SAM 2:Segment Anything in Images and Videos 论文详解
小豆包的小朋友0217 2024-08-26 08:31:01 阅读 67
SAM 2:Segment Anything in Images and Videos
文章目录
SAM 2:Segment Anything in Images and Videos摘要1 Introduction具体分析
2 Related work具体分析:
3 任务:可提示的视觉分割4 模型具体分析具体分析
5 数据5.1 Data engine5.2 SA - V数据集
6 Zero-shot experiments6.1 Video tasks6.1.1 可提示的视频分割6.1.2半监督视频对象分割6.1.3公平性评价
6.2 图像任务
7. 与半监督法的比较8 数据和模型消融8.1 数据消融8.2 模型架构消融8.2.1 容量消融8.2.2 相对位置编码8.2.3 内存架构消融
9 结论AppendixA Pvs任务的细节B 局限性C SAM 2 细节C.1 架构C.2 训练C.2.1 预训练C.2.2 全训练
C.3 速度基准测试
D 数据详情D.1 SA-V 数据集详情D.2 Data engine detailsD.2.1 注释协议
E 详细介绍了零样本迁移实验E.1 零样本学习视频任务E.1.1 视频数据集详情E.1.2 交互线下和线上评价细节E.1.3 半监督VOS评估细节E.1.4 SAM XMem和SAM Cutie基线详细信息
E.2 DAVIS interactive benchmark
Code 解析总结
摘要
我们提出了分割任何事物模型2 ( SAM 2 ),一个用于解决图像和视频中快速视觉分割的基础模型。我们构建了一个数据引擎,通过用户交互来改进模型和数据,以收集到目前为止最大的视频分割数据集。我们的模型是一个简单的具有流式存储的Transformer结构,用于实时视频处理。在我们的数据上训练的SAM 2在广泛的任务中提供了强大的性能。在视频分割中,我们观察到较好的准确性,使用比以前方法更少的3倍的交互。在图像分割中,我们的模型比分割任何事物模型( Segment Anything Model,SAM )更精确,速度快6倍。我们相信,我们的数据、模型和见解将成为视频分割和相关感知任务的重要里程碑。我们正在发布我们模型的一个版本,数据集和一个交互式演示。
Demo:https://sam2.metademolab.com
Code:https://github.com/facebookresearch/segment-anything-2
Website:https://ai.meta.com/sam2
文章地址 https://arxiv.org/pdf/2408.00714
1 Introduction
Segment Anything ( SA )为影像(基里洛夫等, 2023)的快速分割引入了基础模型。然而,一幅图像只是现实世界的静态快照,其中的视觉片段可以表现出复杂的运动,并且随着多媒体内容的快速增长,现在有相当一部分是以时间维度记录的,特别是在视频数据中。在AR / VR、机器人、自动驾驶和视频编辑等领域的许多重要应用中,除了图像级分割外,还需要时间定位。一个通用的视觉分割系统应该同时适用于图像和视频。
视频中的分割旨在确定实体的时空范围,这提出了超越图像的独特挑战。由于运动、形变、遮挡、光照变化等因素的影响,实体在外观上会发生显著的变化。由于相机运动、模糊和较低的分辨率,视频往往比图像的质量低。此外,大量帧的高效处理是一个关键的挑战。虽然SA成功地解决了图像中的分割问题,但现有的视频分割模型和数据集不足以提供与"分割视频中的任何东西"相媲美的能力。
介绍了Segment Anything Model 2 ( SAM 2 ),一个用于视频和图像分割的统一模型(我们将图像看作单帧视频)。我们的工作包括任务、模型和数据集(见图1)。我们关注的是将图像分割推广到视频域的可提示视觉分割( Promptable Visual Segmentation,PVS )任务。该任务在视频的任一帧上作为输入点、框或掩码,定义一个感兴趣的片段,并对其进行时空掩码(即,一个"mask")的预测。一旦预测到一个掩码,就可以通过在额外的帧中提供提示来迭代地对其进行细化。
我们的模型( § 4 )在单幅图像和跨视频帧中生成感兴趣目标的分割掩膜。SAM 2具有存储关于对象和先前交互的信息的存储器,这使得它可以在整个视频中生成masklet预测,并且还可以根据先前观察到的帧中存储的对象的记忆上下文来有效地纠正这些预测。我们的流式架构是SAM在视频领域的自然推广,一次处理一个视频帧,配备了一个记忆注意模块来关注目标对象的先前记忆。当应用于图像时,内存是空的,模型表现出类似SAM的行为。
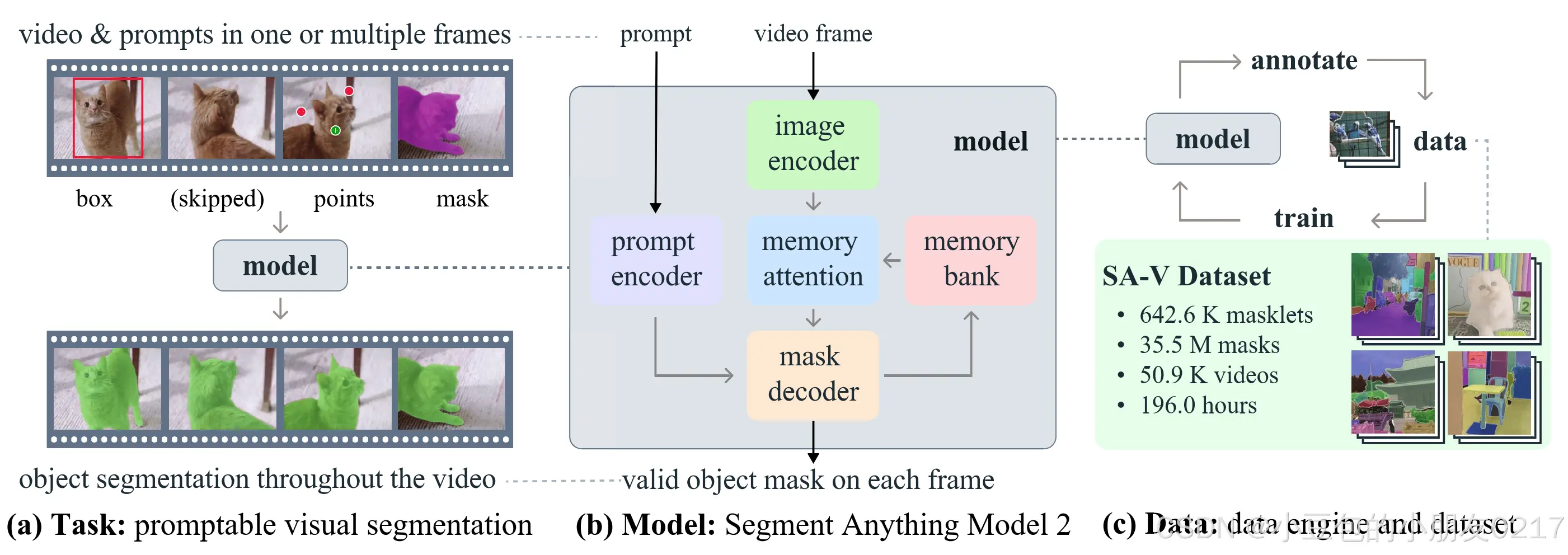
图1我们介绍了分割任何事物模型2 ( SAM 2 ),通过我们的基础模型( b ),在我们的数据引擎( c )收集的大规模SA - V数据集上训练,以解决快速的视觉分割任务( a )。SAM 2能够利用存储了先前提示和预测的流式内存,在一个或多个视频帧上通过提示(点击、方框或面具)交互式地分割区域。
我们使用一个数据引擎( § 5 )来生成训练数据,通过使用我们的模型在与注释器的循环中交互式地注释新的和有挑战性的数据。与大多数现有的视频分割数据集不同,我们的数据引擎并不局限于特定类别的对象,而是有针对性地提供训练数据,用于分割任何具有有效边界的对象,包括零件和子零件。与现有的模型辅助方法相比,我们的SAM 2在循环中的数据引擎在质量相当的情况下快8.4倍。我们的最终数据集Segment Anything Video ( SA-V ) ( § 5.2 )由35.5 M的掩码组成,覆盖了50.9 K的视频,比任何现有的视频分割数据集多53 ×个掩码。SA - V对小物体和在整个视频中被遮挡和再现的部分具有挑战性。我们的SA - V数据集在地理上是多样的,对SAM 2的公平性评价表明,基于感知性别的视频分割的性能差异最小,我们评估的三个感知年龄组之间的差异很小。
我们的实验( § 6 )表明,SAM 2提供了一个视频分割体验的阶跃变化。与以前的方法相比,SAM 2可以产生更好的分割精度,同时使用3倍的交互。此外,在多个评价指标下,SAM 2在已建立的视频对象分割基准中优于先前的工作,并且在图像分割基准上比SAM提供了更好的性能,同时速度提高了6倍。通过大量的零样本测试,包括17个视频分割和37个单幅图像分割,SAM 2被证明在各种视频和图像分布中是有效的。
我们在允许的开放许可证下发布了我们的工作,包括模型SAM 2 ( Apache 2.0 )的SA - V数据集( CC为4.0)a版本,以及https://sam2.metademolab.com.的交互式在线演示
具体分析
SAM2特性:
统一的分割能力:SAM 2 能够处理单幅图像以及跨视频帧的分割任务,生成感兴趣目标的分割掩膜。
