【Linux网络编程】自定义协议+序列化+反序列化
LuckyRich1 2024-07-12 09:35:02 阅读 98
自定义协议+序列化+反序列化
1.再谈 "协议"2.Cal TCP服务端2.Cal TCP客户端4.Json

喜欢的点赞,收藏,关注一下把!

1.再谈 “协议”
协议是一种 “约定”。在前面我们说过父亲和儿子约定打电话的例子,不过这是感性的认识,今天我们理性的认识一下协议。 socket api的接口, 在读写数据时,都是按 “字符串”(其实TCP是字节流,这里是为了理解) 的方式来发送接收的。如果我们要传输一些 “结构化的数据” 怎么办呢?
结构化的数据就比如说我们在使用QQ群聊时除了消息本身、还能看见头像、时间、昵称。这些东西都要发给对方。这些东西都是一个个字符串,难道是把消息、头像、时间、昵称都单独发给对方吗?那分开发的时候,未来群里有成百上千名人大家都发,全都分开发,接收方还要确定每一部分是谁的进行匹配,那这样太恶心了。
实际上这些信息可不是一个个独立个体的而是一个整体。为了理解暂时当作多个字符串。把多个字符串形成一个报文或者说打包成一个字符串(方便理解,其实是一个字节流)然后在网络中发送。多变一方便未来在网络里整体发送。而把多变一的过程,我们称之为序列化。
这里用多个字符串形容也不太准确,下面给具体解释。
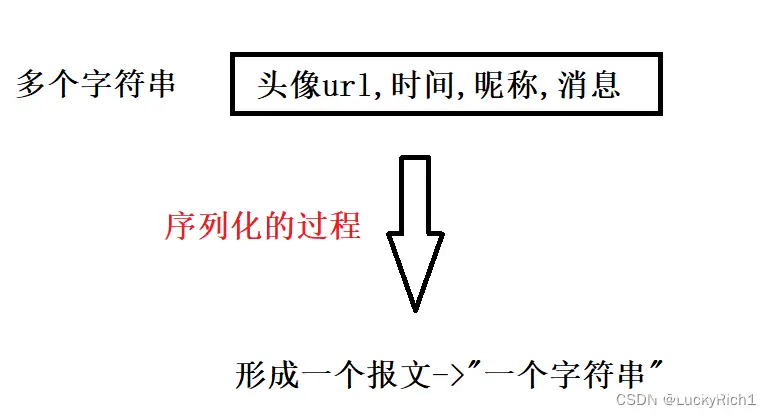
经过序列化的过程变成一个整体后发到网络里,经过网络传输发送给对方,发是整体当作一个字符串发的。接收方收的也是整体收的,所以收到一个报文或者说字符串。但是收到的字符串有什么东西我怎么知道,qq作为上层要的是谁发的、什么时候、发的什么具体的信息,所以接收方收到这个整体字符串后,必须把它转成多个字符串,这种一变多的过程,我们称之为反序列化。
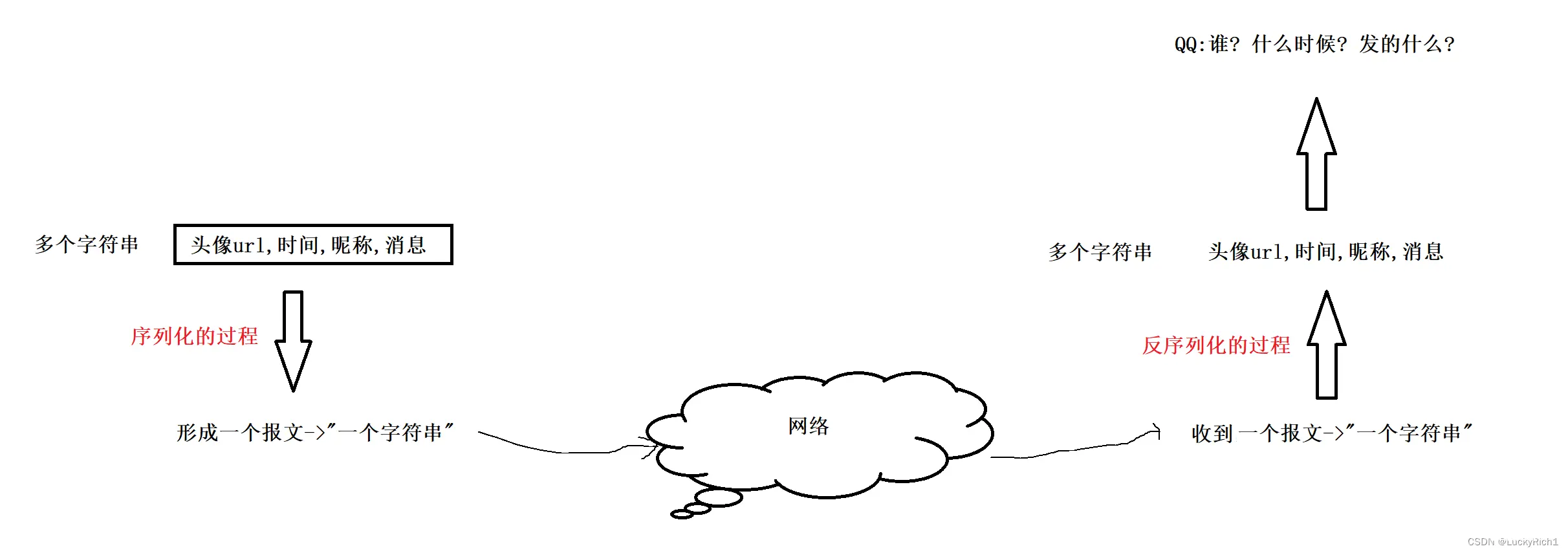
业务结构数据在发送网络中的时候,先序列化在发送,收到的一定是序列字节流,要先进行反序列化,然后才能使用。
刚才说过这里用多个字符串不太对只是为了理解,实际上未来多个字符串实际是一个结构体。是以结构体(结构化的数据)作为体现的,然后把这个结构体转成一个字符串,同理对方收到字符串然后转成对应的结构化的数据。
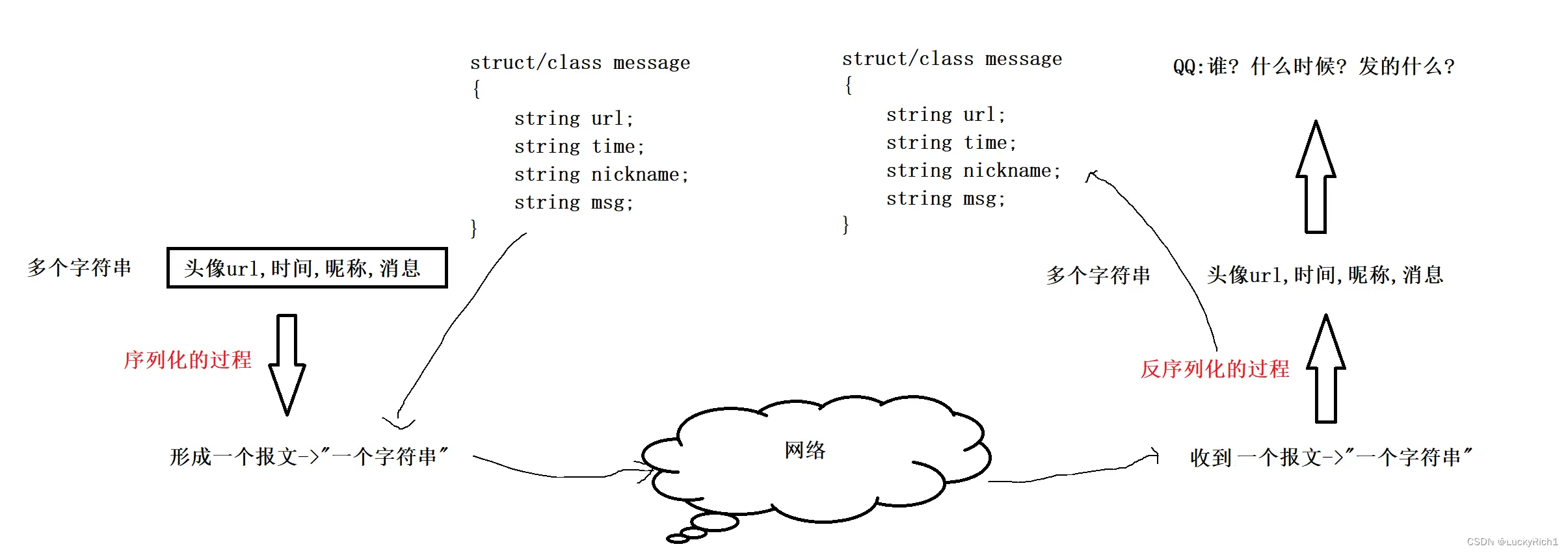
为什么要把字符串转成结构化数据呢?未来这个结构化的数据一定是一个对象,然后使用它的时候,直接对象.url 、对象.time 拿到。
而这里的结构体如message就是传说中的业务协议。
因为它规定了我们聊天时网络通信的数据。
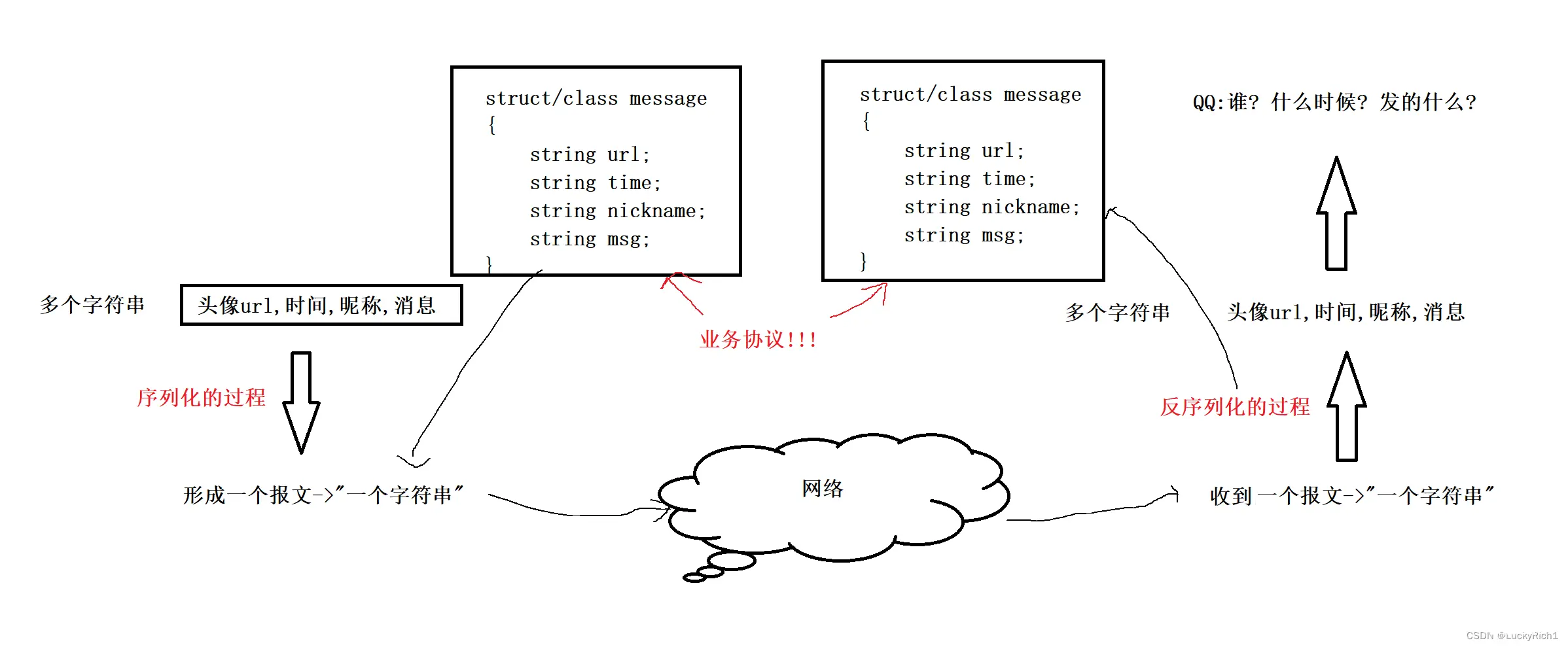
未来我们在应用层定协议就是这种结构体类型,目的就是把结构化的对象转换成序列化结构发送到网络里,然后再把序列化结构转成对应的结构体对象,然后上层直接使用对象进行操作! 这是业务协议,底层协议有自己的特点。
这样光说还是不太理解,下面找一个应用场景加深理解刚才的知识。所以我们写一个网络版计数器。里面体现出业务协议,序列化,反序列化,在写TCP时要注意TCP时面向字节流的,接收方如何保证拿到的是一个完整的报文呢?而不是半个、多个?这里我们都通过下面写代码的时候解决。而UDP是面向数据报的接收方收到的一定是一个完整的报文,因此不考虑刚才的问题。
2.Cal TCP服务端
自定义协议,但协议是一对的。因此有一个请求,一个响应。
