图像融合论文速读:(PSFusion)一种实用的基于渐进式语义注入和场景保真度的IVIF网络
图像强 2024-06-15 13:37:01 阅读 96
@article{tang2023rethinking,
title={Rethinking the necessity of image fusion in high-level vision tasks: A practical infrared and visible image fusion network based on progressive semantic injection and scene fidelity},
author={Tang, Linfeng and Zhang, Hao and Xu, Han and Ma, Jiayi},
journal={Information Fusion},
volume={99},
pages={101870},
year={2023},
publisher={Elsevier}
}
| 论文级别:SCI A1 TOP |
| 影响因子:18.6 |
📖[论文下载地址]
💽[代码下载地址]
文章目录
📖论文解读🔑关键词💭核心思想🎖️本文贡献🪅相关背景知识🪢网络结构🪢语义感知分支🪢场景恢复分支 📉损失函数🔢数据集🎢训练设置🔬实验📏评价指标🥅Baseline🔬实验结果 🧷总结体会 🚀传送门📑图像融合相关论文阅读笔记📚图像融合论文baseline总结📑其他论文🎈其他总结✨精品文章总结 🌻【如侵权请私信我删除】
📖论文解读
问题:以往的像素级融合方法目的主要集中在提高融合图像的视觉吸引力上,没有展示出图像级融合的潜力
本文提出了一种实用的基于【渐进式语义注入】和【场景保真度约束】的红外和可见光图像融合网络,称为PSFusion。
首先,稀疏语义感知分支提取足够的语义特征,然后使用语义注入模块逐步将这些特征整合到融合网络中,以满足高级视觉任务的语义需求。设计场景恢复分支内的场景保真度路径,保证融合特征包含源图像重构所需的完整信息。此外,采用对比蒙版和显著目标蒙版构建融合损失,以保持融合结果的视觉效果。
🔑关键词
Image fusion 图像融合
High-level vision task 高级视觉任务
Progressive semantic injection 渐进式语义注入
Scene fidelity 场景保真度
Feature-level fusion 特征级融合
💭核心思想
具有图像融合路径的【场景恢复分支】和【稀疏语义预测分支】,两者【共享多尺度特征提取网络】
场景恢复分支包含一条场景保真路径和一条图像融合路径,其中两条路径共享连续递进语义注入模块(PSIM)、密集场景重建模块(DSRM)、语义注入模块(SIM)和密集场景重建模块。
语义感知分支由稀疏语义感知模块(S2PM)和稀疏语义感知路径(S2P2)组成,其中S2P2由三个特定于任务的头组成,用于从不同角度感知稀疏语义。稀疏语义感知分支负责预测边界分割结果 I b d I_{bd} Ibd、语义分割结果 I s e I_{se} Ise和二值分割结果 I b i I_{bi} Ibi
在特征级使用语义注入模块,逐步将多个语义感知任务共同约束的语义信息注入场景恢复分支在场景恢复分支中引入了一个场景保真度路径,该路径负责从融合特征重构源图像,以约束融合特征包含源图像的所有完整信息设计了表层细节融合模块和深层语义融合模块,分别对表层特征中的结构信息和深层特征中的语义信息进行融合
🎖️本文贡献
首次证明对于高级视觉任务,多模态图像级融合可以以更低的计算负荷实现与多模态特征级融合相当的性能在特征级逐步向融合网络中注入语义特征,确保具有丰富语义线索的融合结果对任意高级骨干网络具有友好性和鲁棒性设计了与图像融合路径平行的场景保真度路径来约束融合模块以保持源图像的完整信息达到SOTA🪅相关背景知识
深度学习神经网络图像融合像素级融合和特征级融合
扩展学习
[什么是图像融合?(一看就通,通俗易懂)]
🪢网络结构
作者提出的网络结构如下所示。
我们按照顺序看,左上角分别是红外图像和可见光图像
采用ResNet作为的基本特征提取网络,并设计了两个==表面特征提取块(SFEB)==来代替ResNet的第一层

