5 个不错的开源 AI 网络爬虫工具
codingpy 2024-06-24 17:31:06 阅读 96
你好,我是坚持分享干货的 EarlGrey,翻译出版过《Python编程无师自通》、《Python并行计算手册》等技术书籍。
如果我的分享对你有帮助,请关注我,一起向上进击。
简单地说,网络爬虫就是从网站上抓取数据和内容,然后以 XML、Excel 或 SQL 的形式保存数据。除了潜在客户挖掘、竞争对手监控和市场调研之外,网络爬虫工具还可用于实现数据收集过程的自动化。
在人工智能网络爬虫工具的帮助下,可以解决手动或纯粹基于代码的爬虫工具的局限性:动态或非结构化网站现在也可以轻松处理,都无需人工干预。
在此,我们将介绍几款开源 AI 网络爬虫工具供您选择。
Reader
LLM Scraper
Firecrawl
ScrapeGraphAI
LangChain
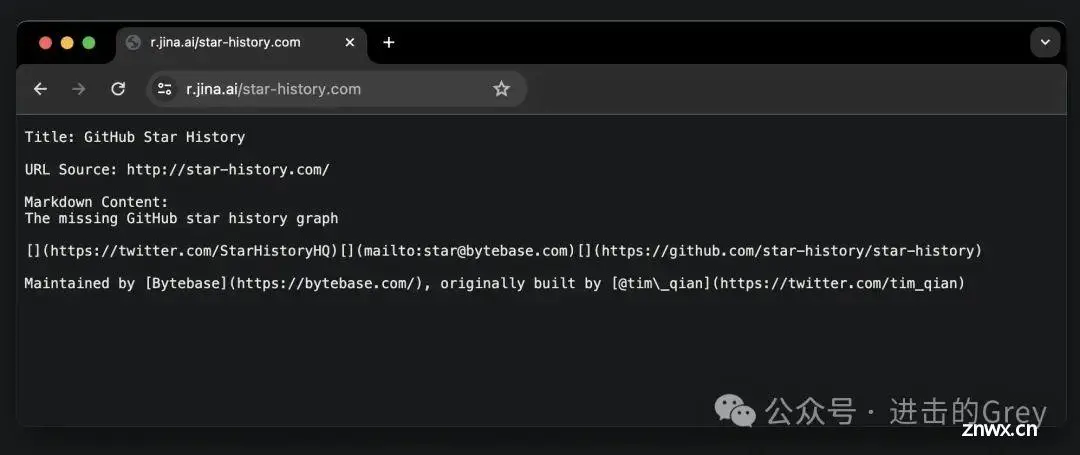
Reader

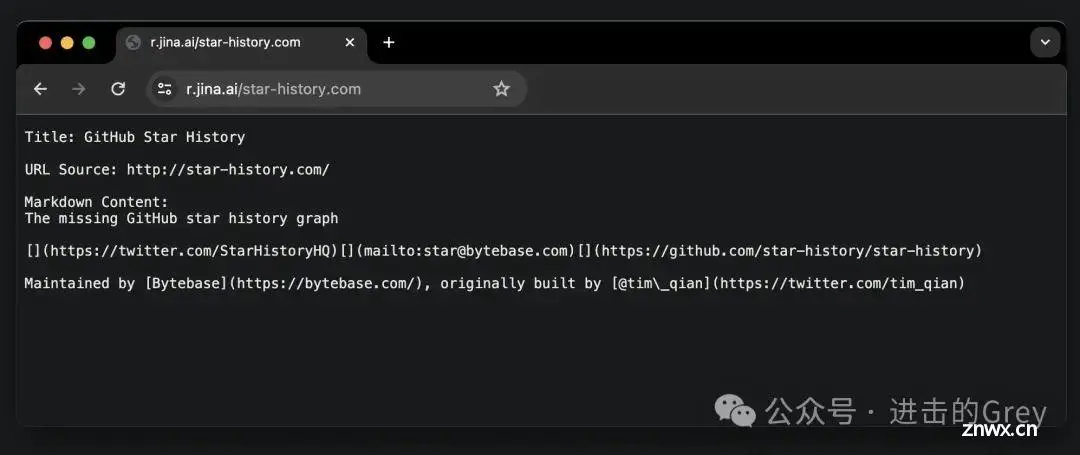
Reader是 Jina AI 推出的一款产品。当你将任意网址附加到https://r.jina.ai/之后,它可以将任何 URL 转换为 LLM 友好的输入,并免费获得可用于 RAG 系统的结构化输出。
自上个月(确切地说是 4 月 15 日)首次发布以来,全球累计请求量已超过 1800 万个请求,而项目本身也已经获得了 4.5K 个星标。
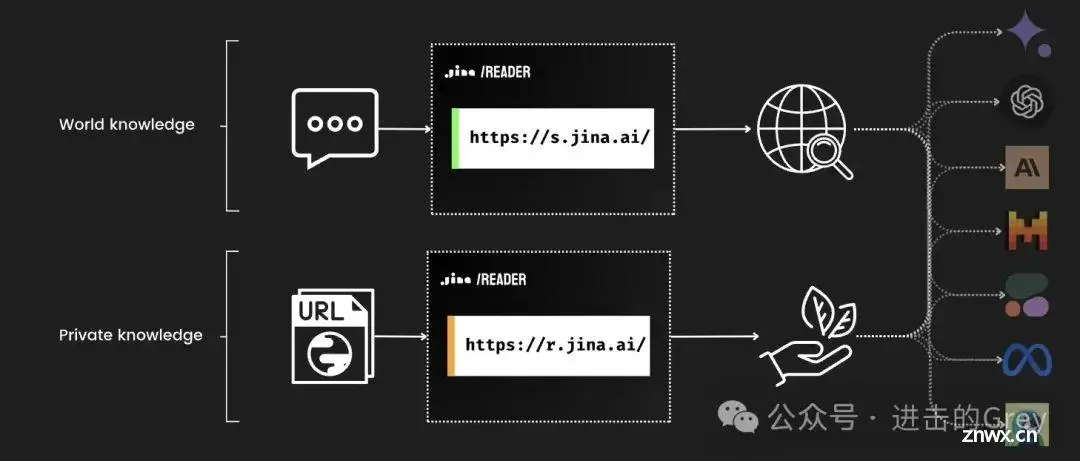
除了爬取任意 URL 之外,Jina 还发布了另一项功能,即可以使用 https://s.jina.ai/YOUR_SEARCH_QUERY 搜索互联网上的最新知识。搜索结果包括标题、LLM友好的markdown文本 和注明来源的 URL。
这样就可以为 LLM、智能体和 RAG 系统构建一个全面的解决方案。
