【ECCV 2024】InternVideo2: Scaling Foundation Models for Multimodal Video Understanding
旋转的油纸伞 2024-09-04 08:01:02 阅读 98
【ECCV 2024】InternVideo2: Scaling Foundation Models for Multimodal Video Understanding
一、前言Abstract1 Introduction2 Related Work3 Method3.1 Stage1: Reconstructing Unmasked Video Tokens3.2 Stage 2: Aligning Video to Audio-Speech-Text3.3 Stage3: Predicting Next Token with Video-Centric Inputs
4 Multimodal Video Data4.1 Video-only Data for Masked Autoencoders4.2 Videos with Audio-Speech Modalities4.3 Instruction-Tuning Data for Video Dialogue
5 Experiments5.1 Video Classification5.1.1 Action Recognition5.1.2 Temporal Action Localization5.1.3 Video Instance Segmentation
5.2 Video-Audio-Language Tasks5.2.1 Video Retrieval5.2.2 Video Temporal Grounding5.2.3 Audio-related Tasks
5.3 Video-centric Dialogue and its Applications5.4 Ablation Studies5.4.1 Scaling Video Encoder5.4.2 Training Data and used Teachers in Stage 15.4.3 Training Arch, Method, and Data in Stage 25.4.4 Training and Evaluation in Stage 3
6 Conclusion and Discussion7 Broader Impact
一、前言
Authors: Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Chenting Wang, Guo Chen, Baoqi Pei, Ziang Yan, Rongkun Zheng, Jilan Xu, Zun Wang, Yansong Shi, Tianxiang Jiang, Songze Li, Hongjie Zhang, Yifei Huang, Yu Qiao, Yali Wang, Limin Wang
单位:OpenGVLab, Shanghai AI Laboratory
【Paper】 > 【Github_Code】 > 【Project】
Abstract
介绍:我们推出了 InternVideo2,这是一个新的视频基础模型 (ViFM) 系列,它在视频识别、视频文本任务和以视频为中心的对话方面取得了最先进的结果。
方法:我们的核心设计是一种渐进式训练方法,它将屏蔽视频建模、跨模态对比学习和下一个标记预测相结合,将视频编码器大小扩展到 6B 参数。在数据层面,我们通过对视频进行语义分割并生成视频音频语音字幕来优先考虑时空一致性。这改善了视频和文本之间的对齐。
实验:通过大量实验,我们验证了我们的设计,并在 60 多个视频和音频任务中展示了卓越的性能。值得注意的是,我们的模型在各种与视频相关的对话和长视频理解基准上优于其他模型,突显了其推理和理解较长上下文的能力。
1 Introduction

学习可迁移的时空表示是计算机视觉中的一个关键研究领域,在跨领域拥有多种应用,例如视频搜索 \cite{gabeur2020multi}、游戏控制 \cite{bruce2024genie}、机器人学习 \cite{palme}、自动驾驶 \cite{ zablocki2022explainability},以及科学研究 \cite{team2023gemini}。最近,大型语言模型(LLM)的进步 \ cite {gpt3,gpt4,llama1,llama2}及其多模态变体(MLLM)\ cite {gpt4v,mmgpt,llava,team2023gemini}对视觉研究和研究产生了深远的影响。其他学科。将视频有效地嵌入到这些大型模型中并利用其能力来增强视频理解性能已成为关键任务 \ cite {li2023videochat,videochatgpt}。
先前的研究已经确定了几种有效的视频表示学习方案,包括使用屏蔽输入重建视频 [He et al., 2022, Tong et al., 2022, Wang et al., 2023b, Feichtenhofer et al., 2022]、对齐视频与语言[Li and Wang, 2020, Xu et al., 2021, Yan et al., 2022, Li et al., 2023e],并使用视频预测下一个标记[Alayrac et al., 2022, Sun et al., 2022] ,2023c,Li 等人,2023d]。事实证明,这些方法是互补的,可以通过渐进式训练计划进行统一。值得注意的是,InternVideo [Wang et al., 2022]、UMT [Li et al., 2023e] 和 VideoPrism [Zhao et al., 2024] 等方法采用了涉及掩模重建和多模态对比学习的两阶段训练方法,从而提高下游任务的性能。沿着这条线,我们的目标是通过结合基于视频的下一个令牌预测和扩展整个训练过程(包括模型和数据)来进一步扩展这种渐进式训练方案,以构建新的视频基础模型系列。
