MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions
kebijuelun 2024-08-23 12:31:24 阅读 87
Paper name
MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions
Paper Reading Note
Paper URL: https://arxiv.org/pdf/2407.06358v1
Project URL: https://mira-space.github.io/
Code URL: https://github.com/mira-space/MiraData?tab=readme-ov-file
TL;DR
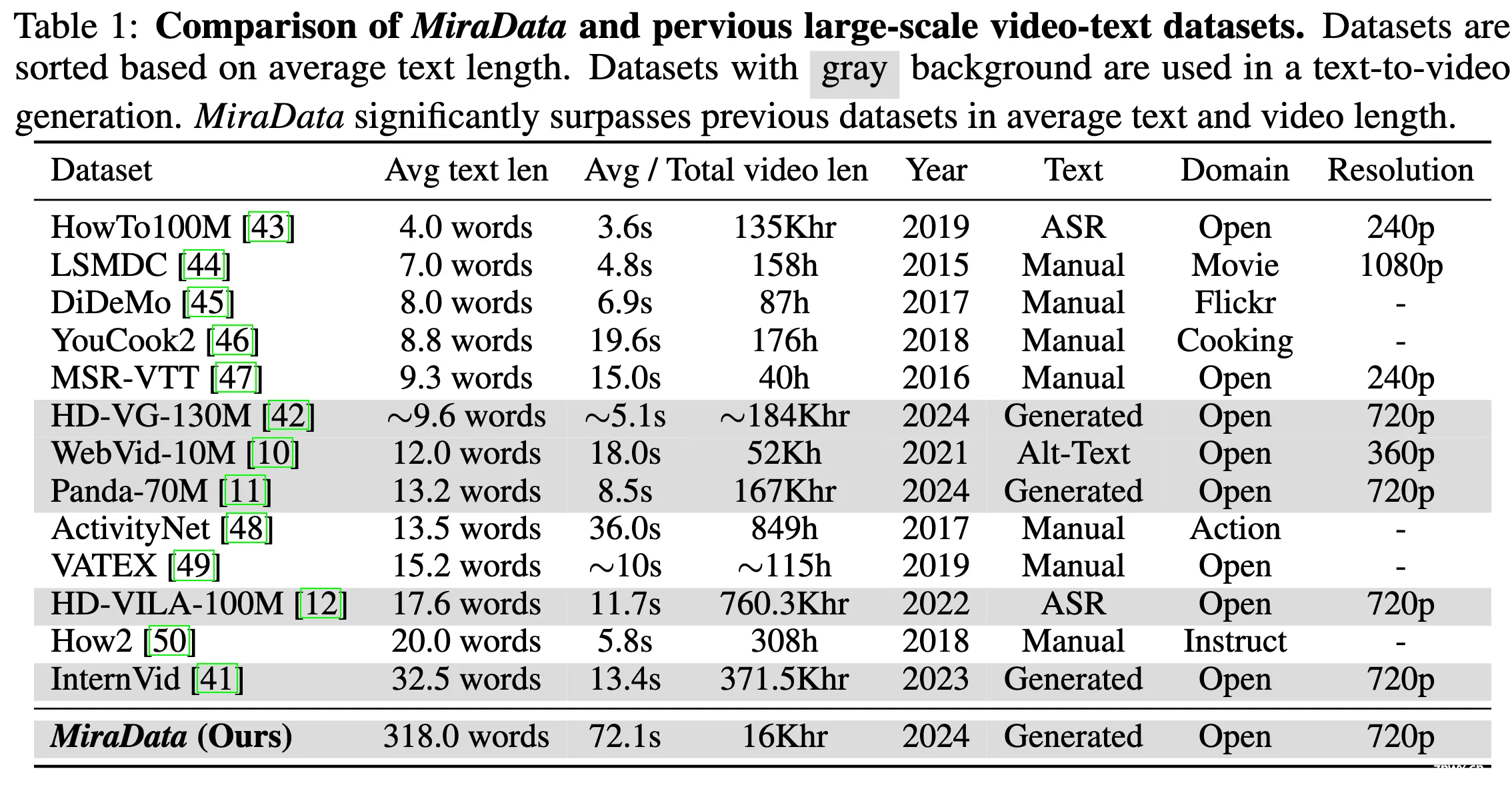
2024 腾讯 ARC Lab 文章,提出了 MiraData。MiraData 是大规模、高质量的视频数据集,具有长视频(平均72.1秒)、高运动强度和详细的结构化字幕(平均318字)。同时引入了 MiraBench 用于更好评估视频生成中的时间一致性和运动强度。使用基于 DiT 的视频生成模型 MiraDiT 进行实验,验证相比于当前公开的数据集,使用 MiraData 训练的模型具有更大的运动幅度和运动一致性。
Introduction
背景
Sora 的高运动强度和长时间一致性视频对视频生成领域产生了重大影响,吸引了前所未有的关注。然而,现有公开可用的数据集不足以生成类似 Sora 的视频,因为它们主要包含运动强度低、字幕简短的短视频。