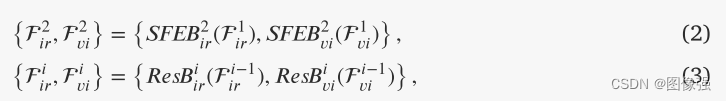
当i=1,2,3时, F i r i \mathcal F_{ir}^i Firi和 F v i i \mathcal F_{vi}^i Fvii分别代表浅层红外和可见光特征
当i=4,5,6时, F i r i \mathcal F_{ir}^i Firi和 F v i i \mathcal F_{vi}^i Fvii分别代表深层红外和可见光语义特征
考虑到浅层特征包含丰富的细节信息和结构信息,提出了一种基于通道-空间注意机制的浅层特征融合模块(SDFM)。将通道维度中的红外和可见光特征连接起来,然后将它们馈送到由卷积和池化操作组成的通道注意力模块中以生成注意力权重。然后将这些权重应用于通过元素乘法对原始特征进行加权,并将结果特征添加到来自另一个分支的原始特征中,以增强它们的表示。如下图



然后,将增强特征在通道维度上进行拼接,并输入到平行通道注意和空间注意模块中,生成最终的融合权重。

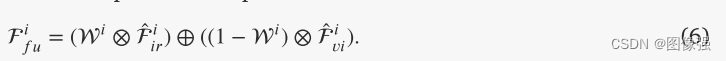
使用==基于交叉注意的深度语义融合模块(PSFM)==来整合深度特征




然后计算了模态特定的注意图

然后,将该值乘以关注值,得到具有全局上下文的特征。与SDFM类似,我们将全局特征添加到另一个分支的原始特征中,并沿着通道维度将结果特征连接起来。最后,我们将连接的特征输入到卷积层中以获得融合特征。

🪢语义感知分支
表面特征包含了大量的低级信息,即详细信息,这些信息可能会对高级视觉任务的表现产生负面影响[66]。因此,我们的稀疏语义感知分支仅利用深层特征和最后的浅层特征来预测边界、语义和二值分割结果。这些特征首先进行卷积和上采样操作,然后在通道维度上进行连接,如下所示:


将连接的特征作为初始语义特征输入到由连续卷积块组成的稀疏语义感知模块(S2PM)中。每个卷积块包括一个3 × 3内核大小的卷积层、批处理归一化和ReLU激活函数。
然后,利用稀疏语义感知路径来预测边界、语义和二值分割结果。稀疏语义感知路径可表述为:



🪢场景恢复分支
为了使场景还原分支能够充分利用语义感知分支生成的深层语义信息,设计了渐进式语义注入模块(progressive semantic injection module, PSIM),该模块由多个语义注入模块(SIMs)组成,将后两个浅层特征逐步注入到第一个浅层特征中。
具体来说,我们首先将第三个浅层特征中的语义信息注入第二特征中,然后将第二特征中的语义信息注入第一浅层特征中。

第一浅层特征从其他特征中吸收了丰富的语义信息, F s r \mathcal F_{sr} Fsr作为场景恢复分支的初始细节特征。 F s r \mathcal F_{sr} Fsr的数据被输入到密集场景重建模块(DSRM)中,该模块由卷积块和密集连接组成,以增强细粒度的细节。随后,我们将S2PM生成的语义特征 F s e \mathcal F_{se} Fse通过SIM注入到场景重构特征中。部署另一个DSRM来增强细粒度特征并生成最终的场景重建特征 F ^ s r \hat F_{sr} F^sr。最后,我们使用由3 × 3核大小的卷积层和Tanh激活函数组成的图像融合路径合成融合图像𝐼𝑓。值得强调的是,我们还设计了一个由模态特定掩模、卷积层和Tanh激活函数组成的场景保真度路径(SFP),以从 F ^ s r \hat F_{sr} F^sr重建源图像。因此,SFP可以约束 F ^ s r \hat F_{sr} F^sr包含完整的信息,用于重建红外图像 I ^ i r \hat I_{ir} I^ir和可见光图像 I ^ v i \hat I_{vi} I^vi。在稀疏语义感知路径和场景保真度路径的双重约束下,图像融合路径生成的融合结果既能包含足够的语义信息,又能包含完整的场景信息,有利于对成像场景的全面理解。
📉损失函数
PSFusion不仅利用融合损失直接约束融合结果,而且利用场景保真度路径和稀疏语义感知路径间接约束融合网络的特征提取和聚合。


