
ScaledDot-ProductAttention的公式中为什么要除以\(\sqrt{d_k}\)?在学习ScaledDot-ProductAttention的过程中,遇到了如下公式\[\mathrm{Attention}(\math...

交叉注意力机制(Cross-AttentionMechanism)是一种在深度学习中广泛使用的技术,尤其在序列到序列(sequence-to-sequence)模型和Transformer模型中被大量应用。...

MultiHeadAttention多头注意力作为Transformer的核心组件,其主要由多组自注意力组合构成,AttentionIsAllYouNeed,self-attention。_多头自注意力机...
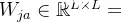
多模态情感识别最近受到了广泛关注,因为它能够利用多种模态(如音频、视觉和生物信号)之间的多样性和互补关系。大多数先进的音频-视觉(A-V)融合方法依赖于循环神经网络或传统的注意力机制,但这些方法没有有效地利用A-V模...
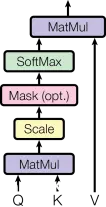
是一篇由AshishVaswani等人在2017年发表的论文,它在自然语言处理领域引入了一种新的架构——Transformer。这个架构现在被广泛应用于各种任务,如机器翻译、文本摘要、问答系统等。Transfo...

YOLOv8继承了YOLO系列的核心思想,即通过单次前向传播同时完成分类和定位任务。它的模型架构进一步优化了CSPDarknet作为骨干网络,并在此基础上引入了多尺度特征融合和改进的损失函数。然而,这些改进仍未能完全...

本文介绍了如何将TripletAttention注意力机制集成到YOLOv8中,并详细讲解了集成的原理、实现步骤、代码示例以及模型部署与应用的细节。通过引入TripletAttention机制,我们能够显著提升YOLOv8在目标检测任务...

Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是「从关注全部到关注重点注意力机制其实是源自于人对于外部信息的处理能力。由于人每一时刻接受的信息都是无比的庞大且复杂,远远超过人脑的...

通过这种方式,SELA可以更好地捕捉到图像中细粒度的局部信息,增强了对局部特征的敏感度。到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv10改进有效涨点专栏,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机...
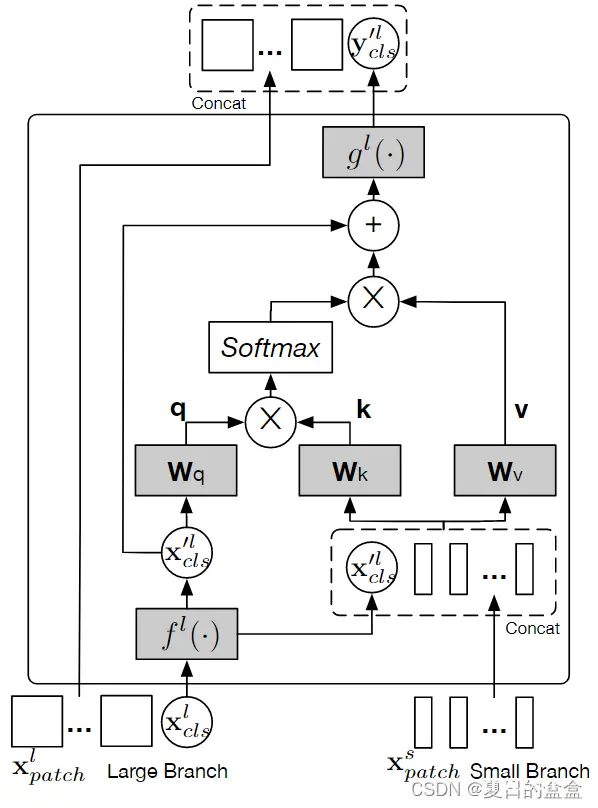
本文提出一个双分支transformer,来组合不同尺寸的图像块(即transformer中的token),以产生更强的图像特征。该方法处理具有不同计算复杂度的两个独立分支的小块和大块token,然后纯粹通过注意力多次...