论文速读记录
cnblogs 2024-09-30 08:13:00 阅读 62

9月论文速读记录,KDD 2024论文专场,提前祝大家国庆快乐!
这次是KDD 2024专场。

目录:
- <li>
Understanding the Ranking Loss for Recommendation with Sparse User Feedback
【从梯度的角度分析为什么pairwise损失在反馈稀疏的场景下有效?】
Unsupervised Ranking Ensemble Model for Recommendation
【如何把多个序融合为一个序?】
Non-autoregressive Generative Models for Reranking Recommendation
【如何用非自回归的方式从n个物品中选出m个进行重排?】
Multi-objective Learning to Rank by Model Distillation
【把多个单目标的模型蒸馏到一个模型中】
Mitigating Pooling Bias in E-commerce Search via False Negative Estimation
【一种减轻假阴样本影响的方法】
总结
Deep Bag-of-Words Model: An Efficient and Interpretable Relevance Architecture for Chinese E-Commerce
【词袋模型和语言模型结合,构建可解释的相关性计算方法】
Deep Bag-of-Words Model: An Efficient and Interpretable Relevance Architecture for Chinese E-Commerce
- https://arxiv.org/pdf/2407.09395,KDD 2024,Alibaba.
应用在淘宝电商搜索中的相关性匹配模型,主要解决用户查询和商品之间的文本相关性问题。
BERT类的模型虽然在文本匹配领域应用广泛,但依然存在一些问题:1)性能问题,一些场景下部署BERT还是比较消耗资源的;2)可解释性问题,通过双塔模型计算文本的相似性比较“黑盒”,可解释性较差,难以做出针对性的优化。一些传统精确匹配的方法(如BM25、tf-idf等)则存在文本表述形式差异带来不准确的问题。
因此,本文提出了一个深度词袋模型,一个高效且可解释的可解释架构,基本思路:将用户查询或商品编码成稀疏的词袋表示,即一系列<词,权重>,相似性表示为查询和商品之间匹配上的词的累计权重。具体的,利用预训练语言模型,将查询或商品编码为一个高维的向量,维度大小等于词表的大小,每一维表示词的权重。
以上方法有两个问题:1)如何将表示的每一维与特定的词对应起来;2)维度扩大带来的计算和存储上的问题。如何解决这俩挑战:
- 通过模型结构和损失函数的设计,将表示的维度与词对齐。
- 在损失函数中增加稀疏约束,降低高维表示中的有效位置。
- 对高维表示进行采样降低表示用到的词数。
具体实现:
- 训练两个编码器,分别从字符粒度和词粒度对输入文本进行编码,如下图的Character Encoder和Word Encoder。
- 扩展了词表(原文是"N-gram Hashing Vocabulary")。
- 根据编码的结果,构建BoW表示。如下图的Term-Weighting Bow和Synonym-Expansion Bow表示。Bow表示即将输入的文本进行词袋表示:\(\\\{w_i : p_i\}\)。重点是如何计算每个词的权重,具体细节不赘述。其中Synonym-Expansion Bow即对输入文本进行扩展,避免一些同义、表述不一致的问题。可以看作是补充了词袋模型的语义功能。
- 损失函数看起来比较常规,没啥好讲的。此外,还用人工标注数据训练了一个交互式的模型,作为教师模型进行蒸馏。

论文的实验表明,即使使用2层的模型效果依然很好。
看这篇论文的效果倒是挺好的,而且也部署在了淘宝的线上系统,不知道如果用于召回的话可行不。
Understanding the Ranking Loss for Recommendation with Sparse User Feedback
- <li>https://arxiv.org/pdf/2403.14144,KDD 2024,Tencent.