所提出的视频基础模型被称为 InternVideo2,是通过渐进式训练方案构建的。学习涉及三个阶段:(1)通过无掩模重建捕获时空结构,(2)与其他模态的语义对齐,以及(3)通过下一个标记预测增强其开放式对话能力。在初始阶段,模型学习重建未屏蔽的视频标记,使视频编码器能够开发基本的时空感知能力。为了估计现有的标记,采用不同训练的视觉编码器(InternViT [Chen et al., 2023c] 和 VideoMAE-g [Wang et al., 2023b])作为代理。在跨模式学习的下一阶段,该架构将扩展为包括音频和文本编码器。这不仅改善了视频和文本之间的对齐,还赋予了 InternVideo2 处理视频音频任务的能力。通过结合这些额外的模式,模型对视频的理解得到了丰富,并与其语义保持一致。最后,在下一个令牌预测阶段,构建以视频为中心的对话系统和相应的指令微调数据集,以进一步调整 InternVideo2。通过将InternVideo2连接到LLM,视频编码器通过next-token预测训练进一步更新,增强其完成VQA和视频描述等开放式任务的能力。
对于InternVideo2的训练,我们强调数据的时空一致性和标签质量。我们构建了一个以视频为中心的大规模多模态数据集,由 4.02 亿个数据条目组成,其中包括 200 万个视频、5000 万个视频文本对(来自 WebVid [Bain 等人,2021] 和 InternVid [Wang 等人,2023d]), 50M 视频-音频-语音-文本对 (InternVid2) 和 300M 图像-文本对。具体来说,对于 InternVid2,我们在语义上将视频分割成剪辑,并专注于使用三种模式重新校准剪辑描述:音频、视频和语音。我们首先分别为这三种模式生成字幕。然后将各个字幕融合在一起以创建更全面的描述,这将提高模型准确理解和解释视频的能力。
我们在广泛的视频相关任务中评估了 InternVideo2。这些任务涵盖从基本的时空感知(例如动作识别)到高级推理任务(例如长视频或程序感知问答(QA)),如图 1 所示。结果(第 5 节)证明 InternVideo2 在多个任务上实现了最先进的性能,并且能够对一系列动作进行分析和推理。这种顶级性能意味着其有效捕获和理解视频内容的能力。这些实证研究结果证实,InternVideo2 可以作为通用视频编码器,用于未来视频理解的探索。总之,我们对视频理解的贡献如下。
本文介绍了 InternVideo2,这是一个具有竞争力的视频基础模型系列,它利用掩模重建、跨模态对比学习和下一个标记预测来使模型具有感知性、语义性,并能够在视频理解中进行推理。InternVideo2 为 60 多个视频/音频任务实现了最先进的性能。我们的模型在视频相关对话和长视频理解方面表现出了卓越的性能,凸显了其在建模高级世界知识方面的潜力。我们提供增强的数据集来训练InternVideo2。这包括训练期间音频数据的验证和合并,以及改进的字幕方法。这些改进导致模型性能和泛化能力显着增强。
2 Related Work
Video Foundation Models. 考虑到其广泛的应用,学习视频基础模型的研究变得越来越重要\cite{cpd,videoclip,umt,wang2022internvideo,videoprism,wang2023masked,videococa,st_mae,wang2023allinone,videomae,wang2023videomae}。构建视频基础模型 (ViFM) 的典型方法包括视频文本对比学习 \cite{cpd,videoclip,wang2022internvideo}、屏蔽视频建模 \cite{videomae,wang2023videomae,wang2022internvideo,violet} 和下一个标记预测 \cite{flamingo, sun2023emu1,sun2023emu2}。具体来说,All-in-one \cite{wang2023allinone} 使用具有统一多个预训练目标的单个骨干网。另一方面,UMT \cite{umt} 将掩模建模与视频文本对比学习相结合,在动作识别和视频语言任务中表现出强大的性能。另一种方法是 mPLUG-2 \cite{xu2023mplug},它引入了一种用于调制不同模式的新设计。它共享一个跨模式的通用模块,以加强关系,同时纳入针对歧视的特定模式模块。除了视频文本预训练之外,研究人员还探索了使用视频中的音频信息来提高性能。 MERLOT Reserve \cite{zellers2022merlot} 使用大规模视频-语音-转录对数据集学习视频表示。 VALOR \cite{chen2023valor} 采用独立的视频、音频和文本编码器,并训练联合视觉-音频-文本表示。 VAST \cite{chen2024vast} 构建了一个视听语音数据集,并开发了一个在视频音频相关任务中表现出色的多模态骨干网。 VideoPrism \cite{videoprism} 将视频文本对比学习和视频标记重建结合到公共和专有视频上,在各种视频任务中取得了领先的结果。
Multimodal Large Language Models. 随着大型语言模型 (LLM) 的进步 [Devlin et al., 2018, Raffel et al., 2020, Brown et al., 2020],它们的多模态版本 (MLLM) 变得越来越流行,因为它可以处理开放世界任务。像 Flamingo [Alayrac et al., 2022] 这样的开创性作品在一系列多模态任务中表现出了出色的零/少样本性能 [Goyal et al., 2017b, Plummer et al., 2015, Xu et al., 2016, Marino et al., 2016]等,2019]。公共 MLLM [Zhu et al., 2023b、Liu et al., 2023、Gong et al., 2023] 例如 LLaVA [Liu et al., 2023] 和 InstructBLIP [Dai et al., 2023] 提议使用视觉指令-调整数据以提高视觉对话能力。一些以视频为中心的 MLLM 已经被提出,例如 VideoChat [Li et al., 2023c]、VideoChatGPT [Maaz et al., 2023] 和 Valley [Luo et al., 2023],通过使用指令数据将视频编码器连接到用于开放世界视频理解的大语言模型。
