C++:位图和布隆过滤器
✿༺小陈在拼命༻✿ 2024-07-12 09:35:02 阅读 97

一,位图
1.1 位图的概念
究竟什么是位图呢??我们用一道问题来引入
问题:给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在
这40亿个数中。【腾讯】
根据这个问题,我们可以用什么方法来解决呢???我们可以很迅速地想到一下方法:
方法1:排序+二分查找
方法2:将整数丢进哈希表或者红黑树中
看似好像都能解决这个问题,但是我们来审视一下这个问题的关键——内存
1G=1024MB=1024*1024KB=1024*1024*1024Byte 约等于10亿Byte,也就是说40亿个数大约需要16G内存!!没有办法将数据一次性放到内存去处理。
(1)分析方法1:如果我们将数据分在不同的文件里,我们可以用归并排序去完成文件之间的排序,但是无法使用二分查找法,因为没有办法通过下标去直接访问元素!!!
(2)分析方法2:问题就是所需要的内存太大了,光是数据就16G了,更何况红黑树和哈希表的底层的封装还需要一定的损耗,我们如果要使用的话也只能是一部分一部分丢进容器,然后再删掉丢下一部分,这样一方面的问题是我们其实在一开始丢进容器的时候就可以去做比对了,没有必要丢到容器里,另一方面的问题就是不适应需要多次查找比对的场景。
因此上面两种方法都是不太现实的,但是有一种数据结构可以帮助我们解决这个问题,那就是位图——通过哈希函数中的直接定址法确定整型在不在的模型(就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。)
所以方法3:用位图去解决
数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0代表不存在。比如:
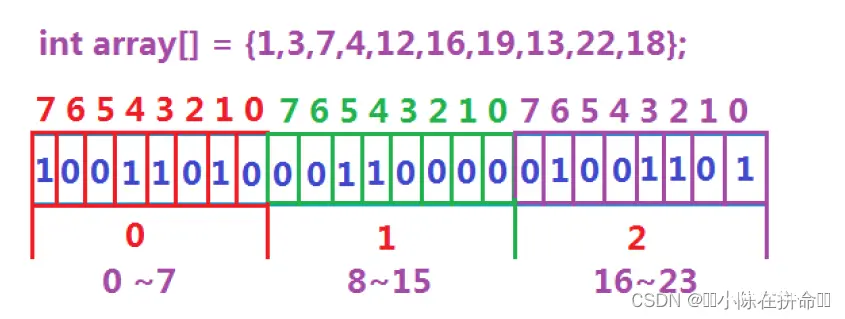
你可能会有这样的疑惑,为什么上面的排布是反着来的,即从7—>1,但其实这样才是符合我们的人为的认知的,比如1234,右边的是低位,左边才是高位。在计算机中具体是怎么排布的我们不得而知,因为那属于内存层,是我们看不到的,我们能看到的只是计算机给我们展现的虚拟层,比如说我们的监视窗口和内存窗口,每个bit位都是左高右低的排布,符合我们人的一个惯性。 而我们的左移运算符 其实就是从低位->高位 而右移运算符 其实是从高位->低位。
1.2 位图的实现
首先,我们的STL容器中是有位图这个容器的,名字叫做bitset。
1.2.1 基本结构
<code>template<size_t N> //非类型模板参数 N表示需要开的位图的大小
class bitset
{
public:
private:
vector<char> _bits;
};
我们需要去控制比特位,所以选择char作为我们的类型是最合适的,其中N是非类型模板参数,表明位图具体开多大。
1.2.2 构造函数
我们具体应该开多大,自然是取决于我们的元素数量的,既然我们一个char有8个bit位,自然就可以表示8个整数,但是需要注意的一个原则是:宁可开多不可开少。因为假设是10,除以8之后余数会被干掉,因此我们最后一定还要加上一个1
bitset()
{
_bits.resize(N / 8 + 1, 0); //只能开多不能开少
}
1.2.3 set
set的作用,就是将某一位设置成1
void set(size_t x) //设置成1
{
size_t i = x / 8;//计算x映射的位char在第i个数组的位置
size_t j = x % 8;//计算x映射的位在这个char的第j个比特位
//按位或 <<左移是低->高
_bits[i] |= (1 << j);
}
size_t i = x / 8;//计算x映射的位char在第i个数组的位置
size_t j = x % 8;//计算x映射的位在这个char的第j个比特位
接下来我们要判断的问题就是,如何将该位设置为1->利用位运算的性质 只要j对应的位置按位或上0……1……0 (1左移j位得到)即可
1.2.4 reset
reset的作用,就是将某一位设置成0
void reset(size_t x)//设置成0
{
size_t i = x / 8;//计算x映射的位char在第i个数组的位置
size_t j = x % 8;//计算x映射的位在这个char的第j个比特位
//按位与
_bits[i] &= ~(1 << j);
}
接下来我们要判断的问题就是,如何将该位设置为0->利用位运算的性质 只要j对应的位置按位或上1……0……1 (1左移j位再取反得到)即可
1.2.5 test
test的作用,就是判断某一位是否为1(即该整数在不在)
bool test(size_t x) //x在不在 判断这一位是0还是1
{
size_t i = x / 8;//计算x映射的位char在第i个数组的位置
size_t j = x % 8;//计算x映射的位在这个char的第j个比特位
return _bits[i] & (1 << j);
}
还要按位与上0……1……0,那么除了第j位 其他位都会是0 那么第j位如果也是0 结果就会是0,如果是1 那么结果就是非0.