<code>class Request
{
public:
Request() : _x(0), _y(0), _op(0)
{
}
Request(int x, int y, char op) : _x(x), _y(y), _op(op)
{
}
public:
//这里就是我们的约定,未来形成 “x op y” ,就一定要求x在前面,y在后面,op在中间这约定好的
int _x;//第一个数字
int _y;//第二个数字
char _op;//操作符
};
class Response
{
public:
Response() : _exitcode(0), _result(0)
{
}
Response(int exitcode, int result) : _exitcode(exitcode), _result(result)
{
}
public:
//约定
int _exitcode; // 0:计算成功,!0表示计算失败,具体是多少,定好标准
int _result; // 计算结果
};
以前我们写过服务器的代码,有些东西就直接用了,这里服务器是多进程版本。
我们这里主要进行业务逻辑方面的设计。
如果有新链接来了我们就进行处理,因此给一个handlerEntry函数,这里没写在类里主要是为了解耦。并且也把业务逻辑进行解耦给一个回调函数,handlerEntry函数你做你的序列化反序列化等一系列工作,和我没关系。我只做我的工作就行了。
//业务逻辑处理
typedef function<void(const Request &, Response &)> func_t;
void handlerEntry(int sock, func_t callback)
{
//1.读取
// 1.1 你怎么保证你读到的消息是 【一个】完整的请求
//2. 对请求Request,反序列化
//2.1 得到一个结构化的请求对象
//Request req=...;
// 3. 计算机处理,req.x, req.op, req.y --- 业务逻辑
// 3.1 得到一个结构化的响应
//Response resp=...;
//callback(req,resp);// req的处理结果,全部放入到了resp
// 4.对响应Response,进行序列化
// 4.1 得到了一个"字符串"
// 5. 然后我们在发送响应
}
class CalServer
{
public:
//。。。
void start(func_t func)
{
// 子进程退出自动被OS回收
signal(SIGCHLD, SIG_IGN);
for (;;)
{
// 4.获取新链接
struct sockaddr_in peer;
socklen_t len = (sizeof(peer));
int sock = accept(_listensock, (struct sockaddr *)&peer, &len); // 成功返回一个文件描述符
if (sock < 0)
{
logMessage(ERROR, "accpet error");
continue;
}
logMessage(NORMAL, "accpet a new link success,get new sock: %d", sock);
// 5.通信 这里就是一个sock,未来通信我们就用这个sock,tcp面向字节流的,后序全部都是文件操作!
