
@目录1.原理2.寻找批量的图片URL的储存地址2.1百度2.2搜狗2.3必应2.4总结3.处理存储图片URL的请求头4.完整demo1.原理网页中的图片有自己的URL,访问这些URL可以直接得到图片,譬如,访问下面这个URL,你就能得到一张图片:...

Python爬虫实战:利用代理IP爬取百度翻译_百度翻译详细翻译怎么爬取...
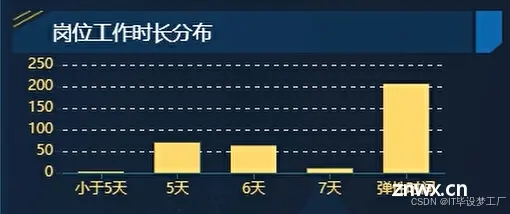
在当今的就业市场中,招聘数据的分析对于理解劳动市场动态、预测行业趋势以及制定人力资源策略至关重要。据统计,全球每年有数亿的招聘广告发布,覆盖了从初级职位到高级管理的各个层级。然而,这些数据往往分散在不同的招聘平台和公...
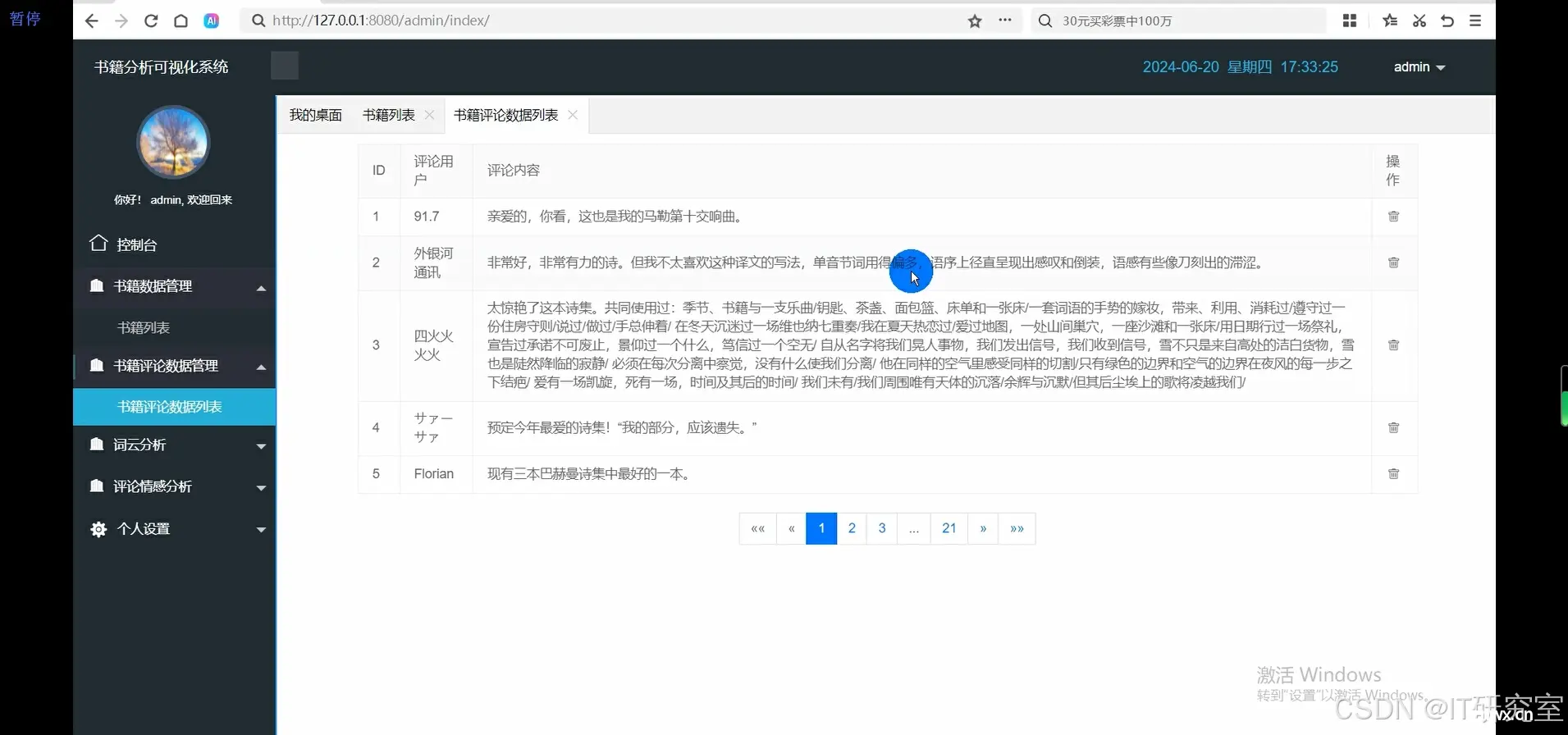
随着数字化阅读的普及,豆瓣等在线书籍评价平台积累了大量的用户评论和评分数据。这些数据不仅反映了读者的阅读体验,也为书籍的推广和改进提供了重要参考。根据豆瓣平台的统计数据,每年有数百万条书籍评论被发布,涵盖了各种类型和...

