人工智能的语音革命:SenseVoice模型的突破与应用
CSDN 2024-10-21 16:31:03 阅读 93
在人工智能领域,语音识别技术一直是研究的热点之一。随着技术的不断进步,我们见证了从简单的语音转文字到复杂的情感分析和事件检测等高级功能的演进。今天,我们将探讨一个名为SenseVoice的开源项目,它在语音识别和理解方面取得了显著的成就。
引言:语音识别技术的发展历程
语音识别技术自20世纪50年代起步以来,经历了从规则基到统计学习方法的转变,再到现代的深度学习方法。随着大数据和计算能力的提升,语音识别的准确性和应用场景得到了极大的扩展。如今,我们能够通过语音与机器进行更加自然和深入的交互。
SenseVoice模型概述
SenseVoice是一个专注于高精度多语言语音识别、情感辨识和音频事件检测的开源模型。它不仅支持超过50种语言的语音识别,而且在情感识别和音频事件检测方面也展现出卓越的性能。以下是SenseVoice模型的主要特点:
多语言识别能力:通过超过40万小时的数据训练,SenseVoice在多语言识别上超越了现有的Whisper模型。情感识别:在测试数据上,SenseVoice的情感识别效果达到了业界领先水平。音频事件检测:能够检测音乐、掌声、笑声、哭声等多种人机交互事件。高效推理:采用非自回归端到端框架,推理速度极快,10秒音频的推理时间仅为70毫秒。微调定制:提供便捷的微调脚本和策略,帮助用户针对特定业务场景进行优化。服务部署:支持多并发请求,客户端语言包括Python、C++、HTML、Java和C#等。
SenseVoice模型结构
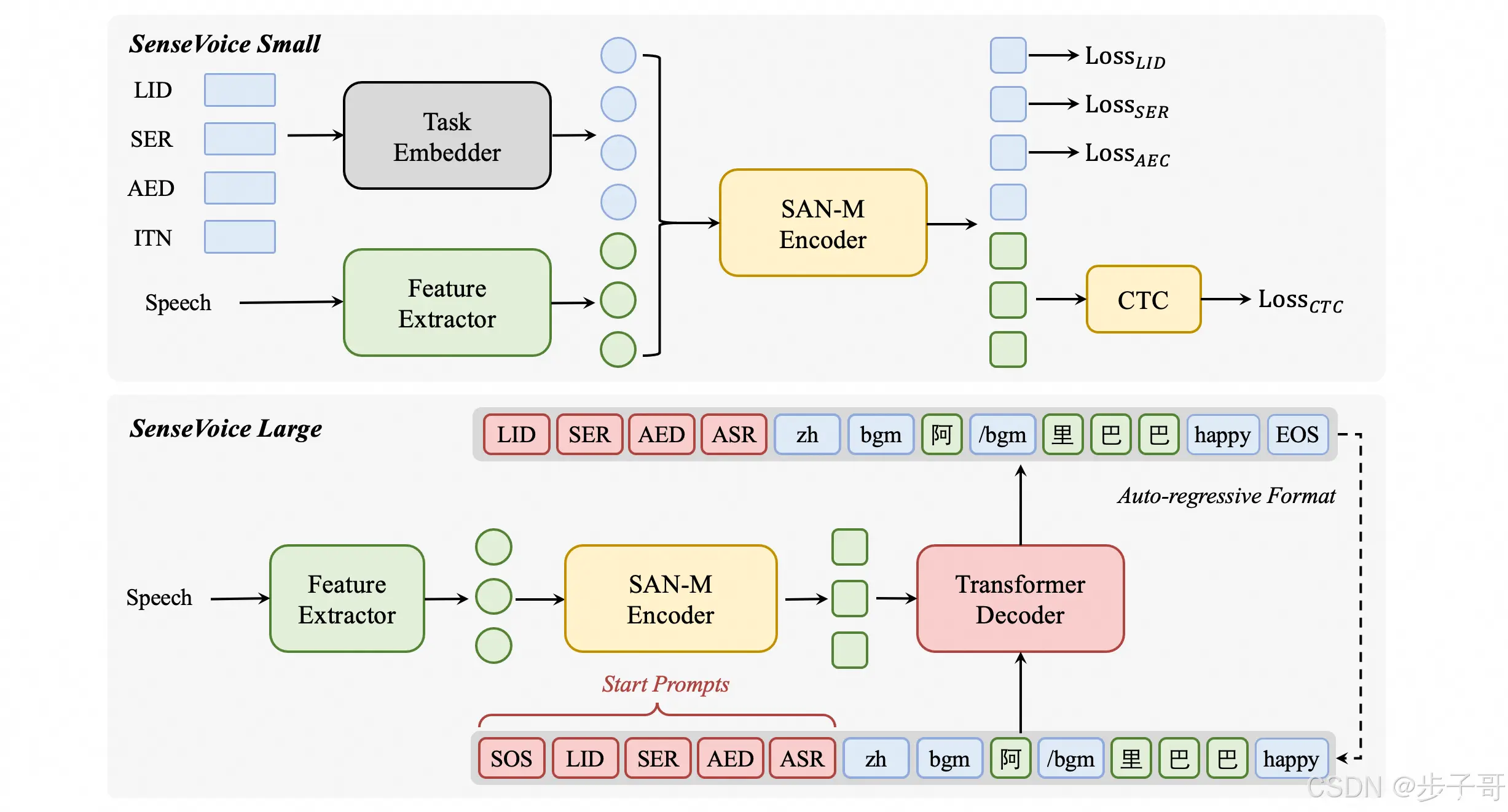
SenseVoice模型的结构设计巧妙,它在语音特征前添加了四个嵌入作为输入传递给编码器,这些嵌入包括:
LID(Language ID):用于预测音频的语种标签。SER(Speech Emotion Recognition):用于预测音频的情感标签。AED(Acoustic Event Detection):用于预测音频中包含的事件标签。ITN(Inverse Text Normalization):用于指定识别输出文本是否进行逆文本正则化。