如WebVid-10M、Panda-70M 和 HD-VILA-100M,主要由来自互联网未经过滤视频的短视频片段(5-18秒)组成,这导致了大量低质量或低运动片段,不足以训练生成类似 Sora 的模型。此外,现有数据集中的字幕通常较短(12-30字),缺乏描述视频所需的细节
本文方案
为了解决这些问题,我们提出了 MiraData,这是一个高质量的视频数据集,在视频时长、字幕详细程度、运动强度和视觉质量上均超越以往的数据集。
MiraData 是大规模、高质量的视频数据集,具有长视频(平均72.1秒)、高运动强度和详细的结构化字幕(平均318字)使用 GPT-4V 对结构化字幕进行标注:从四个不同的角度提供详细描述,并总结出密集的摘要字幕 为了更好地评估视频生成中的时间一致性和运动强度,我们引入了 MiraBench,通过添加 3D 一致性和基于跟踪的运动强度指标来增强现有基准
MiraBench 包含 150 个评估提示和 17 项指标,涵盖时间一致性、运动强度、3D 一致性、视觉质量、文本视频对齐和分布相似性。 我们使用基于 DiT 的视频生成模型 MiraDiT 进行实验
Methods
MiraData
数据处理整体流程,以下小结详细介绍各个步骤的处理细节

与之前数据集的比较
数据收集
在视频生成任务中,通常有四个关键期望:(1)内容多样性、(2)高视觉质量、(3)长时长和(4)大运动强度从YouTube、Videvo、Pixabay和Pexels中选择源视频,以确保视频生成任务有更全面和适合的数据来源。
YouTube:
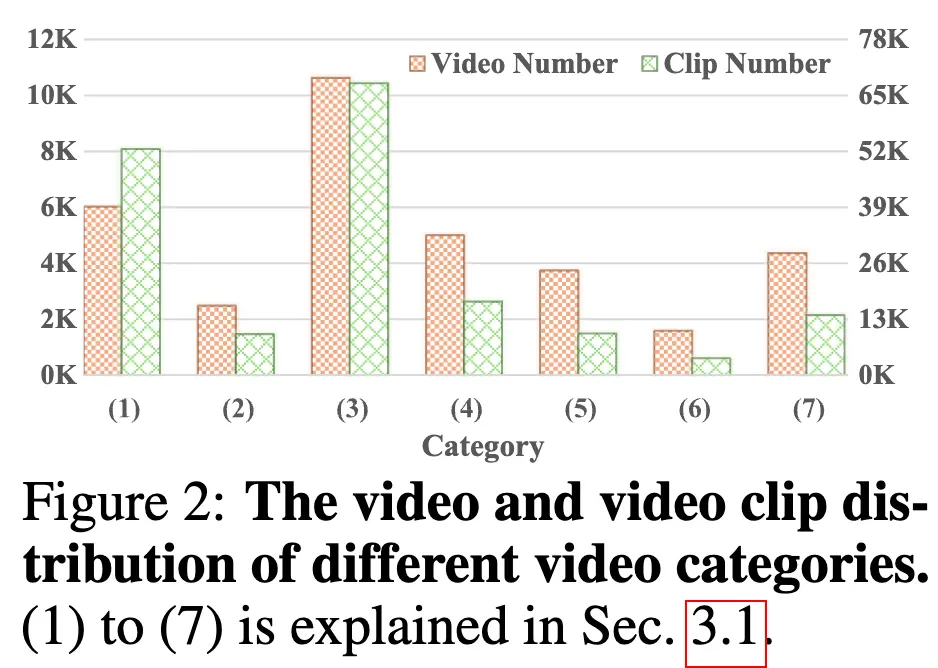
手动选择了156个适合生成任务的高质量YouTube频道。包括(1)3D引擎渲染场景、(2)城市/风景游览、(3)电影、(4)第一人称视角摄像视频、(5)物体创建/物理法则演示、(6)延时视频和(7)展示人体运动