LLM Scraper
LLM Scraper 是一个 TypeScript 库,可通过 LLM 将任何网页转换为结构化数据。本质上,它使用函数调用将网页转换为结构化数据。
与 Reader 类似,它也是上个月才开源的。它目前支持本地(GGUF)、OpenAI 和 Groq 聊天模型。显然,作者正在努力通过 llama.cpp 支持本地 LLM,以降低使用 LLM 进行网络爬取的成本。
Firecrawl

Firecrawl是一个 API 服务,可将 URL 转换为简洁、格式良好的markdown文本。这种格式非常适合 LLM 应用程序,它提供了一种结构化而又灵活的方式来表示网页内容。
该工具专为 LLM 工程师、数据科学家、人工智能研究人员和开发人员量身定制,他们希望利用网络数据来训练机器学习模型、进行市场研究和内容聚合。它简化了数据准备过程,使专业人员能够专注于洞察力和模型开发,您还可以根据自己的喜好自行托管它。
ScrapeGraphAI
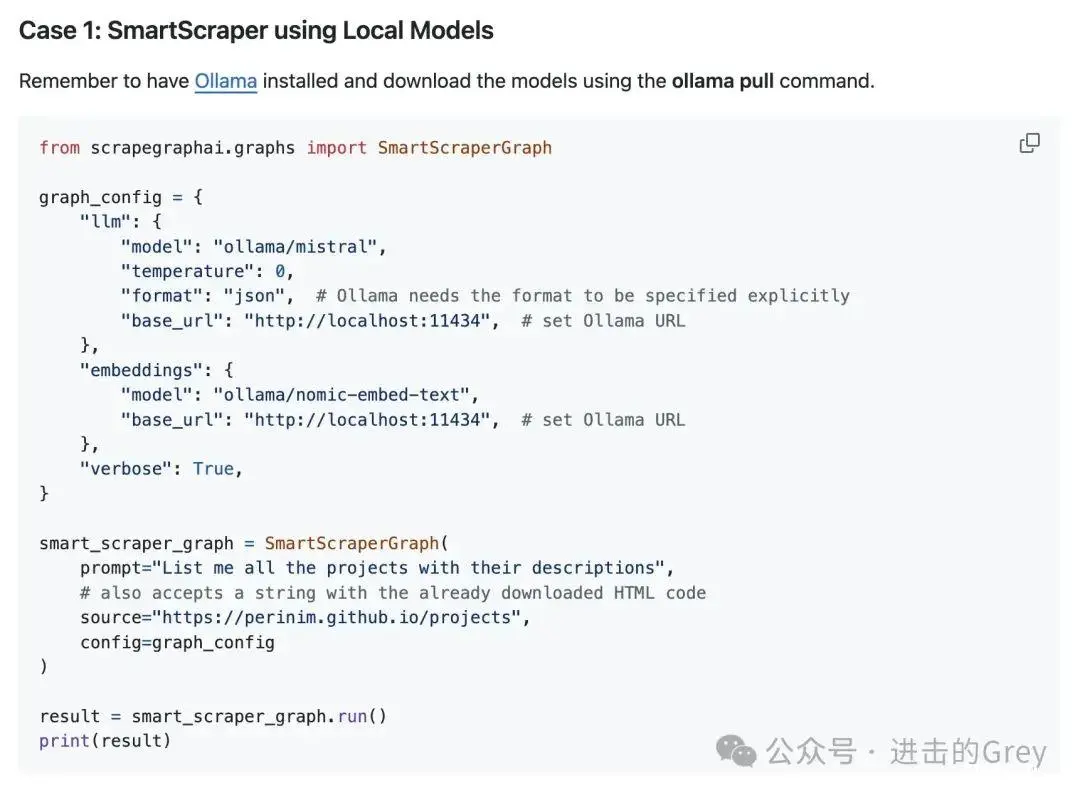
ScrapeGraphAI是一个 Python 库,它使用 LLM 和直接图逻辑来创建网站和本地文档(XML、HTML、JSON 等)的爬取管道。使用 ScrapeGraphAI,您可以准确指定要提取的数据类型。
ScrapegraphAI 充分利用了 LLM 的强大功能,因此可以适应网站结构的变化,减少了开发人员不断干预的需要。这种灵活性确保了即使网站布局发生变化,爬虫也能保持正常运行。
它目前支持的 LLM 包括 GPT、Gemini、Groq、Azure、Hugging Face 以及本地模型。
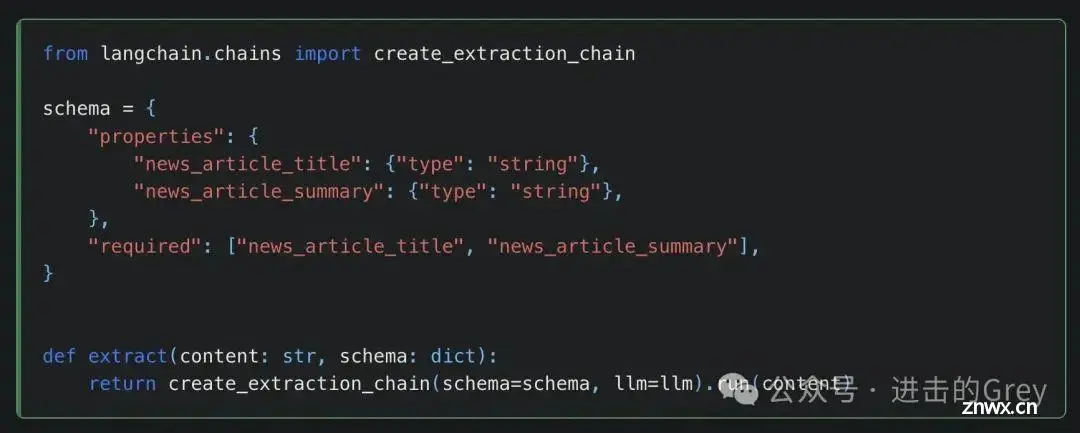
LangChain
有什么是 LangChain 做不到的?[网络爬虫]也能做(https://python.langchain.com/v0.1/docs/use_cases/web_scraping/)。
