
python操作kafka_pythonkafka...

ApacheDruid是一个高效的实时数据存储和分析系统,结合Kafka能实现对实时流数据的摄取与处理。典型的流程是先通过Kafka采集数据,Kafka作为数据源接收生产者发送的实时数据,比如用户行...
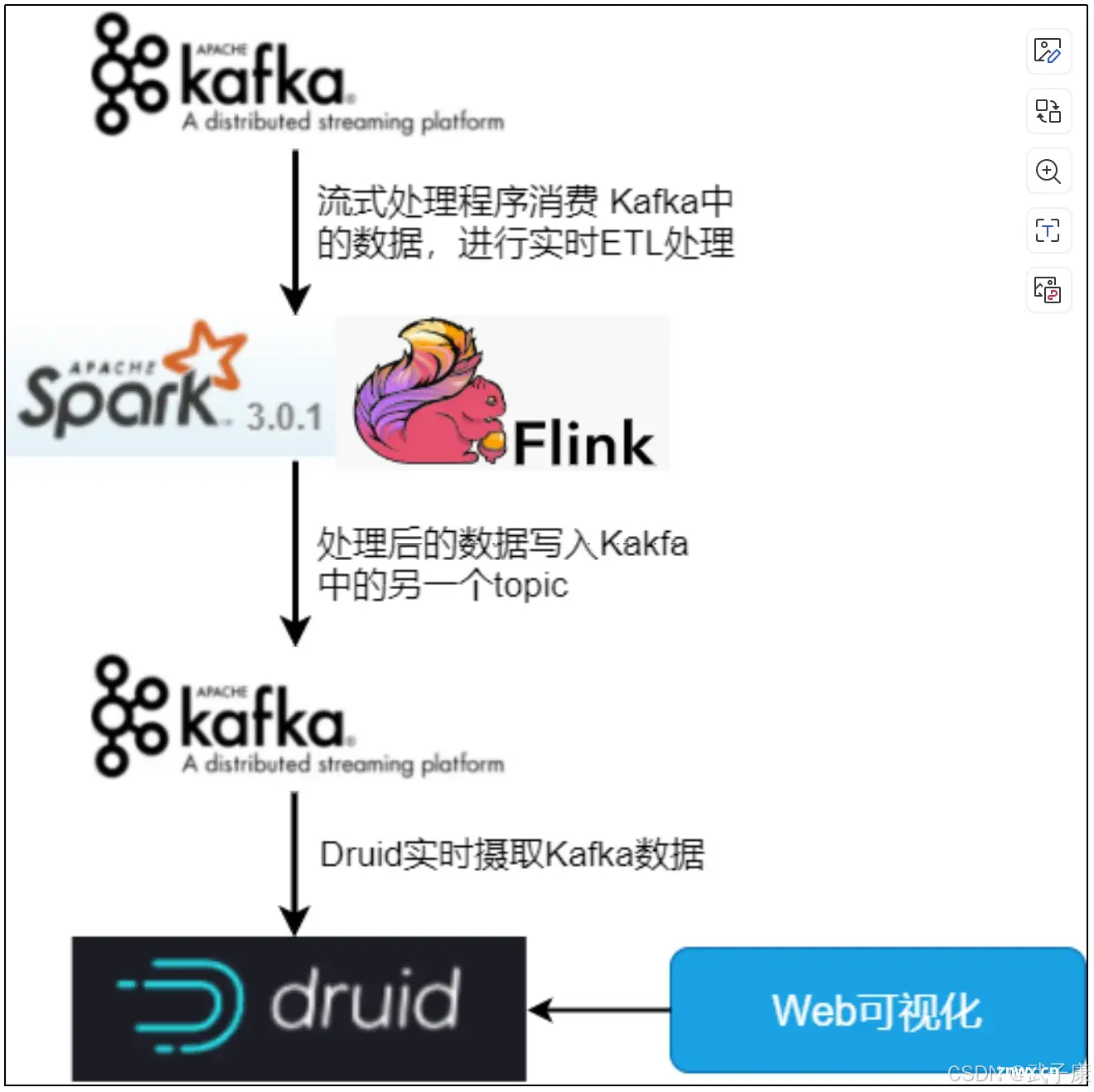
ApacheDruid从Kafka中获取数据并进行分析的流程通常分为以下几个步骤:Kafka数据流的接入:Druid通过KafkaIndexingService直接从Kafka中摄取实时流...