收集了大约 68K 个 720p 分辨率的视频。切分后获得了大约 34K 个视频和 173K 个视频片段
从3D引擎渲染场景和电影中收集了更多视频,因为它们具有更大的多样性和更好的视觉质量。3D引擎渲染视频中物理法则的简单性和一致性对于使视频生成模型学习和理解物理法则至关重要
Videvo、Pixabay 和 Pexels 视频
这三个网站提供没有版权问题的库存视频和动态图形,通常是由技术娴熟的摄影师上传的高质量视频。
可以弥补YouTube视频在视觉质量方面的不足从Videvo收集了大约63K个视频,从Pixabay收集了43K个视频,从Pexels收集了318K个视频(K表示千)。
数据切分和拼接
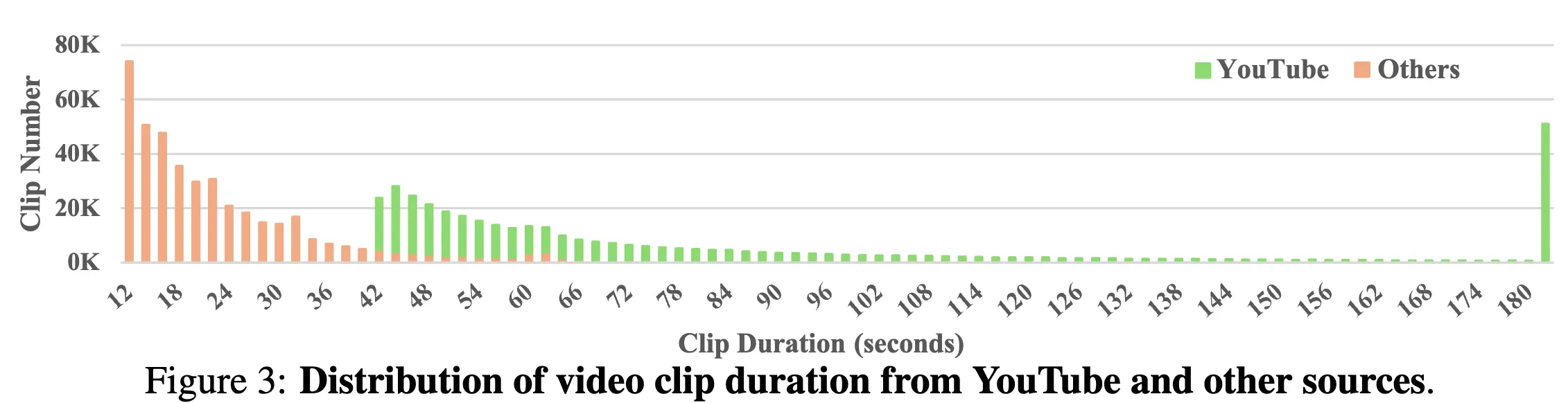
理想的视频剪辑应该具有语义连贯的内容,要么没有镜头转换,要么在转换之间具有强烈的连贯性。为此,我们对 YouTube 视频进行两阶段的拆分与拼接处理。在拆分阶段,我们使用低阈值的镜头变化检测将视频分割成多个片段,确保提取出所有不同的剪辑。然后,我们将短片段拼接在一起,以避免错误的分离,同时考虑内容连贯的视频过渡和准确性。
使用 Qwen-VL-Chat、LLaVA、ImageBind 和 DINOv2 来评估相邻的短片段是否应该连接。视觉语言模型在检测内容连贯过渡方面表现出色,而图像特征余弦相似性在连接错误分离方面更有效。只有当视觉语言模型或图像特征提取模型都同意时才会进行连接。保留超过 40 秒的剪辑用于 MiraData。由于 Videvo、Pixabay 和 Pexels 视频自然以剪辑形式存在,我们选择长度超过 10 秒的剪辑,以筛选出具有较强运动强度的较长视频。
