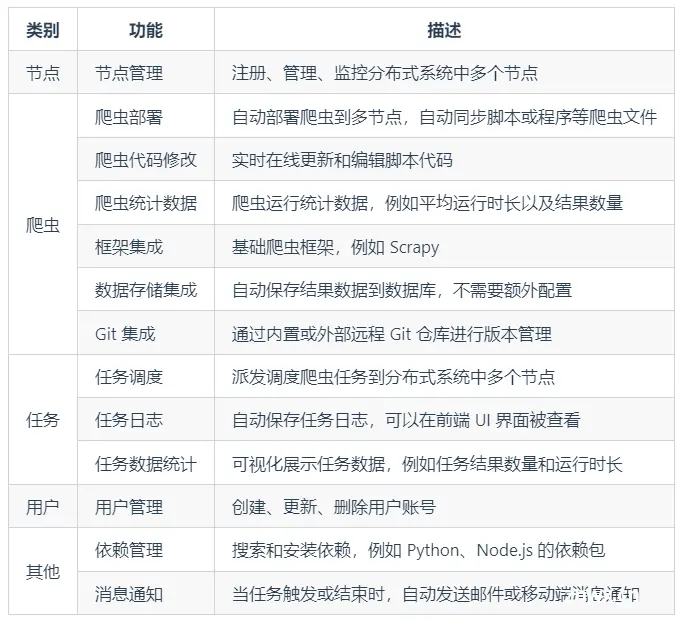
Crawlab——一个基于Golang的分布式爬虫管理平台,支持Python、NodeJS、Go、Java、PHP等多种编程语言以及多种爬虫框架。...

个人主页:在线OJ的阿川大佬的支持和鼓励,将是我成长路上最大的动力阿川水平有限,如有错误,欢迎大佬指正在这个时代AI与我们每个人息息相关1956年在美国召开了第一场人工智能研讨会,由此人类开始了对人工智能道...
你好,我是坚持分享干货的EarlGrey,翻译出版过《Python编程无师自通》、《Python并行计算手册》等技术书籍。如果我的分享对你有帮助,请关注我,一起向上进击。简单地说,网络爬虫就是从网站上抓取数据和内...
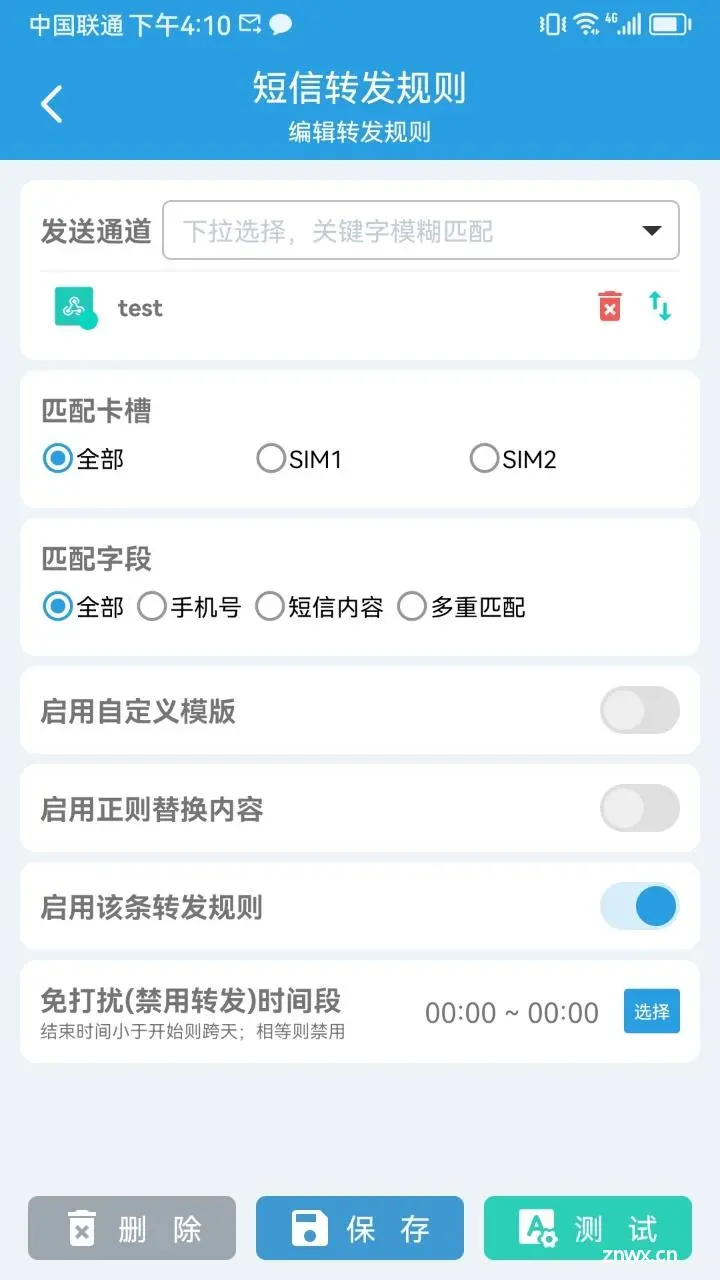
Python爬虫验证码识别——手机验证码自动化处理_爬虫模拟登陆手机短信验证码...