// version2 多进程信号版
int fd = fork();
if (fd == 0)
{
close(_listensock);
handlerEntry(sock, func);
close(sock);
exit(0);
}
close(sock);
}
}
//。。。
private:
uint16_t _port;
int _listensock;
};
#include "CalServer.hpp"
#include <memory>
void Usage(string proc)
{
cout << "\nUsage:\n\t" << proc << " local_port\n\n";
}
// req: 里面一定是我们的处理好的一个完整的请求对象
// resp: 根据req,进行业务处理,填充resp,不用管理任何读取和写入,序列化和反序列化等任何细节
void Cal(const Request &req, Response &resp)
{
}
// ./tcpserver port
int main(int argc, char *argv[])
{
if (argc != 2)
{
Usage(argv[0]);
exit(USAGG_ERR);
}
uint16_t serverport = atoi(argv[1]);
unique_ptr<CalServer> tsv(new CalServer(serverport));
tsv->initServer();
tsv->start(Cal);
return 0;
}
整体就是这样的逻辑,我们现在把软件分成三层。第一层获取链接进行处理,第二层handlerEntery进行序列化反序列化等一系列工作,第三层进行业务处理callback。
现在逻辑清晰了,我们一个个补充代码
为什么说保证你读到的消息是 【一个】完整的请求?因为TCP是面向字节流的,我们保证不了,所以要明确 报文和报文的边界。
TCP有自己内核级别的发送缓冲区和接收缓冲区,而应用层也有自己的缓冲区,我们自己写的代码调用read,write发送读取使用的buffer就是对应缓冲区。其实我们调用的所有的发送函数,根本就不是把数据发送到网络中!
发送函数,本质是拷贝函数!!!
write只是把数据从应用层缓冲区拷贝到TCP发送缓冲区,由TCP协议决定什么时候把数据发送到网络,发多少,出错了怎么办。所以TCP协议叫做传输控制协议!!
最终数据经过网络发送被服务端放到自己的接收缓冲区里,然后我们在应用层调用read,实际在等接收缓冲区里有没有数据,有数据就把数据拷贝应用层的缓冲区。没有数据就是说接收缓冲区是空的,read就会被阻塞。
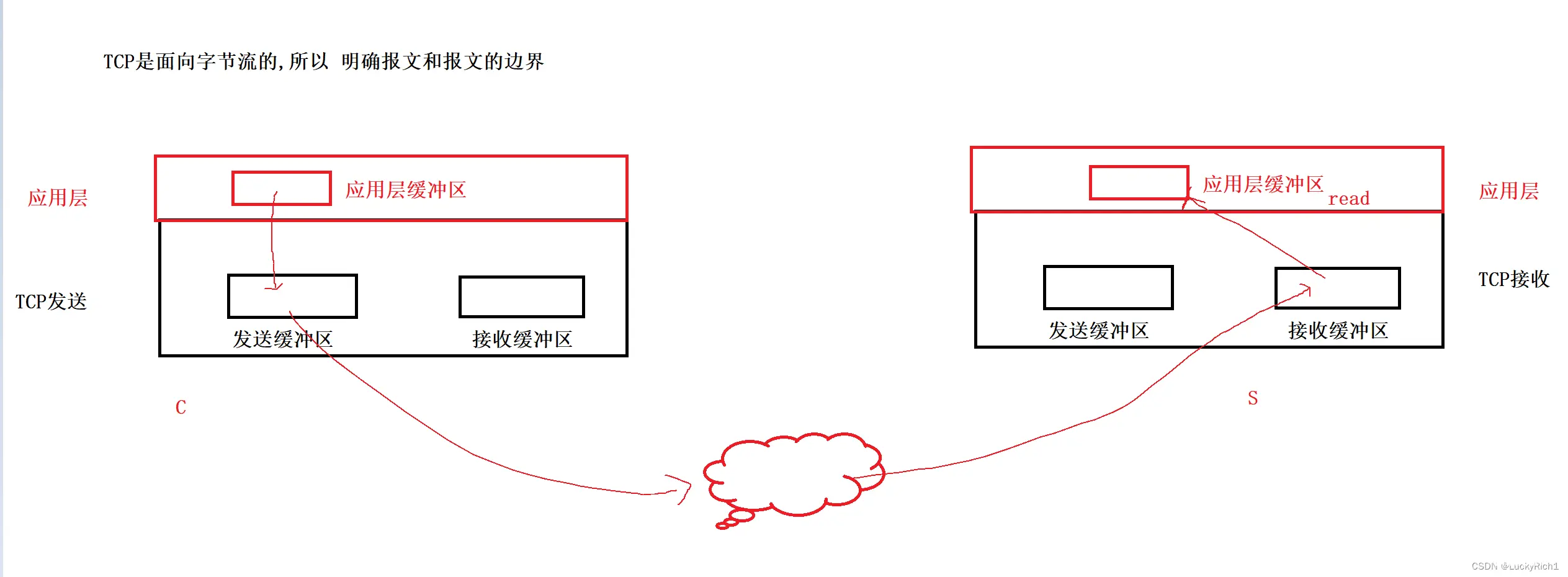
所以网络发送的本质:
C->S: tcp发送的本质,其实就是将数据从c的发送缓冲区,拷贝到s的接收缓冲区。
S->C: tcp发送的本质,其实就是将数据从s的发送缓冲区,拷贝到c的接收缓冲区。
c->s发,并不影响s->c发,因为用的是不同的成对的缓冲区,所以tcp是全双工的!
这里主要想说的是,tcp在进行发送数据的时候,发收方一直发数据但是对方正在做其他事情来不及读数据,所以导致接收方的接收缓冲区里面存在很多的报文,因为是TCP面向字节流的所以这些报文是挨在一起,最终读的时候怎么保证读到的是一个完整的报文交给上层处理,而不是半个,多个。就是因为我们有接收缓冲区的存在,因此首先我们要解决读取的问题。
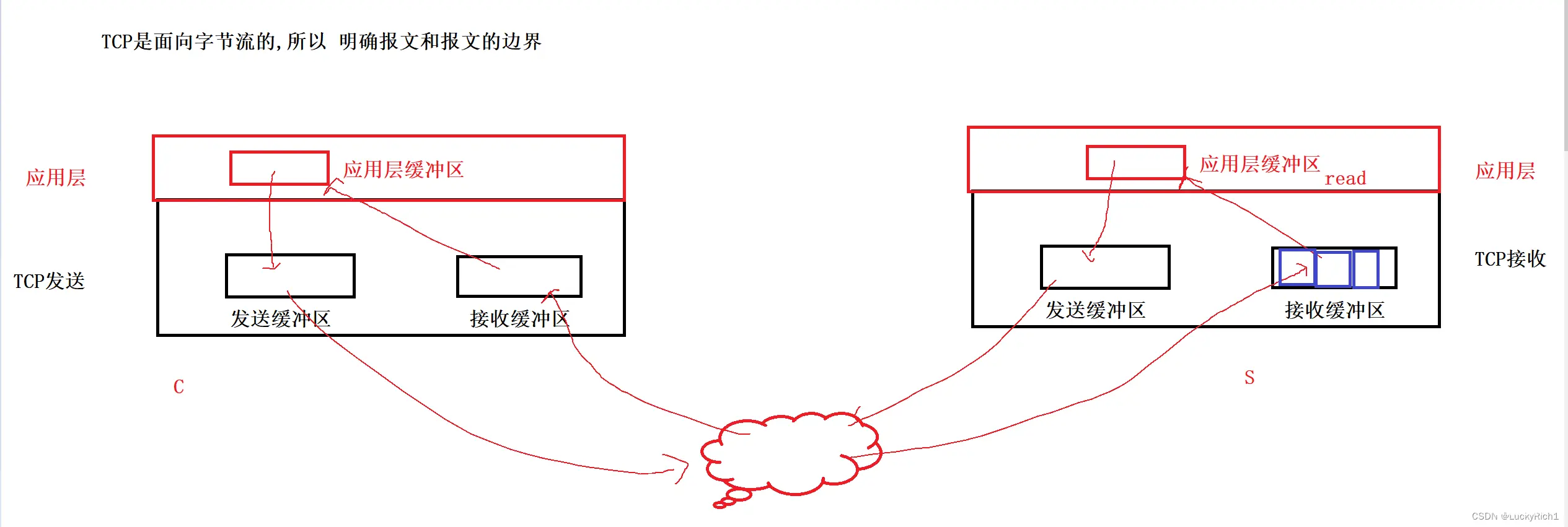
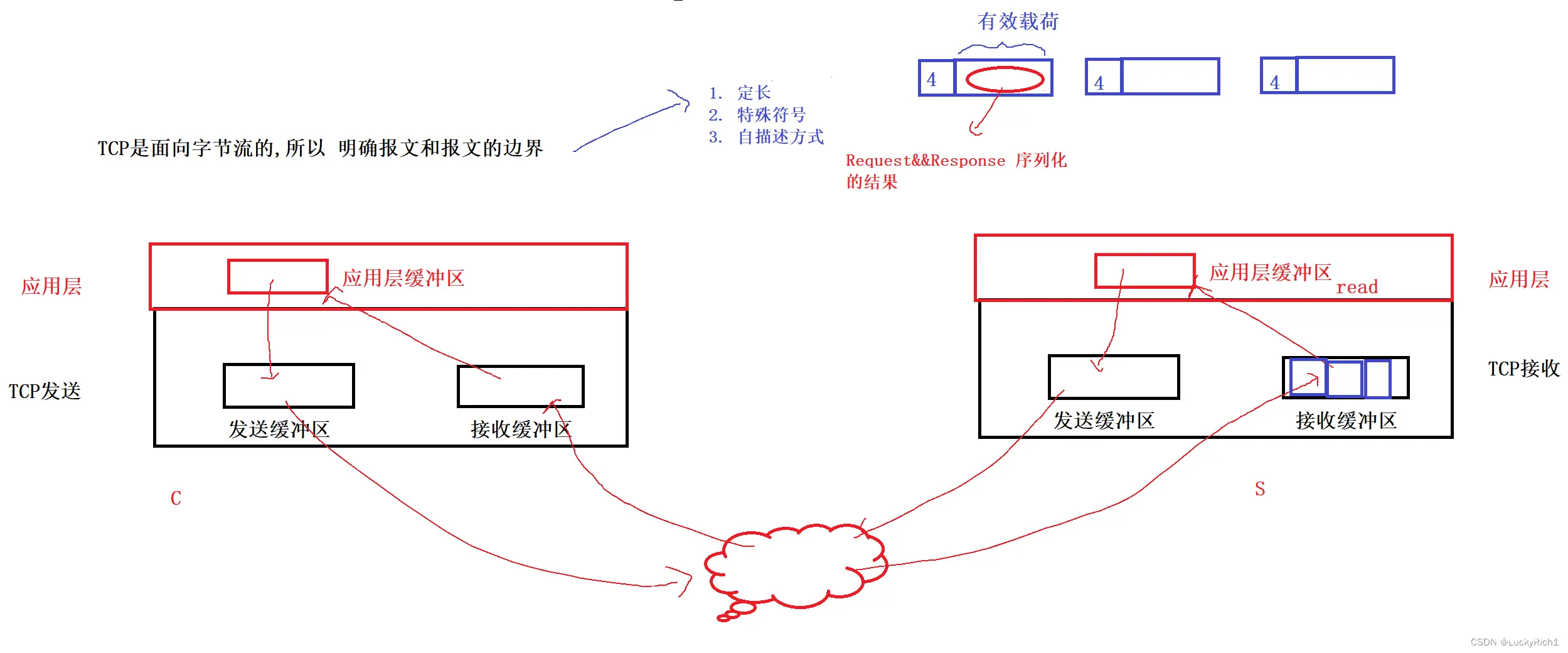
明确 报文和报文的边界:
定长特殊符号自描述方式
我们给每个报文前面带一个有效载荷长度的字段,未来我先读到这个长度,根据这个长度在读取若干字节,这样就能读取到一个报文,一个能读到,n个也能读到。有效载荷里面是请求或者响应序列化的结果。
<code>//有效载荷->报文
string Enlenth(const string &text)
{ }
//将读到的一个完整报文分离出有效载荷