概述:
论文探讨了在稀疏用户反馈情况下,结合排名损失和二元交叉熵损失在推荐系统中的有效性。研究的动机在于:
- 如何在正样本(如点击)稀疏的情况下优化模型以提高CTR准确性。
- 为何结合交叉熵和排名损失能够提升CTR预测的性能。
论文揭示了在用户反馈稀疏时:交叉熵损失容易导致负样本的梯度消失问题,而排名损失能够为负样本生成更大的梯度,从而缓解了模型学习过程中的优化问题。论文通过理论分析和在公开数据集上的实验验证了这一观点,并在腾讯在线广告系统中部署了排名损失,取得了显著的商业价值提升。
直接揭晓答案:交叉熵损失的优化曲面相对平缓(如下图),在正样本稀疏的情况下梯度一般都比较小,所以存在收敛速度慢、收敛效果不够好的问题,而结合排名损失后优化曲面更“凸”,正好解决了该问题。
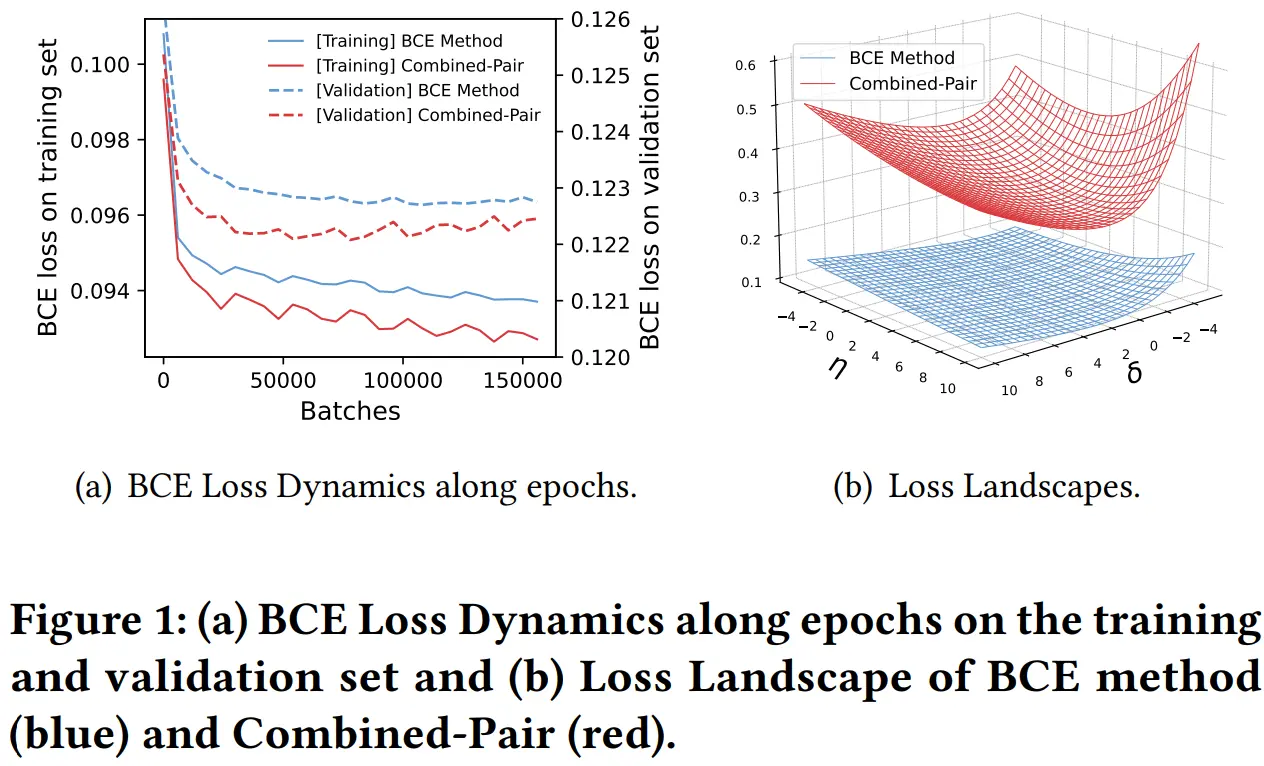
简单说一下理论分析:过求损失函数对正/负样本的logits的梯度,可以看出交叉熵下负样本的梯度的均值与样本集中的CTR接近,而在稀疏场景下CTR一般都很小,具体的分析见论文,不赘述。
另外说一下论文中讨论的排名损失基本是pair形式的。直观地来说,正负样本组pair能够增大梯度是正常的?
Unsupervised Ranking Ensemble Model for Recommendation
- <li>KDD 2024,Kuaishou.