在JavaScript逆向工程中,字体反爬(FontAnti-Scraping)是一种常见的反爬虫技术,它通过自定义字体来显示网页中的文字,使得这些文字在标准字体库中无法直接识别,从而增加爬虫获取文本内容的难度...

某讯视频是采用m3u8视频流格式,先找到你所需要爬取电影的m3u8文件的url,然后通过访问这个url得到.ts文件的地址某音和音乐只需要找到视频的链接就可以直接下载某站的视频有所不同,某站视频的视频和音频是分开的...
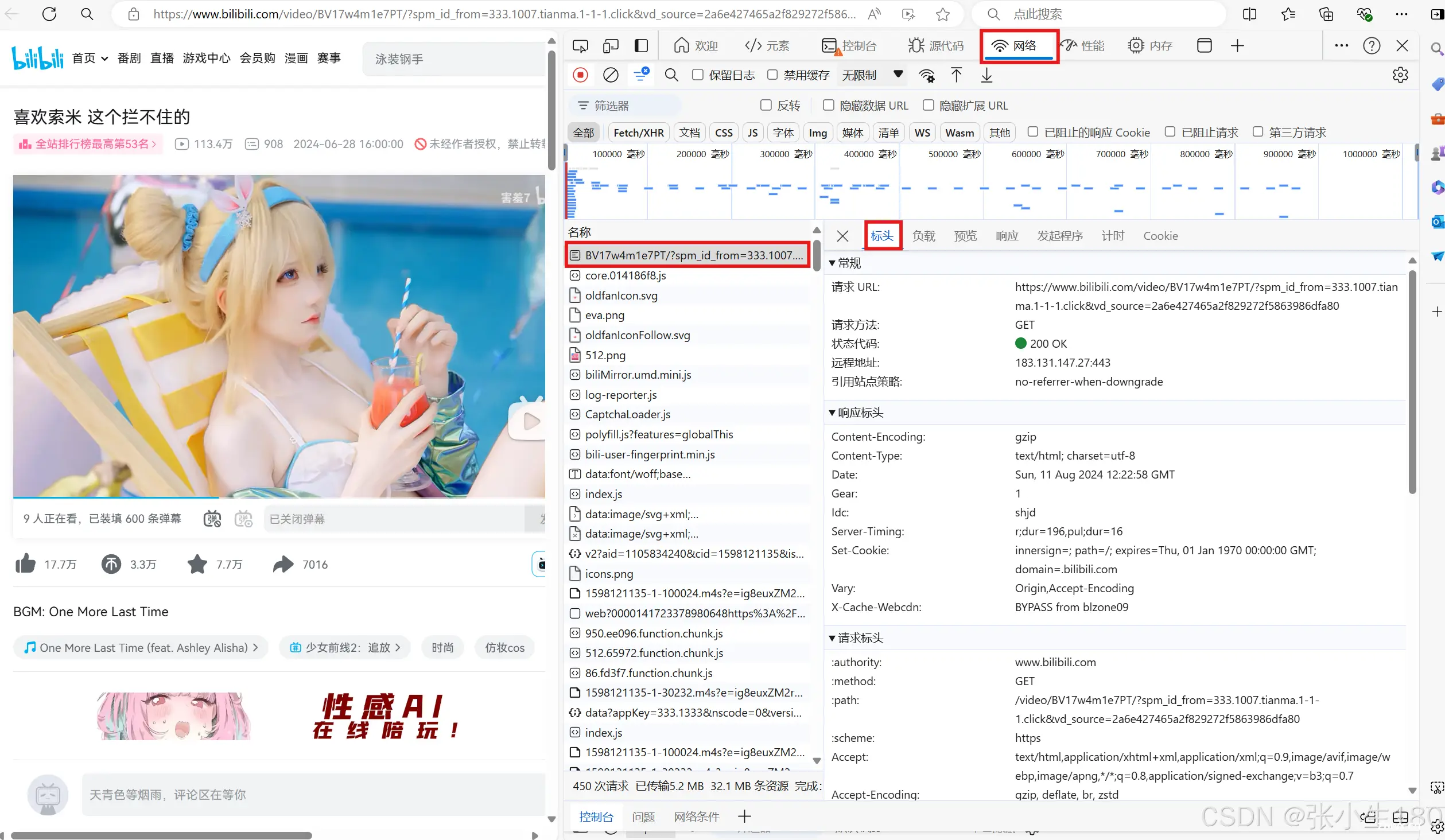
爬取哔哩哔哩中的视频...

本实验数据集来源于房天下官网,通过使用python爬虫获取了长沙市的租房数据获取了房屋租金、交付方式、房屋户型、房屋面积、装修情况、校区、地址、配套设施、房源亮点等字段信息,具体如下图所示。...
DrissionPage是一个基于Python的网页自动化和抓取工具,它通过整合Selenium和Requests的优点,提供了高效、简洁的网页操作和数据抓取解决方案。无论是浏览器自动化控制,还是直接发...
Webbot是一个专为Python设计的库,用于简化网页自动化任务。它基于SeleniumWebDriver,提供了一系列高级接口,使自动化任务更加直观和易于管理。Webbot库的设计理念是将复杂的网页交互抽象为...