1.2.6 位图开满空间的方法
bitset<-1> bs;//开满的方法
bitset<0xFFFFFFFF> bs;
-1强转成size_t 类型的时候就是无符号整型的最大值,而0xFFFFFFFF则是16进制下的无符号整型最大值。
1.3 位图的应用
1. 快速查找某个数据是否在一个集合中
一般适用于整型
2. 排序 + 去重
可以将一堆元素都丢进位图中,如果对应位置原来为0的话,就变成1,如果原来位置原来为1的话,就不处理,然后我们再通过映射关系将元素还原回来,就完成了排序+去重
3. 求两个集合的交集、并集等
这边有两种思路:
1、将两个集合分别放在两个位图中,分别完成排序和去重,然后再一个个去比对。
2、先将其中一个集合放进位图中,然后再通过另一个集合去判断,如果位图中为1,说明该数就是交集,但是为了防止集合出现重复数字,我们此时将该位置变成0(改进方法).
两种方法都可以,但是第一种方法有两个问题,一个是空间的消耗太大,另一个就是无论这个集合多大,我们都需要将所有的位置都遍历完了才可以确定,因为我们并不清楚集合里元素的范围。 而第二种方法可以有效改进上面两个问题,不仅空间消耗减少,而且我们只需要判断集合2的元素是否在位图中出现过即可,肯定比遍历全部位置效率高。 另一方面由于集合2没有进行去重,所以可能会出现重复元素,但是通过我们的改进方法——即发现交集的时候,将原先位图的位置变成0就可以解决这个问题。
总结:如果数据量达到亿级别,可能用第一种比较合适,但是大多数情况下,第二种显然是更合适的!!
4.数据相对集中时的统计次数
假设说我们已知数据只有可能出现‘a’->‘z’ 此时我们发现也就26种可能性,这个时候我们也不需要单独去封装一个位图,直接用一个整型就可以解决问题!!
附上一道位图有关的OJ题
面试题 01.01. 判定字符是否唯一 - 力扣(LeetCode)

<code>class Solution {
public:
bool isUnique(string astr)
{
if(astr.size()>26) return false;//鸽巢原理做优化
//利用位图的思想
int bitmap=0;
for(auto ch:astr)
{
int i=ch-'a';//找到映射关系
if((bitmap>>i)&1==1) return false;//先判断该字符是否出现过 判断第i位是否是1
//如果没出现过,将第i位的0修改为1
bitmap|=(1<<i);
}
return true;
}
};
5. 操作系统中磁盘块标记
1.4 位图的海量数据处理
1. 1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
该问题的关键就是:我们位图模型只能判断有或者无,但是无法区分出现多少次。
这个时候我们就要从本质去分析,为什么位图只能判断有或者无呢??原因就是我们只有一个比特位来表示状态的有无,所以我们这个时候可以用两个比特位来表示当前的状态。但是我们如果直接用一个为位图来解决,那么计算逻辑也会随之改变。所以我们还是用之前的位图,但是为了表示多种状态,我们使用两个位图。 00表示无,01表示1次,11表示2次,10表示2次以上即可。
根据上述的分析,我们构建出解决这一问题的类
template<size_t N> //非类型模板参数 N表示需要开的位图的大小
class twobitset //解决100亿数据判断有无 找到数据中不超过2次的整数 00-无 01一个 11两个 10两个以上
{
public:
void set(size_t x) //设置成1
{
if (_bit1.test(x) == false && _bit2.test(x) == false) _bit2.set(x);//00->01
else if (_bit1.test(x) == false && _bit2.test(x) == true) _bit1.set(x);//01->11
else if (_bit1.test(x) == true && _bit2.test(x) == true) _bit2.reset(x);//11->10
//如果是11 不处理
}
void Print() //打印只出现一次或者两次的整数
{
for (size_t i = 0; i < N; ++i)
if (_bit2.test(i) == true)
cout << i << endl;
cout << endl;
}
private:
bitset<N> _bit1;
bitset<N> _bit2;
};
2、给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
解决方案我在1.3中已经讲过了!!
