arthas实战
hu020138 2024-10-03 10:37:02 阅读 98
Arthas 是一款线上监控诊断产品,通过全局视角实时查看应用 load、内存、gc、线程的状态信息,并能在不修改应用代码的情况下,对业务问题进行诊断,包括查看方法调用的出入参、异常,监测方法执行耗时,类加载信息等,大大提升线上问题排查效率。
讲几个比较常用的指令
<code>(1)dashboard 默认采样时间5000ms
查看当前系统的实时数据面板,包括thread memory cpu runtime environment GC等信息
dashboard -n 2 表示闪烁两次
dashboard -i 1000 表示每秒闪烁一次
默认是5S,一直闪烁
(2)thread 默认采样时间200ms
查看该进程的线程堆栈信息
thread -b, 找出当前阻塞其他线程的线程
thread -n 3 找出200ms内,最忙的三个线程
thread指令 展示的线程和dashboard指令 看到的类似,但是会打印jvm线程堆栈明细
(3)trace 跟踪方法耗时
(4)watch 函数执行数据观测,包括观察方法的入参、返回体、抛出异常等
甚至还可以观测到方法所在类(对象)的成员变量属性!
(5)heapdump指令 和java的jmap指令类似
(6)arthas下的 jvm指令
和 jstat -gcutil pid 10