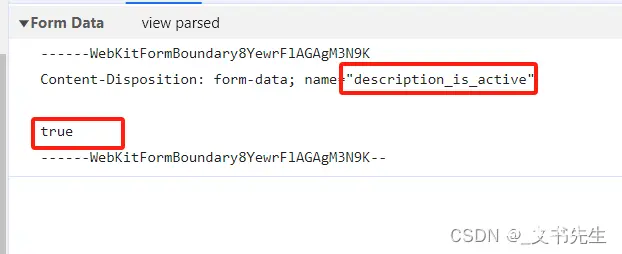
boundary=----WebKitFormBoundary****************,尝试这从其它返回的接口中也找不到它,然后使用MultipartEncoder(fields=fields,boundary=boun...

探秘AiSpider:智能爬虫框架的强大与实用项目地址:https://gitcode.com/xiaosimao/AiSpiderAiSpider是一个基于Python的开源爬虫框架,它融合了机器学习和人工智能技术...
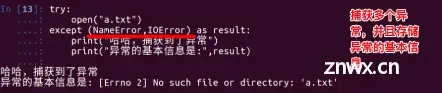
Python在各个编程语言中比较适合新手学习,Python解释器易于扩展,可以使用C、C++或其他可以通过C调用的语言扩展新的功能和数据类型。Python也可用于可定制化软件中的扩展程序语言。Python丰富的标...