3 Method
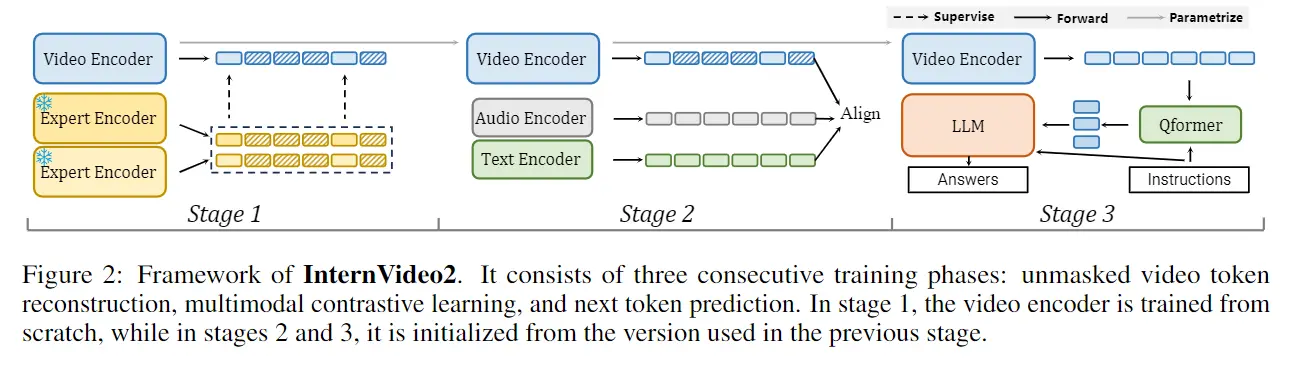
我们分三个阶段学习 InternVideo2,如图 2 所示。这些阶段包括时空标记重建、视频-音频-语音-语言对比学习以及连接到大型语言模型 (LLM) 进行联合训练。
Video Encoder. InternVideo2 中使用的视频编码器遵循 Vision Transformer (ViT) [Dosovitskiy et al., 2020],并包含用于蒸馏的附加投影层。受到之前作品的启发 [Chen et al., 2023c, Yu et al., 2022],我们将注意力池引入到 ViT 中。对于输入视频,我们稀疏采样 8 帧 [Wang et al., 2016] 并执行 14×14 (h × w) 空间下采样。然后将这些时空标记与类标记连接起来,并与 3D 位置嵌入相结合。 ViT-6B 架构的详细信息在 Supp 中给出。
3.1 Stage1: Reconstructing Unmasked Video Tokens
我们利用两个专家模型来指导视频编码器对未屏蔽区域进行标记级重建。具体来说,我们采用 InternVL-6B [Chen et al., 2023c] 和 VideoMAEv2-g [Wang et al., 2023b] 通过简单的投影层传输未屏蔽的知识。训练时,我们将完整视频输入给不同的教师,在多模态模型 InternVL 和运动感知模型 VideoMAEv2 的语义指导下,逐帧屏蔽 80% 的标记。我们仅通过最小化学生和教师之间的均方误差(MSE)来对齐未屏蔽的标记。学习目标是将剩余的标记重构为:
L
=
1
Z
∑
(
α
1
∣
f
V
(
V
p
)
−
h
(
V
p
)
∣
2
+
α
2
∣
f
V
(
V
p
)
−
g
(
V
p
)
∣
2
)
,
\begin{equation} \mathcal{L} = \frac{1}{Z}\sum_{}{(\alpha_1|f^V(\mathbf{V}_p)-h(\mathbf{V}_p)|^2+\alpha_2|f^V(\mathbf{V}_p)-g(\mathbf{V}_p)|^2)}, \end{equation}
L=Z1∑(α1∣fV(Vp)−h(Vp)∣2+α2∣fV(Vp)−g(Vp)∣2),其中
f
V
f^V
fV、
h
h
h 和
g
g
g 分别是我们的视频编码器、VideoMAEv2 的 InternViT-6B \cite{chen2023internvl} 和 ViT-g。
p
p
p 代表 token 索引,
f
(
V
p
)
f(\mathbf{V}_p)
f(Vp) 是 InternVideo2 为输入视频
V
\mathbf{V}
V 提取的相应 token。
Z
Z
Z 是标准化因子。
α
1
\alpha_1
α1 和
α
2
\alpha_2
α2 平衡了所采用模型之间的影响。
在我们的实现中,我们随机初始化视频编码器,然后将不同层的输出(由可学习的多层感知器转换)与专家模型的输出对齐。具体来说,我们对齐:1) InternVL 的最后 6 层,2) VideoMAEv2 的最后 4 层,以及 3) InternVL 的最终输出标记。这些对齐是使用 l2 范数对视频编码器的相应输出进行的。简单地将不同的损失项相加以进行优化。预训练后,我们放弃那些投影层,只使用基本编码器。与仅在 UMT 和 VideoPrism 中使用多模态模型相比,我们的策略使视觉编码器具有多模态友好性,并增强了其对动作建模的时间敏感性。
3.2 Stage 2: Aligning Video to Audio-Speech-Text
我们利用视频和音频、语音和文本之间的对应关系来鼓励 InternVideo2 学习更多语义。实际上,InternVideo2 拥有庞大的视频编码器,其使用的音频和文本编码器相对轻量级。使用的音频编码器是一个用 BEAT 初始化的 12 层变压器 [Chen et al., 2023a] (90M)。它采用 64 维对数梅尔滤波器组频谱图作为输入,该频谱图是使用 25 毫秒汉明窗从 10 秒长的剪辑(用零填充)生成的。对于文本和语音编码器,我们使用 BERT-Large 初始化文本编码器和多模态解码器 [Devlin et al., 2018]。具体来说,我们利用 BERT-Large 的最初 19 层作为文本编码器,随后配备交叉注意力层的 5 层作为多模态解码器。
对于预训练目标,我们通过文本(包括视频、音频、图像和语音)建立跨不同模式的一致性。我们采用跨模态对比和匹配损失与掩码语言重建损失:
L
=
L
CON
+
L
MAC
+
L
MLM
,
\begin{equation} \mathcal{L} = \mathcal{L}_\text{CON} + \mathcal{L}_\text{MAC} + \mathcal{L}_\text{MLM}, \end{equation}
L=LCON+LMAC+LMLM,使用的
L
MAC
\mathcal{L}_\text{MAC}
LMAC 和
L
MLM
\mathcal{L}_\text{MLM}
LMLM 是来自 \cite{Cheng2022VindLUAR} 的标准损失。具体来说,跨模态对比学习给出为:
L
CON
=
∑
M
,
T
M
′
L
CON
(
M
,
T
M
′
)
=
−
∑
M
,
T
M
′
(
∑
i
=
1
N
log
exp
(
sim
(
f
i
M
,
f
i
T