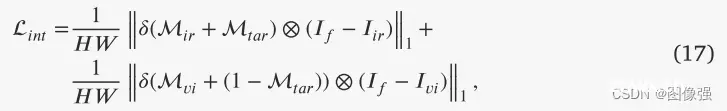

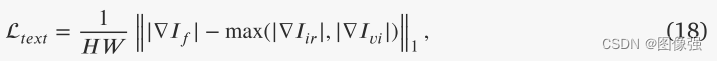
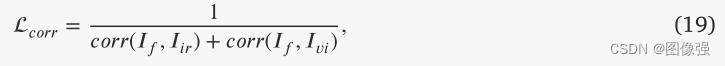

🔢数据集
MSRSM3FDTNOROADSCENE图像融合数据集链接
[图像融合常用数据集整理]
🎢训练设置

🔬实验
📏评价指标
ENSDAGSFSCDVIF扩展学习
[图像融合定量指标分析]
🥅Baseline
GTFDIDFusionRFN-NestFusionGANTarDALCMGRSeAFusionU2FusionSwinFusion✨✨✨扩展学习✨✨✨
✨✨✨强烈推荐必看博客[图像融合论文baseline及其网络模型]✨✨✨
🔬实验结果














更多实验结果及分析可以查看原文:
📖[论文下载地址]
🧷总结体会
特征级融合向像素级融合发起的挑战,一个伟大的里程碑
🚀传送门
📑图像融合相关论文阅读笔记
📑[SGFusion: A saliency guided deep-learning framework for pixel-level image fusion]
📑[MUFusion: A general unsupervised image fusion network based on memory unit]
📑[(TLGAN)Boosting target-level infrared and visible image fusion with regional information coordination]
📑[ReFusion: Learning Image Fusion from Reconstruction with Learnable Loss via Meta-Learning]
📑[YDTR: Infrared and Visible Image Fusion via Y-Shape Dynamic Transformer]
📑[CS2Fusion: Contrastive learning for Self-Supervised infrared and visible image fusion by estimating feature compensation map]
📑[CrossFuse: A novel cross attention mechanism based infrared and visible image fusion approach]
📑[(DIF-Net)Unsupervised Deep Image Fusion With Structure Tensor Representations]
📑[(MURF: Mutually Reinforcing Multi-Modal Image Registration and Fusion]
📑[(A Deep Learning Framework for Infrared and Visible Image Fusion Without Strict Registration]
📑[(APWNet)Real-time infrared and visible image fusion network using adaptive pixel weighting strategy]
📑[Dif-fusion: Towards high color fidelity in infrared and visible image fusion with diffusion models]
📑[Coconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion]
📑[LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images]
📑[(DeFusion)Fusion from decomposition: A self-supervised decomposition approach for image fusion]
📑[ReCoNet: Recurrent Correction Network for Fast and Efficient Multi-modality Image Fusion]
📑[RFN-Nest: An end-to-end resid- ual fusion network for infrared and visible images]
📑[SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images]
📑[SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer]
📑[(MFEIF)Learning a Deep Multi-Scale Feature Ensemble and an Edge-Attention Guidance for Image Fusion]
📑[DenseFuse: A fusion approach to infrared and visible images]
📑[DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pair]
📑[GANMcC: A Generative Adversarial Network With Multiclassification Constraints for IVIF]
📑[DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion]
📑[IFCNN: A general image fusion framework based on convolutional neural network]
📑[(PMGI) Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity]
📑[SDNet: A Versatile Squeeze-and-Decomposition Network for Real-Time Image Fusion]
📑[DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion]
📑[FusionGAN: A generative adversarial network for infrared and visible image fusion]
📑[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
📑[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
📑[U2Fusion: A Unified Unsupervised Image Fusion Network]
📑综述[Visible and Infrared Image Fusion Using Deep Learning]
📚图像融合论文baseline总结
📚[图像融合论文baseline及其网络模型]
📑其他论文
📑[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
🎈其他总结
🎈[CVPR2023、ICCV2023论文题目汇总及词频统计]
✨精品文章总结
✨[图像融合论文及代码整理最全大合集]
✨[图像融合常用数据集整理]
🌻【如侵权请私信我删除】
如有疑问可联系:420269520@qq.com;
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力,祝各位早发paper,顺利毕业~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。