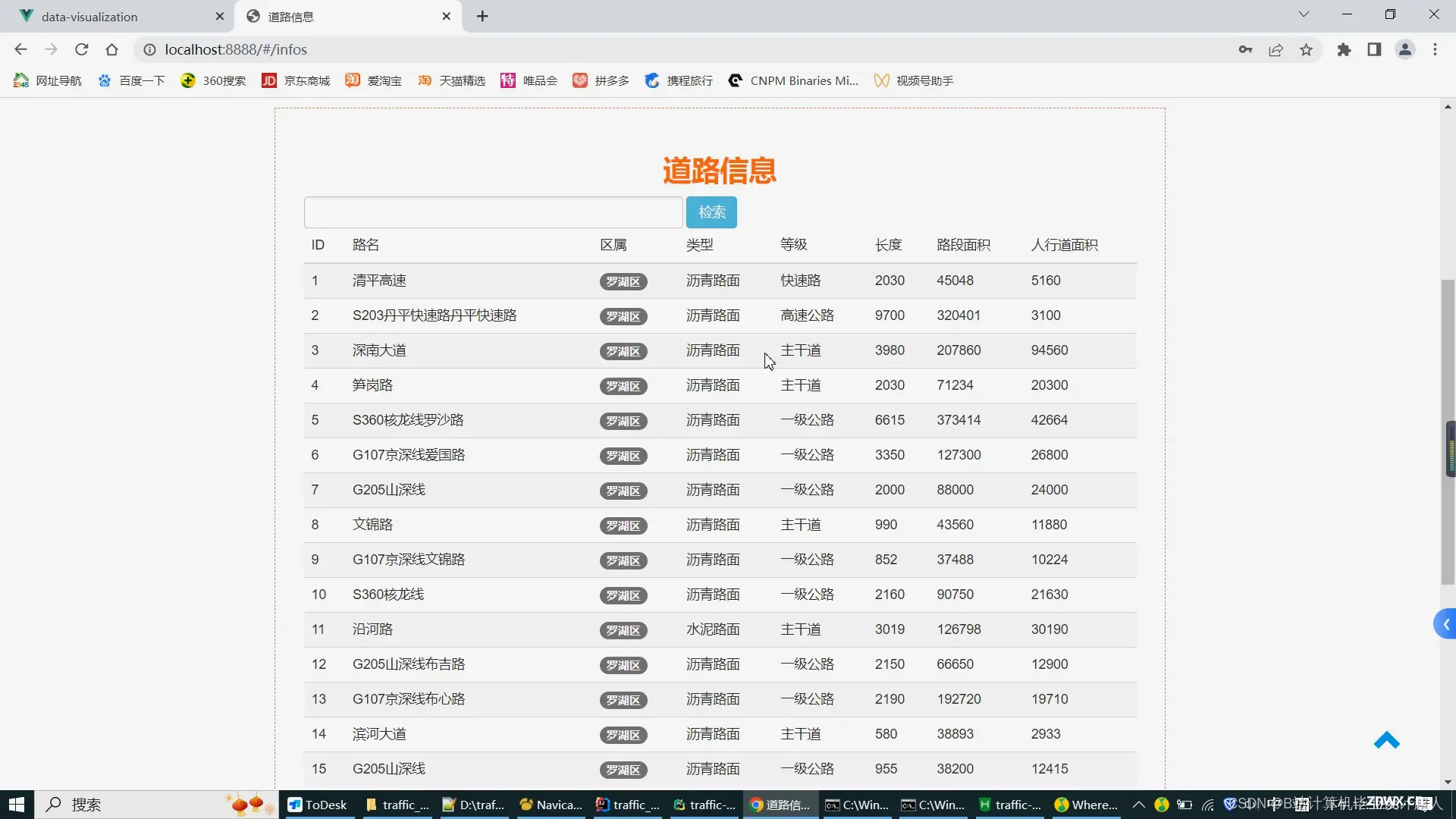
大数据毕业设计Python+Spark高速公路车流量预测可视化分析智慧城市交通大数据交通流量预测交通爬虫地铁客流量分析深度学习计算机毕业设计知识图谱深度学习人工智能_基于spark的智慧交通大数...
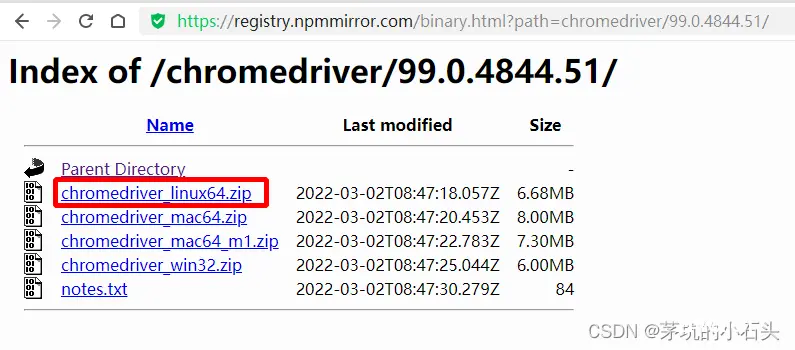
9.参考https://blog.csdn.net/qq_44757034/article/details/131109612_linux爬虫安装goog浏览器...

DrissionPage是一个基于python的网页自动化工具。它既能控制浏览器,也能收发数据包,还能把两者合而为一。可兼顾浏览器自动化的便利性和requests的高效率。_drissionpage设置...