看题目就知道了,排序继承(融合)模型,即如何把多个序融合成一个序。虽然没找到这篇论文的PDF版本,但是根据摘要和放出的报告视频,感觉还有点意思,还挺符合线上的融合排序的场景的—— 集成多个分进行排序。
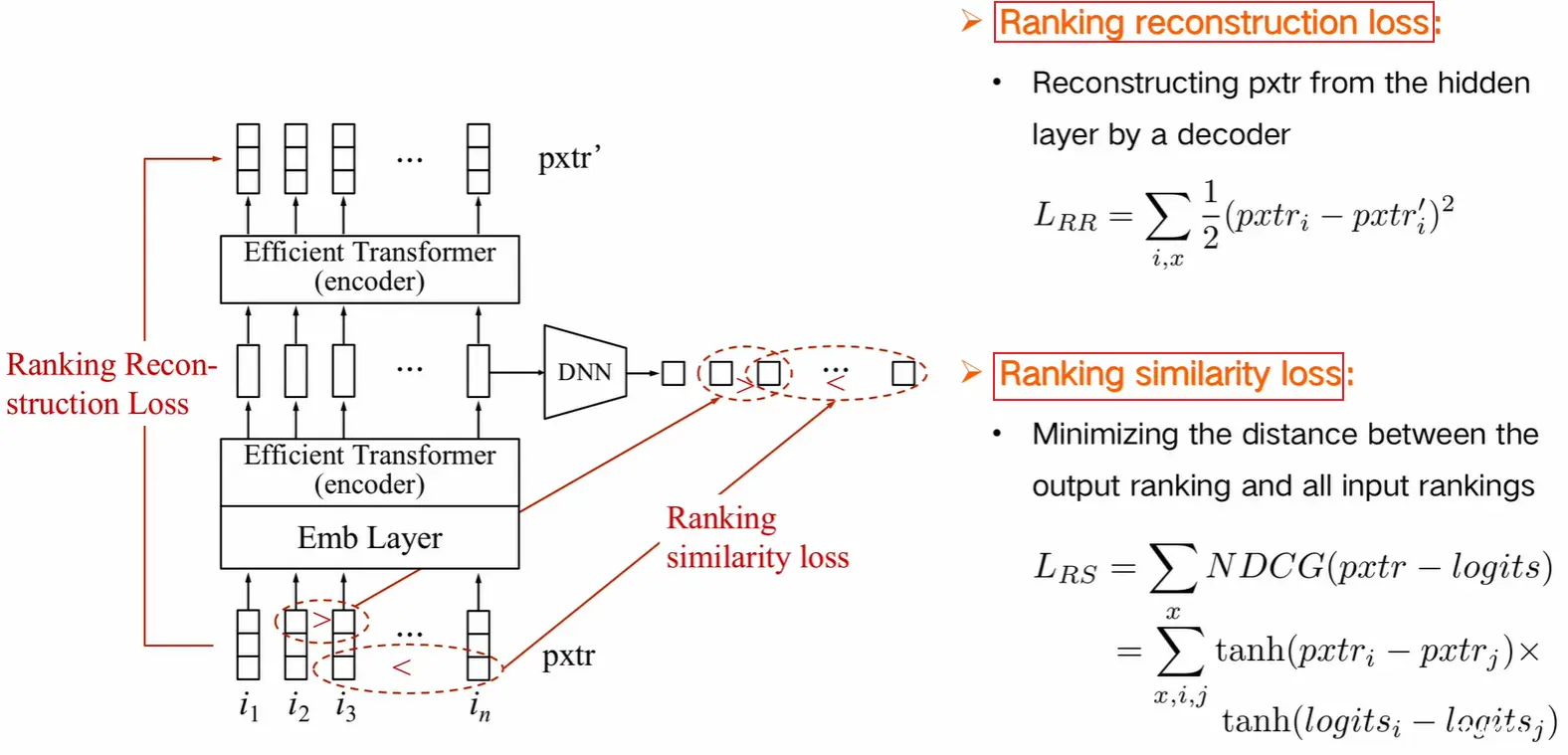
实际场景中,通常会有多个打分模型,每个模型通常代表一个指标,如点击、喜欢、收藏等。当然,如果有一个最终序的监督信号,可以直接用这个信号融合这些分,但是往往这种最终的监督信号是缺失的。因此,论文提出了一个无监督的方法集成多个排序模型,来学习多个序的信息。
具体来说,主要学习多个序的两种信息:1)序列信息,衡量两个序之间的距离,使最终的序和输入的多个序之间的距离最小;2)数值信息,使模型能够学习到原来序的打分信息。论文提出的方法内容可以参考下图,应该也是基于变形金刚做的(?),等论文出来再看看细节:
Non-autoregressive Generative Models for Reranking Recommendation
- <li>https://arxiv.org/pdf/2402.06871,KDD 2024,Kuaishou.