1.5 位图的优缺点
优点:速度快、节省内存
缺点:只能映射整型,如浮点数、string等等不能存储映射
首先我们要思考,为什么位图无法存储这两种类型的映射,原因就在于其可以表现的形式太多种了,比如说对于无符号整型来说,最多也就2^32-1种可能, 但是对于浮点数和string来说,其组合之多导致无法像整型一样在位图中可以直接使用直接定址法。
浮点数还好,但是string平时非常常用,比如用户名,所以这个时候当数据量极大的时候,也是一个问题,所以后来出现了一种结构解决了这种问题——>布隆过滤器
二、布隆过滤器
2.1 布隆过滤器的提出
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那
些已经存在的记录。 如何快速查找呢?
1. 用哈希表存储用户记录,缺点:浪费空间
2. 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理
了。
3. 将哈希与位图结合,即布隆过滤器
2.2 布隆过滤器的概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存
在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也
可以节省大量的内存空间。
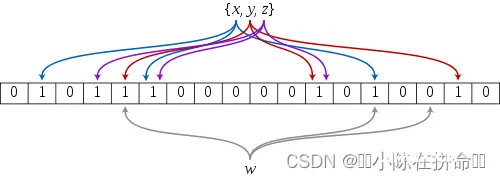
怎么去理解概率型数据结构呢??
首先可以确定的是,由于字符串的排列组合种类非常多,所以我们无论如何都无法做到通过直接定址法让每个字符串正好都对应一个位置……也就是说,我们利用字符串哈希函数在位图中存储大量字符串信息是必然会造成哈希冲突的,而布隆大佬的想法并不是完全解决哈希冲突,而是想降低哈希冲突的概率。 策略就是:既然一个字符串映射一个位置容易出现哈希冲突,那么一个字符串映射多个位置出现哈希冲突的概率就会降低!!!这是一种退而求其次的策略。
所以我们要使用多个类型的字符串哈希函数来帮助我们让一个字符串映射多个位置。具体有哪些常用的哈希函数可以参照下面的文章:字符串哈希函数算法
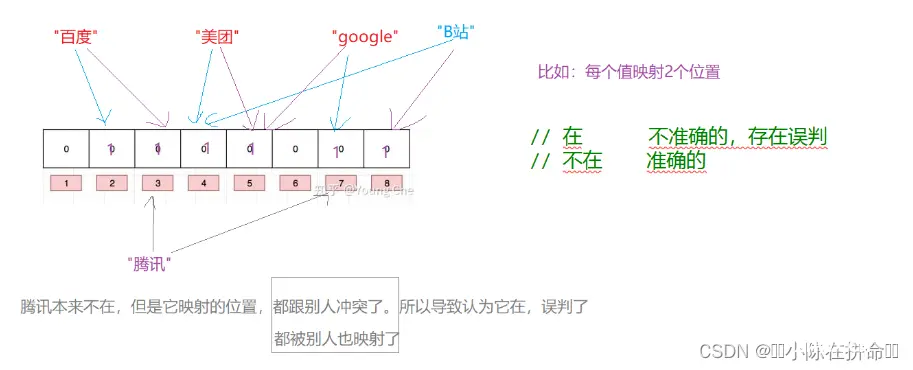