视频选择
MiraData 提供了 5 个不同质量级别的数据版本用于视频生成训练,过滤标准包括四个标准:
(1)视频色彩:计算平均色彩和最亮与最暗的 80% 帧的色彩,过滤掉在过于明亮或黑暗环境中拍摄的视频(2)美学质量:使用 Laion-Aesthetic 进行美学分数预测(3)运动强度:使用 RAFT 计算帧之间的光流(4)NSFW 内容:Stable Diffusion Safety Checker 进行检测(每个视频选 8 帧)
视频字幕
如 PixArt 和 DALL-E 3 所强调的,字幕的质量和细粒度对文本到图像生成至关重要使用 GPT-4V 生成字幕
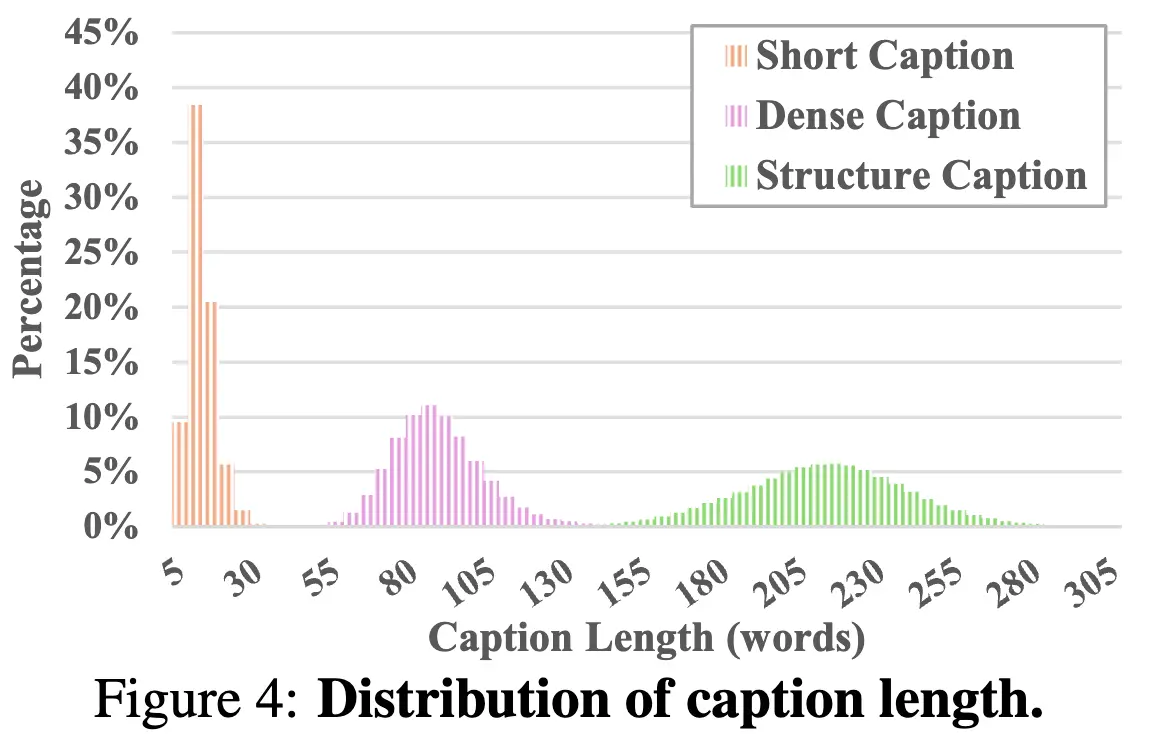
从每个视频中提取 8 个均匀采样的帧,并将它们排列成 2×4 网格的单个图像引导 GPT-4V 生成有助于学习文本到视频生成模型的视频描述。我们首先使用 Panda-70M 生成描述主要对象和动作的“短字幕”,作为 GPT-4V 的额外提示GPT-4V 生成的“密集字幕”涵盖了主要对象、动作、风格、背景和摄像机。 为了获得更详细、细粒度且准确的字幕,提出使用结构化字幕:(1)主要对象:描述视频中的主要对象或主体,捕捉它们的属性、动作、位置和移动,(2)背景:提供有关环境或设置的上下文,包括对象、位置、天气和时间,(3)摄像机移动:详细描述任何摄像机的平移、缩放或其他移动,以及(4)视频风格:涵盖视频的艺术风格以及视觉和摄影特征(例如写实、赛博朋克和电影化)。
数值统计对比
MiraData 比之前数据集的动作幅度、美学指标更高

MiraBench
提示选择