这篇论文提出了一种非自回归生成式的推荐重排模型,NAR4Rec。研究动机主要针对现有自回归模型的以下问题:
- 只能逐个地生成结果,推理速度慢。
- 训练与推理之间的不一致性问题。这个乍一看没看明白,原来就是指生成模型训练和推理时不一致的问题。
训练时:基于已有的序列预测下一个token。
推理时:基于之前生成的序列预测下一个token。
- 自左向右地生成顺序忽视了后生成结果的信息,导致次优。
针对这些问题,论文提出了NAR4Rec:
- 能够同时生成目标序列中的所有项,从而提高效率和有效性。
- 介绍了一种匹配模型来解决训练样本稀疏和动态候选项对模型收敛性的影响,以及一种序列级非似然训练目标和对比解码方法,以捕捉目标项之间的相关性。
在正式介绍之前,先看下自回归和非自回归的区别:

再看下重排。描述一下重排任务:从n个候选结果中排列出m个物品。重排的两类典型方法:
- <li>单阶段方法。就是给定一个结果列表,在此基础上为每个结果打分,再依据打分按照贪心的策略重排这些结果。问题:打分只考虑了初始的序,但是重排过程中序以及发生变化,打分可能已经不准确。
- 双阶段方法。采用生成器-评估器框架,生成器生成多个可行的序,评估器对序打分以选择最优序列。
这么看,本文的方法应该是双阶段的,NAR4Rec框架如下:
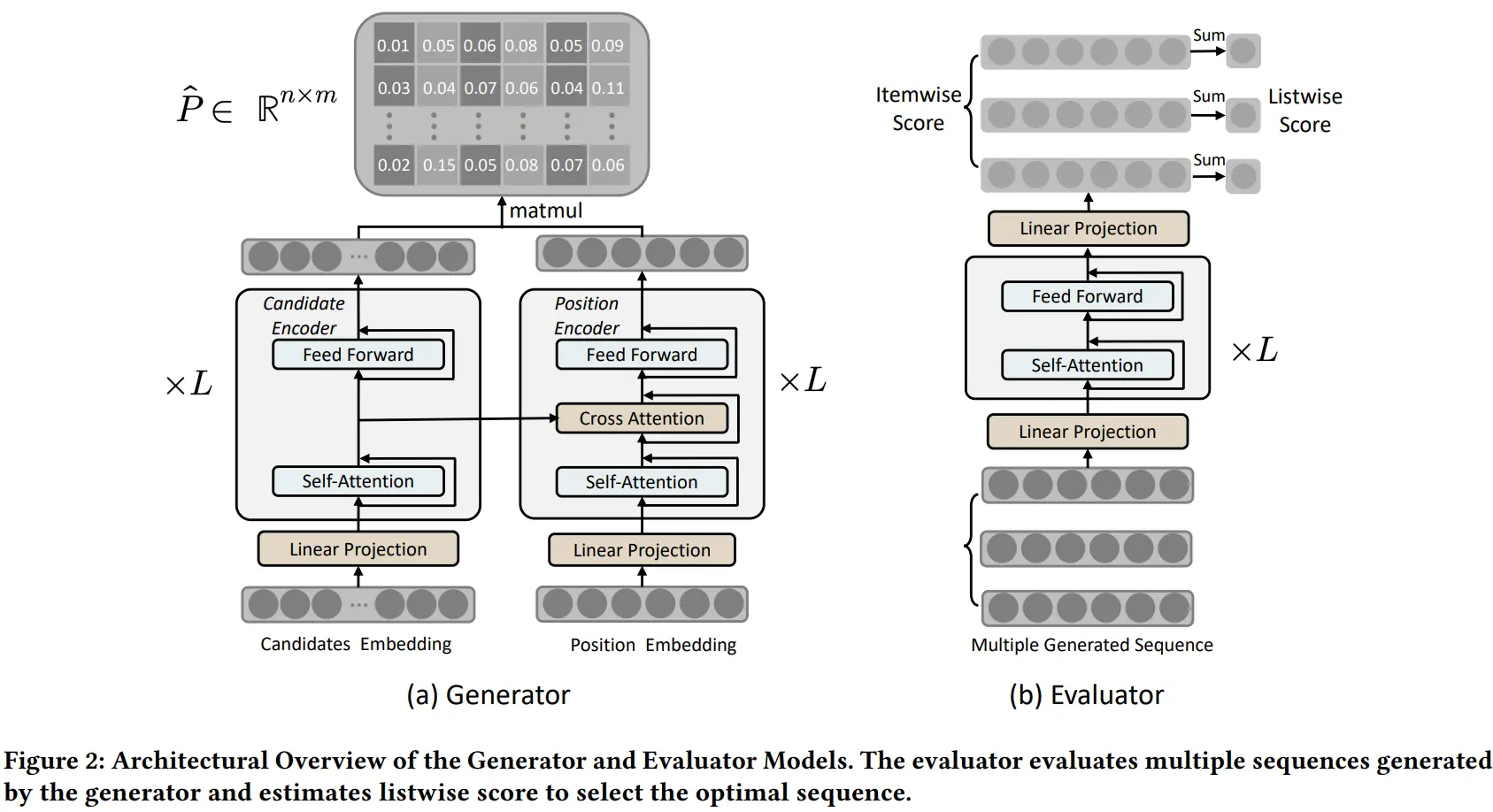
简单介绍一下:
- <li>左边的是生成器。由候选物品编码器和位置编码器组成。位置编码器不是位置编码,而是重排输出的每个位置的编码。生成器的输出是一个n*m的矩阵,(i, j)表示把第i个候选物品放在重排输出的第j个位置的概率。关于如何根据输出的矩阵解码得到重排序列,可参考论文(主要是没时间细读😀)。
- 右边是评估器,即对生成的序列打分。很显然,也是一个类似变现金刚的结构,重排序列作为输入进行listwise的打分,不赘述。不过论文好像也没提评估器是怎么训练的?
整体看下来,感觉比较精妙的应该是把重排的每个槽位作为输入,计算候选物品在每个位置的概率了。
看实验,论文的方法离线和线上都提升挺多的。
Multi-objective Learning to Rank by Model Distillation