M
′
)
/
τ
)
∑
j
=
1
N
exp
(
sim
(
f
i
M
,
f
j
T
M
′
)
/
τ
)
+
∑
i
=
1
N
log
exp
(
sim
(
f
i
T
M
′
,
f
i
M
)
/
τ
)
∑
j
=
1
N
exp
(
sim
(
f
i
T
M
′
,
f
j
M
)
/
τ
)
)
,
\begin{align} \mathcal{L}_{\text{CON}} = \sum_{M, T_{M'}}\mathcal{L}_{\text{CON}}(M, T_{M'}) = -\sum_{M, T_{M'}} \left( \sum^N_{i=1} \log \frac{\exp(\text{sim}(f^{M}_i, f^{T_{M'}}_i) / \tau)}{\sum^N_{j=1} \exp(\text{sim}(f^{M}_i, f^{T_{M'}}_j) / \tau)} + \sum^N_{i=1} \log \frac{\exp(\text{sim}(f^{T_{M'}}_i, f^{M}_i) / \tau)}{\sum^N_{j=1} \exp(\text{sim}(f^{T_{M'}}_i, f^{M}_j) / \tau)} \right), \end{align}
LCON=M,TM′∑LCON(M,TM′)=−M,TM′∑(i=1∑Nlog∑j=1Nexp(sim(fiM,fjTM′)/τ)exp(sim(fiM,fiTM′)/τ)+i=1∑Nlog∑j=1Nexp(sim(fiTM′,fjM)/τ)exp(sim(fiTM′,fiM)/τ)),其中
f
V
f^{V}
fV 和
f
T
f^{T}
fT 分别表示学习的视频和文本嵌入。
M
M
M和
T
M
′
T_{M'}
TM′分别表示输入信号的模态和描述的文本描述。
sim
(
⋅
)
\text{sim}(\cdot)
sim(⋅) 计算两个特征之间的余弦相似度。
τ
\tau
τ 是可学习的温度。
对于匹配部分,其给出为:
L
MAC
=
−
y
log
f
p
(
V
,
T
)
−
(
1
−
y
)
log
(
1
−
f
p
(
V
,
T
)
)
,
\begin{equation} \mathcal{L}_{\text{MAC}} = - y \log f_p(\mathbf{V}, \mathbf{T}) - (1-y)\log (1-f_p(\mathbf{V}, \mathbf{T})), \end{equation}
LMAC=−ylogfp(V,T)−(1−y)log(1−fp(V,T)),其中
f
p
(
V
,
T
)
f_p(\mathbf{V}, \mathbf{T})
fp(V,T)计算
V
\mathbf{V}
V和
T
\mathbf{T}
T之间的匹配可能性。
y
y
y 表示给定的视频和文本是否配对 (
y
=
1
y=1
y=1) 或不配对 (
y
=
0
y=0
y=0)。
采用的掩码语言建模损失为:
L
MLM
=
−
log
f
p
T
(
T
j
∣
T
<
j
)
,
\begin{equation} \mathcal{L}_{\text{MLM}} = - \log f_p^T(\mathbf{T}_j|\mathbf{T}_{<j}), \end{equation}
LMLM=−logfpT(Tj∣T<j),其中
f
p
T
(
T
j
∣
T
<
j
)
f_p^T(\mathbf{T}_j|\mathbf{T}_{<j})
fpT(Tj∣T<j) 根据之前的文本标记计算
j
th
j_\text{th}
jth 文本标记的可能性。这里
T
\mathbf{T}
T指的是视频字幕。
为了提高训练效率,我们采用屏蔽学习策略,首先将未屏蔽的视频标记与其他模态的标记对齐,然后立即使用完整的视频标记重建。具体来说,包括以下两个步骤:
Aligning Masked Visual-Language-Audio. 我们冻结音频编码器并专注于对齐视觉、音频和文本特征。对于预训练,我们使用一套全面的图像、视频和音频视频数据。使用的模态组合表示为
{
M
,
T
M
′
}
∈
{
{
I
,
T
I
}
,
{
V
,
T
V
}
,
{
V
,
T
VAS
}
,
{
VA
,
T
VAS
}
}
\{M, T_{M'}\} \in \{ \{I, T_I\}, \{V, T_V\}, \{V, T_\textit{VAS} \}, \{\textit{VA}, T_\textit{VAS}\}\}
{ M,TM′}∈{ { I,TI},{ V,TV},{ V,TVAS},{ VA,TVAS}} 其中每对表示来自各自模态的串联特征。
Unmasked Visual-Audio-Language Post-Pretraining. 我们冻结视觉编码器以联合对齐音频、视觉和文本特征。后预训练是使用较小的图像和视频数据子集(25M 样本)以及全套音频(0.5M 样本)和音频视频数据(50M 样本)进行的。由于最大的 ViT-6B 模型的参数被冻结,因此我们在此阶段不使用屏蔽策略,以确保与推理过程的一致性,并最大限度地减少下游任务中的性能下降。这里使用的模态组合是
{
M
,
T
M
′
}
∈
{
{
I
,
T
I
}
,
{
V
,
T
V
}
,
{
A
,
T
A
}
,
V
,
T
VAS
}
,
{
VA
,
T
VA
}
}
}
\{M, T_{M'}\} \in \{ \{I, T_I\}, \{V, T_V\}, \{A, T_{A}\}, \ {V,T_\textit{VAS}\},\{\textit{VA},T_\textit{VA}\}\}\}}
{ M,TM′}∈{ { I,TI},{ V,TV},{ A,TA}, V,TVAS},{ VA,TVA}}}。
3.3 Stage3: Predicting Next Token with Video-Centric Inputs