jmap -heap pid
jps -v 类似功能,
查看垃圾回收器 垃圾回收次数耗时 jvm启动参数等
今天先讲一个指令 :dashboard 指令、thread指令
dashboard 指令、thread指令
在接入层服务的cmd(类似spring的controller)中,实际写了个死循环代码(开平方根的计算),每调用一次cmd就会触发一次高cpu利用率的操作。
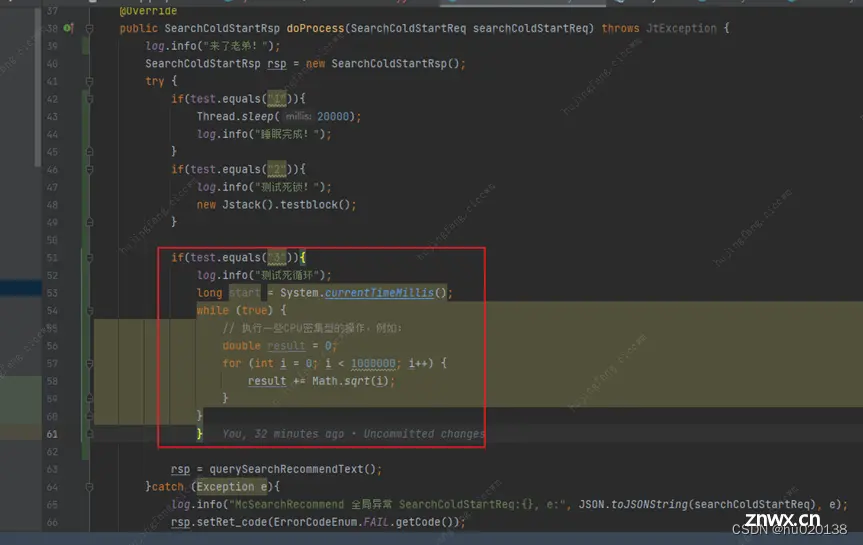
使用arthas指令dashboard,发现cpu最多达到100%(因为一个线程同一时间最多只能占用一个processor,不会超过100%,但是top指令却可以超过100%,因为进程的cpu是可以超过100%的)
注意dashboard要观察第二次采样,第一次采样往往有偏差(thread指令就不用,因为统计的是200ms期间,而dashboard的第一闪是瞬间的,所以存在不准确的问题)
DELTA_TIME表示的是本次采样(默认5S)这个线程一共占用pending了多长的时间,
TIME表示的是该线程运行的总CPU时间,历史以来的,因线程池线程会复用, 这个指标的参照意义不大。
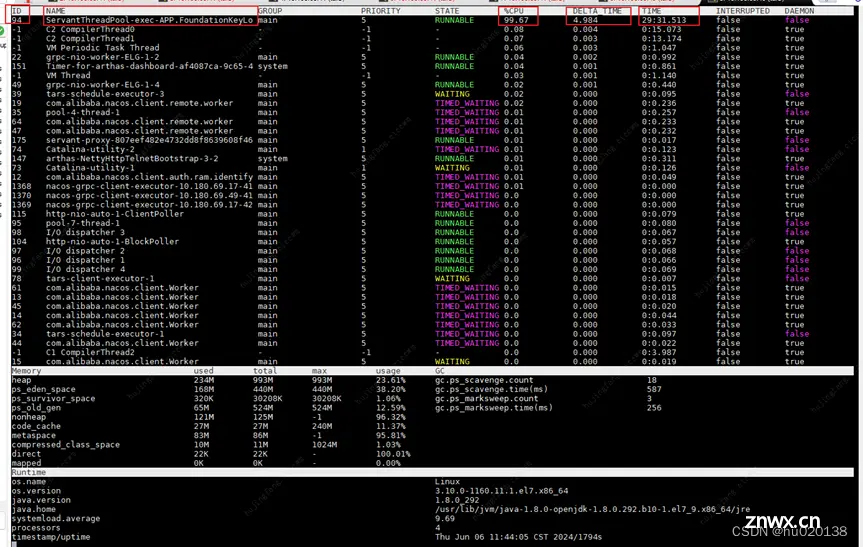
再使用arthas指令thread -n 3,可以观察到最忙的线程就是它,并且可以打印出来线程的堆栈信息,指标中的