- https://arxiv.org/pdf/2407.07181,KDD 2024,Airbnb.
一直听说爱彼迎的论文干货满满了,这次必须好好学习一下。
论文探讨了在线市场(如Airbnb)中搜索排名面临的挑战,即如何在提高购买或转化率(主要目标)的同时,也优化购买结果(次要目标),例如订单取消、评价评级等。
论文中讨论的多目标方案是:一个模型,预测多个目标,训练时每个目标的损失加权作为最终的损失,推理时融合多个打分作为最终打分。这种方法的参数可分成两部分:1)为每个目标打分的参数,即共享参数和任务参数;2)融合多个打分的参数。实际场景中,这种方式也是比较合理的,多目标可能是各自优化的,模型既有共有的参数也有任务特有的参数,迭代时可能只优化一部分。因此会把多目标模型尽量解耦,比如共有参数、目标特有参数、融合参数等。
多目标L2R的挑战:
- 参数调优复杂。其中包括上述提到的两部分参数之间的不适配问题,比如模型损失收敛很好了,但是融合多个目标的分数可能不适用了。
- 数据的不平衡和冲突问题。不同目标的数据稀疏程度不一致,目标间的相关性可能不高等。
- 有些目标是不可导的。
论文提出了一种基于模型蒸馏的多目标排名解决方案,优化了Airbnb的端到端排名系统,包括多个不同目标的排名模型,并考虑了训练和服务效率,以满足工业标准。研究发现,与传统方法相比,所提出的方法不仅显著提高了主要目标,而且满足了次要目标的约束,并提高了模型的稳定性。此外,论文还展示了该系统可以通过模型自我蒸馏进一步简化,并通过额外的模拟表明,这种方法还可以有效地将非微分的业务目标注入排名系统,同时平衡优化目标。
针对以上问题,论文的贡献如下:
- 模型蒸馏:将多目标LTR问题转化为模型蒸馏问题,通过训练一个模型来优化多个目标,并逼近每个目标的独立优化解,且不需要为线上融合多个目标打分调参。
- 软标签概念:引入软标签来减少模型不可再生性,并通过自我蒸馏软标签来简化排名系统。
- 非微分目标的整合:通过修改软标签,将非微分业务目标有效地整合到排名模型中。
论文里从公式的角度推导了一下:一个主目标加多个辅助目标约束的优化等价于主目标加蒸馏损失:
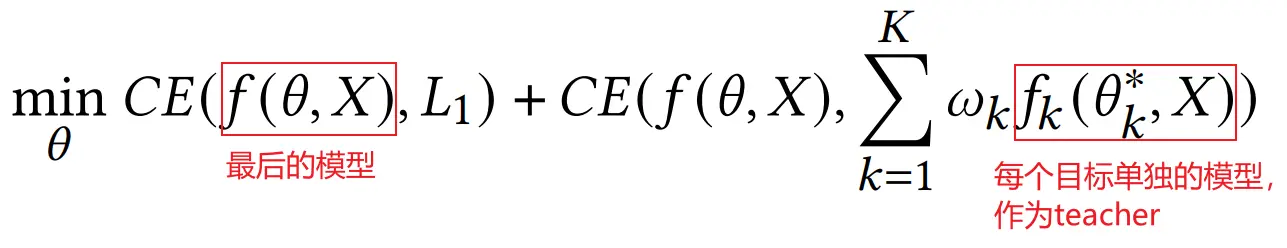
最后的结论就是:每个目标一个单独模型进行优化,然后一起蒸馏到一个模型里,如下图:
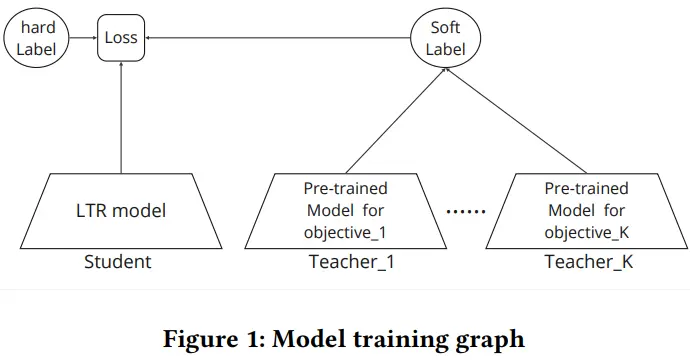
(从工程量来说,感觉还是得训练多个模型😂)论文中还有一些实践中的经验,不赘述。
Mitigating Pooling Bias in E-commerce Search via False Negative Estimation
- https://arxiv.org/pdf/2311.06444,KDD 2024.
论文探讨了电子商务搜索中的产品相关性评估问题,在训练相关性评估模型时经常出现pooling bias(即采样到假阴样本,第一次看到这种叫法)问题。针对这一问题,论文提出了一种减轻偏差的难负样本采样方法(Bias-mitigating Hard Negative Sampling,BHNS),识别假阴样本以提升数据质量。
方法包括:
提出了False Negative Estimation指标,评估假阴样本的似然性(等价于样本是正样本的概率?左右互搏?)。基于一个假设:query之间相似度越高,越可能共享正样本。计算方式如下:
li>
根据估计的假阴概率,通过两种方式减小pooling bias。第一种:Sampling Regularization,思想很简单:假阴概率越大,被采样为难负样本的概率越小。
li>
第二种:Pseudo Label Generation。把假阴概率作为难分负样本的伪标签。
假阴样本确实是模型训练中的一个经典问题了。这论文的思想还是挺简单的,以后可以试试。
总结
文章的标题起的不太对,不是速读,是慢读😐
以前看论文有点贪多,经常是通篇读下来,想了解论文里的每个细节,不小心就花了大把时间。或许是心态不一样,也没有针对性地看论文。工作后看论文,更多是了解一下别人的工作,学习学习。也不会过多纠结于一些细节,主要了解一下论文的思路,毕竟不同场景下方法、策略的表现不一样,实践过程中也有差别,重要的还是开拓一下思路。

第一次看到北京这么好的天
上一篇: AI表情神同步!LivePortrait安装配置,一键包,使用教程
下一篇: 使用世界领先的 Qwen2.5-Math 开源模型当 AI 数学老师,让奥数解题辅导不在鸡飞狗跳(文末有福利)
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。