为了进一步丰富 InternVideo2 中嵌入的语义并提高其对以视频为中心的对话的支持,我们通过将其连接到具有 QFormer 设计的 LLM 来对其进行调整 [Li et al., 2022a,b]。我们采用 [Li et al., 2023d] 中的渐进式学习方案,使用 InternVideo2 作为视频编码器,并训练视频 blip 以与开源 LLM 进行通信 [Zheng et al., 2023; Jiang et al., 2023]。此外,我们还实现了高清后训练阶段,以提高模型的细粒度和长时空能力。在此阶段,输入视频被分为最多 6 个子视频,每个子视频的分辨率为 224x224 像素,以及一个具有相同分辨率的全局调整大小的子视频。然后,我们训练模型另外两个时期:第一个时期使用 8 帧视频输入,而第二个时期使用 16 帧输入。在额外的训练过程中,我们更新视频编码器和 BLIP Qformer,同时使用 LoRA 更新 LLM [Hu et al., 2021]。
4 Multimodal Video Data
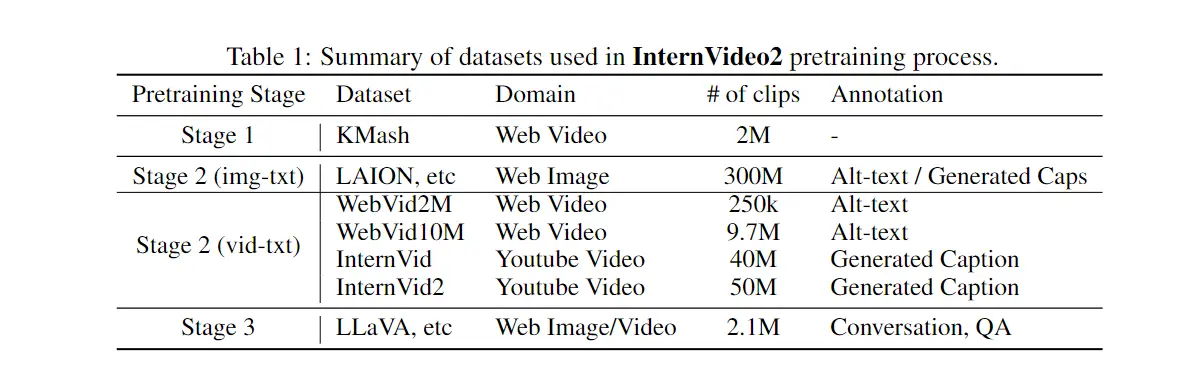
我们在表1中列出了我们的训练数据。 使用的数据集中,KMash和InternVid2是新建的,其余数据集是公开的。
4.1 Video-only Data for Masked Autoencoders
我们从动作识别数据集中策划了一个没有标签的新视频集,名为 K-Mash [Carreira 和 Zisserman, 2017, Goyal et al., 2017a, Monfort et al., 2020, Heilbron et al., 2015, Chao et al., 2019 ],详见补充材料。它包含多种视频类型,包括第一人称和第三人称视角,持续时间有短有长,并且具有各种设置。此外,我们还为 K-Mash2M 提供了来自 YouTube 的额外来源和精选的 844K 视频,以实现多样性。
4.2 Videos with Audio-Speech Modalities
我们构建了一个多模态视频数据集,称为 InternVid2,其中包含视频-音频-语音信息及其描述,用于通过其他模态增强视频感知。它由 1 亿个视频及其 VAS 字幕组成。在 InternVid2 中,我们从多个来源收集视频(在supp中详细介绍),将它们分割成剪辑,并根据其单模态或跨模态输入自动注释它们。我们强调了时间分割在剪辑生成和我们的视频多模态注释系统中的重要性。我们发现改进它们可以带来显着的下游改进。
时间一致性很重要。我们采用时间边界检测模型 AutoShot [Zhu et al., 2023c] 将视频分割成剪辑,而不是使用 FFmpeg 中的 SceneDet 过滤器。它根据时间语义变化而不是像素差异来预测边界,并且能够生成语义上完整的剪切,而无需将额外的帧与不一致的上下文混合在一起。
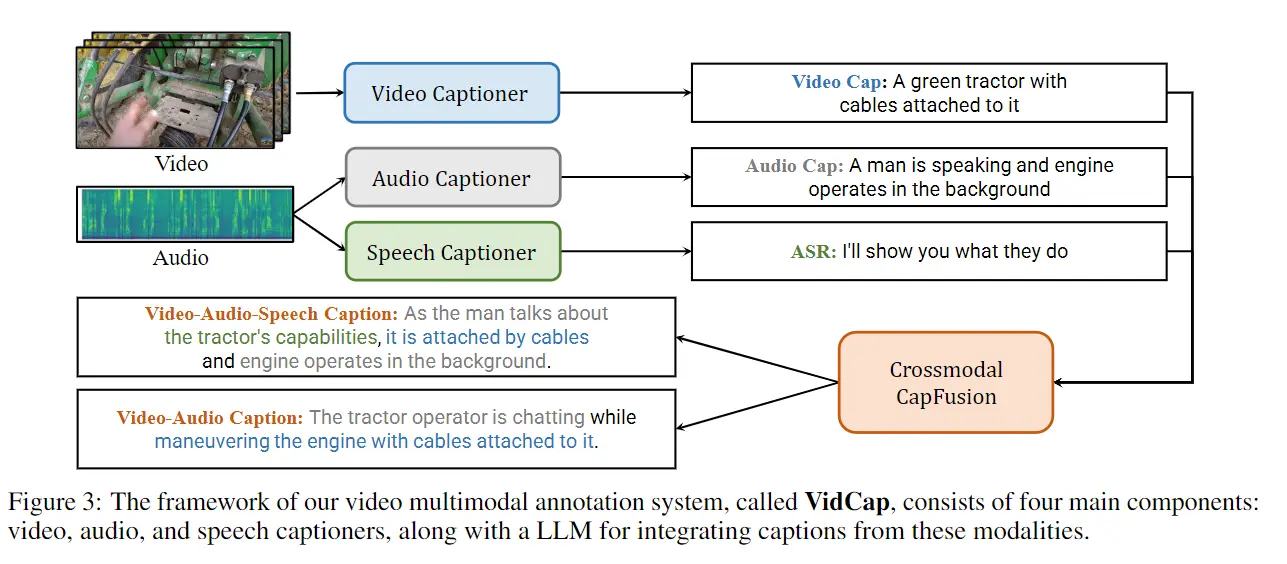
视频多模态注释。我们设计了一个视频多模态注释系统 VidCap,为不同感知的视频文本化提供适当的单模态和跨模态描述。它自动为 InternVid2 的视觉、音频和语音添加字幕,然后纠正它们并通过 LLM 将它们融合为跨模式字幕。系统框架如图3所示。VidCap具有独立的视频、音频、语音字幕器,以及用于字幕细化和融合的LLM。对于视频、语音和字幕后处理,我们采用现有方法作为视频字幕管道 [Wang et al., 2023d]、WhisperV2-large 模型 [Radford et al., 2023] 和 Vicuna-1.5 [Zheng et al., 2023]。 ,2023]。对于音频,我们在 VideoChat 上制作了一个音频字幕生成器 [Li et al., 2023c],因为我们没有找到开源的音频字幕生成器。它从 Beats 的输入中提取音频特征 [Chen et al., 2023a]。我们仅通过使用大规模音频文本语料库 WavCaps [Mei et al., 2023] 数据集的组合来调整其 Qformer 来学习它。补充材料中给出了详细信息。
4.3 Instruction-Tuning Data for Video Dialogue
我们采用更新的 MVBench 训练版本 [Li et al., 2023d]。最初,它包含来自 34 个不同来源的 190 万个样本(图像和视频)。我们将来自 WebVid 和 CoCo 的字幕数据量分别减少到 80k 和 100k,并添加来自 S-MiT 的新数据,以提高指令数据集的多样性而不是数量。在额外的 HD 训练阶段,我们将来自 [Chen et al., 2024a] 的带有相应 GPT-4 注释的视频合并到训练集中。我们通过包含来自 PerceptionTestQA [Patraucean et al., 2024]、TVQA [Lei et al., 2018]、NTU-RGB-D [Liu et al., 2020] 和 EgotaskQA [Grauman et al., 2020] 的数据集进一步扩展了训练集., 2022],以及基于 DiDeMo [Anne Hendricks et al., 2017] 和 COCO [Lin et al., 2014] 的基础数据集。该训练数据涵盖关键任务中图像和视频理解的关键特征,包括 1) 对话、2) 标题、3) 视觉问题解答、4) 推理和 5) 分类。
5 Experiments
在对 InternVideo2 的评估中,我们评估了三个学习阶段的模型。评估涵盖了广泛的任务,包括视频识别、视频检索、问答等。它包括零样本学习、微调和线性探测等各种场景。
对于第 1、2 和 3 阶段训练的 InternVideo2,我们分别用 InternVideo2s1、InternVideo2s2 和 InternVideo2s3 表示。我们还学习了由 InternVideo2clip 表示的 CLIP 风格的 InternVideo2。它是通过仅保留视频和文本编码器以及对比损失从 InternVideo2s2 进行后预训练的。
