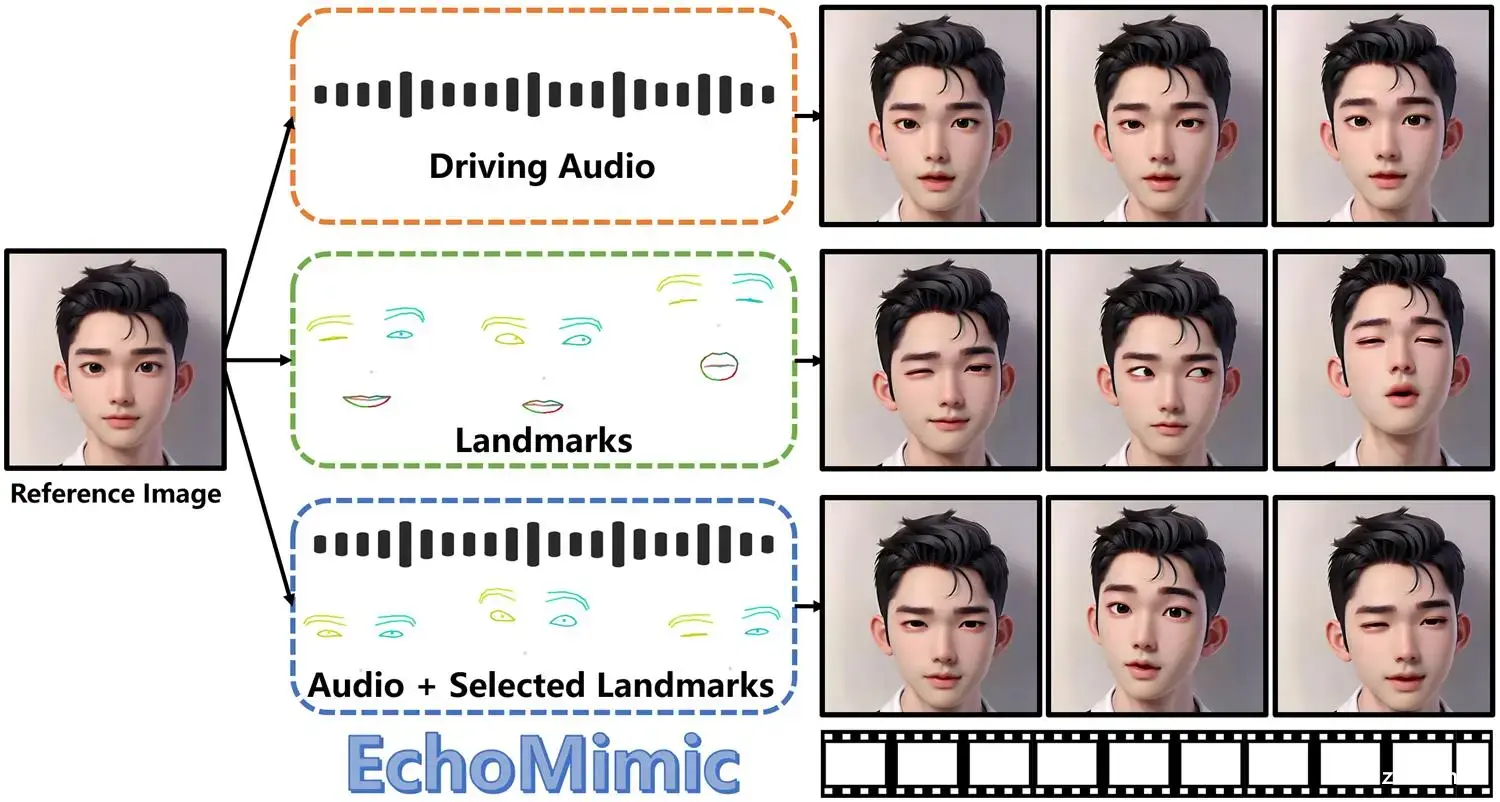
与快手的 LivePortrait 不同, EchoMimic不仅能通过参考表情生成视频,还能够通过音频匹配对应口型,还支持将两者混用,即通过音频控制口型,通过 landmarks 来控制姿势和表情。
想象一下,你的声音和面部动作,能被完美复制到视频中,就像照镜子一样自然。
以往,我们生成视频动画要么依赖音频信号,要么依赖面部标志点,但这两种方法都有各自的局限性。音频驱动的方法容易不稳定,而面部关键点驱动的又缺乏自然感。EchoMimic横空出世,一举解决了这两个问题。它能够结合音频和面部标志点,让生成的视频既稳定又自然。

EchoMimic的稳定性和自然度是它的两大杀手锏。通过融合音频和面部标志点的特征,它生成的面部动画更加符合真实的面部运动和表情变化。无论是微小的嘴角上扬,还是眼神的微妙流转,EchoMimic都能精准捕捉,让动画效果如真人般逼真。
面部标志点,听起来很高大上,其实它们就是面部图像上的一些特定点,用来表示面部的关键特征和结构。这些点通常位于眼睛、鼻子、嘴巴等关键部位,帮助计算机视觉算法更好地理解和分析面部表情和动作。

EchoMimic的功能强大到令人惊叹。它可以单独使用音频或面部标志点生成肖像视频,也可以将两者结合,创造出更加逼真的动画。更厉害的是,它还支持多语言和多风格,无论是普通话、英语还是歌唱,EchoMimic都能轻松应对。
EchoMimic的应用前景无限广阔。无论是面部识别、表情识别,还是面部动画、增强现实,甚至是医学成像,EchoMimic都能大展身手。它的出现,无疑将为这些领域带来革命性的变革。