bool Delenth(const string &packge, string *text)
{ }
未来读取到一个完整的报文就看这两个函数的具体实现了。
还有不管是请求和响应未来都需要做序列化和反序列化,因此在这两个类中都要包含这两个函数。
class Request
{
public:
Request() : _x(0), _y(0), _op(0)
{
}
Request(int x, int y, char op) : _x(x), _y(y), _op(op)
{
}
//序列化
bool serialize(string *out)
{
}
//反序列化
bool deserialize(const string &in)
{
}
public:
int _x;
int _y;
char _op;
};
关于这个序列化我们可以自己写,也可以用现成的,不过我们是初学先自己写感受一下,等都写完我们在介绍现成的。
序列化就是怎么把这个结构化的数据形成一个规定好格式的字符串。
#define SEP " "
#define SEP_LEN strlen(SEP)
#define LINE_SEP "\r\n"
#define LINE_SEP_LEN strlen(LINE_SEP)
bool serialize(string *out)
{
// 结构化 -> "x op y" //规定字符串必须是是 “第一个参数 操作数 第二个参数”
*out = "";
string x_string = to_string(_x);
string y_string = to_string(_y);
*out += x_string;
*out += SEP;
*out += _op;
*out += SEP;
*out += y_string;
return true;
}
反序列化就是把这个字符串变成规定好的结构化的数据
bool deserialize(const string &in)
{
// "x op y" -> 结构化
auto left = in.find(SEP);
auto right = in.rfind(SEP);
if (left == string::npos || right == string::npos)
return false;
if (left == right)
return false;
if (right - (left + SEP_LEN) != 1)//防止op是其他不合规的操作符如++
return false;
string x_string = in.substr(0, left); // [0, 2) [start, end) , start, end - start
string y_string = in.substr(right + SEP_LEN);
if (x_string.empty())
return false;
if (y_string.empty())
return false;
_x = stoi(x_string);
_y = stoi(y_string);
_op = in[left + SEP_LEN];
return true;
}
读取一个完整的请求,后面在填写,先补充其他逻辑
void handlerEntery(int sock, func_t callback)
{
string inbuffer;
while (true)
{
// 1. 读取
// 1.1 你怎么保证你读到的消息是 【一个】完整的请求
string req_str;//代表报文分离之后读取到的字符串(有效载荷)
// 2. 对请求Request,反序列化
// 2.1 得到一个结构化的请求对象
Request req;
if (!req.deserialize(req_str))
return;
// 3. 计算机处理,req.x, req.op, req.y --- 业务逻辑
// 3.1 得到一个结构化的响应
Response resp;
callback(req, resp); // req的处理结果,全部放入到了resp, 回调是不是不回来了?不是!