InternVideo2-6B 的每个训练阶段都使用不同的配置和资源。在第一阶段,我们使用 256 个 NVIDIA A100 GPU 并训练模型 18 天。第二阶段也使用 256 个 A100 GPU,训练时间为 14 天。最后,在第三阶段,我们使用 64 个 A100 GPU 并训练模型 3 天。我们引入 DeepSpeed 和 FlashAttention [Dao et al., 2022] 用于训练和推理。更多的实现细节和实验结果在支持中给出。
5.1 Video Classification
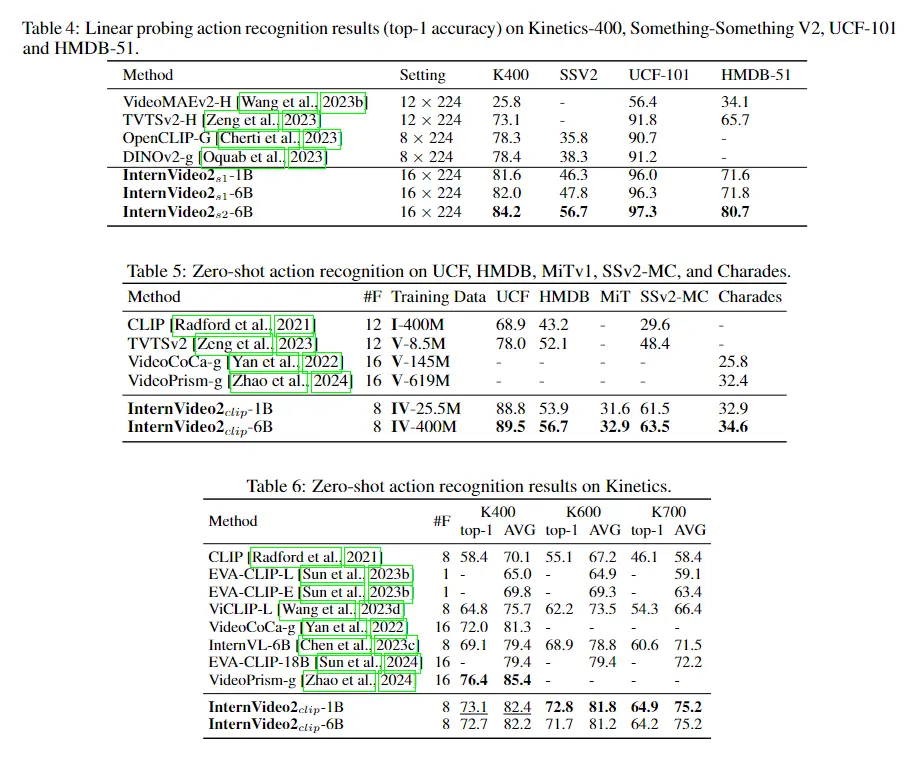
5.1.1 Action Recognition
我们在动力学上Kinetics 测试了 InternVideo2(即 K400、600 和 700 [Carreira 和 Zisserman,2017,Carreira 等人,2018,2019])、Moments in Time V1 (MiT) [Monfort 等人,2020]、Something- Something V2 (SSv2) [Goyal 等人,2017a]、UCF [Soomro 等人,2012]、HMDB [Kuehne 等人,2011]、Charades [Gao 等人,2017]、ActivityNet [Heilbron 等人,2017] ,2015](ANet)和 HACS [Zhao et al.,2019]。我们在四种设置中进行评估:(a)对整个骨干网进行端到端微调;(b) 注意力探测与线性池化类似,但额外训练注意力池层 [Yu et al., 2022]。 © 线性探测,冻结骨干网,仅训练任务负责人; (d) 零样本。
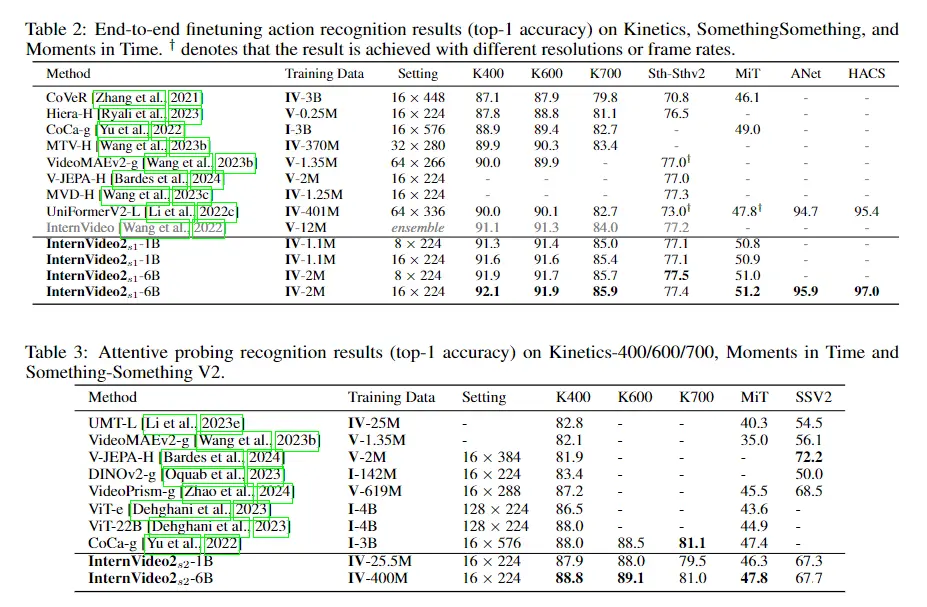
端到端微调。表 2 显示,InternVideo2-6B 仅用 16 帧就在动力学(K400/600/700 上分别为 92.1%/91.9%/85.9%)、SthSthv2、MiT、ANet 和 HACS 上获得了新的最先进 (SOTA) 结果帧,而以前的 SOTA 需要更大的分辨率(224 与 576)或模型集合。至于表2中的 MiT。 InternVideo2-6B 比之前的 SOTA CoCa-g 大幅提升了 2.2%(51.2% vs. 49.0%)。关于表中与时间相关的操作。如表 2 所示,我们的 InternVideo2-6B 也超过了 SSv2 上的 MVD [Wang et al., 2023c](77.5% vs. 77.3%)。此外,我们的 InternVideo2-6B 在未修剪的视频分析方面展示了最佳性能,如表 2 所示。 ActivityNet 上的占比为 95.9%,HACS 上的占比为 97.0%。这些结果证实了我们的模型在不同场景中稳健识别复杂动作的卓越能力。注:“I”和“V”分别表示图像和视频。 “IV-3B”表示使用的图像和视频总数为3B,而“I-3B”表示使用3B图像。
细心探查Attentive Probing。如表3所示。InternVideo2-6B不仅在以场景为中心的数据集中优于ViT-22B [Dehghani et al., 2023]和CoCa-g [Yu et al., 2022],而且超越或匹配最新视频基础模型的性能[ Bardes 等人,2024,Zhao 等人,2024],关于强调时间动态的数据集(SthSthV2)。这强调了我们的模型有效理解和解释空间和时间信息的卓越能力。
线性探测。如表 4 所示,InternVideo2-1B 的性能显着优于之前的 SOTA、DINOv2-g [Oquab 等人,2023],差距显着:K400 上 +3.2%,SthSthV2 上 +8.0%,UCF-101 上 +4.8%。当我们扩展模型时,观察到结果呈上升趋势,强调了模型增强的好处。值得注意的是,多模式预训练(第 2 阶段)的整合使结果进一步提高。我们假设第二阶段增强了特征辨别力。
零射击Zero-shot.。表 5 和表 6 显示,InternVideo2 在 K400/600/700 上分别获得 72.7%/71.7%/64.2%,优于除 VideoPrism 在 K400 上的其他产品(76.4%)。在 UCF [Soomro et al., 2012]、HMDB [Kuehne et al., 2011]、MiT [Monfort et al., 2020]、SSv2-MC 和 Charades 上,InternVideo2 比其他方法具有领先优势。K400 上 VideoPrism 和 InternVideo2 之间的明显差距可能表明 VideoPrism 中预训练语料库(311M 带文本的视频,其中 36.1M 是手动标记的)对于 K400 零样本的重要性。请注意,在 Kinetics、UCF101 和 HMDB51 数据集上,其分布更接近 stage1 中使用的预训练数据集,Internvideo2-6B 的性能略逊于 Internvideo2-1B。我们认为这是由于Internvideo2-6B在stage2中使用了更丰富的预训练数据集,导致stage1中的预训练数据被遗忘造成的。
5.1.2 Temporal Action Localization
我们在四个时间动作定位(TAL)数据集上评估模型:THUMOS14 [Idrees et al., 2017]、ActivityNet [Krishna et al., 2017]、HACS Segment [Zhao et al., 2019] 和 FineAction [Liu et al., 2017] al., 2022] 以基于特征的方式进行微调。我们使用 InternVideo2 第 7 层的输出作为输入作为相应的特征,而不融合其他任何东西。 ActionFormer [Anne Hendricks et al., 2017] 用作检测头。我们报告了多个 tIoU 下的平均平均精度(mAP),如 [Lin et al., 2019, Chen et al., 2022a, Anne Hendricks et al., 2017, Yang et al., 2023]。在表7中,InternVideo2-6B在所有数据集中的所有比较中获得最高的mAP,而InternVideo2-1B几乎超过除THUMOS14之外的其他方法。我们发现,除了 FineAction 之外,InternVideo2-6B 几乎始终如一地提高了 mAP,与 InternVideo2-1B 相比,差距显着。我们认为在没有数据细化的情况下扩展模型容量不能显着提高模型的细粒度辨别能力。在训练中缩放详细注释可能会解决这个问题。