按照 EvalCrafter 的方法,我们提出了四类:人类、动物、物体和景观。我们随机选择了400个视频字幕,手动整理以在元类中实现平衡,并优先选择与原始视频最匹配的字幕。我们选择了50个精确的视频-文本对,使用简短、密集且结构化的字幕作为提示,形成一组150个提示。
评估指标设计
我们在 MiraBench 中设计了17个评估指标,从6个方面进行评估,包括时间一致性、时间运动强度、3D一致性、视觉质量、文本-视频对齐和分布一致性。这些指标涵盖了以前视频生成模型和文本到视频基准中常用的大多数评估标准。与以前的基准如 VBench 相比,我们的指标更强调模型在通用提示下的表现,而不是手动设计的提示,并强调 3D 一致性和运动强度。
时间运动强度
(1) 动态程度。使用 RAFT 估算的光流平均距离来估算动态程度。
(2) 追踪强度。在光流中,目标是估算视频帧内所有点的速度。这种估算是为所有点共同执行的,但运动仅在一个微小的距离上预测。在追踪中,目标是估算点在较长时间段内的运动。因此,追踪点的距离可以更好地区分视频是否涉及长距离或小范围的运动(例如相机抖动或来回移动的局部运动)。

如上图所示,左图的运动距离比右图小。然而,在图(b)中,左图的动态程度错误地为 1.2,右图为 0.7,表明左图的运动较大。图©中的追踪强度准确反映了移动距离,左图为 4.1,右图为 11.8。我们使用 CoTracker 计算追踪路径,并将追踪点从初始帧的平均距离作为追踪强度指标。
时间一致性
(3) DINO(结构)时间一致性。DINO 专注于结构信息。我们计算相邻帧的 DINO 特征的余弦相似性以评估结构时间一致性。
(4) CLIP(语义)时间一致性。我们计算相邻帧的 CLIP 特征的余弦相似性以评估语义时间一致性,因为 CLIP 专注于语义信息。
