改进yolov8|FasterNet替换主干网络,跑得飞快!!
干饭王也敲代码 2024-08-11 13:07:02 阅读 51
改进yolov8|FasterNet替换主干网络,跑得飞快!!
一、FasterNet简介论文地址代码地址论文内容(原创整理)前述贡献具体显著效果
改进过程FasterNet核心代码(添加到ultralytics/nn/modules/block.py):并在ultralytics/nn/modules/block.py中最上方“_all_”中引用‘BasicStage’, 'PatchEmbed_FasterNet', 'PatchMerging_FasterNet'在ultralytics/nn/modules/__init__.py中在 ultralytics/nn/tasks.py 上方在parse_model解析函数中添加如下代码:在 ultralytics/nn/tasks.py 中的self.model.modules()后面添加
在ultralytics/cfg/models/v8文件夹下新建yolov8-FasterNet.yaml文件
运行即可
各位哥哥姐姐弟弟妹妹大家好,我是干饭王刘姐,主业干饭,主业2.0计算机研究生在读。
和我一起来改进yolov8变身计算机大牛吧!
本文中的论文笔记都是刘姐亲自整理,原创整理哦~
一、FasterNet简介
论文地址
https://export.arxiv.org/pdf/2303.03667v1.pdf
代码地址
https://github.com/JierunChen/FasterNet
论文内容(原创整理)

前述
提出了一种新的部分卷积(PConv),更有效地提取空间特征,同时减少冗余计算和内存访问。MobileNets,ShuffleNets 和GhostNet 等利用 dependency卷积(DWConv)和/或组卷积(GConv)来提取空间特征。然而,在努力减少FLOP的过程中,操作员经常遭受增加的存储器访问的副作用。MicroNet 进一步分解和稀疏化网络,将其FLOP推到极低的水平。延迟Latency = FLOPs/FLOPS, FLOPS是每秒浮点运算的缩写,作为有效计算速度的度量。本文旨在通过开发一种简单而快速有效的运算符来消除这种差异,该运算符可以在降低FLOPs的情况下保持高FLOPS。从本质上讲,PConv具有比常规Conv更低的FLOPS,而具有比DWConv/GConv更高的FLOPS。换句话说,PConv更好地利用了设备上的计算能力。基于DWConv
贡献
指出了实现更高FLOPS的重要性,而不仅仅是为了更快的神经网络而减少FLOPS。·引入了一个简单而快速有效的算子PConv,它很有可能取代现有的首选项DWConv。·推出FasterNet,它可以在GPU,CPU和ARM处理器等各种设备上顺利运行,速度普遍很快。·对各种任务进行了广泛的实验,并验证了PConv和FasterNet的高速和有效性。
具体
它只是在一部分输入通道上应用常规Conv进行空间特征提取,其余通道保持不变。PConv的FLOPs为:hwkkcp*cp。内存访问量:hw2cp+kkcpcp。PConv后接PWConv(逐点卷积)FasterNet,这是一种新的神经网络家族,运行速度快,对许多视觉任务非常有效。

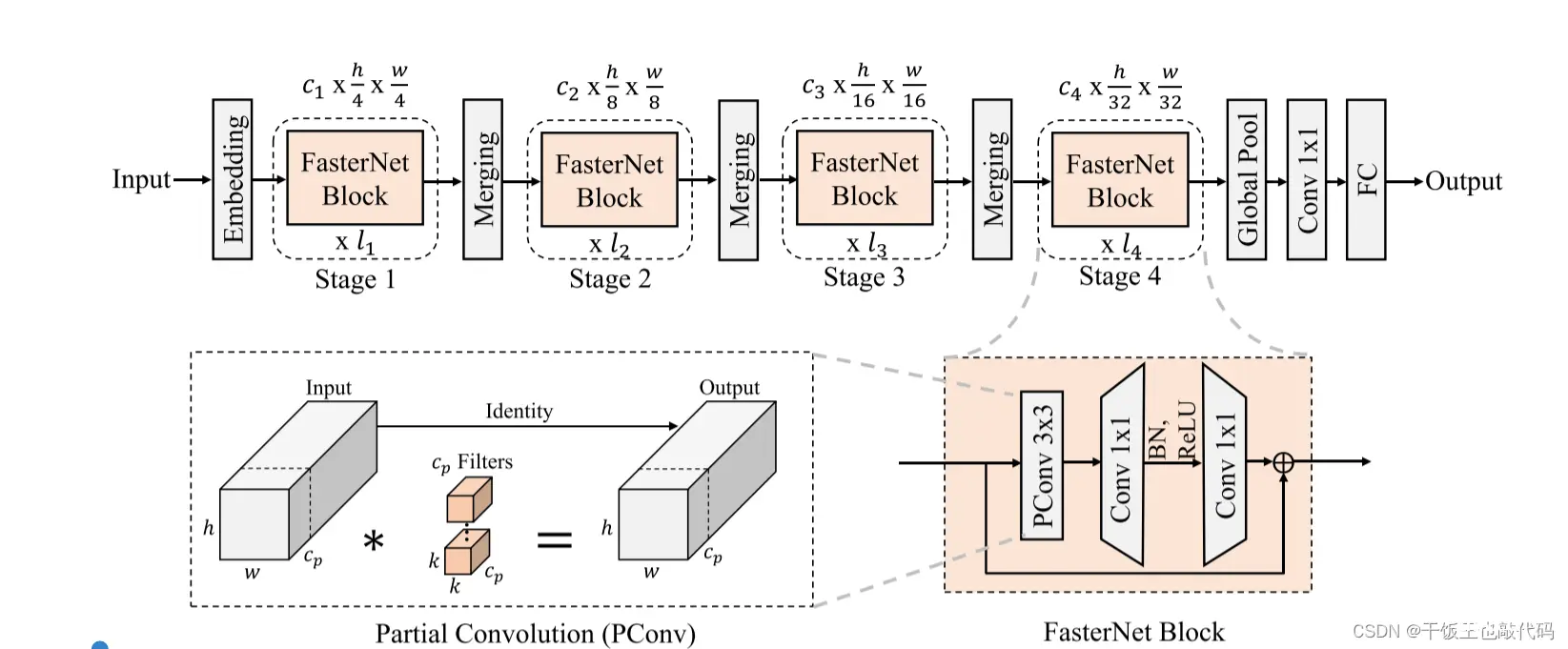
显著效果
时间提高巨大50%+,GFLOPs减少60%+
改进过程
FasterNet核心代码(添加到ultralytics/nn/modules/block.py):
<code># --------------------------FasterNet----------------------------
from timm.models.layers import DropPath
class Partial_conv3(nn.Module):
def __init__(self, dim, n_div, forward):
super().__init__()
self.dim_conv3 = dim // n_div
self.dim_untouched = dim - self.dim_conv3
self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)
if forward == 'slicing':
self.forward = self.forward_slicing
elif forward == 'split_cat':
self.forward = self.forward_split_cat
else:
raise NotImplementedError
def forward_slicing(self, x):
# only for inference
x = x.clone() # !!! Keep the original input intact for the residual connection later
x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])
return x
