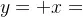
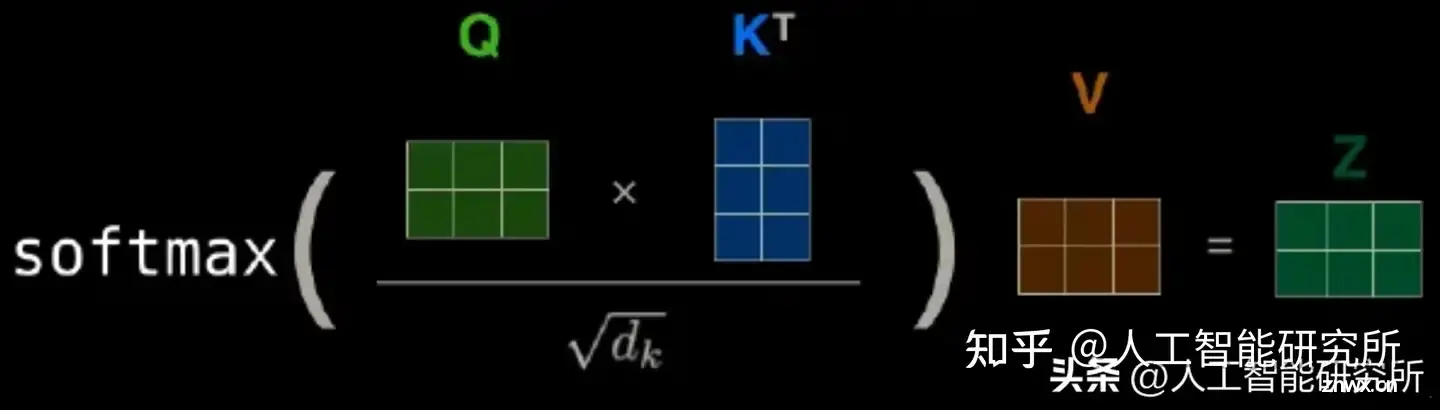
自注意力机制是Transformer模型的核心,它允许模型在编码每个单词时同时关注序列中的其他单词,从而捕捉到单词之间的依赖关系。位置编码的生成使用了正弦和余弦函数的不同频率,以确保编码在不同维度上具有不同的模式...
因模型规模的扩展和需要处理的序列不断变长,transformer逐渐出现计算量激增、计算效率下降等问题,研究者们提出了——,它结合了递归神经网络(RNN)和卷积神经网络(CNN)的特点,以提高处理长序列数据时的计算...

本文对transformers之pipeline的总结(summarization)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行...
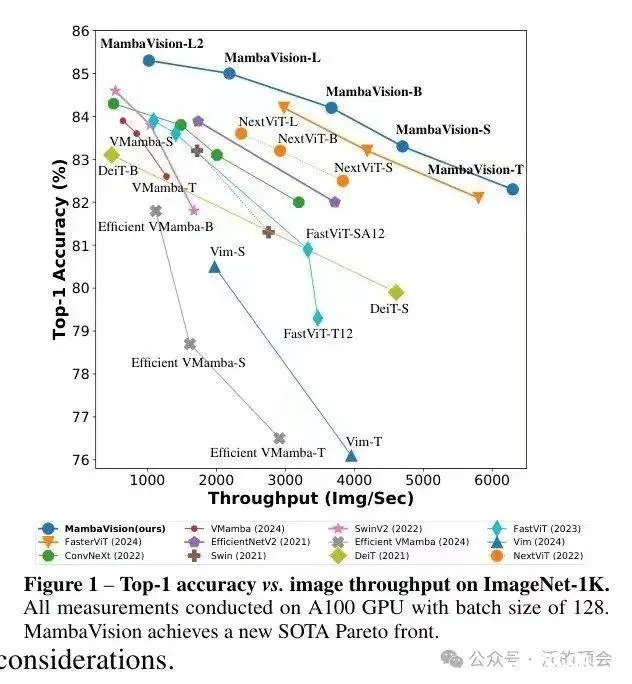
TowardsRobustBlindFaceRestorationwithCodebookLookupTransformer(NeurIPS2022)这篇论文试图解决的是盲目面部恢复(blindfacerestoration)问题,这是...