5.1.3 Video Instance Segmentation
我们对视频实例分割 (VIS) 数据集 Youtube-VIS 2019 [Yang et al., 2019] 进行评估。基于 Mask2Former [Cheng et al., 2021],我们采用 InternVideo2 的视频编码器作为 ViT 适配器的主干[Chenet al., 2022b] 对于特征。我们还尝试使用 InternViT [Chen et al., 2023c] 进行比较。在表 8 中,InternVideo2 得到
其中 mAP 最高。这验证了其在相对细粒度的时空感知方面的有效性。
5.2 Video-Audio-Language Tasks
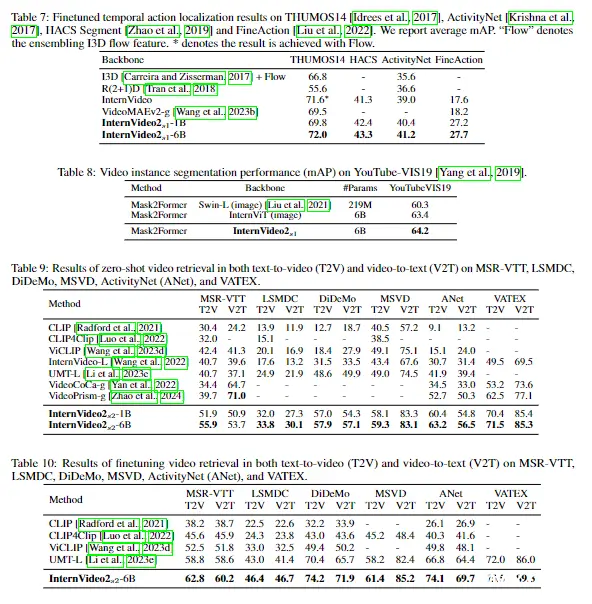
我们在视频检索、字幕和多选问答 (QA) 方面评估了 InternVideo2。前两个任务是通过在第 2 阶段中使用文本编码器匹配视频表示和候选文本来执行的。后者由第 3 阶段中学习的 VideoLLM 进行测试。我们还测试音频任务。
5.2.1 Video Retrieval
我们在六个流行的基准上评估视频检索:MSR-VTT [Xu et al., 2016]、LSMDC [Rohrbach et al., 2015]、DiDeMo [Anne Hendricks et al., 2017]、MSVD [Chen and Dolan, 2011] ]、ActivityNet (ANet) [Heilbron et al.,2016] 和 VATEX [Wang et al., 2019],如表 9 和 10 所示。 在评估中,对输入视频中的八帧进行均匀采样。我们在表9和10中报告了文本到视频 (t2v) 和视频到文本 (v2t) 任务的 R@1 分数 。R@5和R@10在补充中给出。
表 9 和 10 表明,InternVideo2 的性能优于其他最先进的技术,无论在零样本还是微调设置下,所有使用的数据集的 t2v 和 v2t 都有显着的优势,除了 MSR-VTT 的 v2t,其中 VideoPrism 给出最好的结果。这显示了 InternVideo2 传输性的视频语言语义对齐。
5.2.2 Video Temporal Grounding
我们在两个视频时间接地(VTG)数据集上评估 InternVideo2:QVhighlight [Lei et al., 2021] 和 Charade-STA [Gao et al., 2017]。 eval 设置和使用的功能与 TAL 中的相同。我们使用 CG-DETR [Moon et al., 2023] 作为接地头。我们报告 R1@0.3、R1@0.5、R1@0.7 和 mAP 用于矩检索,如 [Lei et al., 2021, Moon et al., 2023, Lin et al., 2023]。高光检测根据“非常好”mAP 和 HiT@1 进行评估。在表 11 中,与 CLIP [Radford et al., 2021] 和 CLIP [Radford et al., 2021]+Slowfast [Feichtenhofer et al., 2019] 相比,InternVideo2-1B 和 InternVideo2-6B 带来了逐步的性能改进。这表明更大的时空模型更有利于短期视频语义对齐能力。
5.2.3 Audio-related Tasks
我们在音频任务上评估了 InternVideo2 的音频和文本编码器,包括 AudioCaps [Kim et al., 2019]、Clotov1 和 Clothov2 [Drossos et al., 2020] 上的音频文本检索; ClothoAQA [Lipping et al., 2022] 和 Audio-MusicAVQA [Behera et al., 2023] 上的 audioQA;以及 ESC-50 上的音频分类 [Piczak,2015]。如表 12、13a 和 13b 所示,我们的模型在所有下游任务上都实现了最先进的性能。考虑到所使用的音频和文本编码器的大小有限,这些与音频相关的结果表明,跨模式对比学习的好处与所使用的模式是相互的。音频和相应的文本模型也从这种学习中受益。
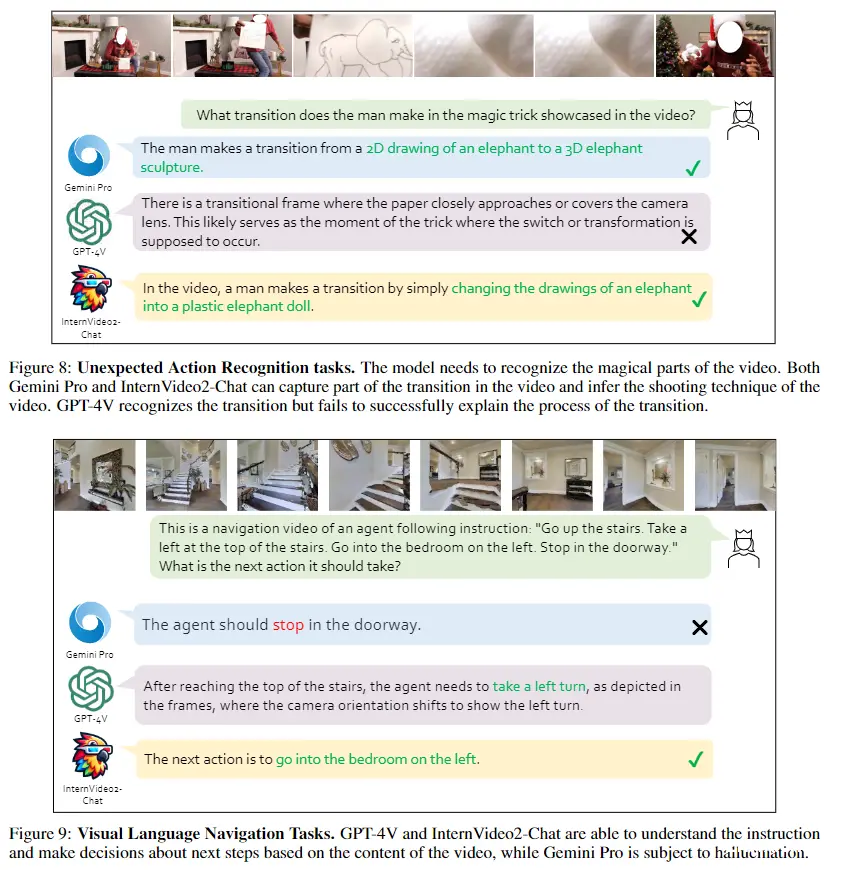
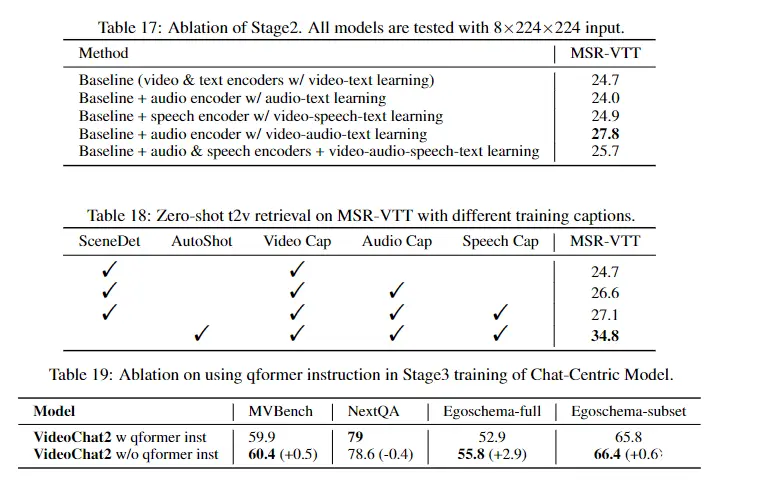
5.3 Video-centric Dialogue and its Applications
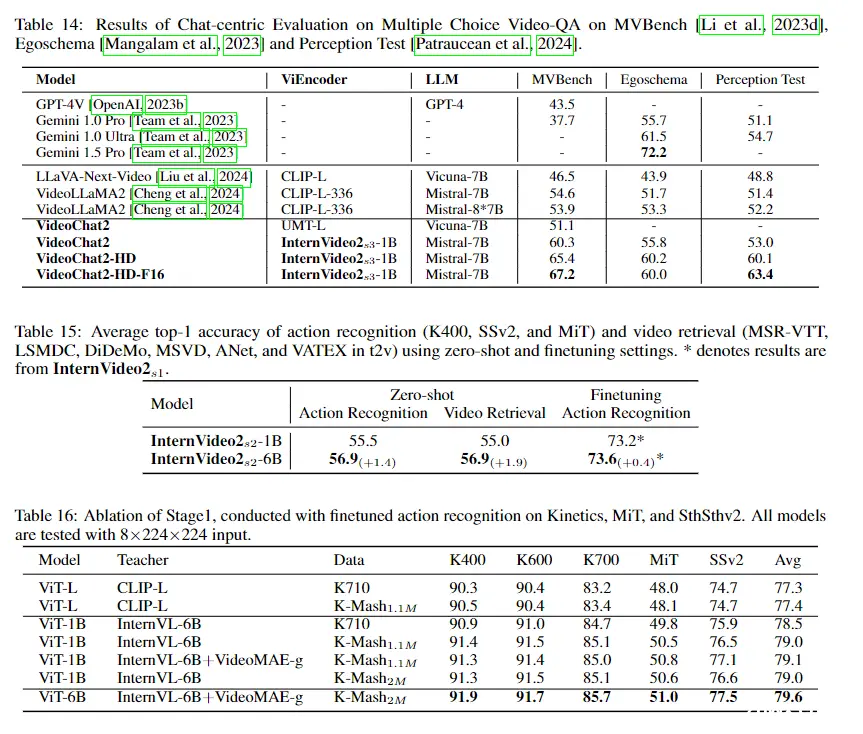
5.4 Ablation Studies
5.4.1 Scaling Video Encoder
表 23 给出了 InternVideo2 在动作识别和视频检索方面的平均性能。它表明,将视频编码器从 1B 缩放到 6B 仍然会导致动作识别和视频检索的泛化能力显着提高,分别提高了 1.4% 和 1.9%(在零样本中)。同时,随着模型规模的增长,微调动作识别结果的增长相对较小(0.4%)。
5.4.2 Training Data and used Teachers in Stage 1