(5) 时间运动平滑度。按照 VBench,我们使用视频插值模型 AMT 中的运动先验来计算运动平滑度。由于较大的运动预期包含较小的一致性,反之亦然,我们将追踪强度乘以这些特征相似性以获得更合理的时间一致性指标。
3D 一致性
按照 GVGC,我们计算 (6) 平均绝对误差和 (7) 均方根误差,以从3D重建的角度评估视频的 3D 一致性。
视觉质量
(8) 美学质量。我们使用 LAION 美学预测器评估生成视频帧的美学得分。
(9) 图像质量。按照 VBench,我们使用 MUSIQ 质量预测器评估视频失真(例如过度曝光、噪声和模糊)。
文本-视频对齐
我们使用 ViCLIP 评估视频和文本之间的一致性。我们根据 MiraBench 提示结构从5个方面进行计算:
(10) 摄像机对齐。
(11) 主要物体对齐。
(12) 背景对齐。
(13) 风格对齐。
(14) 整体对齐。
分布相似性
使用 (15) FVD、(16) FID、(17) KID 评估生成和训练数据的分布相似性。
Experiments
MiraDiT 模型与实验设计
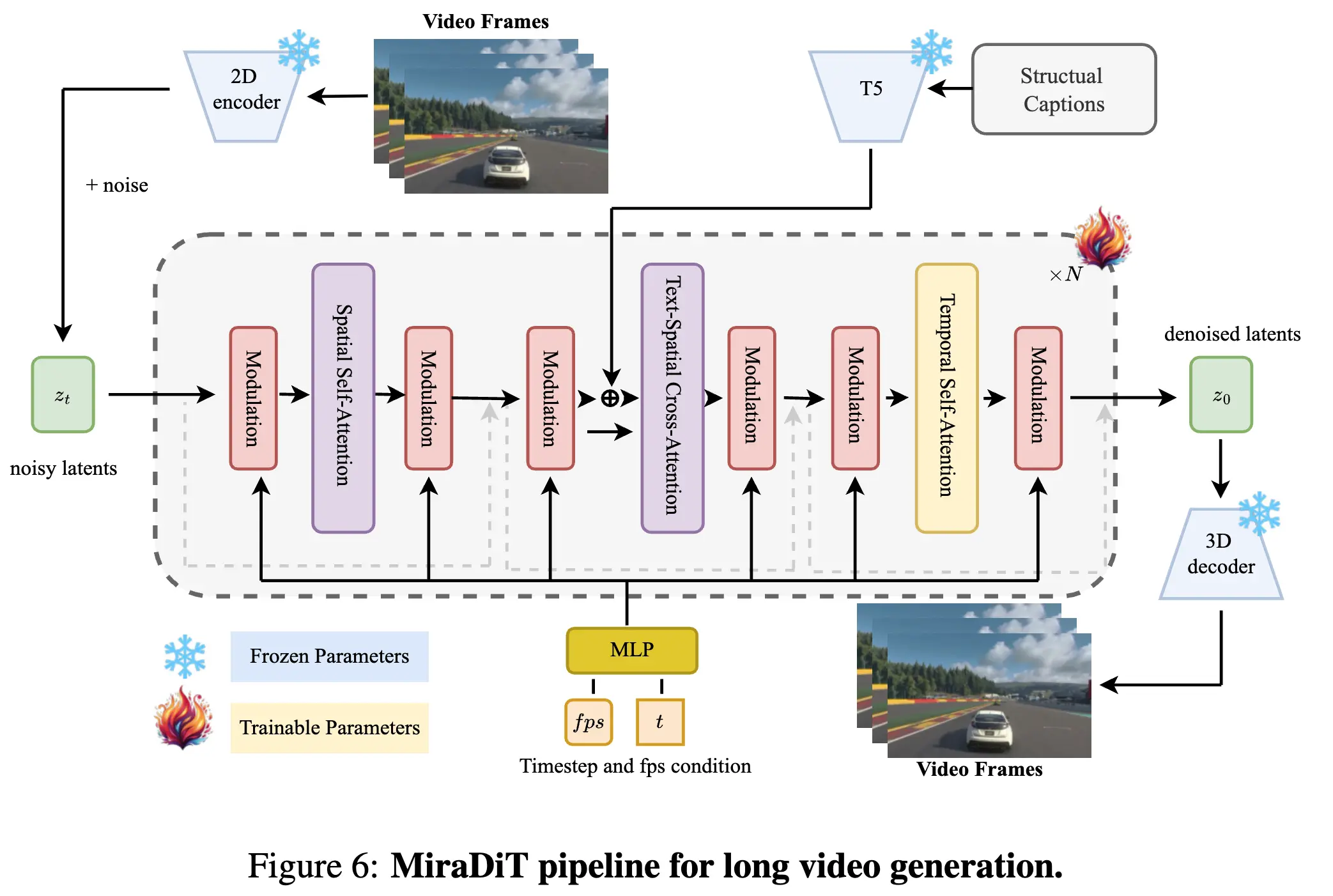
为了验证MiraData在生成一致长视频方面的有效性,我们设计了一种基于 DiT(Diffusion Transformer)的高效管道。根据 SVD,我们使用了混合变分自编码器(Variational Autoencoder),其中包含一个二维卷积编码器和一个三维卷积解码器,以减少生成视频中的闪烁现象。与依赖简短字幕并通常使用 77 个输出 token 的 CLIP 文本编码器的先前方法不同,我们采用了更大的 Flan-T5-XXL 进行文本编码,支持多达 512 个 token 以实现密集和结构化的字幕理解。文本-空间交叉注意力。