def forward_split_cat(self, x):
# for training/inference
x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)
x1 = self.partial_conv3(x1)
x = torch.cat((x1, x2), 1)
return x
class MLPBlock(nn.Module):
def __init__(self,
dim,
n_div,
mlp_ratio,
drop_path,
layer_scale_init_value,
act_layer,
norm_layer,
pconv_fw_type
):
super().__init__()
self.dim = dim
self.mlp_ratio = mlp_ratio
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.n_div = n_div
mlp_hidden_dim = int(dim * mlp_ratio)
mlp_layer = [
nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),
norm_layer(mlp_hidden_dim),
act_layer(),
nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)
]
self.mlp = nn.Sequential(*mlp_layer)
self.spatial_mixing = Partial_conv3(
dim,
n_div,
pconv_fw_type
)
if layer_scale_init_value > 0:
self.layer_scale = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.forward = self.forward_layer_scale
else:
self.forward = self.forward
def forward(self, x):
shortcut = x
x = self.spatial_mixing(x)
x = shortcut + self.drop_path(self.mlp(x))
return x
def forward_layer_scale(self, x):
shortcut = x
x = self.spatial_mixing(x)
x = shortcut + self.drop_path(
self.layer_scale.unsqueeze(-1).unsqueeze(-1) * self.mlp(x))
return x
class BasicStage(nn.Module):
def __init__(self,
dim,
depth=1,
n_div=4,
mlp_ratio=2,
layer_scale_init_value=0,
norm_layer=nn.BatchNorm2d,
act_layer=nn.ReLU,
pconv_fw_type='split_cat'code>
):
super().__init__()
dpr = [x.item()
for x in torch.linspace(0, 0.0, sum([1, 2, 8, 2]))]
blocks_list = [
MLPBlock(
dim=dim,
n_div=n_div,
mlp_ratio=mlp_ratio,
drop_path=dpr[i],
layer_scale_init_value=layer_scale_init_value,
norm_layer=norm_layer,
act_layer=act_layer,
pconv_fw_type=pconv_fw_type
)
for i in range(depth)
]
self.blocks = nn.Sequential(*blocks_list)
def forward(self, x):
x = self.blocks(x)
return x
class PatchEmbed_FasterNet(nn.Module):
def __init__(self, in_chans, embed_dim, patch_size, patch_stride, norm_layer=nn.BatchNorm2d):
super().__init__()
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_stride, bias=False)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = nn.Identity()
def forward(self, x):
x = self.norm(self.proj(x))
return x
def fuseforward(self, x):
x = self.proj(x)
return x
class PatchMerging_FasterNet(nn.Module):