// 4.对响应Response,进行序列化
// 4.1 得到了一个"字符串"
// 5. 然后我们在发送响应
// 5.1 构建成为一个完整的报文
}
}
业务处理
enum
{
OK,
DIV_ERR,
MOD_ERR,
OPER_ERR
};
// req: 里面一定是我们的处理好的一个完整的请求对象
// resp: 根据req,进行业务处理,填充resp,不用管理任何读取和写入,序列化和反序列化等任何细节
void Cal(const Request &req, Response &resp)
{
//req已经有结构化完成的数据啦,你可以直接使用
resp._exitcode = OK;
resp._result = OK;
switch (req._op)
{
case '+':
resp._result = req._x + req._y;
break;
case '-':
resp._result = req._x - req._y;
break;
case '*':
resp._result = req._x * req._y;
break;
case '/':
{
if (req._y == 0)
resp._exitcode = DIV_ERR;
else
resp._result=req._x/req._y;
}
break;
case '%':
{
if (req._y == 0)
resp._exitcode = MOD_ERR;
else
resp._result=req._x%req._y;
}
break;
default:
resp._exitcode = OPER_ERR;
break;
}
}
现在对响应进行序列化,反序列化
class Response
{
public:
Response() : _exitcode(0), _result(0)
{
}
Response(int exitcode, int result) : _exitcode(exitcode), _result(result)
{
}
bool serialize(string *out)
{
// 结构化 -> "_exitcode _result"
*out = "";
*out = to_string(_exitcode);
*out += SEP;
*out += to_string(_result);
return true;
}
bool deserialize(const string &in)
{
//"_exitcode _result" ->结构化
auto pos = in.find(SEP);
if (pos == string::npos)
return false;
string ec_string = in.substr(0, pos);
string res_string = in.substr(pos + SEP_LEN);
if (ec_string.empty())
return false;
if (res_string.empty())
return false;
_exitcode = stoi(ec_string);
_result = stoi(res_string);
return true;
}
public:
int _exitcode; // 0:计算成功,!0表示计算失败,具体是多少,定好标准
int _result; // 计算结果
};
void handlerEntery(int sock, func_t callback)
{
string inbuffer;
while (true)
{
// 1. 读取
// 1.1 你怎么保证你读到的消息是 【一个】完整的请求
string req_str;//代表报文分离之后读取到的字符串(有效载荷)
// 2. 对请求Request,反序列化
// 2.1 得到一个结构化的请求对象
Request req;
if (!req.deserialize(req_str))
return;
// 3. 计算机处理,req.x, req.op, req.y --- 业务逻辑
// 3.1 得到一个结构化的响应
Response resp;
callback(req, resp); // req的处理结果,全部放入到了resp, 回调是不是不回来了?不是!
// 4.对响应Response,进行序列化
// 4.1 得到了一个"字符串"
string resp_str;
if (!resp.serialize(&resp_str))
return;
// 5. 然后我们在发送响应
// 5.1 构建成为一个完整的报文
}
}
现在的问题就是如何读到一个完整的报文请求。
首先得是一个报文,因此我们把序列化形成的字符串加上特定的格式形成一个报文
// "x op y" -> "content_len"\r\n"x op y"\r\n
string Enlenth(const string &text)
{
string send_string = to_string(text.size());
send_string += LINE_SEP;
send_string += text;
send_string += LINE_SEP;
return send_string;
}
void handlerEntery(int sock, func_t callback)
{
string inbuffer;
while (true)
{
// 1. 读取
// 1.1 你怎么保证你读到的消息是 【一个】完整的请求
string req_str;//代表报文分离之后读取到的字符串(有效载荷)
// 2. 对请求Request,反序列化
// 2.1 得到一个结构化的请求对象
Request req;
if (!req.deserialize(req_str))
return;
// 3. 计算机处理,req.x, req.op, req.y --- 业务逻辑
// 3.1 得到一个结构化的响应
Response resp;
callback(req, resp); // req的处理结果,全部放入到了resp, 回调是不是不回来了?不是!
// 4.对响应Response,进行序列化
// 4.1 得到了一个"字符串"
string resp_str;
if (!resp.serialize(&resp_str))
return;
// 5. 然后我们在发送响应
// 5.1 构建成为一个完整的报文
string send_string = Enlenth(resp_str);
//5.2 发送
send(sock, send_string.c_str(), send_string.size(), 0);
}
}
新的接口函数send和write一模一样,不过多了一个参数flags:发送方式,默认为0后面解释。
现在我们就差最后一步,如何读取的是一个完整的报文。
现在我们已经知道完整的报文是,这是我们自己定制好。
<code>"content_len"\r\n"x op y"\r\n
我们在写一个recvpackge读取函数,让它进行处理。只要这个函数返回了,走到下面一定是读取到了一个完整的报文。然后对这个报文进行处理只要有效载荷。
void handlerEntery(int sock, func_t callback)
{
string inbuffer;//每次从缓冲区拿到的数据放到inbuffer里
while (true)
{
string req_text, req_str;
// 1. 读取:"content_len"\r\n"x op y"\r\n
// 1.1 你怎么保证你读到的消息是 【一个】完整的请求
//把从sock读取的数据最后放到inbuffer里,从inbuffer里面拿到一个完整的请求放到req_text
if (!recvpackge(sock, inbuffer, &req_text))
return;
// 1.2 我们保证,我们req_text里面一定是一个完整的请求:"content_len"\r\n"x op y"\r\n
if (!Delenth(req_text, &req_str))
return;
//req_str 里放的是"x op y" 下面在进行处理
//。。。
}
}
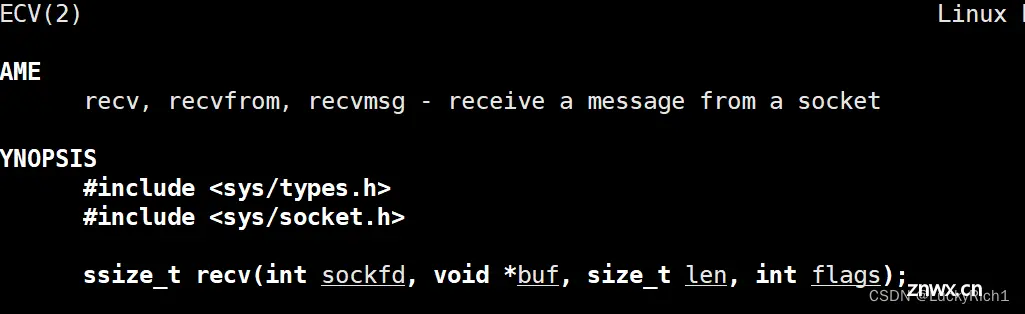
recv和read也是一模一样,也是后面多个发送方式,暂时写0
<code>bool recvpackge(int sock, string &inbuffer, string *text)
{
//"content_len"/r/n"x op y"/r/n
char buffer[1024];
while (true)
{
ssize_t n = recv(sock, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
inbuffer += buffer;//可能一次没用读到完整的报文,这里使用的是+=
auto pos = inbuffer.find(LINE_SEP);
if (pos == string::npos) // 没读到一个完整报文
continue;
//inbuffer.size() >= "content_len"/r/n"x op y"/r/n
//如果inbuffer.size()大于或等于一个完整报文的长度,说明inbuffer里面至少有一个完整报文
string text_len_string = inbuffer.substr(0, pos);
int text_len = stoi(text_len_string);
int total_len = text_len_string.size() + 2 * LINE_SEP_LEN + text_len;
if (inbuffer.size() < total_len)//也没有读到一个完整报文
continue;
// 至少有一个完整的报文
*text = inbuffer.substr(0, total_len);//拿到一个完整报文
inbuffer.erase(0, total_len);//把拿走的报文从inbuffer缓冲区里减去
break;
}
else
{
return false;
}
}
return true;
}
接下面Delenth得到这个报文中的有效载荷
//"content_len"\r\n"x op y"\r\n -> "x op y"
bool Delenth(const string &packge, string *text)
{
auto pos = packge.find(LINE_SEP);
if (pos == string::npos)
return false;
string text_len_string = packge.substr(0, pos);
int text_len = stoi(text_len_string);
*text = packge.substr(pos + LINE_SEP_LEN, text_len);
return true;
}
现在关于服务端有关业务逻辑已经都写好了,接下来写客户端的。
服务端业务逻辑完整代码
这里我们增加一些打印信息,最后运行可以看的到序列化反序列的过程。
#pragma once
#include <iostream>
#include <string>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#define SEP " "
#define SEP_LEN strlen(SEP)
#define LINE_SEP "\r\n"
#define LINE_SEP_LEN strlen(LINE_SEP)
using namespace std;
// "x op y" -> "content_len"\r\n"x op y"\r\n
string Enlenth(const string &text)
{
string send_string = to_string(text.size());
send_string += LINE_SEP;
send_string += text;
send_string += LINE_SEP;
return send_string;
}
//"content_len"\r\n"x op y"\r\n -> "x op y"
bool Delenth(const string &packge, string *text)
{
auto pos = packge.find(LINE_SEP);