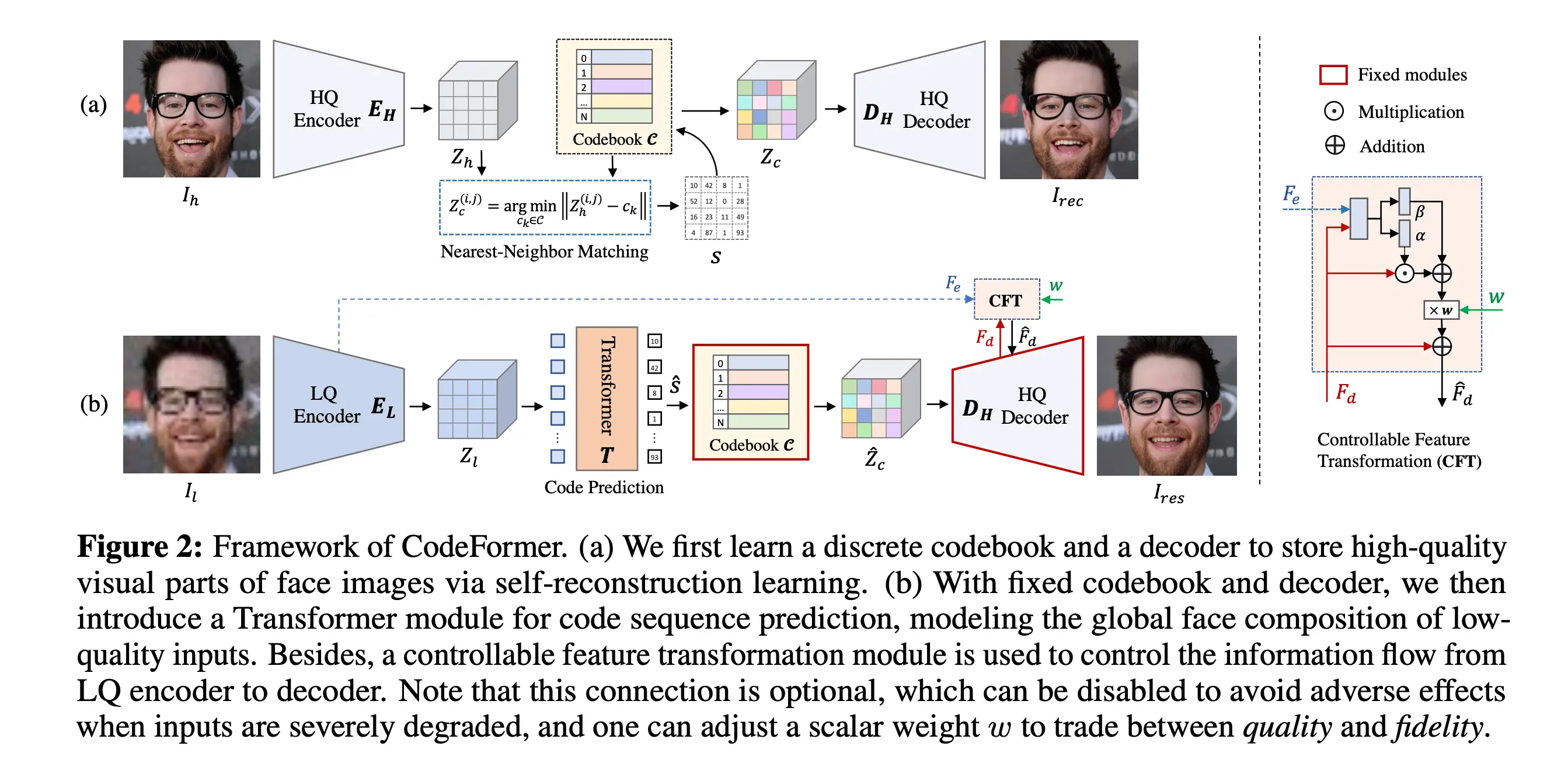
NLP之transformer:transformer-explainer的简介、安装和使用方法、案例应用之详细攻略目录相关论文transformer-explainer的简介transformer-expla...