内存机制:模型配备了一个内存机制,用于存储关于对象和先前交互的信息。这使得SAM 2 能够在整个视频中生成masklet预测,并根据先前观察到的帧中存储的对象记忆上下文来有效地纠正这些预测。
流式架构:SAM 2 的流式架构是SAM在视频领域的自然推广,它一次处理一个视频帧,并配备了一个记忆注意模块来关注目标对象的先前记忆。当应用于图像时,内存是空的,此时模型的行为类似于原始的SAM
输入阶段
视频与图像帧:流程从接收视频和图像帧开始,这些帧被明确标记为“video frame”(视频帧)、“box”(框)、“points”(点)和“mask”(掩码),表明它们将用于后续的分割任务。
模型架构
提示编码器(Prompt Encoder):该部分负责接收视频帧和图像帧,通过处理生成对应的提示表示,这些提示为后续的分割任务提供了关键信息。
记忆注意力机制(Memory Attention):利用提示编码器生成的提示,通过内存银行(Memory Bank)进行交互,生成富含上下文信息的特征表示。这一机制增强了模型对视频和图像内容的理解能力。
掩码解码器(Mask Decoder):接收记忆注意力机制输出的特征表示,进一步处理以生成每个像素的精确分割掩码。这是实现视频和图像分割任务的核心步骤。
任务描述
提示视觉分割(Promptable Visual Segmentation):该模型的核心任务是,在给定的视频和图像帧中,根据用户或系统的提示,生成每个像素的精确分割掩码。这种能力在视频编辑、自动驾驶、医学影像分析等领域具有广泛的应用前景。
2 Related work
图像分割。Segment Anything(基里洛夫et al , 2023)引入了一个可提示的图像分割任务,其目标是在给定输入提示的情况下输出一个有效的分割掩膜,例如一个边界框或一个指向感兴趣目标的点。在SA - 1B数据集上训练的SAM允许使用灵活提示的零样本分割,这使其能够被广泛的下游应用所采用。最近的工作通过提高SAM的质量扩展了SAM。例如,HQ - SAM( Ke et al . , 2024)通过引入一个高质量输出令牌并在细粒度掩码上训练模型来增强SAM。另一类工作关注于SAM的效率,以使其能够在现实世界和移动应用中更广泛地使用,例如EfficientSAM( Xiong et al , 2023),MobileSAM( Zhang et al , 2023a)和FastSAM( Zhao et al . , 2023)。SAM的成功使其在医学成像( Ma et al , 2024 ; Deng et al , 2023 ;马祖罗夫斯基et al , 2023 ; Wu et al , 2023a)、遥感( Chen et al , 2024 ; Ren et al , 2024)、运动分割( Xie et al , 2024)、伪装目标检测( Tang et al , 2023)等领域得到了广泛的应用。
交互式视频对象分割( Ivos )。交互式视频对象分割已经成为一项至关重要的任务,它可以在用户指导下高效地获得视频(掩码)中的对象分割,通常以涂鸦、点击或边界框的形式出现。早期的一些方法( Wang et al,2005 );部署基于图的优化来指导分割标注过程。最近的方法( Heo et al . , 2020 ; Cheng et al . , 2021b ; Delatolas et al , 2024)通常采用模块化设计,将用户输入转换为单帧上的掩码表示,然后将其传播到其他帧。我们的工作与这些工作有着相似的目标,即以良好的交互体验来分割视频中的对象,并且为了追求这一目标,我们建立了一个强大的模型以及一个庞大而多样化的数据集。
特别地,DAVIS交互基准( Caelles et al , 2018)允许在多个帧上通过涂抹输入交互式地分割对象。受DAVIS交互式基准的启发,我们在§ 6.1中对可提示的视频分割任务也采用了交互式评估设置。
基于点击的输入更容易收集到( Homayounfar et al , 2021),用于交互式视频分割。最近的工作已经将SAM与基于masks( Cheng et al . , 2023b ; Yang et al , 2023 ; Cheng et al , 2023c)或point(拉吉切等, 2023)的视频跟踪器结合使用。然而,这些方法存在局限性:跟踪器可能无法适用于所有对象,对于视频中的图像帧,SAM可能无法很好地执行,并且没有任何机制可以交互地细化模型的错误,除了在错误帧上从头重新注释使用SAM并从那里重新启动跟踪。
半监督视频对象分割( vos )。半监督VOS通常从第一帧输入的目标掩码开始,必须在整个视频( Pont-Tutset et al , 2017)中准确跟踪。它被称为"半监督",因为输入掩码可以被看作是物体外观的监督信号,只对第一帧可用。这项任务由于其在各种应用中的相关性而引起了极大的关注,包括视频编辑,机器人技术和自动背景去除。
早期的基于神经网络的方法通常在第一个视频帧( Caelleset al , 2016 ;佩拉齐et al , 2016 ; Yoon et al , 2017 ; Maninis et al , 2017 ; Hu et al , 2018a ; Bhat et al , 2020 ; Robinson et al , 2020)或所有视频帧(福伦达)上使用在线微调。通过离线训练的模型实现了更快速的推理,仅在第一帧上进行条件限制或者也整合了之前的框架。这种多条件已经扩展到所有具有RNN的帧和交叉注意力。最近的方法(张杰等, 2023b ; Wu et al . , 2023b)扩展了一个单一的视觉转换器来联合处理当前帧以及所有以前的帧和相关的预测,从而产生一个简单的架构,但以令人望而却步的推理代价。半监督VOS可以看作是我们的可提示视觉分割( Promptable Visual Segmentation,PVS )任务的一个特例,因为它相当于在第一个视频帧中只提供一个掩码提示。然而,在第一帧中标注所需的高质量目标掩码实际上是具有挑战性且耗时的。
扩展单个视觉转换器来联合处理当前帧和所有先前帧以及相关的预测,从而产生一个简单的架构,但以令人望而却步的推理代价。半监督VOS可以看作是我们的可提示视觉分割( Promptable Visual Segmentation,PVS )任务的一个特例,因为它相当于在第一个视频帧中只提供一个掩码提示。然而,在第一帧中标注所需的高质量目标掩码实际上是具有挑战性且耗时的。
