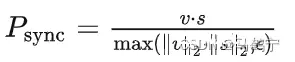
本文介绍了一种名为Wav2Lip的模型,它可以根据语音生成唇形同步的视频。这个模型是第一个通用的说话者模型,可以在真实世界的情况下进行应用。...

目录1.效果展示和玩法场景2.GeneFace++原理学习3.数据集准备以及训练的过程5.遇到的问题与解决方案6.参考资料一、效果展示AI数字人进阶--GeneFace++(1)AI数字人进阶--GeneFace...
试玩了国内外目前可以找到的AI数字人软件,不是数字人达不到要求,就是价格不亲民,场景也单调。未来是否可以不断推陈出新以及多给用户更长期限的免费体验,增强数字人的功能,才会有比较好的市场效果。搞来搞去最终就是收集客户信...

EchoMimic是阿里巴巴达摩院推出的一个AI驱动的口型同步技术项目。这项技术能够通过给定的音频和一张或多张人物的面部照片,生成一个看起来像是在说话的视频,其中的人物口型动作与音频中的语音完美匹配。这种技术在娱...
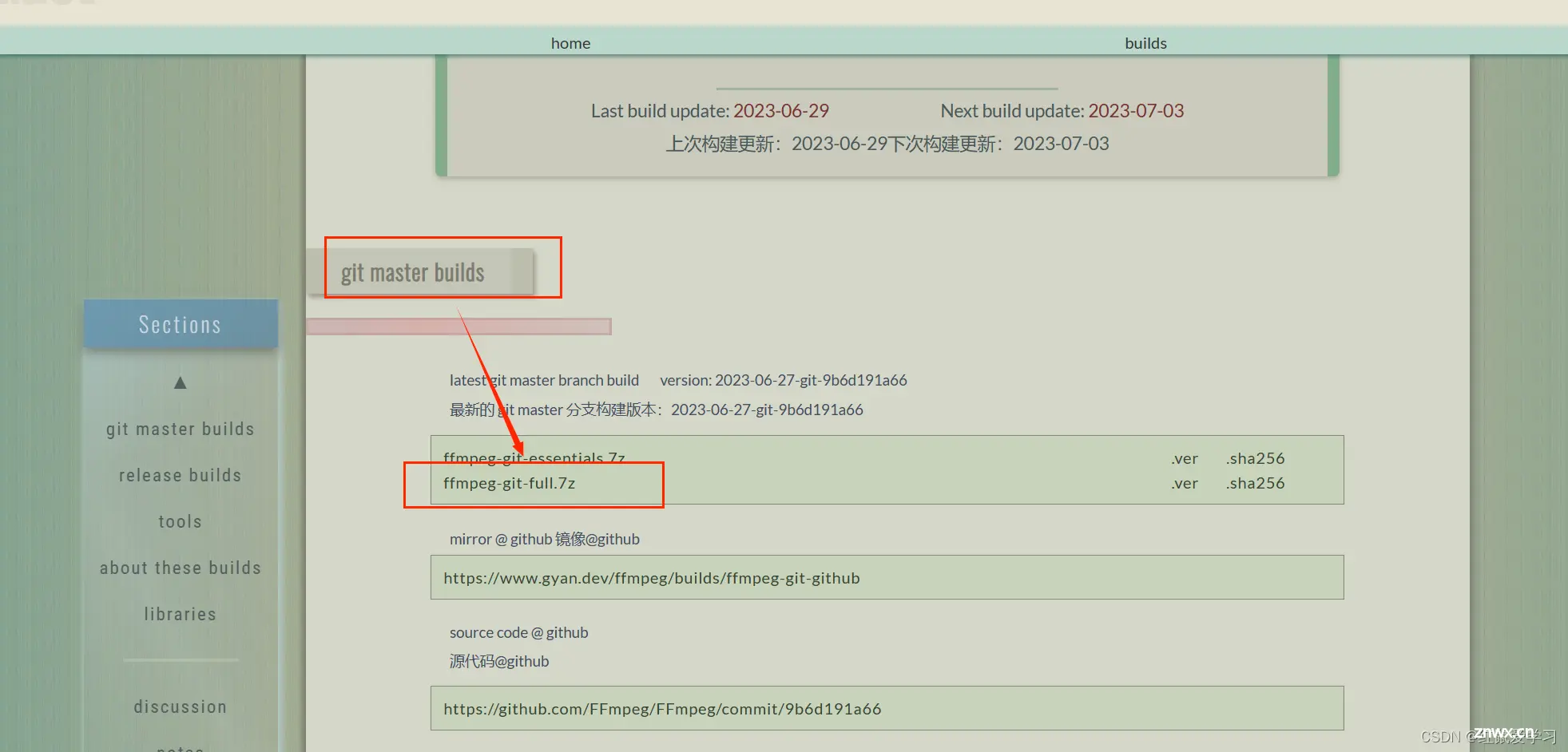
打开stablediffusion中扩展栏目,从网页下载sadtalker插件,下载完之后可以在installed处检查会出现sadtalker的标志,如果有就下载成功了,如果没有可能是因为网络原因,多试几次,...

AI数字人是一种结合了人工智能和计算机图形学技术的虚拟人物。它不仅可以进行语音对话,还能通过动画和表情与人类互动。自然语言处理(NLP):理解和生成自然语言。语音合成和识别:将文字转化为语音,或将语音转化为文字。计算...
OpenAIGym可以用于训练数字人的运动控制、表情控制、语音控制等。MeshTensorFlow已经被用于多个3D深度学习任务,例如3D重建、3D生成、3D理解等。MeshTensorFl...

1、CMLR2、LRW-10003、其他数据集4、视频收集与处理与训练5、资料Wav2Lip实现的是视频人物根据输入音频生成与语音同步的人物唇形,使得生成的视频人物口型与输入语音同步。不仅可以基于静态图像来输出与...
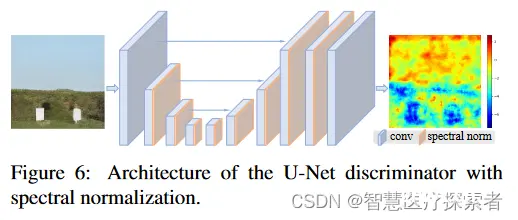
Real-ESRGAN是一种基于深度学习的图像超分辨率增强方法,通过生成对抗网络实现高质量的图像重建。它在保留细节和增强图像逼真度方面表现出色,可以广泛应用于图像处理和增强领域。在AI数字人打造过程中,Real-E...

唇读(LipReading),也称视觉语音识别(VisualSpeechRecognition),通过说话者口型变化信息推断其所说的内容,旨在利用视觉信道信息补充听觉信道信息,在现实生活中有重要应用。例如,...