网络爬虫的最大挑战之一是网站的布局和内容不断变化,这就需要修改脚本以适应变化,而 LangChain 还利用了带有提取链的功能(如 OpenAI),这样当网站发生变化时,您就不必不断修改代码了。
如果你正在做研究,只想从《华尔街日报》网站上爬取新闻文章的名称和摘要,它就能满足你的需求。
小结
当然,没有放之四海而皆准的网络搜刮工具。你是喜欢传统的老式网络爬虫,还是喜欢由 LLM 驱动的网络搜爬虫工具?
英文原文:star-history.com
- EOF -
文章已经看到这了,别忘了在右下角点个“赞”和“在看”鼓励哦~
推荐阅读 点击标题可跳转
1、Python 项目工程化最佳实践
2、Python 可以比 C 还要快!
3、streamlit,一个超强的 Python 库
4、豆瓣8.9分的C++经典之作,免费送!
5、Python 3.12 版本有什么变化?
最近我开了一家淘宝店,名字叫【打破壁垒】,主打程序开发相关付费素材、工具的共享类商品,帮助大家降低试错和使用成本。欢迎大家关注。
长按扫描下方二维码,然后点击页面中的【打开淘宝】,即可进入店铺:
回复下方「关键词」,获取优质资源
回复关键词「 pybook03」,领取进击的Grey与小伙伴一起翻译的《Think Python 2e》电子版
回复关键词「书单02」,领取进击的Grey整理的 10 本 Python 入门书的电子版
👇关注我的公众号👇
告诉你更多细节干货
欢迎围观我的朋友圈
👆每天更新所想所悟
上一篇: 奥特曼谈AI的机遇、挑战与人类自我反思:中国将拥有独特的大语言模型
下一篇: 2023年11月3日《广东省人民政府关于加快建设通用人工智能产业创新引领地的实施意见》发布,以下不属于其主要特色的是()
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。