dockerexec:这是Docker的一个命令,用于在运行的Docker容器中执行命令。--it:这是两个选项的组合。-i选项让Docker的输入保持打开,-t选项让Docker分配一个伪终端(pseud...

本文详细描述了如何使用Docker和docker-compose在宿主机上部署Zookeeper和Kafka集群,包括创建数据目录、配置文件(如ZooKeeper的zoo.cfg和log4j.properties),...
上节完成了Kafka集群的搭建和分析Kafka集群的应用场景,并且完成了实机的搭建。本节我们研究Kafka集群的可视化方案,JavaAPI获取集群指标、JConsole、KafkaEagle等可视化方案。Kaf...
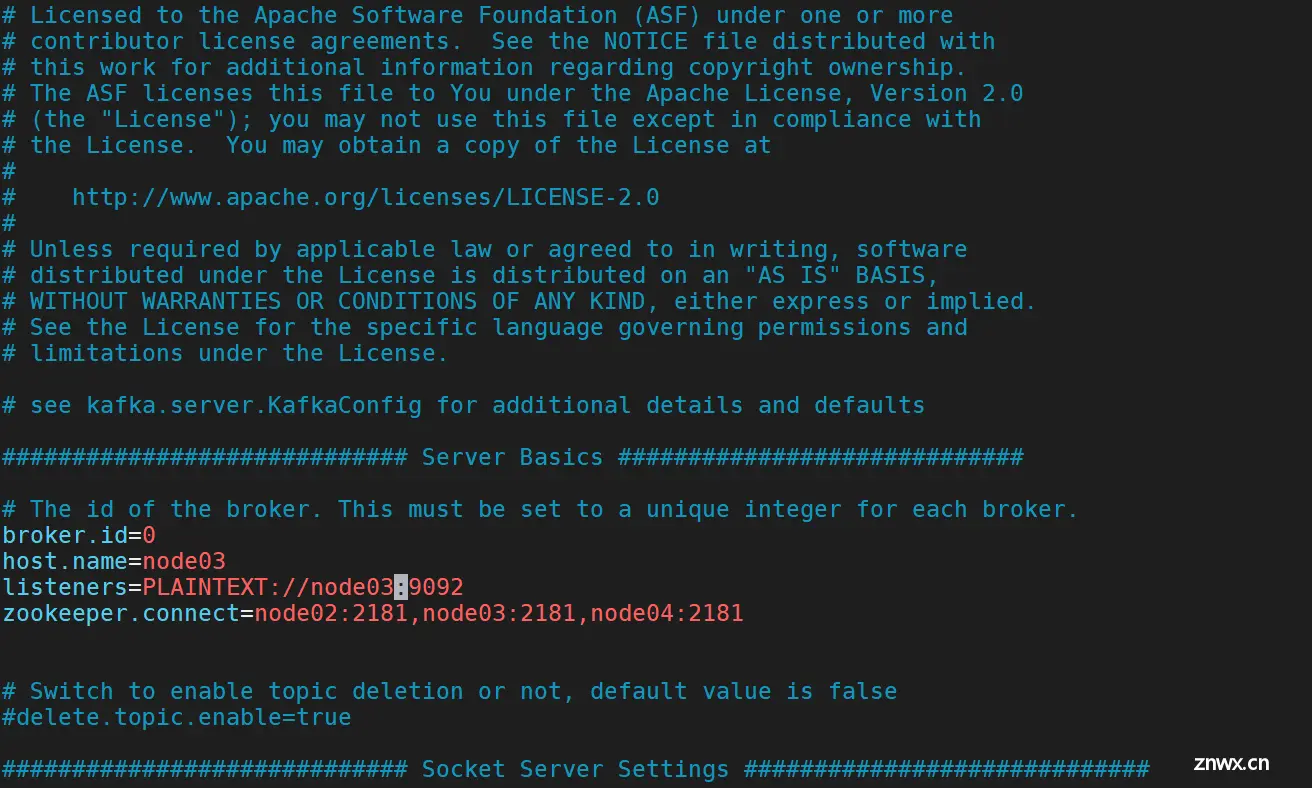
在node02上执行以下命令,拷贝kafka_2.11-0.10.1.1到node03、4的“/usr/local”目录下。在node02、3、4上执行以下命令,都可以查看到上一步骤创建的topic主题。添加完成...