delta_time和time,和dashboard指令的指标含义是相同的,并且可以看到这个线程的状态是Runnable的。
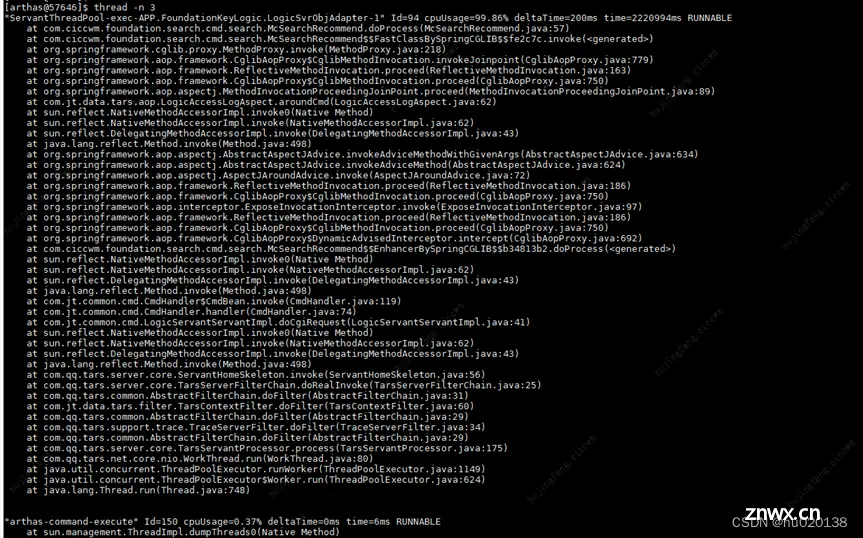
使用指令:thread -b,发现没有线程阻塞的情况发生:
因为这个线程是Runnable状态的

用linux top指令也可以看到该线程所属java服务的cpu达到了100,并且可以超过100:
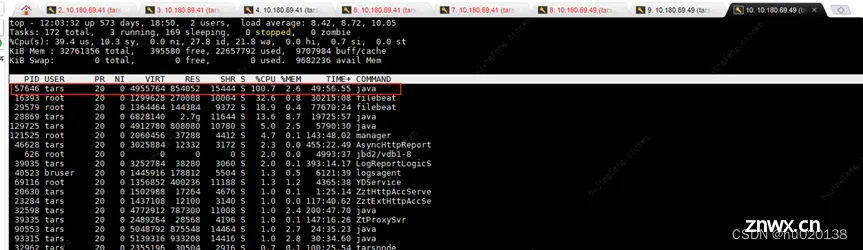
以上基本可得出结论:arthas的thread dashboard和linux的top指令,在统计的原理上 是比较类似功能的。
再调用一次这个cmd,发现此时就有两个线程占cpu达到了100%(说明每个线程执行是占用一个cpu的),观察top指令也会发现,此时该进程pid已经达到了200%,再次说明:在进程级别cpu利用率是可以100%,你如果一直请求cmd的话,会把cpu资源耗尽。


再来看一个例子:
在接入层服务的cmd中,执行死锁的代码,调用第一次cmd就会触发死锁操作,后续调用cmd会触发其他线程blocked在synchronized的对象锁上
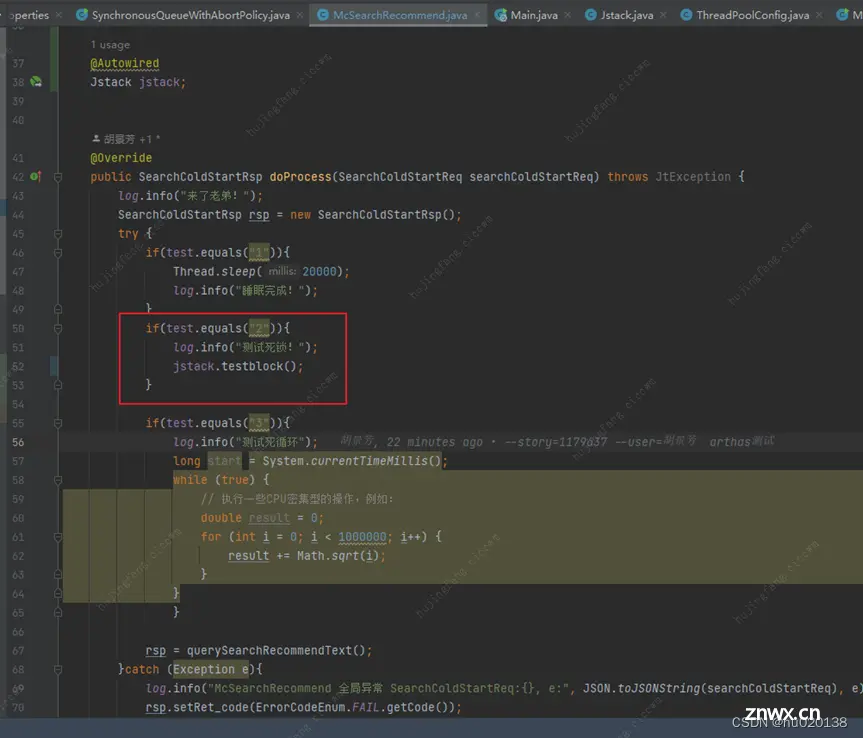
死锁后查看cpu情况,发现该进程几乎不占用cpu,所以这种情况下的死锁并不会导致cpu的飙高:
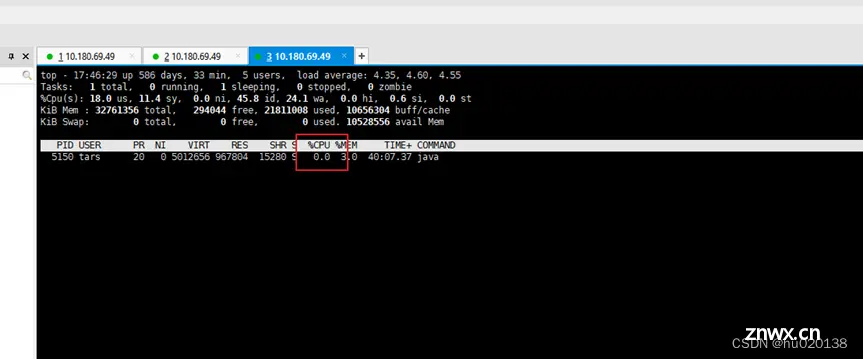
而某些数据库的死锁往往是导致 cpu飙高, 这可能是因为他在自旋操作,但是java的死锁更多的是锁等待,线程会让出cpu的调度权力
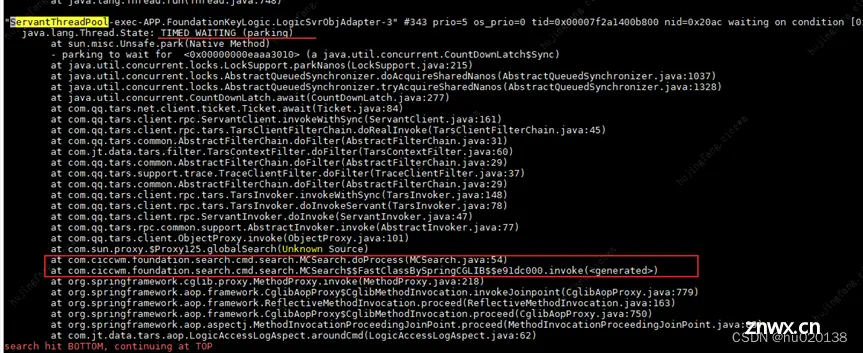
在arthas工具下执行thread -b :
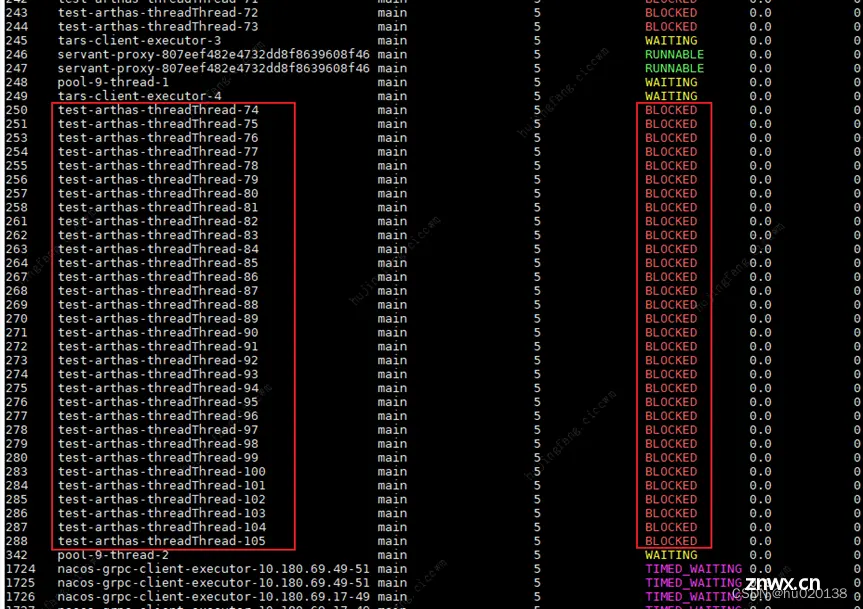
可以看到,只有一个死锁的发生, 但是该锁已经已经阻塞BLOCKED了38个线程了,官方文档也有介绍:

而从thread --all也可以看出来,BLOCKED WAITING TIMED_WAITING 颜色较深,需要引起足够重视,而 NEW 、TERMINATED 、RUNNABLE都是比较健康的线程状态。

thread --state BLOCKED 这个指令 则是可以查询所有的BLOCKED状态的线程,
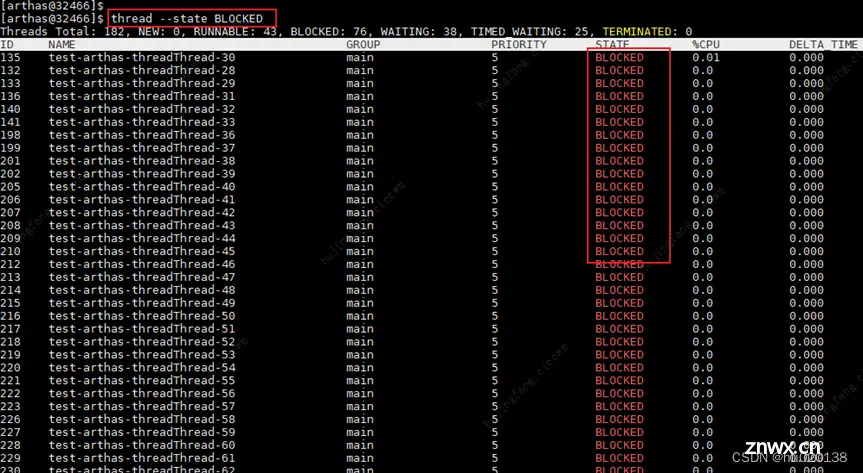
再通过jvm的指令 jstack pid,也同样可以看到对应的BLOCKED状态的线程

如果是排查线程死锁的问题的,服务卡死的问题,jstack指令也是够用的。一般建议
Jstack pid >>hello.txt 将线程栈的信息打印到文件中,再用vi指令进行检索。而一般线上服务假死问题,基本因为BLOCKED线程引起的