if (pos == string::npos)
return false;
string text_len_string = packge.substr(0, pos);
int text_len = stoi(text_len_string);
*text = packge.substr(pos + LINE_SEP_LEN, text_len);
return true;
}
class Request
{
public:
Request() : _x(0), _y(0), _op(0)
{
}
Request(int x, int y, char op) : _x(x), _y(y), _op(op)
{
}
bool serialize(string *out)
{
// 结构化 -> "x op y"
*out = "";
string x_string = to_string(_x);
string y_string = to_string(_y);
*out += x_string;
*out += SEP;
*out += _op;
*out += SEP;
*out += y_string;
return true;
}
bool deserialize(const string &in)
{
// "x op y" -> 结构化
auto left = in.find(SEP);
auto right = in.rfind(SEP);
if (left == string::npos || right == string::npos)
return false;
if (left == right)
return false;
if (right - (left + SEP_LEN) != 1)
return false;
string x_string = in.substr(0, left); // [0, 2) [start, end) , start, end - start
string y_string = in.substr(right + SEP_LEN);
if (x_string.empty())
return false;
if (y_string.empty())
return false;
_x = stoi(x_string);
_y = stoi(y_string);
_op = in[left + SEP_LEN];
return true;
}
public:
int _x;
int _y;
char _op;
};
class Response
{
public:
Response() : _exitcode(0), _result(0)
{
}
Response(int exitcode, int result) : _exitcode(exitcode), _result(result)
{
}
bool serialize(string *out)
{
// 结构化 -> "_exitcode _result"
*out = "";
*out = to_string(_exitcode);
*out += SEP;
*out += to_string(_result);
return true;
}
bool deserialize(const string &in)
{
//"_exitcode _result" ->结构化
auto pos = in.find(SEP);
if (pos == string::npos)
return false;
string ec_string = in.substr(0, pos);
string res_string = in.substr(pos + SEP_LEN);
if (ec_string.empty())
return false;
if (res_string.empty())
return false;
_exitcode = stoi(ec_string);
_result = stoi(res_string);
return true;
}
public:
int _exitcode; // 0:计算成功,!0表示计算失败,具体是多少,定好标准
int _result; // 计算结果
};
bool recvpackge(int sock, string &inbuffer, string *text)
{
//"content_len"/r/n"x op y"/r/n
char buffer[1024];
while (true)
{
ssize_t n = recv(sock, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
inbuffer += buffer;//可能一次没用读到完整的报文,这里使用的是+=
auto pos = inbuffer.find(LINE_SEP);
if (pos == string::npos) // 没读到一个完整报文
continue;
//inbuffer.size() >= "content_len"/r/n"x op y"/r/n
//如果inbuffer.size()大于或等于一个完整报文的长度,说明inbuffer里面至少有一个完整报文
string text_len_string = inbuffer.substr(0, pos);
int text_len = stoi(text_len_string);
int total_len = text_len_string.size() + 2 * LINE_SEP_LEN + text_len;
cout << "处理前#inbuffer: \n"<< inbuffer << std::endl;
if (inbuffer.size() < total_len)//也没有读到一个完整报文
{
cout << "你输入的消息,没有严格遵守我们的协议,正在等待后续的内容, continue" << endl;
continue;
}
// 至少有一个完整的报文
*text = inbuffer.substr(0, total_len);//拿到一个完整报文
inbuffer.erase(0, total_len);//把拿走的报文从inbuffer缓冲区里减去
cout << "处理后#inbuffer:\n " << inbuffer << endl;
break;
}
else
{
return false;
}
}
return true;
}
#pragma once
#include "logMessage.hpp"
#include "protocol.hpp"
#include <iostream>
#include <string>
#include <stdlib.h>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <sys/wait.h>
#include <signal.h>
#include <functional>
using namespace std;
enum
{
USAGG_ERR = 1,
SOCKET_ERR,
BIND_ERR,
LISTEN_ERR
};
const int backlog = 5;
typedef function<void(const Request &, Response &)> func_t;
enum
{
OK,
DIV_ERR,
MOD_ERR,
OPER_ERR
};
void handlerEntery(int sock, func_t callback)
{
string inbuffer;
while (true)
{
string req_text, req_str;
// 1. 读取:"content_len"\r\n"x op y"\r\n
// 1.1 你怎么保证你读到的消息是 【一个】完整的请求
if (!recvpackge(sock, inbuffer, &req_text))
return;
cout << "带报头的请求:\n"<< req_text << std::endl;
// 1.2 我们保证,我们req_text里面一定是一个完整的请求:"content_len"\r\n"x op y"\r\n
if (!Delenth(req_text, &req_str))
return;
cout << "去掉报头的正文:\n"<< req_str << endl;
// 2. 对请求Request,反序列化
// 2.1 得到一个结构化的请求对象
Request req;
if (!req.deserialize(req_str))
return;
// 3. 计算机处理,req.x, req.op, req.y --- 业务逻辑
// 3.1 得到一个结构化的响应
Response resp;
callback(req, resp); // req的处理结果,全部放入到了resp, 回调是不是不回来了?不是!
// 4.对响应Response,进行序列化
// 4.1 得到了一个"字符串"
string resp_str;
if (!resp.serialize(&resp_str))
return;
cout << "计算完成, 序列化响应: " << resp_str << endl;
// 5. 然后我们在发送响应
// 5.1 构建成为一个完整的报文
string send_string = Enlenth(resp_str);
cout << "构建完成完整的响应\n"<< send_string << endl;
send(sock, send_string.c_str(), send_string.size(), 0);
}
}
class CalServer
{
public:
CalServer(const uint16_t port) : _port(port), _listensock(-1)
{
}
void initServer()
{
// 1.创建socket文件套接字对象
_listensock = socket(AF_INET, SOCK_STREAM, 0);
if (_listensock < 0)
{
logMessage(FATAL, "socket create error");
exit(SOCKET_ERR);
}
logMessage(NORMAL, "socker create success :%d", _listensock);
// 2.bind 绑定自己的网络消息 port和ip
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(_port);
local.sin_addr.s_addr = INADDR_ANY; // 任意地址bind,服务器真实写法
if (bind(_listensock, (struct sockaddr *)&local, sizeof(local)) < 0)
{
logMessage(FATAL, "bind socket error");
exit(BIND_ERR);
}
logMessage(NORMAL, "bind socket success");
// 3.设置socket为监听状态
if (listen(_listensock, backlog) < 0) // backlog 底层链接队列的长度
{
logMessage(FATAL, "listen socket error");
exit(LISTEN_ERR);
}
logMessage(NORMAL, "listen socker success");
}
void start(func_t func)
{
// 子进程退出自动被OS回收
signal(SIGCHLD, SIG_IGN);
for (;;)
{
// 4.获取新链接
struct sockaddr_in peer;
socklen_t len = (sizeof(peer));
int sock = accept(_listensock, (struct sockaddr *)&peer, &len); // 成功返回一个文件描述符
if (sock < 0)
{
logMessage(ERROR, "accpet error");
continue;
}
logMessage(NORMAL, "accpet a new link success,get new sock: %d", sock);
// 5.通信 这里就是一个sock,未来通信我们就用这个sock,tcp面向字节流的,后序全部都是文件操作!