视频分割数据集。许多数据集已经被提出来支持VOS任务。早期的VOS数据集( Prest et al . , 2012 ; Li et al . , 2013 ; Ochs et al . , 2014 ;樊纲等, 2015),如DAVIS( Pont-Tutset et al , 2017 ; Caelles et al , 2019),包含高质量的注释,但其有限的规模不允许训练基于深度学习的方法。YouTube - VOS(雪等, 2018b)涵盖了超过4 000个视频的94个对象类别,是第一个用于VOS任务的大规模数据集。随着算法的改进和基准性能的饱和,研究人员已经开始着眼于增加VOS任务的难度,特别关注遮挡(齐志刚等, 2022 ;丁一汇等, 2023)、长视频( Hong et al , 2023 , 2024)、极端变换(托克马科夫等, 2022)、对象多样性( Wang et al , 2021b , 2023)或场景多样性( Athar et al , 2022)。
我们发现,目前的视频分割数据集缺乏足够的覆盖率来实现"视频中的任何事物分割"的能力。它们的注释通常覆盖整个对象(而不是部分),数据集往往围绕特定的对象类,如人、车辆和动物。与这些数据集相比,我们发布的SA - V数据集不仅关注整个物体,而且广泛地覆盖了物体的各个部分,并且包含了一个数量级以上的掩码。
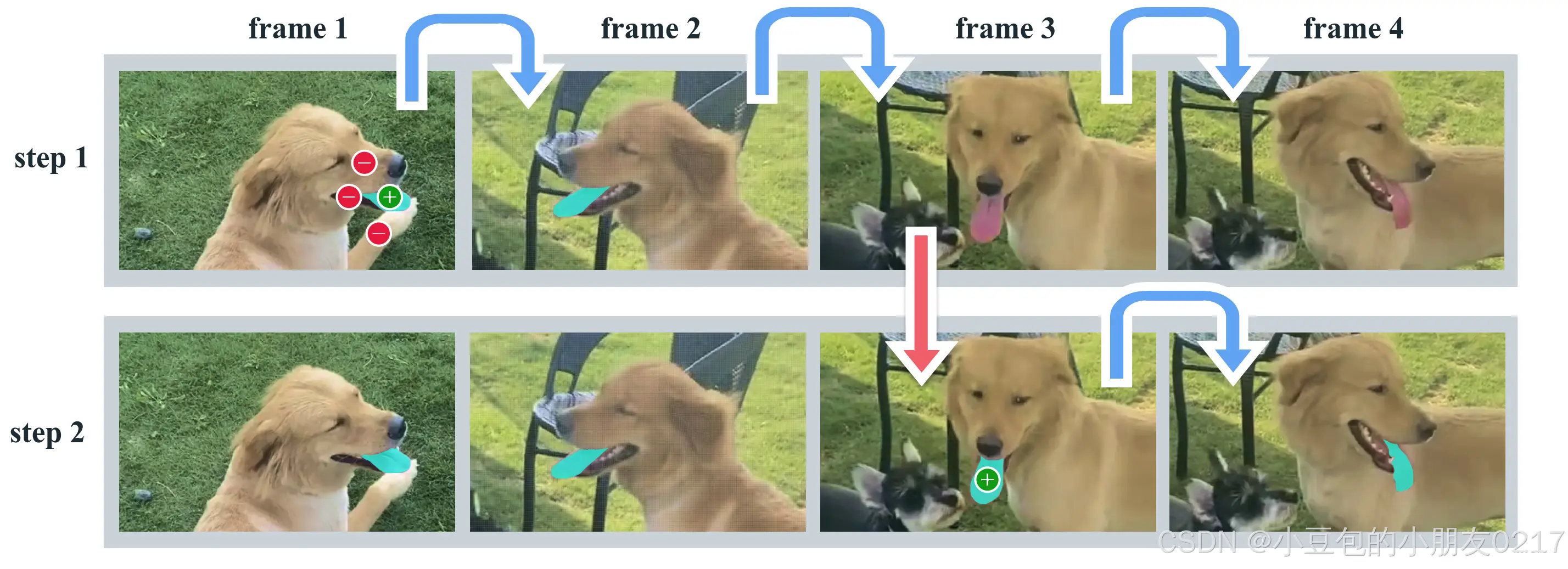
图2与SAM的交互分割2 .步骤1 (选择):在帧1中提示SAM 2,得到目标物体(舌头)的片段。绿色/红色圆点分别表示正负脉冲充电提示。SAM 2自动将片段传播到下面的帧(蓝色箭头),形成一个掩码。如果SAM 2丢失了对象(在第2帧之后),我们可以通过在新的一帧中提供一个额外的提示(红色箭头)来纠正掩码。步骤2 (精化):在第3帧中单击一下就足以恢复物体并传播,得到正确的掩码。一个解耦的SAM视频跟踪器方法需要在3(如框架1所示)帧中的几个点击来正确地重新注释对象,因为分割从零开始重新启动。在SAM 2的记忆下,一次点击就可以恢复出舌头。
具体分析:
图2展示了与Segment Anything Model 2(SAM 2)的高效交互分割过程,特别针对视频中的舌头进行精确分割。在步骤1中,通过在帧1中提供绿色和红色圆点作为正负脉冲充电提示,SAM 2能够迅速识别出目标物体(舌头)的片段,并自动将这些片段传播到后续帧中,形成一个初始的掩码。这种自动化的传播机制显著提高了分割效率。
若SAM 2在后续帧中丢失了目标对象(如第2帧后),用户只需在新的一帧中提供一个额外的提示,即可快速纠正掩码,确保分割的连续性。在步骤2的精化阶段,即便在对象暂时丢失的情况下,用户也仅需在第3帧中简单点击,SAM 2便能凭借其记忆能力恢复出舌头,并继续传播正确的掩码。
这一解耦的SAM视频跟踪器方法展现了其卓越的性能,能够在极少的点击次数内**(如3帧内的几个点击)重新注释对象**,无需从零开始分割。SAM 2的记忆功能使得一次点击即可恢复并跟踪目标物体,极大地提升了视频分割的准确性和效率。
3 任务:可提示的视觉分割
PVS任务允许在视频的任何一帧上向模型提供提示。提示可以是正/负点击、边界框或掩码,既可以定义要分割的对象,也可以细化预测的模型。为了提供交互体验,当接收到特定帧上的提示时,模型应该立即响应该帧上对象的有效分割掩码**。在接收到初始(一个或多个)提示(无论是同一帧还是不同帧)后,模型需要在整个视频中传播这些提示**,以获得目标对象的掩码,其中包含目标对象在每个视频帧上的分割掩码。在视频(如图2)的任何一帧上都可以向模型提供额外的提示,以细化整个视频(如图2)的片段。关于任务的细节,见§ A.
在接下来的章节( § 4 )中,SAM 2被用作数据收集工具,用于构建我们的SA - V数据集( § 5 )的PVS任务。通过模拟涉及跨多帧注释的交互式视频分割场景,在传统的半监督VOS设置(注释仅限于第一帧)和SA基准上的图像分割,在在线和离线环境下对模型进行评估( § 6 )。
4 模型
我们的模型可以看作是SAM在视频(和图像)领域的推广。SAM 2 (图3 )支持对单个帧进行点、框和掩码提示,以定义视频中待分割对象的空间范围。对于图像输入,模型表现出与SAM类似的行为。一个可提示的轻量级掩码解码器接受一个帧嵌入,并在当前帧上提示(如果有的话),并为该帧输出一个分割掩码。提示可以在一帧上迭代地添加,以细化掩模。
与SAM不同,SAM 2解码器使用的帧嵌入不是直接来自图像编码器,而是基于对过去预测和提示帧的记忆。相对于当前框架,提示框架也有可能"来自未来"。**帧的记忆是由基于当前预测的记忆编码器创建的,并放置在内存库中供后续帧使用。**记忆注意操作从图像编码器中获取每帧嵌入,并将其条件化到记忆库中,产生一个嵌入,然后传递给掩码解码器。
具体分析
SAM 2的核心是一个可提示的轻量级掩码解码器,它接收一个帧嵌入和当前帧上的提示(如果有的话),并为该帧输出一个分割掩码。用户可以在一帧上迭代地添加提示,以细化掩模,从而获得更精确的分割结果。
与SAM不同的是,SAM 2解码器使用的帧嵌入不是直接来自图像编码器,而是基于对过去预测和提示帧的记忆。这意味着SAM 2能够利用之前的帧和提示信息来改进当前帧的分割。此外,提示框架也有可能“来自未来”,即利用后续帧的信息来进一步优化当前帧的分割结果。
帧的记忆是由一个基于当前预测的记忆编码器创建的,并被放置在内存库中供后续帧使用。记忆注意操作从图像编码器中获取每帧嵌入,并将其与记忆库中的信息相结合,产生一个条件化的嵌入,然后传递给掩码解码器以生成分割掩码。这种机制使得SAM 2能够在视频帧之间传递和利用信息,从而实现更准确的视频分割
我们在下面描述了单个组件和训练,并在附录C中提供了更多的细节。
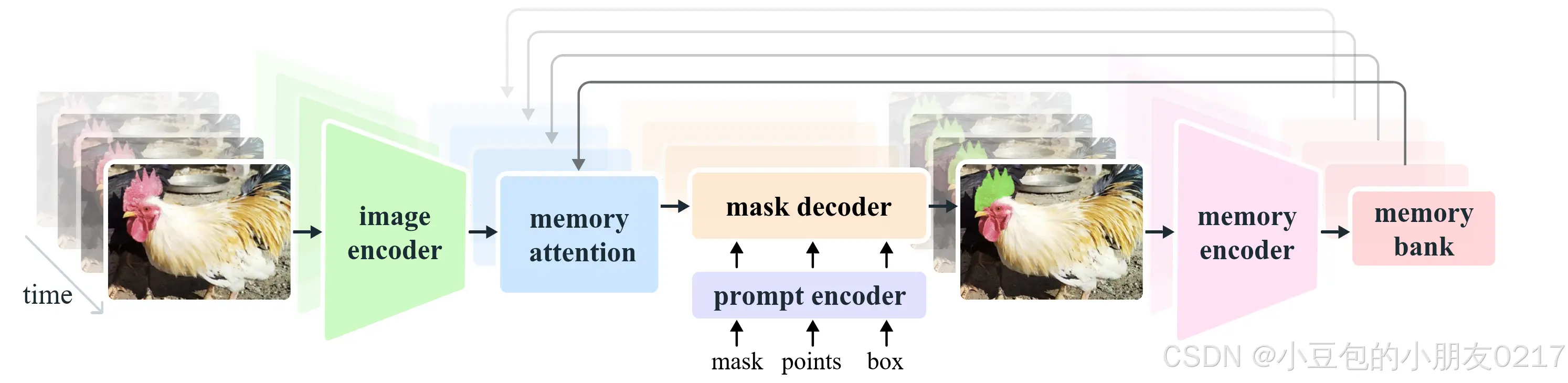
图3 SAM2架构。对于给定的帧,分割预测是以当前的提示和/或先前观察到的记忆为条件的。对视频进行流式处理,由图像编码器一次性消耗一帧图像,并从前一帧图像中交叉注意对目标物体的记忆。掩码解码器( maskdecoder )也可选择性地接收输入提示,预测该帧的分割掩码。最后,一个记忆编码器将预测和图像编码器嵌入转换为(未在图中显示),以便在未来帧中使用。
图像编码器。对于任意长视频的实时处理,我们采取流式处理的方法,在视频帧可用时消耗视频帧。图像编码器在整个交互过程中只运行一次,其作用是提供代表每一帧的无条件令牌(特征嵌入)。我们使用了一个MAE( Heet al , 2022)预训练的Hiera( Ryali et al . , 2023 ; Bolya et al , 2023)图像编码器,它是分层的,允许我们在解码过程中使用多尺度特征。
记忆注意。记忆注意的作用是将当前的框架特征条件化在过去的框架特征和预测以及任何新的提示上。我们堆叠L个变换块,第一个变换块以当前帧的图像编码作为输入。每个块执行自注意力,然后对(提示/未提示)帧和对象指针的记忆进行交叉注意力(见下文),存储在记忆库中(见下文),随后执行MLP。我们使用vanilla注意力操作进行自注意力和交叉注意力,使我们能够从最近开发的高效注意力核(道, 2023)中受益。
提示编码器和掩码解码器。我们的提示编码器与SAM完全相同,可以通过单击(积极的或消极的)、边界框或掩码来提示,以定义给定帧中对象的范围。稀疏提示由位置编码表示,并与每个提示类型的学习嵌入相加,而掩码使用卷积嵌入,并与帧嵌入相加。
