
本节对ApacheKudu进行部署,通过DockerCompose配置文件,用于部署ApacheKudu集群。ApacheKudu是一个用于快速分析和实时数据处理的分布式列式存储系统,常与A...

ApacheDruid是一个高效的实时数据存储和分析系统,结合Kafka能实现对实时流数据的摄取与处理。典型的流程是先通过Kafka采集数据,Kafka作为数据源接收生产者发送的实时数据,比如用户行...
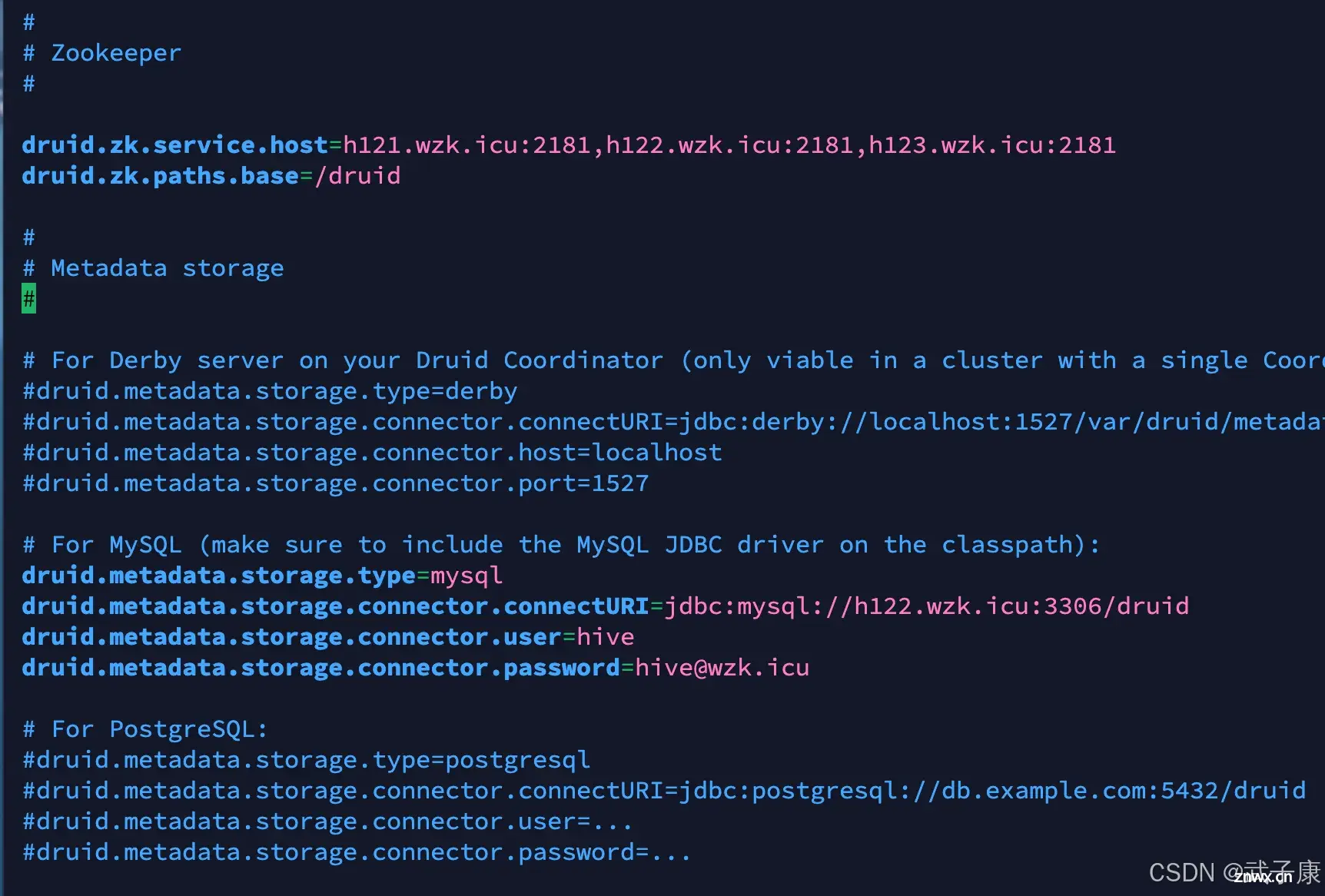
ApacheDruid集群模式配置启动【上篇】超详细!将MySQL驱动链接到:$DRUID_HOME/extensions/mysql-metadata-storage中。上述文件链接到conf/dr...