通过上图,我们可以确定布隆过滤器的两个特点:
1、不在是准确的,因为只要有一个位置没映射上,就是不在。
2、在是不准备的,存在误判,因为可能该字符串映射的位置恰好被前面的字符串给映射了
2.3 布隆过滤器的应用场景
既然布隆过滤器只是降低哈希冲突而不是避免哈希冲突,那么他适合的场景如下:
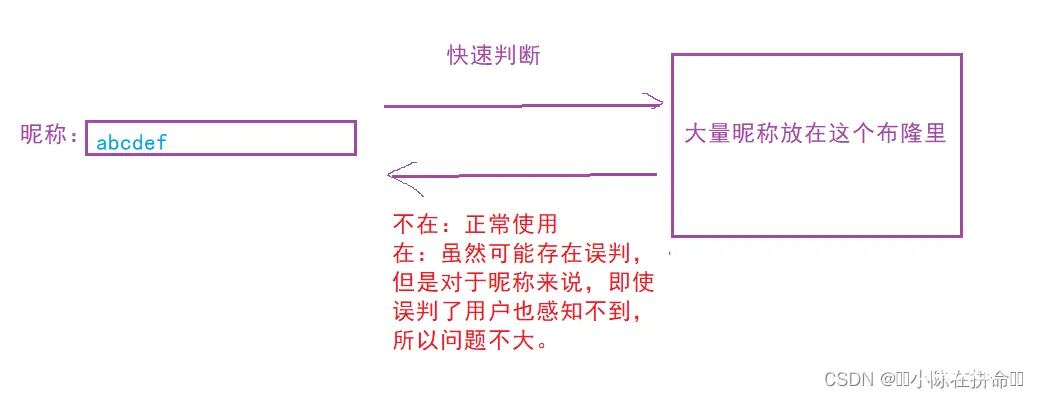
1、能容忍误判的场景(客户端感知不到)
比如注册时,快速判断昵称是否被使用过。
2、虽然不能容忍误判,但是可以确定不在是准确的,只需要对在的场景进行特殊处理
比如说注册时,快速判断该电话号码是否被注册过。
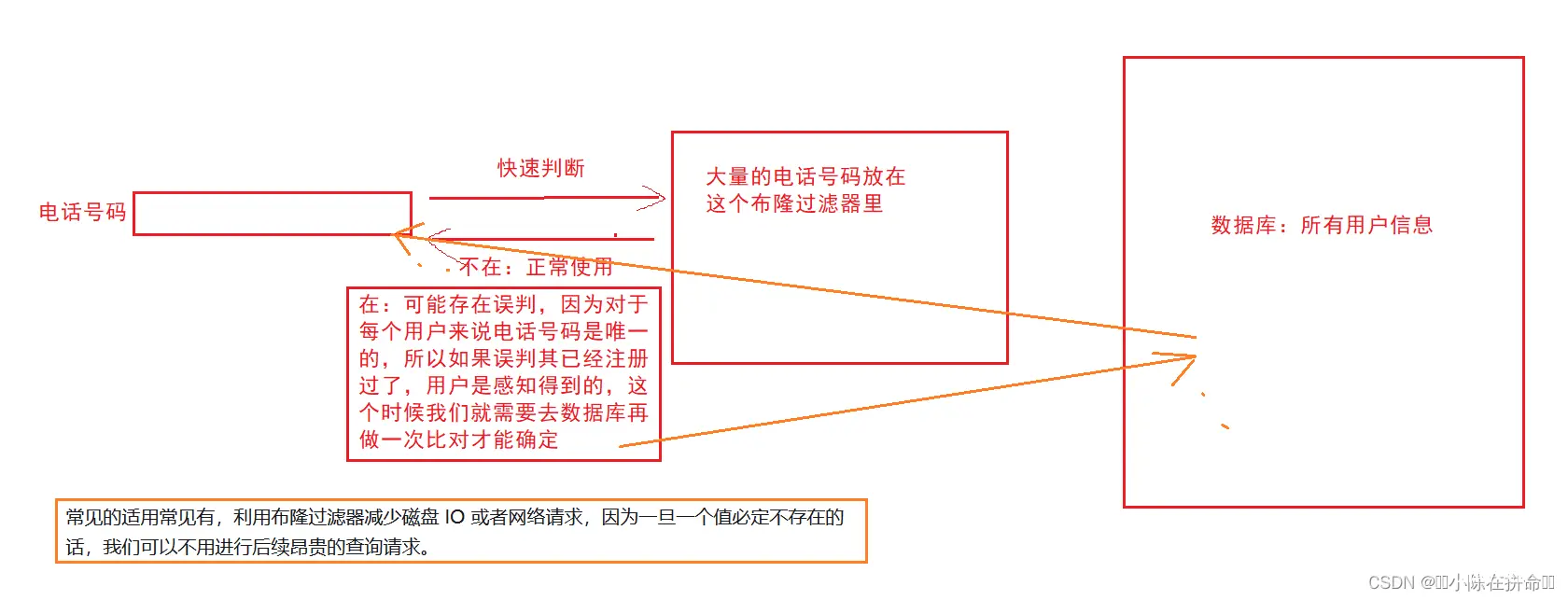
通过上图我们可以发现,布隆过滤器至少对不在的场景是判断准确的,所以我们可以不需要去数据库查询,只需要对在的结果进行查询和比对即可。
同时大家会发现,上图就充分展现了为什么该解决就叫做布隆过滤器,其实就是将大量的信息进行过滤,处理其中可以解决的问题,对于少部分不能解决的问题,再到数据库中去解决。
2.4 布隆过滤器实现的基本结构
<code> //想把类当函数使用 就要想到仿函数
//提供三个字符串哈希函数
struct BKDRHash
{
size_t operator() (const string& s) //字符串转整型
{
size_t hash = 0;
for (auto e : s)
{
hash += e;
hash *= 31;
}
return hash;
}
};
struct APHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (long i = 0; i < s.size(); i++)
{
size_t ch = s[i];
if ((i & 1) == 0) hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
else hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s) hash += (hash << 5) + ch;