BLOCKED都是synchronized的状态,java的 Lock并不是BLOCKED
写代码demo测试Lock的线程状态,到处堆栈信息

上图第二个是TIMED_WAITING(sleeping状态,比如调用Thread.sleep)
第一个是WATING(parking)状态,是竞争Lock锁失败,最终调用LockSupport.park,所以是parking状态
再过段时间后,对应线程池的线程都已经没有任何任务执行了,再次导出jstack pid >> test.txt vi查看发现:
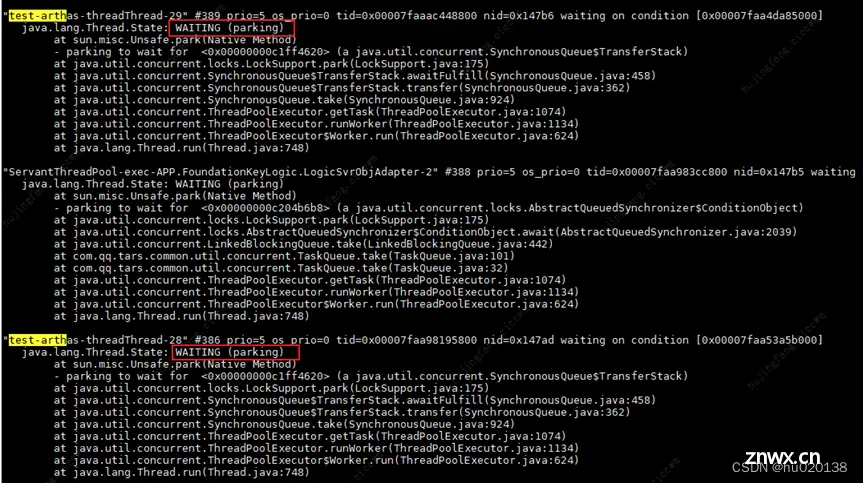
可以发现,以上两个线程,都变成WAITING(parking)状态,但是和上上图的WAITING(parking)状态不同的是,之前是WAITING在业务Lock上,而现在是WAITING线程池的队列上(线程池的原理:核心线程执行完任务后,最终不会被回收,而是等待在队列上)
一般性结论:WAITING 或者TIMED_WAITING状态问题相对没那么严重,重点要关注的线程是BLOCKED状态的线程,因为WAITING 状态一般是人为主动的操作(人为的主动加锁,解锁),而BLOCKED基本都是隐式加锁更容易出现问题。
如果线程调用外部IO,外部服务耗时很严重,该线程呈现为什么状态?