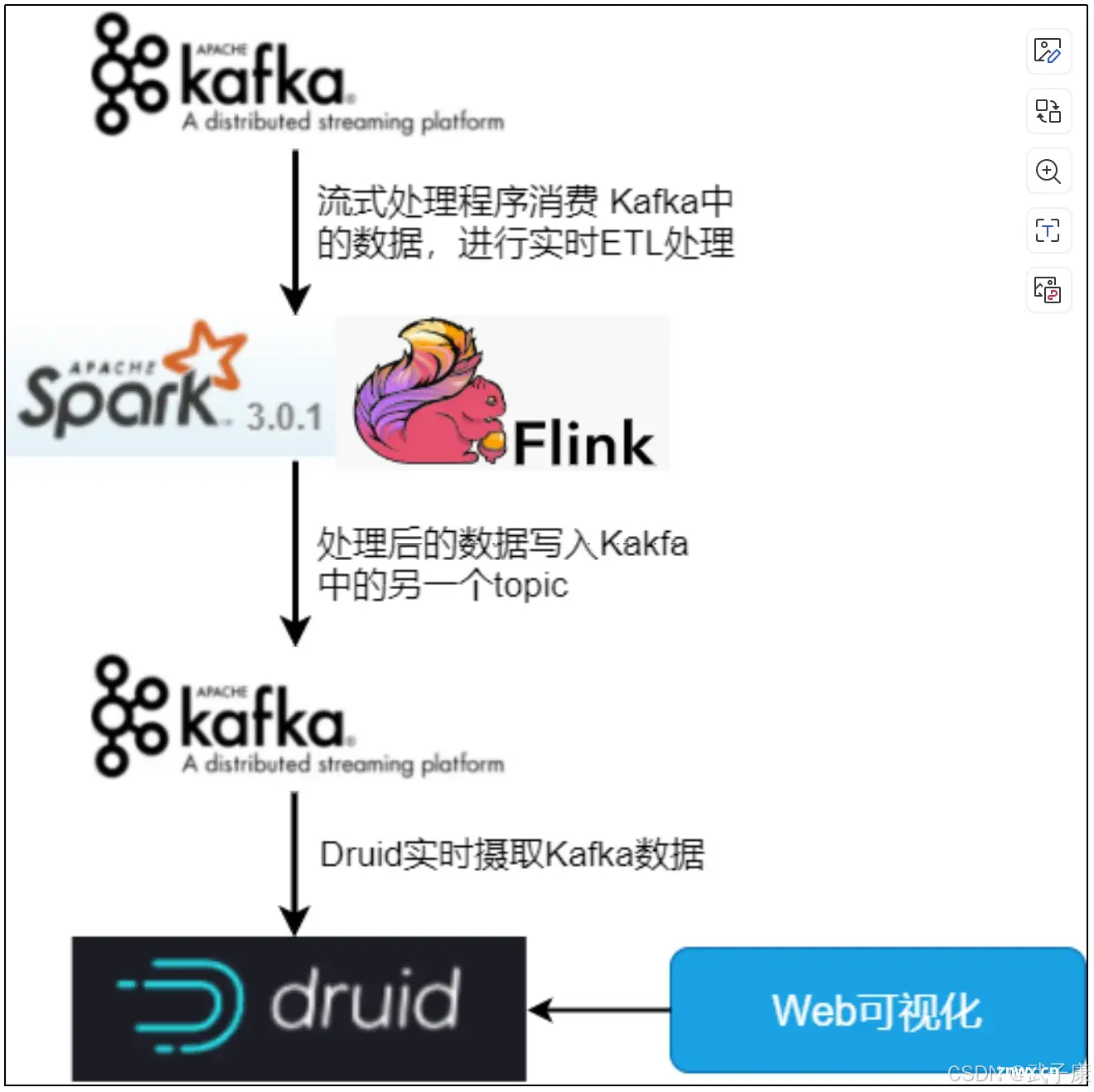
ApacheDruid从Kafka中获取数据并进行分析的流程通常分为以下几个步骤:Kafka数据流的接入:Druid通过KafkaIndexingService直接从Kafka中摄取实时流...