我们的解码器设计在很大程度上遵循SAM。我们堆叠"双向" Transformer块,更新提示和帧嵌入。正如在SAM中,对于歧义提示(即,单次点击),其中可能存在多个兼容的目标掩码,我们预测多个掩码。这种设计对于保证模型输出有效的掩模具有重要意义。在视频中,模糊度可以跨视频帧扩展,模型在每一帧上预测多个掩码。如果没有后续提示来解决歧义,模型只传播当前帧具有最高预测IoU的掩码。
与SAM在正提示条件下总有一个有效对象进行分割不同,在PVS任务中,在某些帧(例如,由于遮挡造成的)上不可能存在有效对象。为了解释这种新的输出模式,我们添加了一个额外的头部,用于预测当前帧上是否存在感兴趣的对象。与SAM的另一个不同之处是,我们使用了来自分层图像编码器(绕过记忆注意)的跳跃连接,以将高分辨率信息用于掩码解码(见§ C )。
记忆编码器。记忆编码器通过使用卷积模块对输出掩码进行下采样,并将其与来自图像编码器(如图3所示)的无条件帧嵌入进行逐元素求和来生成记忆,随后使用轻量级卷积层来融合信息。
Memory bank.。存储体通过维护多达N个最近帧的存储器FIFO队列来保留视频中目标对象过去预测的信息,并将提示信息存储在多达M个提示信息帧的FIFO队列中。例如,在以初始掩蔽为唯一提示的VOS任务中,记忆库始终如一地保留第1帧的记忆以及最多N个最近(未提示)帧的记忆。两组记忆都存储为空间特征图。
除了空间内存之外,我们还根据每帧(美因哈特, 2022)的掩码解码器输出令牌,存储一个对象指针列表作为待分割对象高层语义信息的轻量级向量。我们的记忆注意交叉地注意到空间记忆特征和这些对象指针。
我们将时间位置信息嵌入到N个最近帧的记忆中,使模型能够表示短期的物体运动,而不是在提示帧的记忆中,因为提示帧的训练信号更稀疏,更难以推广到推理场景中,因为提示帧可能来自与训练过程中看到的非常不同的时间范围。
训练。模型在图像和视频数据上进行联合训练。与先前的工作(基里洛夫et al , 2023 ; Sofiiuk et al , 2022)类似,我们模拟了模型的交互提示。我们对8帧序列进行采样,并随机选择最多2帧来提示和概率性地接收纠正点击,在训练过程中使用真实掩码和模型预测进行采样。训练任务是依次进行(和"互动")预测地面真值掩码。模型的初始提示可以是概率为0.5的地面实况掩码,概率为0.25的从地面实况掩码中采样的正点击,或者概率为0.25的丰富框输入。更详细的内容见§ C。
具体分析
5 数据
为了开发对视频中的任何事物进行"分割"的能力,我们建立了一个数据引擎来收集大量的、多样的视频分割数据集。我们在与人类注释器的循环设置中采用了交互模型。与基里洛夫等人( 2023 )类似,我们不对标注的masklets施加语义约束,而是同时关注整体对象(例如,一个人)和部分对象(例如,一个人的帽子)。我们的数据引擎经历了3个阶段,每个阶段根据提供给标注者的模型辅助程度进行分类。接下来,我们描述了每个数据引擎阶段和我们的SA - V数据集。
5.1 Data engine
第一阶段:每帧SAM。初始阶段使用基于图像的交互式SAM(基里洛夫等, 2023)来辅助人工标注。注释器的任务是使用SAM和像素精确的手工编辑工具,如"画笔"和"橡皮擦",以每秒6帧( FPS )的速度在视频的每一帧中注释目标对象的面具。没有涉及跟踪模型来辅助掩码向其他帧的时间传播。由于这是一种每帧的方法,并且所有的帧都需要从头标注,因此过程缓慢,在我们的实验中平均每帧的标注时间为37.8秒。然而,这会产生每帧高质量的空间标注。在这一阶段,我们在1.4 K的视频中收集了16K个掩码。我们进一步使用这种方法来注释我们的SA - V val和测试集,以减轻SAM 2在评估过程中的潜在偏差。
第二阶段:Sam+Sam 2掩模。第二阶段在循环中加入SAM 2,SAM 2只接受掩码作为提示。我们将该版本称为SAM 2 Mask。注释者使用SAM和第一阶段中的其他工具在第一帧中生成空间掩码,然后使用SAM 2 Mask将注释后的掩码在时间上传播到其他帧,以获得完整的时空掩码。在随后的任何视频帧中,注释器通过从头注释一个掩码,用SAM、"画笔"和/或"橡皮擦"对SAM 2 Mask的预测进行空间修改,并与SAM 2 Mask重新传播,重复此过程,直到掩码正确。SAM 2 Mask最初在Phase 1数据和公开数据集上进行训练。在阶段2中,我们利用收集到的数据对注释循环中的SAM 2 Mask进行了两次重新训练和更新。在第二阶段,我们收集了63.5 K的掩模。注释时间降至7.4 s /帧,比第一阶段提高了5.1倍。尽管在注释时间上有所改进,但这种解耦的方法需要从头注释中间帧中的掩码,而不需要先前的内存。然后,我们进一步开发了全功能的SAM 2,能够在a中同时执行交互式图像分割和掩模传播
第三阶段:SAM2。在最后一个阶段,我们使用全功能的SAM 2,它接受各种类型的提示,包括点和面具。SAM 2从跨时间维度的对象记忆中获益,以产生掩蔽预测。这意味着注释者只需要向SAM 2提供偶尔的精化点击来编辑中间帧中的预测掩码,而不是使用没有这种记忆上下文的空间SAM从头注释。在第三阶段,我们使用收集到的注释重新训练和更新SAM 2,共五次。在SAM 2的循环中,每帧标注时间下降到4.5秒,比第一阶段提高了8.4倍。在第三阶段,我们收集了197.0 K的掩模
质量验证。为了维护一个高标准的注释,我们引入了一个验证步骤。一组独立的注释器的任务是验证每个注释面具的质量为"令人满意的" (在所有帧中正确和一致地跟踪目标对象)或"不令人满意的" (目标对象被很好地定义,具有清晰的边界,但掩码是不正确或不一致的)。不满意的模板送回注释管道进行精修。任何跟踪没有很好定义的对象的masklets都被完全拒绝。
自动生成掩码。确保注释的多样性对于使我们的模型具有任何能力都很重要。由于人类注释者通常更关注显著性对象,因此我们使用自动生成的掩码(简称’ Auto ')对注释进行增强。这起到了增加注释覆盖率和帮助识别模型失效案例的双重目的。为了生成自动掩码,我们在第一帧中用规则的网格点提示SAM 2,并生成候选掩码。然后将这些送入到掩码验证步骤进行过滤。在SA - V数据集中添加标记为"满意"的自动掩码。将识别为"不满意" (即,模型失效案例)的面具取样并呈现给注释器,使用(数据引擎的第三阶段)循环中的SAM 2进行细化。这些自动掩模不仅覆盖了较大的显著中心物体,还覆盖了背景中不同大小和位置的物体。
分析。表1通过一个对照实验展示了标注协议在每个数据引擎阶段的比较(详见§ D.2 . 2 )。我们比较了每一帧的平均标注时间、每一个掩码的平均人工编辑帧数百分比和每一个被点击的帧的平均点击次数。对于质量评价,我们将第一阶段掩膜对齐分数定义为第一阶段Io U与对应掩膜相比超过0.75的掩膜所占的百分比。选择第一阶段数据作为参考,因为它具有每帧高质量的人工标注。第三阶段在循环中使用SAM 2可以提高效率和质量:它比第一阶段快8.4倍,具有最低的编辑帧率和每帧点击率,并产生更好的对齐效果。
5.2 SA - V数据集
