
通过docker方式实现Qwen2.5-7B-Instruct集成vllm,流式输出...
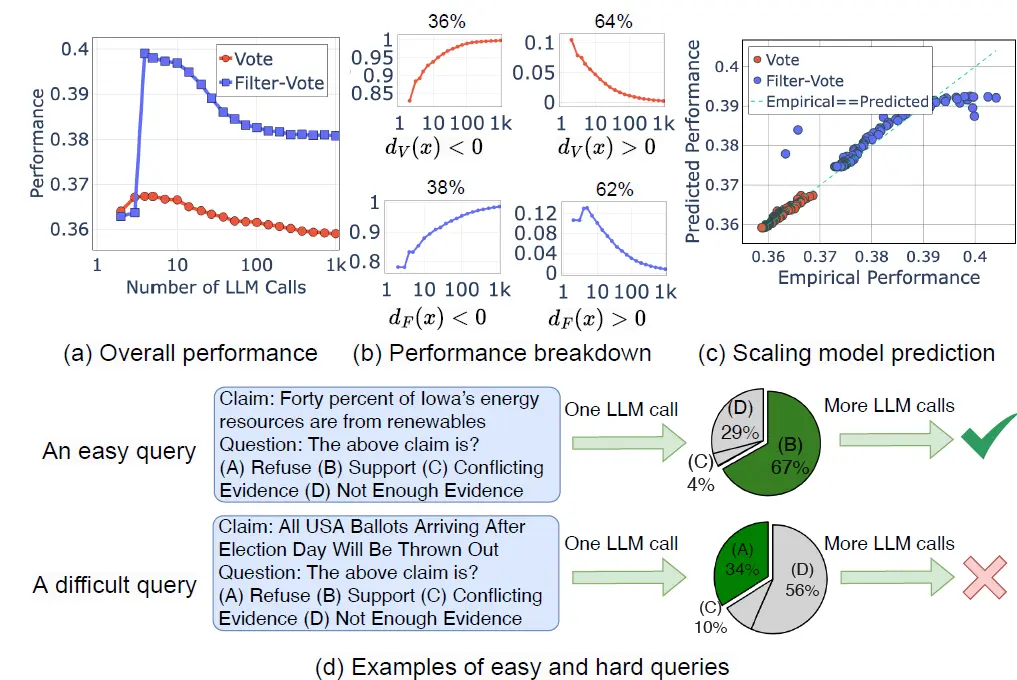
OpenAI的O-1出现前,其实就有大佬开始分析后面OpenAI的技术路线,其中一个方向就是从Pretrain-scaling,Post-Train-scaling向InferenceScaling的转变,这一章我们挑3篇inference-scaling相...

对比分析NVIDIA的H100、A100、A6000、A4000、V100、P6000、RTX4000、L40s、L4九款GPU,哪些更推荐用于模型训练,哪些则更推荐用于推理。_l4gpu...

多模态推理与大型语言模型(LLMs)经常遭受幻觉的困扰,以及LLMs内部知识不足或过时的问题。一些方法通过使用文本知识图谱来缓解这些问题,但它们单一的知识模态限制了全面的跨模态理解。在本文中,我们提出了一种基于多模...

YOLOv11由Ultralytics在2024年9月30日发布,最新的YOLOv11模型在之前的YOLO版本引入了新功能和改进,以进一步提高性能和灵活性。YOLO11在快速、准确且...

了解详情请私解决你的逆向烦恼_算法推理工具...

SGLang:EfficientExecutionofStructuredLanguageModelPrograms,由斯坦福大学、加州大学伯克利分校、上海交通大学、德克萨斯大学完成。_sglang...