return hash;
}
};
//布隆过滤器 基本上解决的是字符串的问题 如果是整型的话 还是位图更好用 至于用多少个哈希函数 取决于实际的需求
//N表示最多会插入key的个数
template<size_t N,
size_t X=6,
class K=string,
class Hash1= BKDRHash,
class Hash2= APHash,
class Hash3= DJBHash> //K并不确定是什么 通过多种Hash函数去帮助我们映射不同的位置
class BloomFilter
{
public:
private:
bitset<N*X> _bits;
};
我们一共用了6个模版参数,首先布隆过滤器大部分情况下是用来解决字符串的问题,所以我们的K默然给的是string,而后面Hash1——Hash3都是字符串哈希函数,这样一个字符串可以映射三个位置。而N表示的是要插入多少个字符串,而关于X是什么,我们来看看下面这个文章。
详解布隆过滤器的原理,使用场景和注意事项 - 知乎
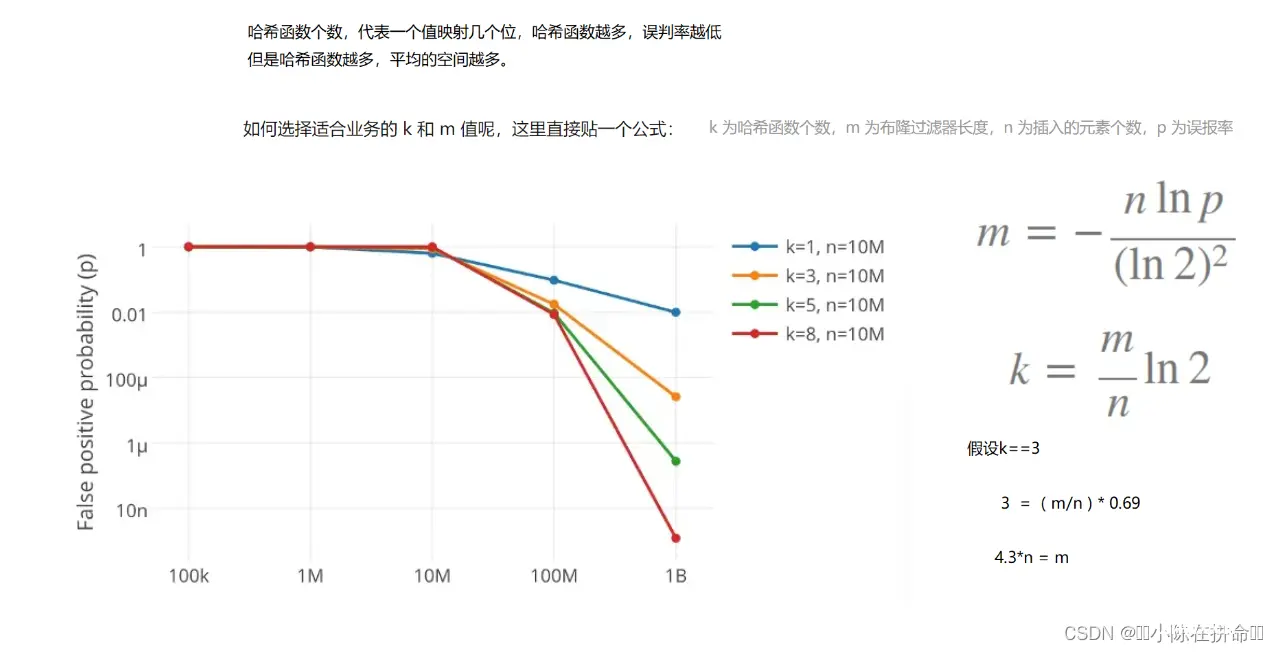
所以X在这边可以理解为我们需要多开X倍的空间,来尽可能达到误判率和效率尽可能合理。
经过计算后如果我们的哈希函数是3个的话,大概需要多开4.3倍的空间比较合理。
2.5 布隆过滤器的插入
<code>void set(const K& key)
{
size_t len = N * X;
size_t hash1 = Hash1()(key) % len;
_bits.set(hash1);
size_t hash2 = Hash2()(key) % len;
_bits.set(hash2);
size_t hash3 = Hash3()(key) % len;
_bits.set(hash3);
//cout << hash1 << " " << hash2 << " " << hash3 << endl << endl; //看看映射的位置
}
2.6 布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
bool test(const K& key)
