
总得拆开炼丹炉看看是什么样的。这篇文章将带你从代码层面一步步实现AI文本生成图像(Text-to-Image)中的LoRA微调过程,你将:-了解**TriggerWords**(触发词)到底是什么,...

真正的魔力在于结合这些方法:提示词、RAG、微调、切换模型和使用多模态大模型。利用每种方法的优势,并将其应用于文本和图像数据,以此用大模型提升你的生产力。_ai大模型知识库...

样本数量一般1万左右的高质量样本即可达到良好效果。对于简单任务,100-300条数据足够;中等难度任务需1000条以上;高难度任务需3000条甚至更多,可能达到10万条。样本质量样本质量优先于数量,高质量样本更有效。需...

主要是修改了导入为包的导入,而不是相对引用。这里稍微修改了open-retrievals。数据仍然采用之前介绍的。...
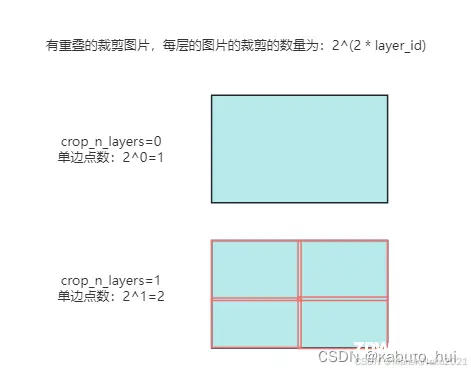
SAM初步理解,简单介绍模型框架,不涉及细节和代码SAM细节理解,对各模块结合代码进一步分析SAM微调实例,原始代码涉及隐私,此部分使用公开的VOC2007数据集,Point和Box作为提示进行maskdeco...
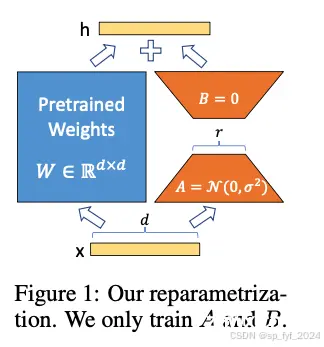
大语言模型的微调技术LoRA及成功背后原理分析文章。...
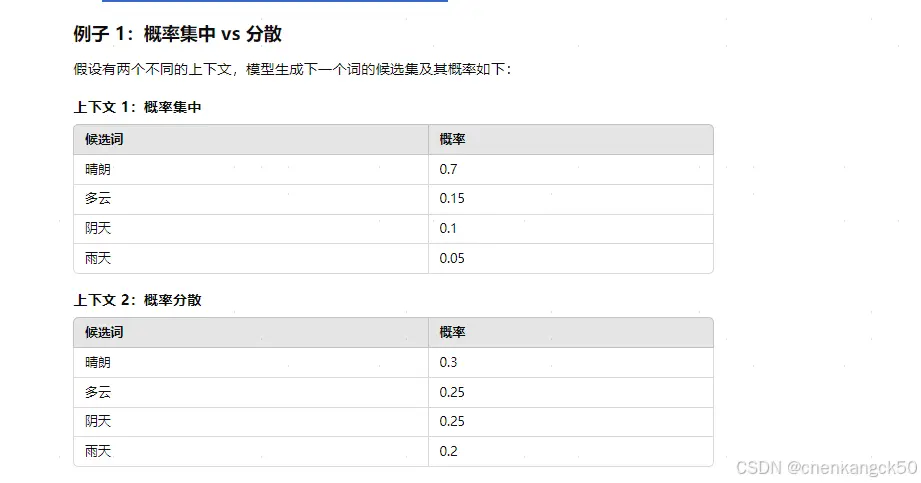
在自然语言处理(NLP)中,Token指的是模型处理的文本片段。它可以是一个单词、单词的一部分,甚至是标点符号。比如在句子“Iamlearning”中,每个词可以被视为一个Token:“I”→1个...

如何微调:关注有效的数据集本文关于适应开源大型语言模型(LLMs)系列博客的第三篇文章。在这篇文章中,我们将探讨一些用于策划高质量训练数据集的经验法则。第一部分探讨了将LLM适应于领域数据的普遍方法第二部分讨论了咋确定微调是否适用于你的实际情况1介绍...

Qwen-VL大模型LoRA微调、融合及部署_qwen-vl微调...
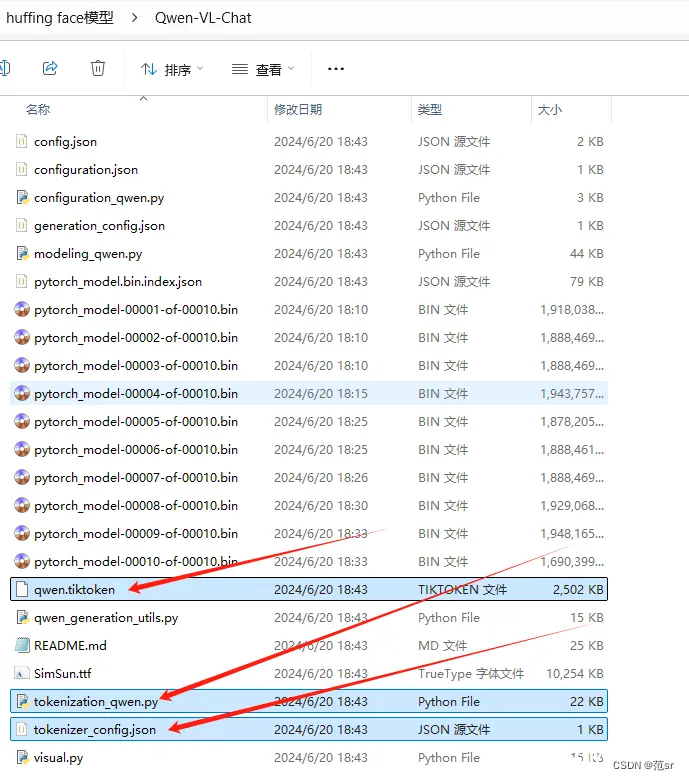
通过这个重定向,标准错误输出和标准输出都会被写入train.log文件。这个脚本文件名为finetune_lora_single_gpu.sh,通常用于单GPU上进行LoRA(Low-RankAda...