机器学习(MachineLearning,ML)和人工智能(ArtificialIntelligence,AI)是紧密相关但又有区别的两个概念。(1)AI是一个广泛的领域,旨在实现机器的智能化。(2)机...
Mamba是一种新的状态空间模型架构,在语言建模等信息密集数据上显示出良好的性能,而以前的二次模型在Transformers方面存在不足。Mamba基于结构化状态空间模型的,并使用FlashAttention...
从2017年在《AttentionisAllYouNeed》中首次提出以来,Transformer模型已经成为自然语言处理(NLP)领域的最新技术。在2021年,论文《AnImageisWorth1...

vit的使用,读者可以自己修改超参数用到自己的数据集上面_transformer调用cifar-10...
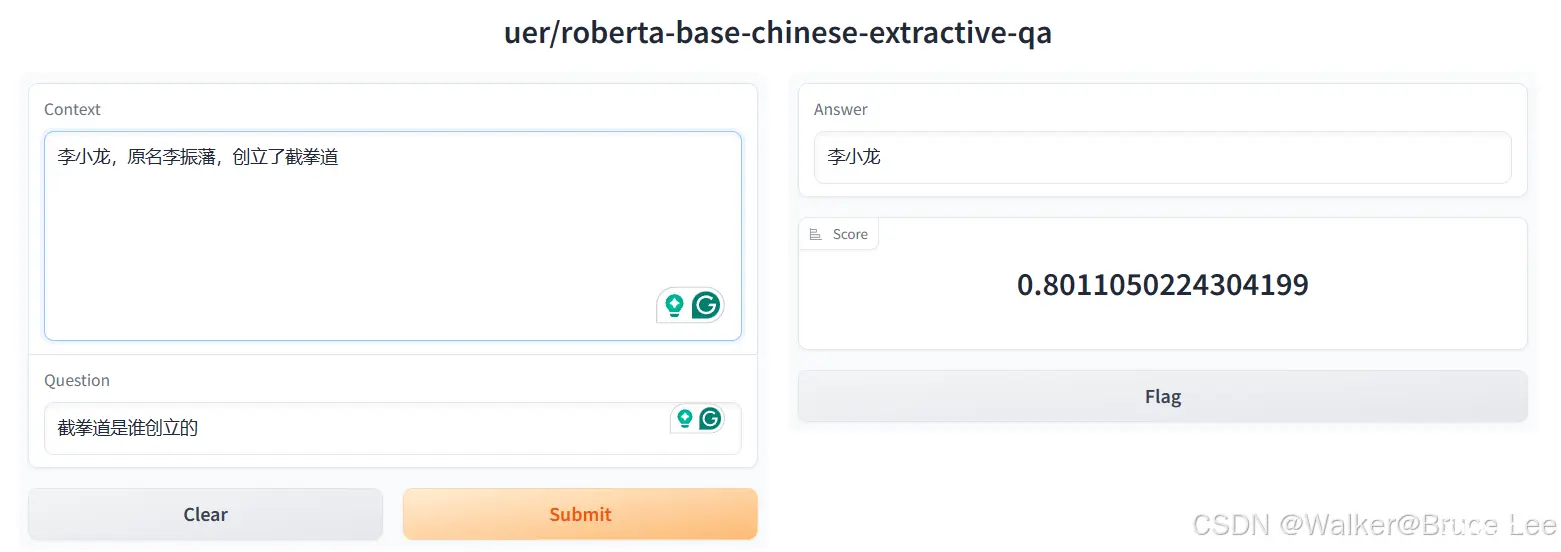
Transformer是大语言模型(LargeLanguageModel,LLM)的基础架构Transformers库是HuggingFace开源的可以完成各种语言、音频、视频、多模态任务情感分析文本生成命名...