上节研究了SparkStreamingKafka的Offset管理,同时使用Scala实现了自定义的Offset管理。本节继续研究,使用Redis对Kafka的Offset进行管理。Redis作为一个高效的内...
本文详细介绍了ApacheKafka的安装过程,包括Java环境准备、安装包下载、配置broker、topic、partition以及如何在Springboot中集成Kafka。涵盖了Kafka的核心概念和实战步...
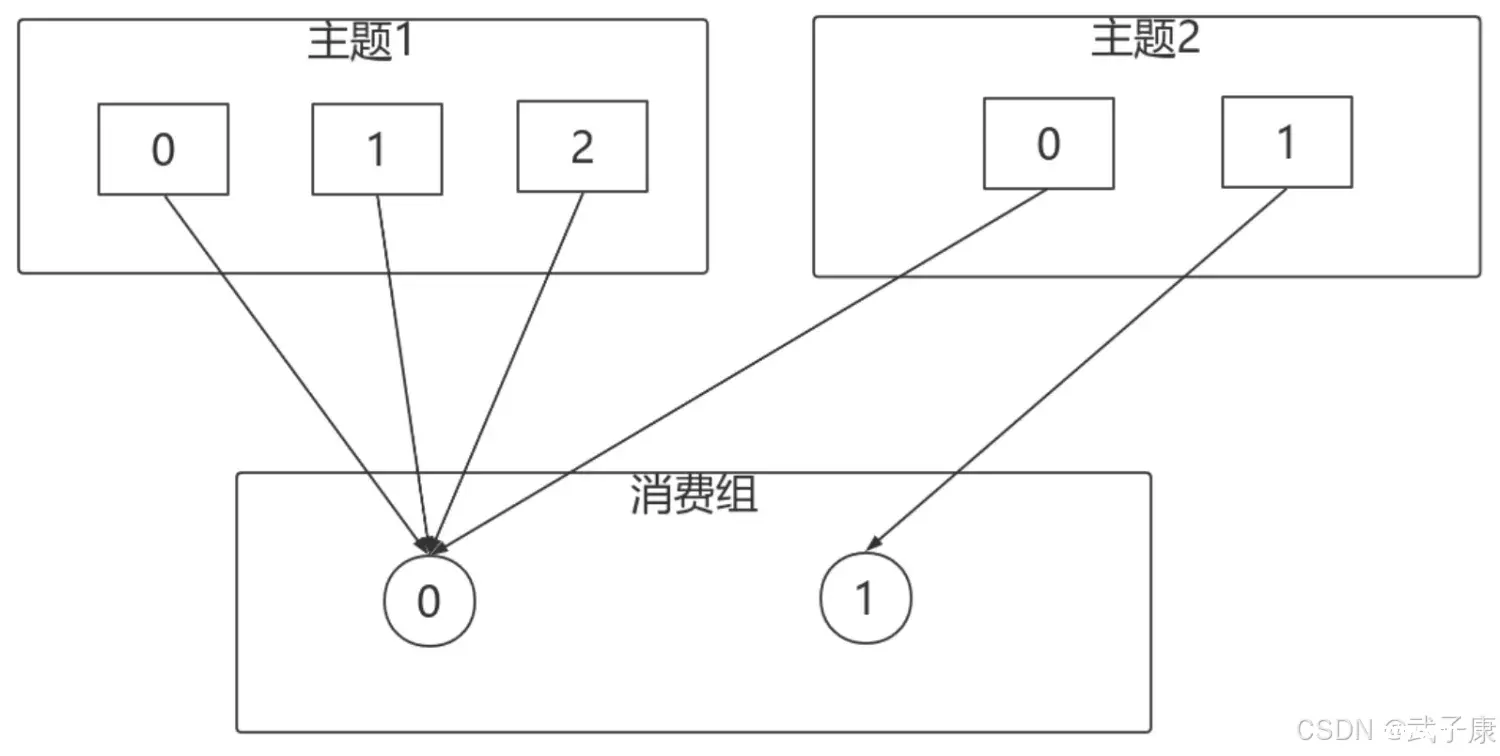
上节Kafka高级特性分区-副本数量调整,业务中遇到副本调整需求,但是无法直接修改,需要JSON+脚本的方式来进行配置。本节分区-分区策略,有Ranger、RoundRobin、Sticky等策略,最后实现自定义...