我们的数据引擎收集的SA - V数据集包含50.9 K个视频和642.6 K个掩码。在表3中,我们将SA - V组合与常见的VOS数据集在视频、掩码和掩码数量上进行了比较。值得注意的是,有注释的掩码数量比任何现有的VOS数据集都大53 × ( 15 ×无自动),为未来的工作提供了大量的资源。我们正在许可的情况下发布SA - V。
视频。我们收集了一组新的50.9 K由人群工作者拍摄的视频。视频包含了54 %的室内场景和46 %的室外场景,平均时长为14秒。视频具有"在野外"的多样化环境,覆盖了各种日常场景。我们的数据集比现有的VOS数据集拥有更多的视频,如图5所示,视频横跨47个国家,并被不同的参与者(自我报告的人口统计)捕获。
掩码。注释包括使用我们的数据引擎收集的190.9 K手动掩码注释和451.7 K自动掩码。掩模叠加(手动和自动)的示例视频如图4所示。SA - V比最大的VOS数据集多了53 × ( 15 ×无自动标注)个掩码。SA-V Manual (至少在一帧中消失,然后重新出现的带注释的掩膜所占的百分比)中(丁一汇等, 2023)的消失率为42.5 %,在现有数据集中具有竞争力。图5a显示了掩模尺寸分布(通过视频分辨率进行归一化)与DAVIS,MOSE和YouTubeVOS的比较。超过88 %的SA - V掩模的归一化掩模面积小于0.1。
SA - V训练、验证和测试分割。我们基于视频作者(及其地理位置)对SA - V进行拆分,以保证相似对象的最小重叠。为了创建SA - Vval和SA - V测试集,我们在选择视频时关注具有挑战性的场景,并要求注释人员识别具有挑战性的目标,这些目标是快速移动的,具有复杂的被其他物体遮挡的情况以及消失/重现模式。这些靶点在§ 5.1中使用数据引擎Phase 1设置以6FPS进行注释。SA - V val拆分有293个掩码和155个视频,SA - V test拆分有278个掩码和150个视频。
内部数据集。我们还使用了内部可用的授权视频数据来进一步增加我们的训练集。我们的内部数据集包括62.9 K个视频和69.6 K个在阶段2和阶段3 (见§ 5.1 )标注的掩码用于训练,96个视频和189个使用阶段1标注的掩码用于测试( Internal-test )。关于数据引擎和SA - V数据集的更多细节见附录D。

图4 SA - V数据集的示例视频,masklets覆盖(手动和自动)。每个掩码都有唯一的颜色,每一行代表一个视频的帧,帧与帧之间间隔1秒。
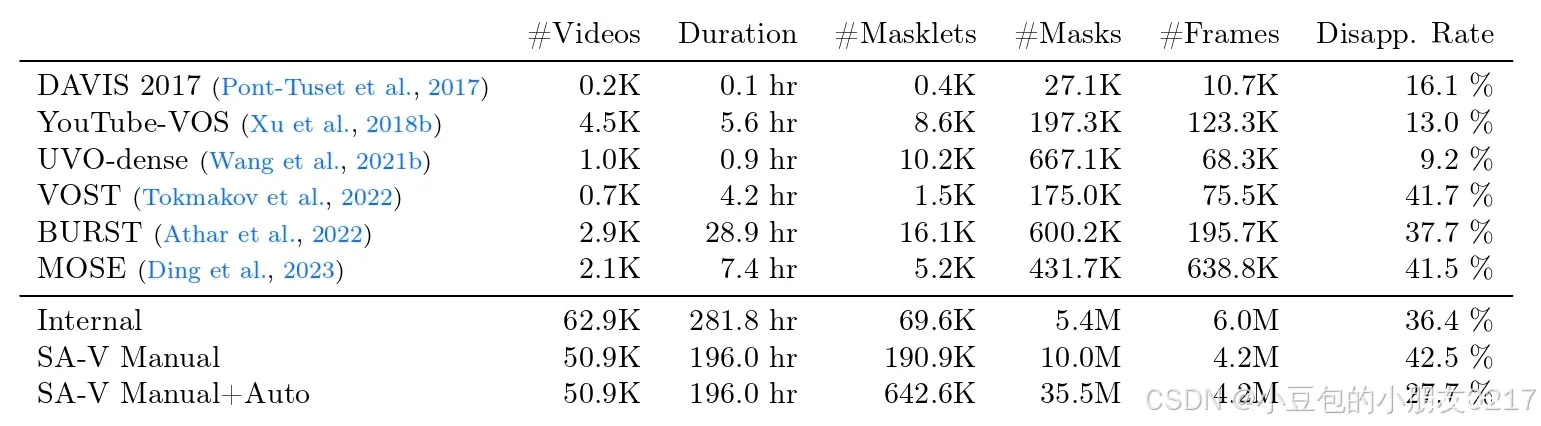
表3 我们的数据集与开源VOS数据集在视频数量、时长、掩码数、掩码数、帧数、消失率等方面的比较。《SA - V手册》只包含人工标注的标签。SA-VManual Auto将人工标注的标签与自动生成的掩码相结合。

图5数据集分布:( a )口罩尺寸分布(通过视频分辨率进行归一化),( b )视频的地理多样性,( c )录制视频的人群工作者的自我报告的人口统计学。
Masklets。注释包括使用我们的数据引擎收集的190.9 K手动掩码注释和451.7 K自动掩码。掩模叠加(手动和自动)的示例视频如图4所示。SA - V比最大的VOS数据集多了53 × ( 15 ×无自动标注)个掩码。SA-V Manual (至少在一帧中消失,然后重新出现的带注释的掩膜所占的百分比)中(丁一汇等, 2023)的消失率为42.5 %,在现有数据集中具有竞争力。图5a显示了掩模尺寸分布(通过视频分辨率进行归一化)与DAVIS,MOSE和YouTubeVOS的比较。超过88 %的SA - V掩模的归一化掩模面积小于0.1。
SA - V训练、验证和测试分割。我们基于视频作者(及其地理位置)对SA - V进行拆分,以保证相似对象的最小重叠。为了创建SA - Vval和SA - V测试集,我们在选择视频时关注具有挑战性的场景,并要求注释人员识别具有挑战性的目标,这些目标是快速移动的,具有复杂的被其他物体遮挡的情况以及消失/重现模式。这些靶点在§ 5.1中使用数据引擎Phase 1设置以6FPS进行注释。SA - V val拆分有293个掩码和155个视频,SA - V test拆分有278个掩码和150个视频。
内部数据集。我们还使用了内部可用的授权视频数据来进一步增加我们的训练集。我们的内部数据集包括62.9 K个视频和69.6 K个在阶段2和阶段3 (见§ 5.1 )标注的掩码用于训练,96个视频和189个使用阶段1标注的掩码用于测试( Internal-test )。关于数据引擎和SA - V数据集的更多细节见附录D
6 Zero-shot experiments
在这里,我们将SAM 2与之前在零样本视频任务( § 6.1 )和图像任务( § 6.2 )上的工作进行了比较。我们报告了标准J
6.1 Video tasks
6.1.1 可提示的视频分割
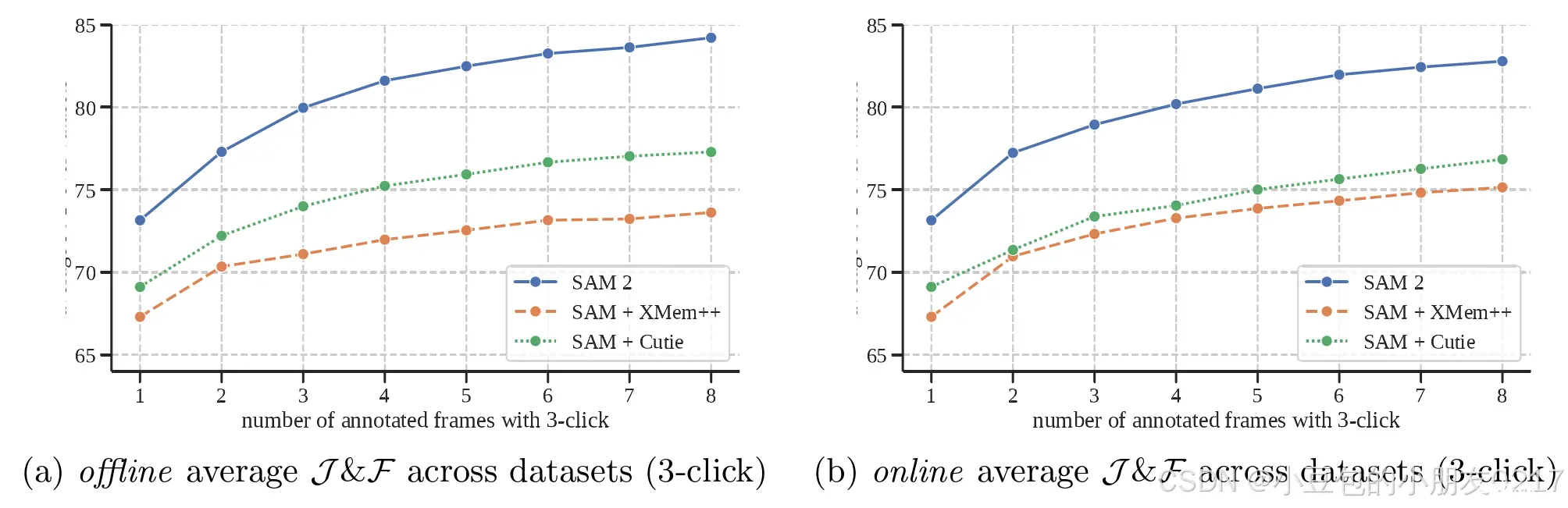
图6在交互式离线和在线评估设置中,在9个数据集上的零样本精度。
我们首先评估可提示的视频分割,这涉及模拟类似于用户体验的交互式设置。我们有两种设置:离线评估和在线评估,离线评估时,在视频中进行多次遍历,以根据最大模型误差选择要与之交互的帧;在线评估时,在视频中进行单次正向遍历,对帧进行注释。使用Nclick =每帧3次点击,在9个密集注释的零镜头视频数据集上进行这些评价(详情见§E.1)。
我们基于用于视频对象分割的两个最新模型XMem ++(Bekuzarov等人,2023)和Cutie(Cheng等人,第2023条a款)。我们使用XMem++基于一个或多个帧上的掩模输入来生成视频分割。SAM用于提供初始掩码或细化输出(通过将当前分段作为掩码提示馈送给SAM)。对于SAM+Cutie基线,我们修改了Cutie以允许在多个帧上进行遮罩输入。
在图6中,我们报告了在Nframe = 1,…,8个交互帧。在脱机和联机评估设置方面,SAM 2的性能都优于SAM+XMem++和SAM+Cutie。在所有9个数据集(参见§E.1中的每个数据集结果)中,SAM 2在两种方法中均占主导地位,证实SAM 2能够通过几次点击生成高质量的视频分割,同时还允许通过进一步提示继续优化结果。总体而言,SAM 2可以产生更好的分割准确度,交互次数减少>3倍。
6.1.2半监督视频对象分割

表4在使用不同提示的半监督VOS评估下,17个视频数据集的零拍摄准确度。该表显示了第一个视频帧中每种类型的提示(1、3或5次点击,边界框或地面实况遮罩)的平均J&F(在这种情况下,我们直接使用遮罩作为XMem++或Cutie的输入,而不使用SAM)。
接下来,我们评估半监督视频对象分割(VOS)设置(Pont-Tuset等人,2017),仅在视频的第一帧上显示单击、框或遮罩提示。当使用点击提示时,我们在第一个视频帧上交互式地采样1、3或5次点击,然后基于这些点击来跟踪对象。