OpenAIo1系列的推出,标志着AI发展进入了全新的阶段。不论是深入的推理能力,还是高效的性能表现,都为我们展现了AI的无限可能性。让我们拭目以待,见证AI带来的更多科技创新!🚀OpenAIo1系列模型通...
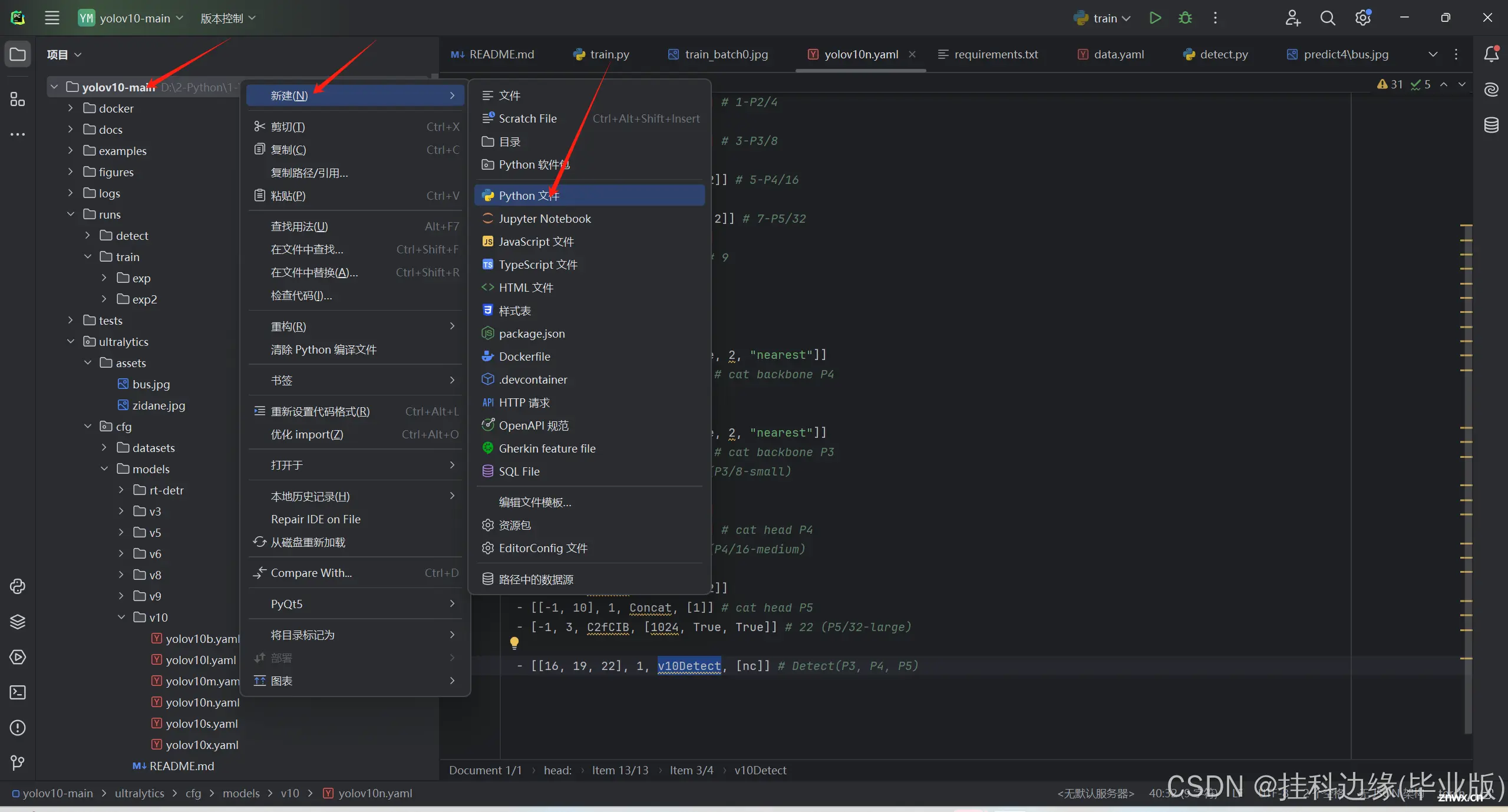
YOLOv10,由清华大学多媒体智能组只开发,是一款亳秒级实时端到端目标检测的开源模型。该模型在保持性能不变的情况下,与YOLOv9相比,延迟减少了46%,参数减少了25%,非常适合需要快速检测物体的应用,如实时...
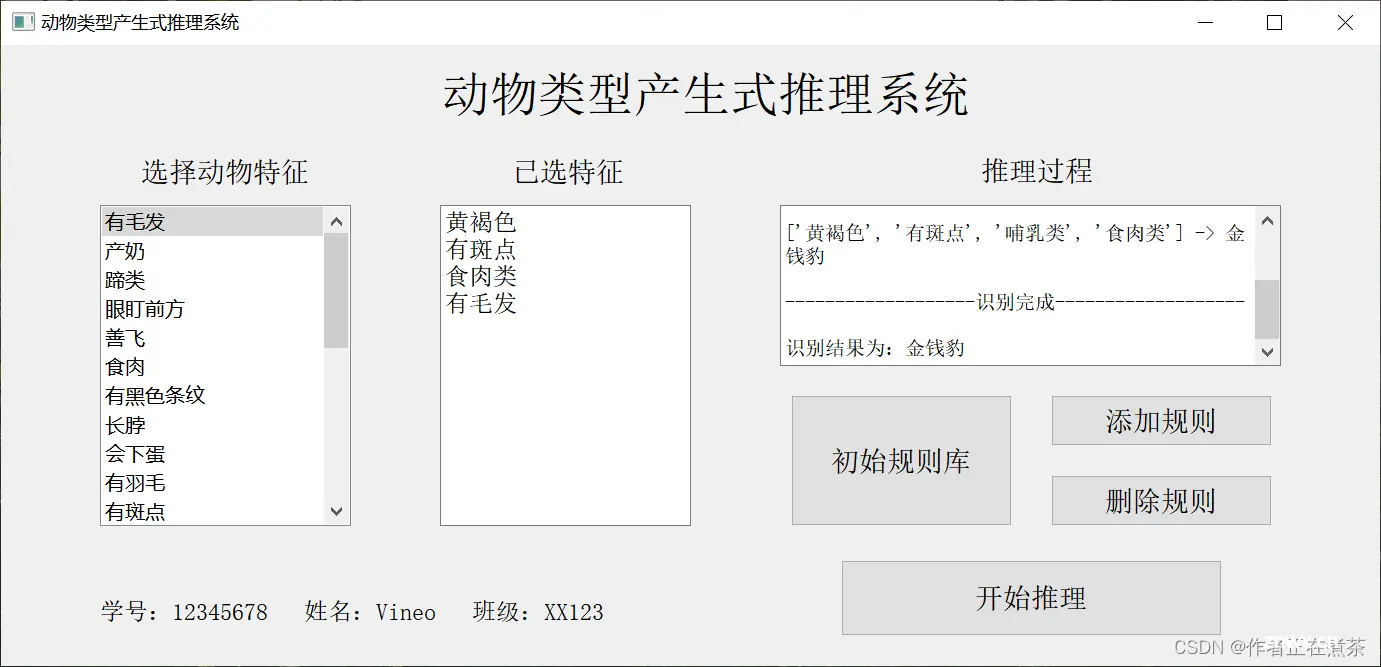
这是作者选修人工智能课程时所作的实验报告,设计实现了动物类型产生式推理系统,希望可以为小伙伴们提供微薄之力~_产生式系统实验...