为了实现 latent 去噪,我们构建了一个空间-时间 transformer 作为可训练的生成骨干网。如上图所示,我们分别采用了空间和时间自注意力,而不是对所有视频像素进行全注意力,以减少长视频生成的巨大计算负担。类似于 W.A.L.T,我们在交叉注意力期间对空间查询应用了额外的条件,以稳定训练并提高生成性能。为了更快收敛,我们部分从文本到图像模型 Pixart-alpha 的权重初始化空间注意力层,而其他层从头开始训练。基于FPS的调制。根据 DiT 和 SD3,我们使用了一个用于当前时间步条件的调制机制。此外,我们在 AdaLN 层中嵌入了额外的当前 FPS 条件,以在生成视频的推理过程中实现运动强度控制。动态帧长度和分辨率。我们训练 MiraDiT 时,支持生成具有不同分辨率和长度的视频,以评估模型在不同场景中运动强度和 3D 一致性方面的性能。受 NaViT 使用 Patch n’ Pack 实现动态分辨率训练的启发,我们采用 Frame n’ Pack 策略来训练具有不同时间长度的视频。具体来说,我们使用时间掩码随机丢弃带有零填充的帧,然后根据时间掩码应用掩码自注意力和位置嵌入。被掩码帧的梯度也会被停止。然而,对于不同分辨率的训练,我们没有采用Patch n’ Pack,因为在早期实验中它使得模型更难训练。相反,我们遵循 Pixart 的做法,使用一个桶策略,其中模型在不同分辨率的视频上进行训练,每个训练批次只包含相同分辨率的视频。推理细节。在推理过程中,我们使用具有 25 步和 guidance scale 12 的无分类引导的 DDIM 采样器。FPS 条件可以设置在 5 到 30 之间,允许生成视频的帧率灵活调整。为了评估目的,我们在 6 fps 下测试所有模型,以确保在不同设置下进行一致比较。为了进一步提高生成视频的视觉质量,我们提供了使用 RIFE 模型的可选后处理步骤。通过应用 4× 帧插值,我们可以将生成视频的帧率提高到 24 fps,从而实现更平滑的运动和改进的整体外观。