{
size_t len = N * X;
size_t hash1 = Hash1()(key) % len;
if (_bits.test(hash1) == false) return false;
size_t hash2 = Hash2()(key) % len;
if (_bits.test(hash2) == false) return false;
size_t hash3 = Hash3()(key) % len;
if (_bits.test(hash3) == false) return false;
return true;//在可能会有误判
}
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可
能存在,因为有些哈希函数存在一定的误判。
2.7 布隆过滤器的删除
首先我们可以确定的是,布隆过滤器是不太支持删除的,因为我们删了一个位置,可能会影响其他位置。
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
但是这样会存在三种缺陷:
1、无法确认元素是否真正在布隆过滤器中
因为无论是位图还是布隆过滤器并不是传统意义上的真的存了相对应的元素在里面,而只能反 应具体在不在。所以我们很难保证说我们当前要删除的元素是否存在布隆过滤器中,如果要删除的元素不存在布隆过滤器中,布隆过滤器是检测不出来的,这样就整个乱套了。
2、容易存在计数回绕
既然是计数,那么我们就可以根据情况去控制一个位置大约用几个比特位来计数,比如我们用4个比特位来计数,那么就有2^4 也就是16个字符串可以映射该位置,如果用8个比特位就是2^8 也就是256个字符串可以映射该位置。但是如果我们超出了这个范围(比如有257个字符串映射了该位置),可能就会出现计数溢出导致计数回绕。
3、无法去重
使用引用计数后,如果一个字符串不小心同时插入了两次,那么对应位置的计数都会增加,这个时候当我们下次要删除的时候,也必须要删除两次,如果只删除一次,那么还是可以找得到。
综合上面的三种缺陷,我们可以得到一个结论就是——布隆过滤器并不适应删除的场景,尤其是第一个缺陷最为严重,严重时会导致数据丢失!!!