def __init__(self, dim, out_dim, k, patch_stride2, norm_layer=nn.BatchNorm2d):
super().__init__()
self.reduction = nn.Conv2d(dim, out_dim, kernel_size=k, stride=patch_stride2, bias=False)
if norm_layer is not None:
self.norm = norm_layer(out_dim)
else:
self.norm = nn.Identity()
def forward(self, x):
x = self.norm(self.reduction(x))
return x
def fuseforward(self, x):
x = self.reduction(x)
return x
并在ultralytics/nn/modules/block.py中最上方“all”中引用‘BasicStage’, ‘PatchEmbed_FasterNet’, ‘PatchMerging_FasterNet’
在ultralytics/nn/modules/init.py中
from .block import (....,BasicStage,PatchEmbed_FasterNet,PatchMerging_FasterNet)
在 ultralytics/nn/tasks.py 上方
from ultralytics.nn.modules import (....BasicStage, PatchEmbed_FasterNet, PatchMerging_FasterNet)
在parse_model解析函数中添加如下代码:
if m in (... BasicStage, PatchEmbed_FasterNet, PatchMerging_FasterNet):
和
elif m in [BasicStage]:
args.pop(1)
在 ultralytics/nn/tasks.py 中的self.model.modules()后面添加
if type(m) is PatchEmbed_FasterNet:
m.proj = fuse_conv_and_bn(m.proj, m.norm)
delattr(m, 'norm') # remove BN
m.forward = m.fuseforward
if type(m) is PatchMerging_FasterNet:
m.reduction = fuse_conv_and_bn(m.reduction, m.norm)
delattr(m, 'norm') # remove BN
m.forward = m.fuseforward
在ultralytics/cfg/models/v8文件夹下新建yolov8-FasterNet.yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, PatchEmbed_FasterNet, [40, 4, 4]] # 0-P1/4
- [-1, 1, BasicStage, [40, 1]] # 1
- [-1, 1, PatchMerging_FasterNet, [80, 2, 2]] # 2-P2/8
- [-1, 2, BasicStage, [80, 1]] # 3-P3/16
- [-1, 1, PatchMerging_FasterNet, [160, 2, 2]] # 4
- [-1, 8, BasicStage, [160, 1]] # 5-P4/32
- [-1, 1, PatchMerging_FasterNet, [320, 2, 2]] # 6
- [-1, 2, BasicStage, [320, 1]] # 7
- [-1, 1, SPPF, [320, 5]] # 8
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 5], 1, Concat, [1]] # cat backbone P4
- [-1, 1, C2f, [512]] # 11
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 3], 1, Concat, [1]] # cat backbone P3
- [-1, 1, C2f, [256]] # 14 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P4
- [-1, 1, C2f, [512]] # 17 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 8], 1, Concat, [1]] # cat head P5
- [-1, 1, C2f, [1024]] # 20 (P5/32-large)
- [[14, 17, 20], 1, Detect, [nc]] # Detect(P3, P4, P5)
运行即可
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。