设计代码,编写demo,外部服务pending 100S期间,查看堆栈信息发现:

从线程栈可以看出该线程的状态是TIMED_WAITING状态(一些人说调用外部服务IO peding期间 , 调用端线程是 RUNNABLE状态,是错误的,RUNNABLE是占用CPU的,而IO peding 阻塞期间, 是不占用cpu时间片的)
而对于其他编号的ServantThreadPool线程,则可以看到状态是WAITING状态,这个也是线程池复用的结果:

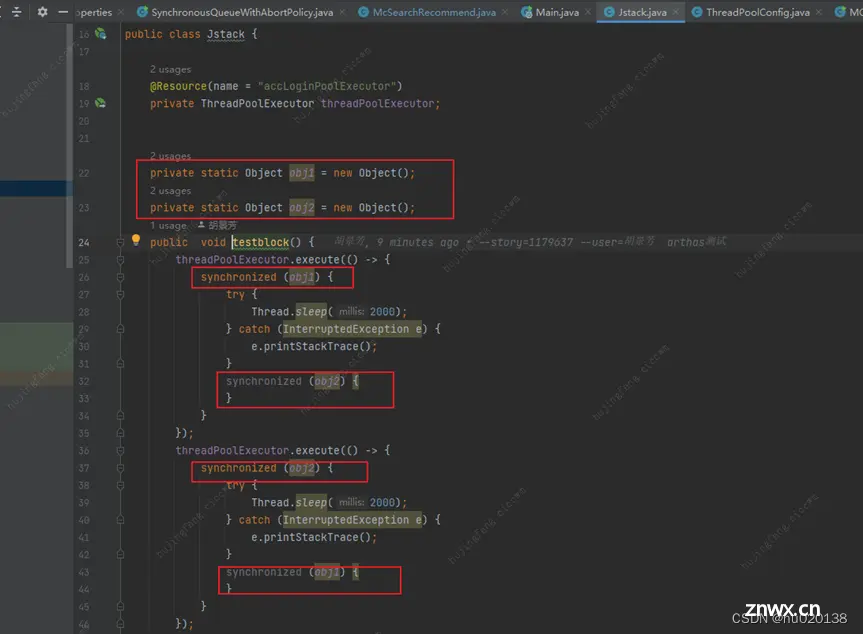
经验总结:后续排查线上问题,这些WAITING状态的并且线程栈中没有出现业务代码的,基本是可以不看的,因为它不可能是问题的原因。线上问题的原因,绝大部分是由业务代码引起的。一句话总结:问题的原因绝大部分是隐藏在业务代码中,别总怀疑框架、中间层问题(虽然fastjson log4j啥确实也有一些漏洞啥的。。。)
其他问题:
(1)线程池的核心线程,在未达到corepoolsize前,可以复用吗? 还是来一个线程,创建一个?
解答:无论从 业务层面线程池内的线程 test-arthas-threadThread-xx 还是从框架层面的
ServantThreadPool-exec-APP.FoundationKeyLogic.LogicSvrObjAdapter-xx
来看,都是会一直创建线程,直到线程数量 达到了corepoolsize前,才会实现复用,这个在线程池的源码层次看也是这样子的。
(2)线程池的线程执行任务异常了,会怎么样?
状态变成TERINATED,后续被垃圾回收掉, 并且线程池会重新补足一个,如果是核心线程,那本来新任务来了就会先创建一个。
(3)线程池如何实现复用的?
jdk源码层面,每个Runnable都被包装成了Worker,其中有个死循环实现了该thread的复用,死循环代码中会一直从阻塞队列中poll和take,而这两个方法底层基于LockSupport的park和unPark操作,类似于object.wait和notifyAll方法。
核心:死循环loop的方式+阻塞队列的方式,实现线程池中线程的复用
可以参考:https://www.cnblogs.com/wupeixuan/p/13285055.html

从整体上看,这是一种职责分离的设计思想,Worker 是 Worker,任务是任务,它俩没必要纠缠在一起。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。