与之前的 video 生成数据集对比
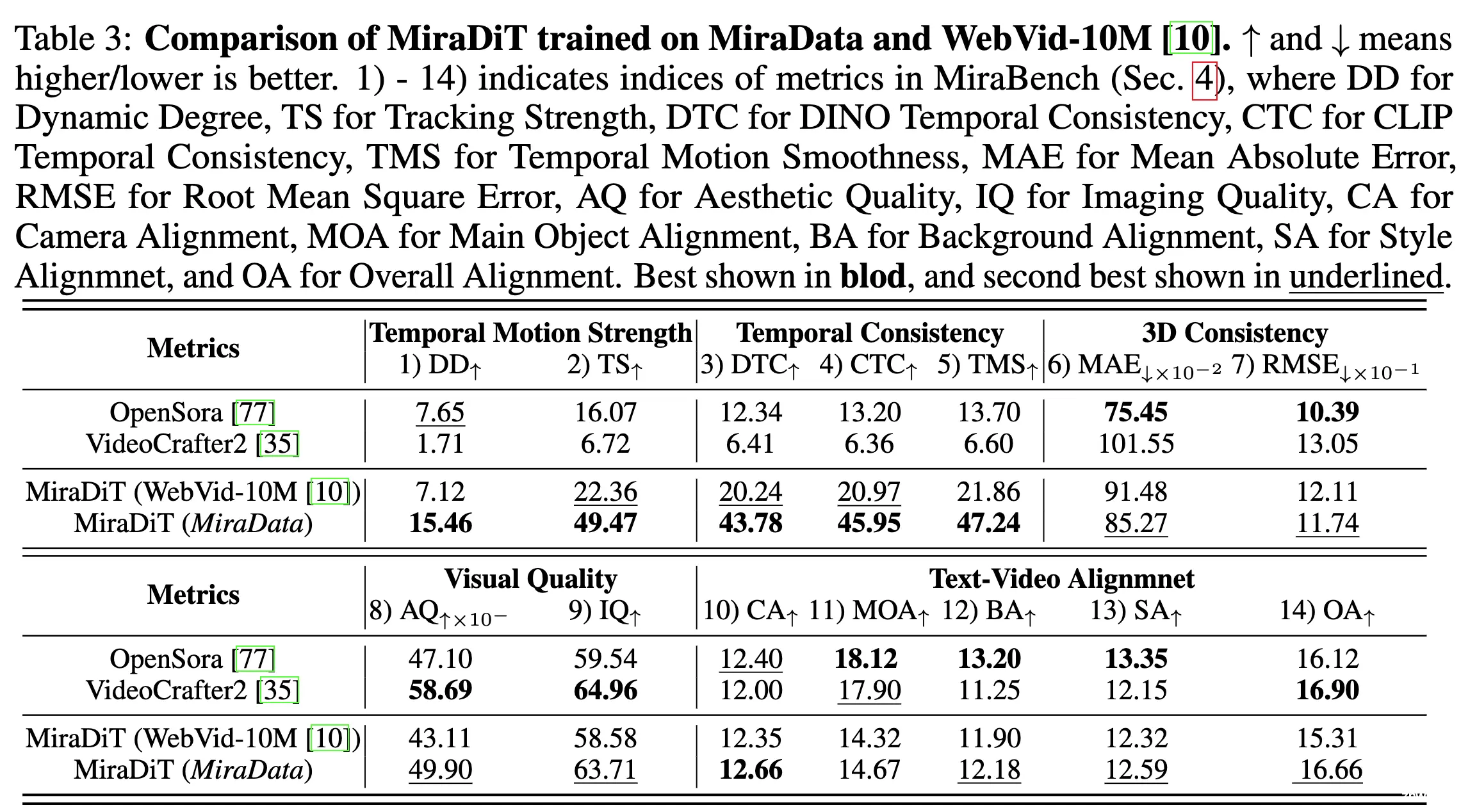
在 MiraData 上训练的模型精度比在 WebVid-10M 上训练的更好。
MiraData训练的模型在保持时间和3D一致性的同时,在运动强度方面显著提高此外,MiraData的高质量视频和密集、准确的提示语使训练模型在视觉质量和文本视频对齐方面表现更好与最先进的开源方法 OpenSora(基于DiT)和 VideoCrafter2(基于U-Net)进行了比较。我们的模型在运动强度和 3D 一致性方面显著优于以前的方法,同时在视觉质量和文本视频对齐方面取得了竞争性结果。
Thoughts
在视频生成数据方面来看是个挺完整的工作,不过数据量不是很大(1.6 万小时),重点是提升了数据质量,比较适合用于学术研究数据切分和拼接很合理,目前 scene boundry detect 模型的效果一般都比较差,很难选到一个能合理切分 shot 的阈值,采样本文的二阶段方案一定程度上能缓解这个问题
上一篇: 【论文笔记】Cross-Domain Few-Shot Object Detection via Enhanced Open-Set Object Detector
下一篇: 避雷!这7本计算机工程SCIE期刊被标记为“On Hold”状态!
本文标签
MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。