表 24,我们检查了蒸馏教师和使用的数据集大小对模型性能的影响。 (a) 数据规模:注意MAE的预训练数据规模应随着模型规模的增加而增长,否则下游性能将饱和,例如ViT-L的K710(0.66M视频),ViT-的K-Mash1.1M 1B 和 ViT-6B 的 K-Mash2M。 (b) 教师:表 24 显示,多模式教师(例如 CLIP [Radford et al., 2021])和运动感知教师(例如 MAE [Tong et al., 2022])之间的协同作用显着提高了性能,尤其是在 SthSthV2 上。它凸显了战略性教师模型选择在升华过程中的重要性。
5.4.3 Training Arch, Method, and Data in Stage 2
我们消除了在第 2 阶段引入音频编码器的必要性。我们分别将 ViT-B 和 Bert-B 用于视频和文本编码器。使用的文字是简单的视频字幕。基线正在进行视频-文本对比和匹配以及掩蔽语言生成损失,以便仅使用视频和文本编码器进行训练。其他设置包括添加音频或语音编码器或两者,以及如何更新新添加的编码器,即是否仅使用文本编码器或同时使用视频和文本编码器来训练它们。表17表明,仅引入音频编码器并与视频和文本编码器一起学习它可以最好地提高视频文本检索性能。语音编码器或多或少地损害了这种有效性。
此外,我们验证了视频时间分割和使用标题作为标签中第 2 阶段文本输入的影响。 18.我们仍然使用ViT-B和Bert-B进行视频文本训练。表 18 发现视频-音频-语音的融合文本与其他文本相比最适合检索任务,MSR-VTT 的零样本 t2v R1 从 24.7 上升到 27.1。此外,使用 AutoShot 代替 SceneDet 显着提高了 t2v 检索(提高了近 7 个点)。它验证了所引入的视频文本数据集及其注释系统的有效性。
5.4.4 Training and Evaluation in Stage 3
如表 19 所示,在第 3 阶段训练期间将问题(即“QA”中的“q”)合并到 QFormer 中,这在 [Dai 等人,2023] 中发现很有用,实际上损害了缩放的域外性能。视频LLM。 NextQA 训练数据已包含在训练语料库中,这是问题注入版本表现更好的唯一基准。因此,我们认为在缩放的 VideoChat 模型的指令调整阶段向 QFormer 添加问题会导致某种程度的过度拟合。
6 Conclusion and Discussion
我们推出了一个名为 InternVideo2 的新视频基础模型系列,它在各种视频和音频任务中实现了最先进的性能。在InternVideo2中,我们将屏蔽视频建模、视频-音频-文本对比学习和下一个标记预测结合到一个统一的框架中。此外,我们创建了一个新的视频文本数据集,其中包含视频音频语音融合字幕作为描述。该数据集包含具有高语义一致性的时间分段剪辑。
InternVideo2 中的这些设计有助于增强感知和推理任务中的视频理解。值得注意的是,InternVideo2 在视频相关对话和长视频理解方面表现出色,证明了其在捕获高级语义方面的有效性。
Limitations and Discussions. 尽管取得了一些成就,InternVideo2 并没有引入具体新颖的架构设计。相反,它利用现有的学习技术来扩展视频基础模型,同时专注于改进数据处理,以增强其时空感知、语义对齐和基础知识嵌入。与之前的研究类似,InternVideo2 仍然面临着来自固定输入分辨率、采样率和高度压缩令牌的限制,这些限制限制了其表达丰富视频信息和捕获细粒度细节的能力。
InternVideo2采用的渐进式学习方案在模型能力和训练计算之间取得了平衡。虽然同时联合学习三个优化目标在计算上是可行的,但当面临有限的资源时,可扩展性就成为一个问题。
尽管InternVideo2在一些视频理解和推理基准测试中表现出了领先的性能,但它不能保证隐式世界模型确保视觉推理的一致性。固定输入表示所施加的固有限制,加上视觉推理任务的复杂性,给实现对视觉世界的全面和一致的理解带来了挑战。
Potential Biases. 我们在这里调查潜在的偏见。我们关注年龄、性别和种族分布,因为这些是公认的可能发生偏见的领域。
我们在使用的标题中计算与这些类别相关的关键字。请注意,这些合成字幕可能无法完全反映相应视频的真实情况,从而在我们的分析与实际情况之间造成差距。以下是我们的分析结果:
年龄
\textbf{年龄}
年龄:大多数是关于成年人(86.99%),其次是儿童(12.87%),几乎没有提到老年人(0.04%)。
性别
\textbf{性别}
性别:62.04%属于男性,37.96%属于女性。
种族
\textbf{种族}
种族:56.19%是亚洲人,23.04%是黑人,14.55%是白人,3.78%是中东人,2.43%是拉丁美洲人。
7 Broader Impact
必须承认,与其他基础模型类似,InternVideo2 有可能在其训练数据和训练期间使用的相关模型中嵌入存在的偏差,例如神经教师 [Tong 等人,2022 年;Chen 等人, 2023c] 和语言模型 (LLM) [Jiang et al., 2023, Cheng et al., 2023]。这些偏见可能是由于多种因素造成的,包括数据创建者的个人想法、偏好、价值观和观点以及所使用的训练语料库。
人工智能模型中存在的偏见可能会产生社会影响,并加剧现有的不平等或偏见。 InternVideo2 中的偏见可能以不公平或歧视性输出的形式表现出来,可能会导致训练数据中存在的社会偏见或刻板印象永久化。因此,仔细考虑在现实应用程序中部署 InternVideo2 的潜在影响并采取主动措施来减少偏见并确保公平性至关重要。

上一篇: 笔记本本地部署100b以上千亿级别LLM,并在手机端接入
下一篇: 最新版本Anaconda 2024.06-1安装设置
本文标签
【ECCV 2024】InternVideo2: Scaling Foundation Models for Multimodal Video Understanding
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。