与第6.1.1节中的交互式设置类似,我们将其与XMem++和Cutie进行比较,使用SAM进行单击和框提示,并在使用掩码提示时使用其默认设置。我们报告了标准J&F准确度(Pont-Tuset等人,2017),除了VOST(Tokmakov等人,2022),其中我们按照其协议报告J度量。结果见表4。SAM 2在17个数据集上的表现优于两个基线,使用各种输入提示。结果强调,SAM 2也擅长于传统的,非交互式的VOS任务与掩模输入,这些其他作品是专门设计的。更多详情见§E.1.3。
6.1.3公平性评价
我们评估SAM 2在人口统计学群体中的公平性。我们在EgoExo 4D中收集人类别的注释(Grauman等人,2023)数据集,其包含由视频的主体提供的自我报告的人口统计信息。我们采用与SA-V瓦尔和测试集相同的注释设置,并将其应用于第三人称(exo)视频的20秒剪辑。我们在第一帧上使用1次、3次点击和地面实况掩码对这些数据进行SAM 2评估。

表5 SAM 2(根据J&F标准)对受保护人口群体的公平性评价
表5示出了SAM 2用于跨性别和年龄分割人的J&F准确性的比较。在3次点击和地面实况掩码提示下,存在最小的差异。我们手动检查单击预测,发现模型经常预测零件的遮罩,而不是人。当将比较限制为人物被正确分割的片段时,1次点击中的差距大幅缩小(J&F男性94.3,女性92.7),表明差异可以部分归因于提示中的模糊性。
在附录G中,我们提供了SA-V的模型、数据和注释卡。
6.2 图像任务
我们在Segment Anything任务上评估了SAM 2在37个零样本数据集上的表现,其中包括SAM之前用于评估的23个数据集,表6报告了1 - click和5 - click的mIoU,并在单个A100 GPU上以帧每秒( Frames Per Second,FPS )显示了按数据集域和模型速度的平均mIoU。
第一列( SA-23 All)表示在SAM的23个数据集上的准确率。SAM2获得了比SAM( 58.1 mIoU , 1点击)更高的准确率(点击1次, 58.9 mIoU),而不使用任何额外的数据,同时速度提高了6倍。这主要归因于SAM 2中更小但更有效的Hiera图像编码器。
最后一行展示了如何在我们的SA - 1B和视频数据混合上进行训练,可以进一步提高准确率,在23个数据集上平均达到61.4 %。在SA - 23(视频数据集评估为图像,与基里洛夫等人( 2023 )相同) )的视频基准上,以及我们添加的14个新的视频数据集上,我们也看到了异常的增益。

表6在37个数据集的Segment Anything ( SA )任务上的零样本准确率。该表按域(图像/视频)显示了SAM 2与SAM相比的平均1 -和5 -点击mIoU。我们报告了SAM ( SA-23 )使用的23个数据集的平均指标和14个额外的零样本视频数据集(详见§ E.3)的平均指标。
总的来说,研究结果强调了SAM 2在交互式视频和图像分割中的双重能力,强度来源于我们的不同训练数据,包括跨视觉域的视频和静态图像。更详细的结果包括按数据集细分的结果见§ E.3。
7. 与半监督法的比较
我们的主要关注点是通用的、交互式的PVS任务,但我们也解决了特定的半监督VOS设置(式中:提示符为第1帧的真值掩码),因为它是一个历史上常见的协议。我们在表7中给出了与现有最先进水平的比较,使用标准协议报告准确性。我们评估了两个版本的SAM 2,它们的图像编码器尺寸不同。( Hiera-B / - L)具有不同的速度和精度的折衷。SAM 2在准确性和推理速度上都比现有的最好方法(最后一列显示的FPS)有显著的提高。为了获得最佳的整体结果,我们观察到使用更大的图像编码器带来了显著的精度增益。
我们还评估了SA - V val和测试集的现有工作,这些测试集衡量了"任意"对象类的开放世界段的性能。在这个基准上进行比较时,我们看到之前的大多数方法都是在相同的精度附近达到峰值。在SA - V val和SA - V测试中,先前工作的最佳表现是显著低于显示"视频中的任何片段"能力的差距。最后,我们看到SAM 2在长期视频对象分割中也带来了显著的增益,正如在LVOS基准测试结果中观察到的那样。
8 数据和模型消融
本部分介绍了为SAM 2的设计决策提供信息的消融。我们在MOSE开发集( ’ MOSE dev ')上进行评估,其中包含200个MOSE训练中随机采样的视频,并从我们的消融、SA - V val和平均9个以上的零样本视频数据集中排除了训练数据。作为比较的指标,我们在第一帧上报告了3次点击输入下的J&F,作为1次点击制度和VOS风格掩码提示之间的平衡。此外,我们报告了SAM在图像SA任务中使用的23个数据集基准上的平均1 - click mIoU。除非另有规定,我们在512分辨率下运行,并使用SA - V手册和SA - 1B的10 %子集。其他细节见§ C.2 .
8.1 数据消融
数据混合消融。在表8中,我们比较了SAM 2在不同数据混合上训练时的准确性。我们在SA - 1B上进行预训练,然后为每个设置训练一个单独的模型。固定迭代次数( 200k )和批次大小( 128 ),只改变实验间的训练数据。我们报告了我们的SA - V val集、MOSE、9个零样本视频基准和SA - 23任务的准确率( § 6.2 )。第1行表明,单纯在VOS数据集( Davis、MOSE、YouTubeVOS)上训练的模型在域内MOSEdev上表现良好,但在包括9个零样本VOS数据集( 59.7 J )在内的所有其他数据集上表现不佳。
我们观察到将我们的数据引擎数据加入到训练组合中带来了巨大的好处,包括在9个零样本数据集(第11排vs 1)上的平均性能提高了12.1 %。这可以归因于VOS数据集的覆盖范围和规模有限。添加SA - 1B图像在不降低VOS能力的前提下,提高了图像分割任务(行3 vs 4、5 vs 6、9 vs 10、11 vs 12)的性能。仅在SA - V和SA - 1B (第4行)上训练就足以在除MOSE外的所有基准上获得强性能。总的来说,我们在混合所有数据集时获得了最好的结果:VOS,SA-1B,和我们的数据引擎数据(行12 )。
数据量消融。接下来,我们研究缩放训练数据的效果。SAM 2在不同大小的SA-V上训练之前在SA-1B上进行了预训练。我们报告了平均J&F分数(当在第一帧单击3次时),超过3个基准测试:SA-V瓦尔、zero-shot和MOSE dev。图7示出了在所有基准上训练数据的数量与视频分割准确度之间的一致幂律关系。
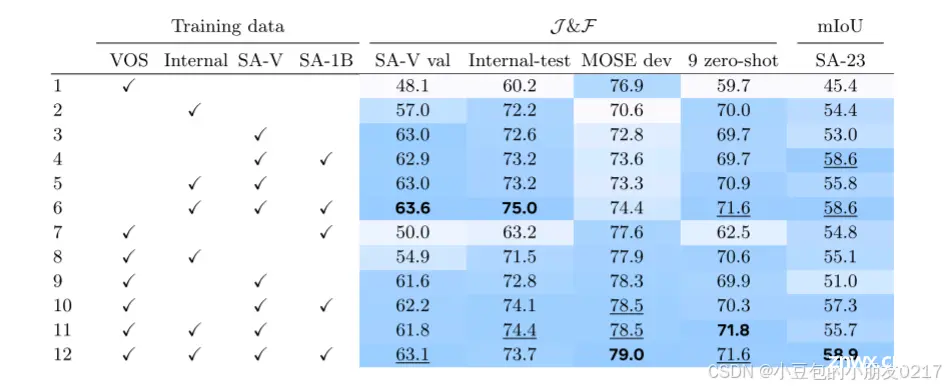
Table8 我们在不同的数据混合物上训练我们的模型,包括VOS(Davis,MOSE,YouTubeVOS),以及Internal-train,SA-V和SA-1B的子集。我们报告了在SA-V瓦尔和Internal-test、MOSE和9个零激发数据集的第一帧中点击3次提示时的J&F准确度,以及SA-23数据集的平均1次点击mIoU。
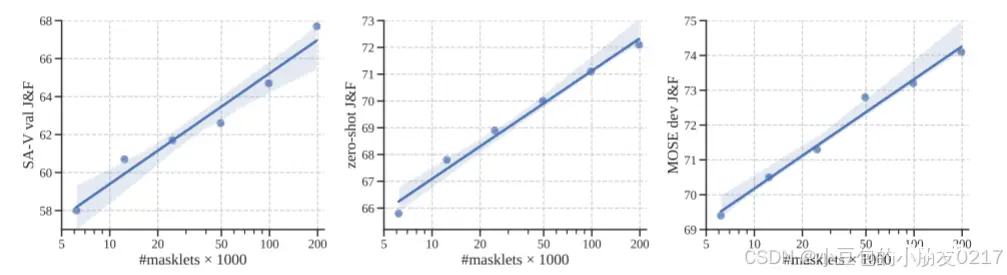