2.8 布隆过滤器的优点
1. 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
2. 哈希函数相互之间没有关系(可多次进行哈希切割),方便硬件并行运算
3. 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
4. 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
5. 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
6. 使用同一组散列函数的布隆过滤器可以进行交、并、差运算(哈希切割)
2.9 布隆过滤器的缺点
1. 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:1,再
建立一个白名单,存储可能会误判的数据。2,对在的场景进行特殊处理)
2. 不能获取元素本身
3. 一般情况下不能从布隆过滤器中删除元素
4. 如果采用计数方式删除,可能会存在计数回绕、删除不在的元素、无法去重等问题。
2.10 布隆过滤器的海量数据处理
1、给两个文件,分别有100亿个query(本质就是一个字符串,如sql语句),我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法

总结:
1,利用一个哈希函数进行哈希切分,根据具体情况将A和B分别切割成多个小文件。
2,用一个set来读取小文件
如果都可以插入,那么就是以下两种情况:(1)单个文件比较小,所以可以插入进去。(2)单个文件比较大,但是其中存在某个大量重复的query(此时换个哈希函数切割也是没用的,切不动)。但是由于set不支持键值冗余,所以都不会正确插入进去。 此时直接把另一个文件拿过来比对即可。
如果插入的过程中出现抛异常(内存不够才会抛异常),那么就是以下情况:单个文件比较大,并且存在大量不同的query,此时我们就再换一个哈希函数进行切割,将该文件切得更小一点。
2.11 布隆过滤器的误判率测试代码
<code>void test_bloomfilter2()
{
srand((unsigned int)time(0));
const size_t N = 10000;
BloomFilter<N> bf;
vector<string> v1;
string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
for (size_t i = 0; i < N; ++i)
{
v1.push_back(url + to_string(i));
}
for (auto& str : v1)
{
bf.set(str);
}
// v2跟v1是相似字符串集,但是不一样
vector<string> v2;
for (size_t i = 0; i < N; ++i)
{
string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
url += to_string(999999 + i);
v2.push_back(url);
}
size_t n2 = 0;
for (auto& str : v2)
{
if (bf.test(str))
{
++n2;
}
}
cout << "相似字符串误判率:" << (double)n2 / (double)N << endl;
// 不相似字符串集
vector<string> v3;
for (size_t i = 0; i < N; ++i)
{
string url = "zhihu.com";
//string url = "https://www.cctalk.com/m/statistics/live/16845432622875";
url += to_string(i + rand());
v3.push_back(url);
}
size_t n3 = 0;
for (auto& str : v3)
{
if (bf.test(str))
{
++n3;
}
}
cout << "不相似字符串误判率:" << (double)n3 / (double)N << endl;
当X为4的时候

当X为5的时候

当X为6的时候

当X是7的时候

我们发现6的时候进步是比较明显的,所以最后我选择了6
2.12 哈希切割
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
与上题条件相同,如何找到top K的IP?如何直接用Linux系统命令实现?

如果是top-K的话,建个小堆去不断比对即可,最后剩下的就是top-K。
2.13 布隆过滤器的整体代码实现
<code> //想把类当函数使用 就要想到仿函数
//提供三个字符串哈希函数
struct BKDRHash
{
size_t operator() (const string& s) //字符串转整型
{
size_t hash = 0;
for (auto e : s)
{
hash += e;
hash *= 31;
}
return hash;
}
};
struct APHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (long i = 0; i < s.size(); i++)
{
size_t ch = s[i];
if ((i & 1) == 0) hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
else hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
return hash;
}
};
struct DJBHash
{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s) hash += (hash << 5) + ch;
return hash;
}
};
//布隆过滤器 基本上解决的是字符串的问题 如果是整型的话 还是位图更好用 至于用多少个哈希函数 取决于实际的需求
//N表示最多会插入key的个数
template<size_t N,
size_t X=6,
class K=string,
class Hash1= BKDRHash,
class Hash2= APHash,
class Hash3= DJBHash> //K并不确定是什么 通过多种Hash函数去帮助我们映射不同的位置
//6是测试用测试代码测试出来的
class BloomFilter
{
public:
void set(const K& key)
{
size_t len = N * X;
size_t hash1 = Hash1()(key) % len;
_bits.set(hash1);
size_t hash2 = Hash2()(key) % len;
_bits.set(hash2);
size_t hash3 = Hash3()(key) % len;
_bits.set(hash3);
//cout << hash1 << " " << hash2 << " " << hash3 << endl << endl; //看看映射的位置
}
bool test(const K& key)
{
size_t len = N * X;
size_t hash1 = Hash1()(key) % len;
if (_bits.test(hash1) == false) return false;
size_t hash2 = Hash2()(key) % len;
if (_bits.test(hash2) == false) return false;
size_t hash3 = Hash3()(key) % len;
if (_bits.test(hash3) == false) return false;
return true;//在可能会有误判
}
private:
bitset<N*X> _bits;
};

上一篇: [python pip] A new release of pip is available: 23.2.1 -> 24.0
下一篇: 【Linux网络编程】自定义协议+序列化+反序列化
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。