// version2 多进程信号版
int fd = fork();
if (fd == 0)
{
close(_listensock);
handlerEntery(sock, func);
close(sock);
exit(0);
}
close(sock);
}
}
~CalServer()
{
}
private:
// string _ip;
uint16_t _port;
int _listensock;
};
#include "CalServer.hpp"
#include <memory>
void Usage(string proc)
{
cout << "\nUsage:\n\t" << proc << " local_port\n\n";
}
// req: 里面一定是我们的处理好的一个完整的请求对象
// resp: 根据req,进行业务处理,填充resp,不用管理任何读取和写入,序列化和反序列化等任何细节
void Cal(const Request &req, Response &resp)
{
// req已经有结构化完成的数据啦,你可以直接使用
resp._exitcode = OK;
resp._result = OK;
switch (req._op)
{
case '+':
resp._result = req._x + req._y;
break;
case '-':
resp._result = req._x - req._y;
break;
case '*':
resp._result = req._x * req._y;
break;
case '/':
{
if (req._y == 0)
resp._exitcode = DIV_ERR;
else
resp._result=req._x/req._y;
}
break;
case '%':
{
if (req._y == 0)
resp._exitcode = MOD_ERR;
else
resp._result=req._x%req._y;
}
break;
default:
resp._exitcode = OPER_ERR;
break;
}
}
// ./tcpserver port
int main(int argc, char *argv[])
{
if (argc != 2)
{
Usage(argv[0]);
exit(USAGG_ERR);
}
uint16_t serverport = atoi(argv[1]);
unique_ptr<CalServer> tsv(new CalServer(serverport));
tsv->initServer();
tsv->start(Cal);
return 0;
}
2.Cal TCP客户端
这里我们就改发送和读取就行了,其他还和以前一样
#pragma once
#include <iostream>
#include <string>
#include <stdlib.h>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include "protocol.hpp"
using namespace std;
class CalClient
{
public:
CalClient(const string &ip, const uint16_t &port)
: _serverip(ip), _serverport(port), _sockfd(-1)
{
}
void initClient()
{
// 1.创建socket套接字
_sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (_sockfd < 0)
{
cerr << "socket fail" << endl;
exit(2);
}
}
void run()
{
// 2.发起链接
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(_serverport);
server.sin_addr.s_addr = inet_addr(_serverip.c_str());
if (connect(_sockfd, (struct sockaddr *)&server, sizeof(server)) != 0)
{
cerr << "socker connect fail" << endl;
}
else
{
string msg,inbuffer;
while (true)
{
// 发
cout << "mycal>> ";
getline(cin, msg);//输入1+1
Request req=ParseLine(msg);//构建Request对象
string req_str;
req.serialize(&req_str);//序列化
string send_string=Enlenth(req_str);//加报头
send(_sockfd,send_string.c_str(),send_string.size(),0);
// 读
// recvpackge里我们是按照特殊格式进行读取的,因此这里直接用
// "content_len"\r\n"exitcode result"\r\n
string resp_text,resp_str;
if(!recvpackge(_sockfd,inbuffer,&resp_text))
continue;
if(!Delenth(resp_text,&resp_str))
continue;
// "exitcode result"
Response resp;
resp.deserialize(resp_str);
cout<<"exitcode: "<<resp._exitcode<<endl;
cout<<"result: "<<resp._result<<endl;
}
}
}
//这里有各种方法,可以选自己喜欢的处理方式
Request ParseLine(const string& msg)
{
//1+1 123*345 24/2
int pos=0;//找到分割符
for(int i=0;i<msg.size();++i)
{
if(isdigit(msg[i]) == false)
{
pos=i;
break;
}
}
string left=msg.substr(0,pos);
string right=msg.substr(pos+1);
Request req;
req._x=stoi(left);
req._y=stoi(right);
req._op=msg[pos];
return req;
}
~CalClient()
{
if(_sockfd >= 0) close(_sockfd);
}
private:
string _serverip;
uint16_t _serverport;
int _sockfd;
};
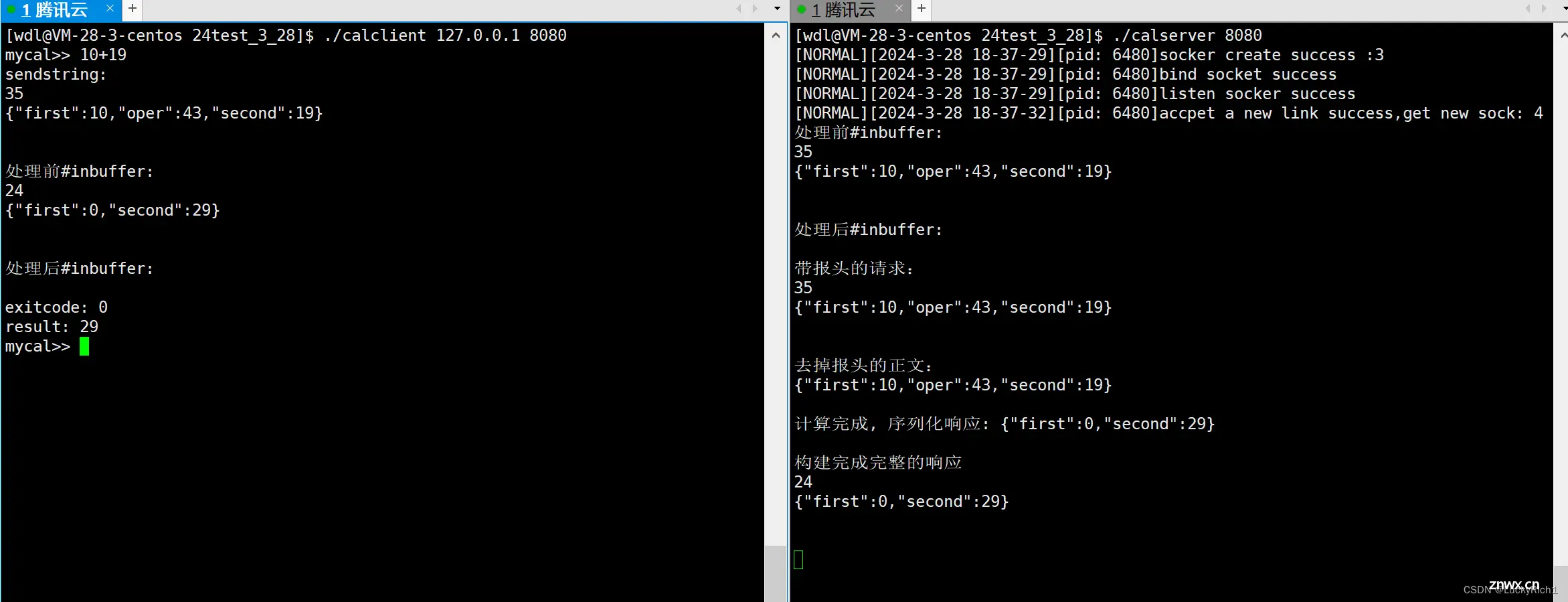
现在服务端和客户端都写好了运行一下,这里我们打印出一些信息能看到序列化和反序列化的过程。
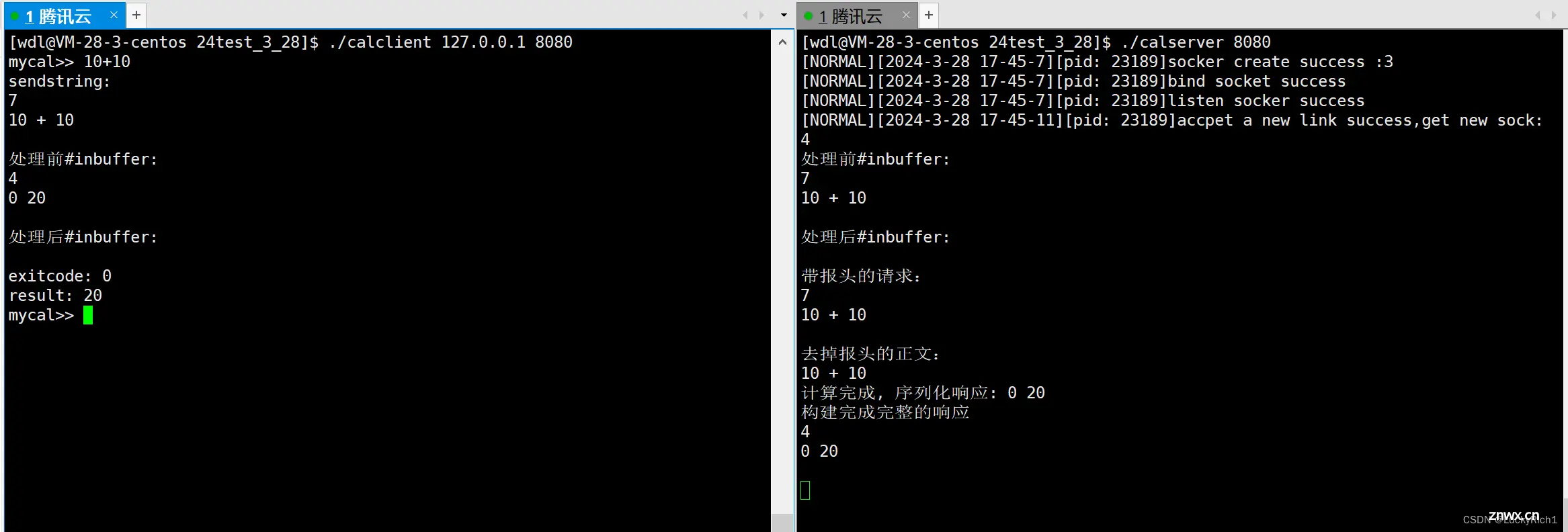
UDP是面向数据报的,因此只需要序列化和反序列化。
TCP是面向字节流的,需要考虑保证读到的是一个完整报文、获取有效载荷、序列化、反序列化。
4.Json
上面是我们手写序列化和反序列化和协议,帮助我们理解这里序列化和反序列化自己写的有的挫。对于序列化和反序列化,有现成的解决方案,绝对不会自己去写。但是没说,协议不能自己定!