这种结构设计使得SenseVoice模型能够同时处理多种任务,提高了模型的通用性和灵活性。
模型的推理与部署
SenseVoice模型提供了多种推理方式,包括使用modelscope pipeline进行推理,以及直接使用SenseVoiceSmall模型进行推理。此外,还可以使用funasr库进行推理,该库已经集成了vad(声音活动检测)模型,支持任意时长音频输入。
在服务部署方面,SenseVoice模型具有完整的服务部署链路,支持多并发请求,确保了在实际应用中的高效性和稳定性。
SenseVoice模型的性能测试
在多个开源基准数据集上,SenseVoice模型与Whisper模型进行了比较。结果显示,在中文和粤语识别效果上,SenseVoice-Small模型具有明显的优势。在情感识别方面,SenseVoice模型在不进行目标数据微调的前提下,达到了业界领先水平。在事件检测方面,尽管SenseVoice主要针对语音数据训练,但其在环境音分类任务上也展现出了良好的性能。
推理效率的比较
SenseVoice-Small模型的推理效率是其一大亮点。在与Whisper模型的比较中,SenseVoice-Small在参数量相当的情况下,推理速度比Whisper-Small快7倍,比Whisper-Large快17倍。这种高效的推理能力,使得SenseVoice模型在实时语音识别和交互场景中具有巨大的应用潜力。
结语
随着人工智能技术的不断发展,语音识别和理解技术正变得越来越重要。SenseVoice模型以其高精度的多语言识别能力、情感辨识和音频事件检测功能,以及高效的推理速度,为语音技术的应用开辟了新的可能性。无论是在智能助手、客服机器人还是智能家居等领域,SenseVoice模型都展现出了巨大的应用潜力和价值。
在未来,我们可以预见,随着技术的进一步发展和优化,SenseVoice模型将在更多领域发挥重要作用,为人类社会带来更多便利和创新的交互体验。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。