总而言之,EchoMimic这项技术不仅仅是一项创新,它更是一次对传统视频生成技术的颠覆。随着技术的不断进步和完善,我们有理由相信,未来EchoMimic将在更多领域大放异彩,为我们带来更加丰富和逼真的视觉体验。
项目地址:https://github.com/BadToBest/EchoMimic
本地一键整合包:EchoMimic - 一张照片生成说话视频,可用于AI数字人生成,阿里最新开源 本地一键整合包下载
注:只支持N卡,建议显存8-10G起使用
使用教程:
1、下载一键包,解压出来,双击“一键启动”等待自动跳转到WebUI界面
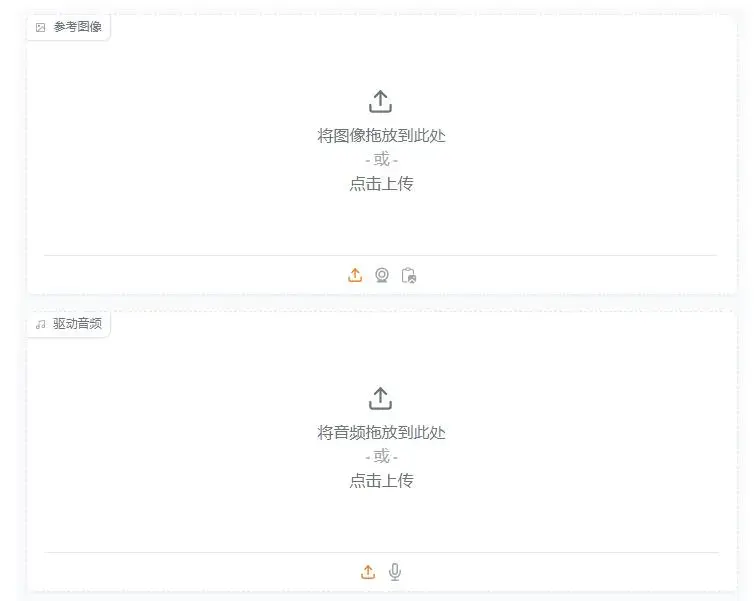
2、上传一张用于生成视频的“参考图”和驱动图片说话的“驱动音频”,如下图
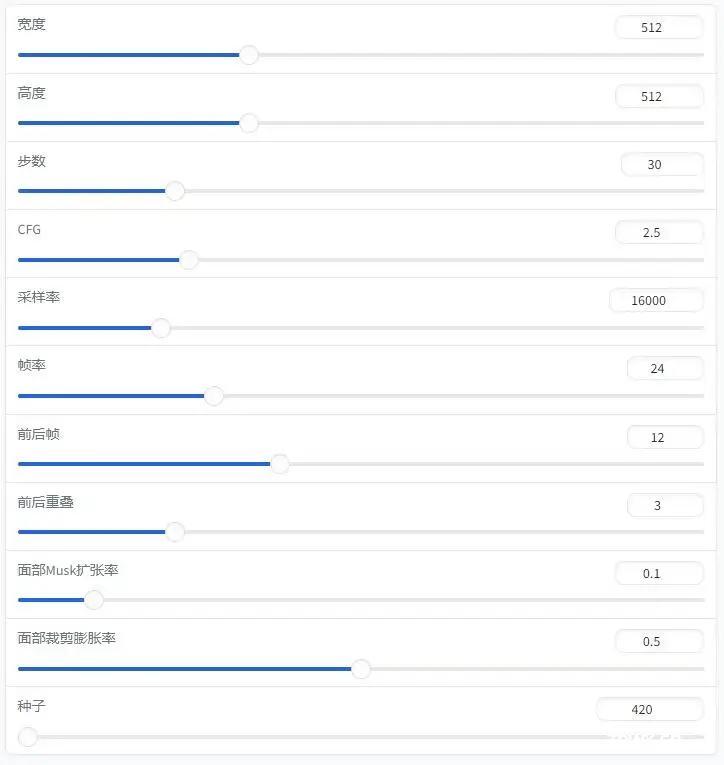
3、高级参数可以默认,也可以自由调节,比如生成视频的宽度、高度,以及视频帧率、步数等参数,如下图
4、所有参数设置完成后,点击下方的“Submit”提交即可。
5、等待生成完成后,在“生成的视频”可以预览生成后的效果,也可以点击下方的“Flag”按钮,将生成的视频和参数保存到本地,保存路径为软件目录下的“flagged”目录。
这个生成速度比较慢,但是效果还是很棒的,感觉这个项目很有前景。测试一段10秒左右的视频生成512x512大概用时10分钟左右,显卡不好的,可以调低参数,比如视频帧率,步数、宽度和高度等。希望后期的版本能对此做优化。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。