Jsonprotobufxml
我们这里用的是Json(简单)
Json其实就是一个字符串风格数据交换格式

里面属性是以K和V的形式呈现出来的键值对,未来我们可以以KV形式设置,提取可以以KV形式提取。
安装Json库
<code>sudo yum install -y jsoncpp-devel //安装c++的json库
下面在代码里我们使用了条件编译,方便自己用Json和自己序列化反序列方案切换。
编译的时候想用Json方案-DMYSELF,不想用#-DMYSELF 注释掉
LD=-DMYSELF
.PHONY:all
all:calclient calserver
calclient:CalClient.cc
g++ -o $@ $^ -std=c++11 -ljsoncpp ${ LD}
calserver:CalServer.cc
g++ -o $@ $^ -std=c++11 -ljsoncpp ${ LD}
.PHONY:clean
clean:
rm -f calserver calclient
#include <jsoncpp/json/json.h>
class Request
{
public:
Request() : _x(0), _y(0), _op(0)
{
}
Request(int x, int y, char op) : _x(x), _y(y), _op(op)
{
}
bool serialize(string *out)
{
#ifndef MYSELF
// 结构化 -> "x op y"
*out = "";
string x_string = to_string(_x);
string y_string = to_string(_y);
*out += x_string;
*out += SEP;
*out += _op;
*out += SEP;
*out += y_string;
#else
Json::Value root;//Json::Value是一个万能对象,用来接收任意类型
//Json是KV的格式,因此我们要给它设置KV,方便后面提取它
//x虽然是个整型,但是实际在保存到Json里它会把所有内容转成字符串
root["first"] = _x;
root["second"] = _y;
root["oper"] = _op;
//Json形成字符串有两种风格,我们选其中一种
Json::FastWriter write;
// Json::StyledWriter writer;
*out = write.write(root);//里面自动组序列化,返回值是一个string
#endif
return true;
}
bool deserialize(const string &in)
{
#ifndef MYSELF
// "x op y" -> 结构化
auto left = in.find(SEP);
auto right = in.rfind(SEP);
if (left == string::npos || right == string::npos)
return false;
if (left == right)
return false;
if (right - (left + SEP_LEN) != 1)
return false;
string x_string = in.substr(0, left); // [0, 2) [start, end) , start, end - start
string y_string = in.substr(right + SEP_LEN);
if (x_string.empty())
return false;
if (y_string.empty())
return false;
_x = stoi(x_string);
_y = stoi(y_string);
_op = in[left + SEP_LEN];
#else
Json::Value root;
Json::Reader reader;
reader.parse(in, root);//从in这个流中做反序列化,放到root里
//根据K提取V
//不过Json默认把所有数据当成字符串
_x = root["first"].asInt();//把字符串转成对于的类型
_y = root["second"].asInt();
_op = root["oper"].asInt();//char本来就是按ASCII码存的,这里也把当它当成整数
#endif
return true;
}
public:
int _x;
int _y;
char _op;
};
class Response
{
public:
Response() : _exitcode(0), _result(0)
{
}
Response(int exitcode, int result) : _exitcode(exitcode), _result(result)
{
}
bool serialize(string *out)
{
#ifndef MYSELF
// 结构化 -> "_exitcode _result"
*out = "";
*out = to_string(_exitcode);
*out += SEP;
*out += to_string(_result);
#else
Json::Value root;
root["first"] = _exitcode;
root["second"] = _result;
Json::FastWriter write;
*out = write.write(root);
#endif
return true;
}
bool deserialize(const string &in)
{
#ifndef MYSELF
//"_exitcode _result" ->结构化
auto pos = in.find(SEP);
if (pos == string::npos)
return false;
string ec_string = in.substr(0, pos);
string res_string = in.substr(pos + SEP_LEN);
if (ec_string.empty())
return false;
if (res_string.empty())
return false;
_exitcode = stoi(ec_string);
_result = stoi(res_string);
#else
Json::Value root;
Json::Reader reader;
reader.parse(in, root);
_exitcode = root["first"].asInt();
_result = root["second"].asInt();
#endif
return true;
}
public:
int _exitcode; // 0:计算成功,!0表示计算失败,具体是多少,定好标准
int _result; // 计算结果
};
如上就是我们的自定义协议,序列化,反序列化的内容。
自定义协议说人话就是定义一个结构化的对象,有了这个结构化的对象,未来客户端和服务端可以进行来回的发送。约定体现在这个结构化对象里面的成员变量都代表了什么意思。为什么一定是这样的格式而不能是其他格式。如op为什么一定是±*/不能是其他,这些都是约定好的。拿到结果先看哪一个后看哪一个。exitcode为0是什么意思,不为0是什么意思。都是规定好的。这就是协议。
没有人规定我们网络通信的时候,只能有一种协议!
我们今天就只写了一种协议Request,Response,未来如果想用Request1,Response1等等,定义100对协议都是可以的。每一对协议做不同的工作。
那我们怎么让系统知道我们用的是哪一种协议呢?
我们可以在报文里添加协议编号。
如"content_len"\r\n"协议编号"\r\n"x op y"\r\n,未来解析协议的时候可以把协议编号拿到,然后根据编号区分清楚用的是那个Request,Response对象。
目前基本socket写完,一般服务器设计原则和方式(多进程、多线程、线程池)+常见的各种场景,自定义协议+序列化和反序列化都已经学了。所以未来我们就可以用这三大构成自己自由去写服务器了。
有没有人已经针对常见场景,早就已经写好了常见的协议软件,供我们使用呢?
当然了,最典型的HTTP/HTTPS。未来它们做的事情和我们以前做的事情是一样的!只不过HTTP是结合它的应用场景来谈的。
下篇博客我们具体详谈!
上一篇: [python pip] A new release of pip is available: 23.2.1 -> 24.0
下一篇: 基于Python + Flask+ Mysq实现简易留言板
本文标签
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。