图7 SAM 2的性能与SA-V量的函数关系我们在SA-V瓦尔(左)、9个零炮数据集(中)和MOSE dev(右)的第一帧中报告了3次点击提示的J&F准确度。
数据质量消融。在表9中,我们对质量过滤策略进行了实验。我们从SA-V中抽取了50 k个masklet,或者是随机抽取,或者是抽取注释者编辑最多的masklet。基于编辑帧数量的过滤仅使用25%的数据就能实现强大的性能,并且优于随机采样。然而,这比使用所有190 k SA-V面罩更糟糕。

表9 我们在SA-V Manual数据的不同子集上训练我们的模型:50 k随机采样的masklet,50 k具有最多编辑帧的masklet,以及完整的SA-V数据集(190 k masklet)。
8.2 模型架构消融
在本节中,我们介绍了引导设计决策的模型消融,在默认输入分辨率为512的较小模型设置下进行。对于每种消融设置,我们报告了视频(J&F)和图像(mIoU)任务的分割准确性及其相对视频分割速度(相对于灰色消融默认设置的最大推理吞吐量)。我们发现图像和视频组件的设计选择在很大程度上是解耦的-这可以归因于我们的模块化设计和培训策略。
8.2.1 容量消融

表10 容量消融。我们消融建模能力沿着输入大小(分辨率,#帧),内存大小(#内存,内存通道暗淡)和模型大小(内存注意,图像编码器)。消融默认为灰色。
输入大小。在训练期间,我们采样固定分辨率和固定长度的帧序列(这里用#帧表示)。我们在表10a、10b中分析了它们的影响。更高的分辨率可显著改善图像和视频任务,我们在最终模型中使用了1024的输入分辨率。增加帧数会显著提高视频基准测试的性能,我们使用默认值8来平衡速度和准确性。
存储器大小。增加(最大)存储器数量N通常有助于提高性能,尽管可能会有一些差异,如表10c所示。我们使用6个过去帧的默认值来在时间上下文长度和计算成本之间取得平衡。如表10d所示,使用较少的存储器通道不会导致太多性能退化,同时使存储所需的存储器减少4倍。
模型尺寸。图像编码器或存储器注意(#self-/#cross-attention blocks)中的更大容量通常导致改进的结果,如表10 e、10 f中所示。缩放图像编码器带来了图像和视频指标的增益,而缩放内存注意力仅改善了视频指标。我们默认使用B+图像编码器,它在速度和精度之间提供了合理的平衡。
8.2.2 相对位置编码

表11相对位置编码。我们在内存注意中使用2d-RoPE,同时默认从图像编码器中删除RPB(灰色)。移除RPB还允许我们启用FlashAttention-2(Dao,2023),它在1024分辨率下提供了显着的速度提升。在1024的较高分辨率下,2d-RoPE(第1行)和无RoPE基线(第3行)之间的速度差距变得小得多。
默认情况下,我们总是在图像编码器和内存注意中使用绝对位置编码。在表11中,我们研究了相对位置编码设计选择。在此,我们还对LVOSv2进行评估(Hong等人,2024),在第一帧上点击3次,作为长期视频对象分割的基准。
虽然SAM(Kirillov等人,Bolya等人(2023)遵循Li等人(2022 b)将相对位置偏差(RPB)添加到所有图像编码器层,Bolya等人(2023)通过在除了全局注意力层之外的所有层中移除RPB同时采用带来大速度增益的“绝对获胜”位置编码来对此进行改进。我们通过从图像编码器中删除所有RPB来进一步改进这一点,在SA-23上没有性能回归,在视频基准测试中回归最小(见表11),同时在1024分辨率下显着提高速度。我们还发现使用2d-RoPE是有益的(Su等人,2021年; Heo等人,#20240;在记忆中。
8.2.3 内存架构消融
循环记忆。我们研究了在将存储器特征添加到存储器库之前将存储器特征馈送到GRU的有效性。与第8.2.2节类似,我们还对LVOSv2进行了评估,作为长期对象分割的附加基准。尽管现有技术通常采用GRU(Cho等人,2014)指出,作为一种将内存纳入跟踪过程的方法,我们在表12中的发现表明,这种方法没有提供改进(除了对LVOSv2略有改进)。相反,我们发现直接将存储器特征存储在存储器组中就足够了,这既简单又高效。
对象指针。我们消除了其他帧中来自掩码解码器输出的对象指针向量的交叉关注的影响(参见§4)。表12所示的结果表明,虽然交叉处理对象指针并不能提高9个零触发数据集的平均性能,但它可以显著提高SA-V瓦尔数据集以及具有挑战性的LVOSv 2基准测试(验证分割)的性能。因此,我们默认将对象指针与内存条交叉连接。

9 结论
我们提出了Segment Anything在视频领域的自然演化,基于三个关键方面:( i )将可提示的分割任务扩展到视频,( ii )在应用于视频时配备使用内存的SAM架构,以及( iii )用于训练和基准测试视频分割的多样化SA - V数据集。我们认为SAM 2标志着视觉感知的重大进步,将我们的贡献定位为里程碑,将推动该领域的进一步研究和应用。
Appendix
目录:·
§ A:任务详情·
§ B:局限性·
§ C:模型详情·
§ D:数据集详情·
§ E:零样本实验详情·
§ G:数据集、注释和模型卡片·
§ D.2 . 1:注释指南
A Pvs任务的细节
可提示视觉分割( Promptable Visual Segmentation,PVS )任务可以看作是分割任何事物( Segment Anything,SA )任务从静态图像到视频的扩展。在PVS设置中,给定一个输入视频,模型可以在视频中的任意一帧上与不同类型的输入(包括点击、方框或mask)进行交互提示,目标是在整个视频中分割(跟踪)一个有效的对象。当与视频交互时,该模型在被提示为(类似于SAM对图像的交互体验)的帧上提供了即时响应,同时也近乎实时地返回整个视频中对象的分割结果。与SAM类似,我们关注的是有明确边界的有效对象,而不考虑没有视觉边界的区域( ( e.g.Bekuzarov et al ( 2023 )) )。任务如图8所示。
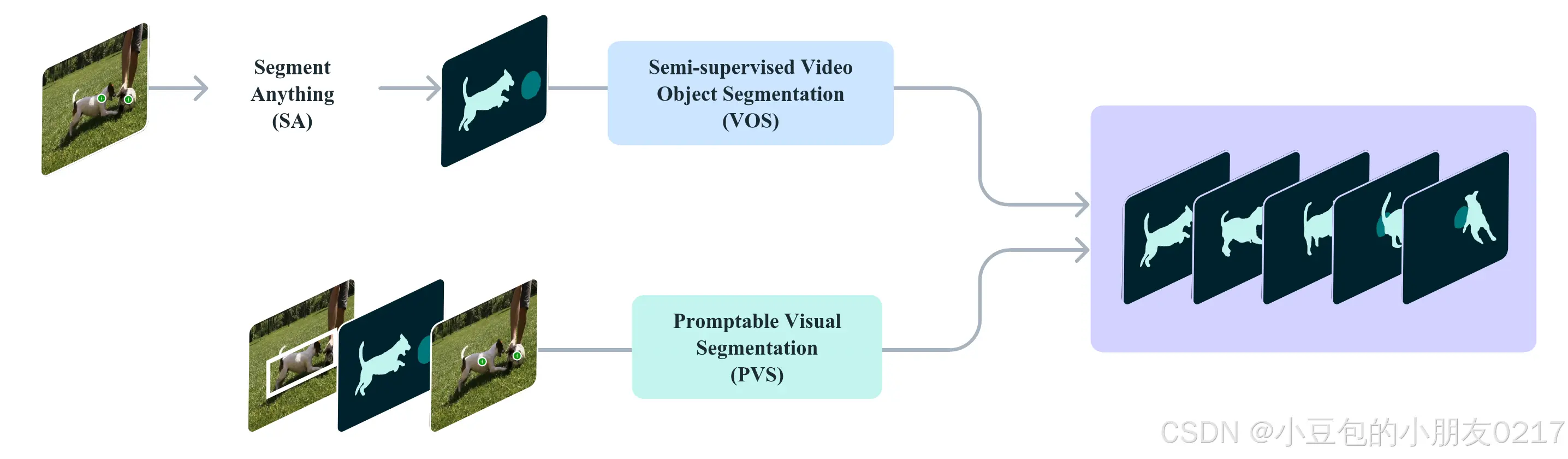
图8可提示的视觉分割任务( PVS )示意图。先前研究的任务如SegmentAnything ( SA )和半监督视频对象分割( VOS )可以看作是PVS任务的特例。
PVS涉及到静态图像和视频领域的多个任务。在图像上,SA任务可以看作是PVS的一个子集,将视频简化为单帧。类似地,传统的半监督和交互式VOS( Pont-Tutset et al , 2017)任务是PVS的特殊情况,仅限于只在第一帧提供掩码提示,并在多个帧上分别涂写以分割整个视频中的对象。在PVS中,提示既可以是点击,也可以是面具或框子,重点是增强交互体验,以最小的交互实现对物体分割的轻松细化。
B 局限性
SAM 2在静态图像和视频领域都表现出了较强的性能,但在某些场景下会遇到困难。该模型在镜头变化时可能无法分割物体,并且在拥挤的场景中,经过长时间的遮挡或在扩展的视频中,可能会丢失或混淆物体的轨迹。为了缓解这一问题,我们设计了在任意一帧中提示SAM 2的能力:如果模型丢失对象或出现错误,则在大多数情况下,对额外帧进行加细点击可以快速恢复正确的预测。特别是当物体快速移动时,SAM 2还难以准确地跟踪具有非常薄或精细细节的物体。另一个具有挑战性的场景是当附近有外观相似的物体(例如,多个相同的跳球)时。在SAM 2中加入更明确的运动建模可以减少这种情况下的错误。