【Python数据采集】国家自然科学基金大数据知识管理服务门户数据采集具体需求:从https://kd.nsfc.cn/网站中根据关键词搜索项目信息,收集列表中展示的信息以及详情页面中的参与人员信息等。在开始干活之前,我们首先要做的是弄清楚需求,然后分析目...
本篇博客深入探讨了C++中的两种重要数据结构——BitSet和BloomFilter。我们首先介绍了它们的基本概念和使用场景,然后详细分析了它们的实现方法,包括高效接口设计和性能优化策略。接着,我们通过...

导出时,由于查询特别耗时,所以点击之后页面会看上去没有反应,通过进度条或者遮罩层的方案来解决问题_easyexcel下载超大文件...
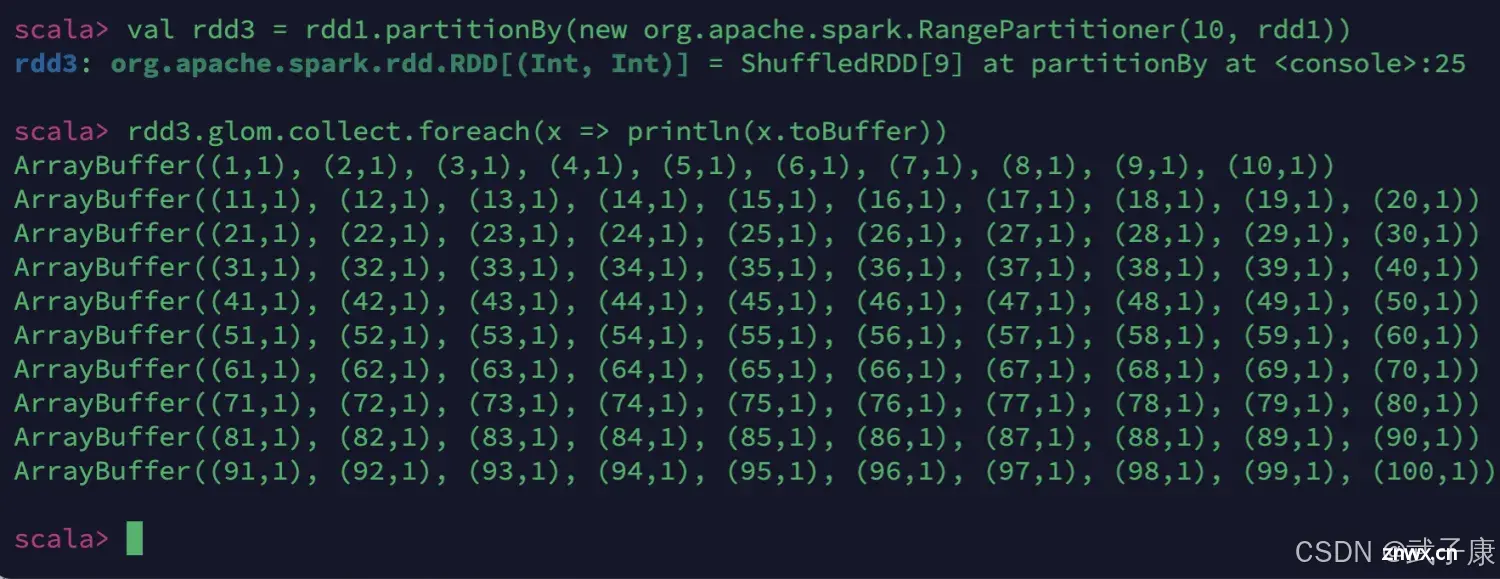
上节研究了Spark的RDD的依赖关系、重回WordCount、RDD持久化、RDD缓存。本节研究Spark的RDD的容错机制、RDD的分区,用Scala实现自定义的分区器。Spark允许用户通过自定义的Par...

本文探讨了DevOps与大数据融合对企业的影响,包括DevOps的优势、大数据的作用、大数据在DevOps中的应用场景、结合方式及成功案例、未来展望和面临的挑战等。文章强调企业应积极应对,充分发挥两者...
摘要在当今数字化时代,网络电视剧作为一种新兴的娱乐形式,受到了广泛的关注和欢迎。随着网络电视剧市场的不断扩大和竞争的加剧,各大卫视平台纷纷推出了大量优质的网络电视剧,努力吸引观众和提升收视率。然而,如何科学准...