虽然SAM 2可以同时跟踪视频中的多个对象,但SAM 2对每个对象进行单独处理,只使用共享的每帧嵌入,而不进行对象间的通信。虽然这种方法简单,但结合共享的对象级上下文信息有助于提高效率。
我们的数据引擎依赖于人类注释器来验证masklet质量并选择需要校正的帧。未来的发展可以包括自动化这一过程,以提高效率。
C SAM 2 细节
C.1 架构
在这里,我们进一步讨论了体系结构细节,扩展了§ 4中的模型描述。
图像编码器。我们使用特征金字塔网络( Lin et al . , 2017)来分别融合Hiera图像编码器第3和第4阶段的16和32步特征,以产生每一帧的图像嵌入。此外,阶段1和阶段2的步长4和8特征不用于记忆注意,而是添加到掩码解码器的上采样层中,如图9所示,这有助于产生高分辨率的分割细节。我们沿用Bolya等人( 2023 )在Hiera图像编码器中使用窗口绝对位置嵌入的方法。在Bolya et al . ( 2023 )中,RPB在主干中提供了跨窗口的位置信息,而我们采用了一种更简单的插值全局位置嵌入的方法来代替跨窗口。我们不使用任何相对位置编码。我们使用不同大小的图像编码器- - T,S,B和L来训练模型。我们遵循Li等人( 2022b )的方法,只在图像编码器层的子集(见表13)中使用全局注意力。
Memory attention。除了正弦绝对位置嵌入,我们在自注意力和交叉注意力层中使用二维空间旋转位置嵌入( RoPE ) ( Su et al . , 2021 ; Heo et al , 2024)。由于对象指针标记不具有特定的空间对应关系,因此将其排除在RoPE之外。默认情况下,记忆注意采用L = 4层。
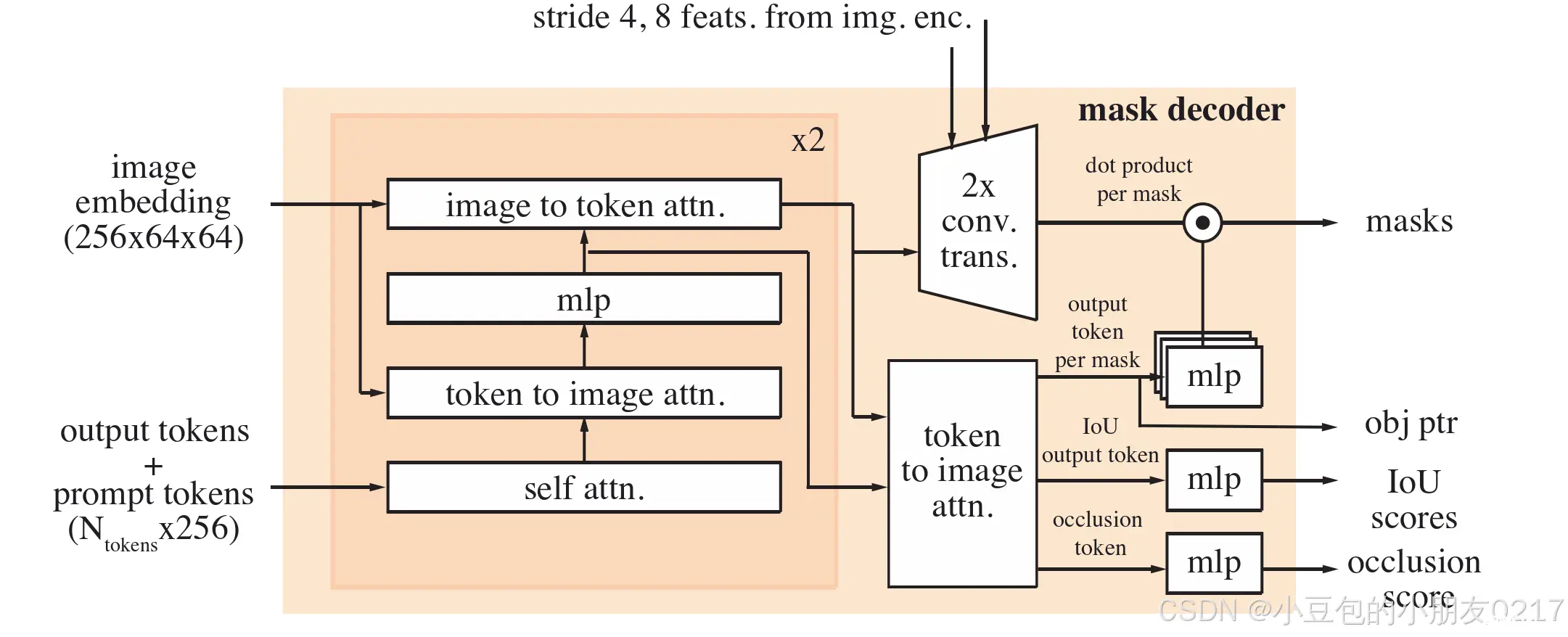
图9 掩码解码器架构。该设计在很大程度上遵循SAM,并且在上采样过程中,我们还包括了来自图像编码器的4步和8步特征。我们还使用输出掩码对应的掩码令牌作为对象指针,并生成一个遮挡分数,该分数表示感兴趣的对象在当前帧中是否可见。
提示编码器和掩码解码器。即时消息编码器的设计遵循SAM,下面讨论掩码解码器中关于设计变更的其他细节。我们将输出掩码对应的掩码令牌作为帧的对象指针令牌,放置在内存库中。正如§ 4所讨论的,我们也是引入遮挡预测头部。这是通过在掩码和IoU输出令牌的基础上增加一个额外的令牌来实现的。一个额外的MLP头被应用到这个新的令牌中,以产生一个分数,表示感兴趣的对象在当前帧(如图9所示)中可见的可能性。
SAM引入了当面对图像中被分割物体的歧义性时,输出多个有效掩码的能力。例如,当一个人点击自行车的轮胎时,模型可以将这个点击解释为仅指轮胎或整个自行车,并输出多个预测。在视频中,这种歧义可以跨视频帧扩展。例如,如果在一帧中只有轮胎是可见的,那么对轮胎的点击可能只与轮胎有关,或者随着更多的自行车在随后的帧中变得可见,这个点击可能是为整个自行车而设计的。为了处理这种歧义,SAM 2在视频的每一步都预测多个掩码。如果进一步提示没有解决歧义性,模型为当前帧选择预测IoU最高的掩码在视频中进一步传播。
记忆编码器和记忆库。我们的记忆编码器没有使用额外的图像编码器,而是复用了Hiera编码器产生的图像嵌入,并将其与预测的掩码信息融合以产生记忆特征(如§ 4所讨论)。这种设计使得存储器特征能够从图像编码器(特别是当我们将图像编码器扩展到更大的尺寸时)产生的强表示中受益。进一步,我们将记忆库中的记忆特征投影到64维,并将256维的对象指针拆分为4个64维的标记,以交叉关注记忆库。
C.2 训练
C.2.1 预训练
我们首先在SA - 1B数据集(基里洛夫et al , 2023)上的静态图像上预训练SAM 2。表13a详细介绍了在SA - 1B上进行预训练时使用的设置,其他未提及的设置遵循基里洛夫等人( 2023 )。图像编码器由MAE预训练的Hiera( Ryali et al , 2023)初始化。与SAM类似,我们过滤了覆盖90 %以上图像的掩膜,并将训练限制在每张图像64个随机采样的掩膜。
与SAM不同的是,我们发现使用ℓ( 1 )损失来更积极地监督IoU的预测,并对IoU逻辑施加sigmoid激活,将输出限制在0到1之间。对于多掩码预测(第1次点击),我们监督所有掩码的IoU预测,以鼓励更好地学习何时掩码可能是坏的,但只监督分割损失最低的掩码logits值(焦损失和骰子损失的线性组合)。在SAM中,在点的迭代采样过程中,插入两次迭代,没有额外的提示(只喂食先前的面具logits) - -我们在训练过程中没有添加这样的迭代,使用7个校正点击(而不是SAM中的8)。我们还在训练过程中使用了水平翻转增强,并将图像大小调整为1024 × 1024的正方形。
我们使用Adam W ( Loshchilov&Hutter,2019)并在图像编码器上应用层衰减( Clark et al , 2020),并遵循倒数平方根调度(翟志刚等, 2022)。预训练阶段的超参数见表13 ( a )。
C.2.2 全训练
经过预训练后,我们在我们引入的数据集SA - V Internal ( § 5.2 ),SA - 1B的10 %子集,以及DAVIS( Pont-Tutset et al , 2017 ;卡勒塞特, 2019),MOSE(丁一汇等, 2023)和YouTubeVOS( Xu et al , 2018b)等开源视频数据集的混合物上训练SAM 2。我们发布的模型是在SA - V手册Internal和SA - 1B上训练的。
SAM 2是为两个任务而设计的;Pvs任务(视频)和SA任务(图像)。训练是在图像和视频数据上联合完成的。为了优化训练过程中的数据使用和计算资源,我们采用了视频数据(多帧)和静态图像(单帧)交替训练的策略。具体来说,在每次训练迭代中,我们从图像或视频数据集中采样一个完整的批次,其采样概率与每个数据源的大小成正比。这种方法允许平衡地暴露两个任务和每个数据源的不同批大小,以最大限度地提高计算利用率。这里没有明确提到的图像任务的设置遵循从预训练阶段开始的设置。在整个训练阶段的超参数见表13 ( b )。训练数据混合体包括:Δ 15.2 % SA-1B,Δ 70 % SA - V和Δ 14.8 % Internal。当包含开源数据集时,使用相同的设置,但会包含额外的数据(约1.3%的DAVIS,约9.4%的MOSE,约9.2%的YouTubeVOS,约15.5%的SA-1B,约49.5%的SA-V,约15.1%的Internal)。
我们通过模拟交互设置进行训练,采样8帧序列,并随机选择多达2帧的(包括第一)进行纠正点击。在训练过程中,我们使用真实掩码和模型预测对提示进行采样,初始提示为真实掩码(概率为50 % )、从真实掩码中点击正键(概率为25 % )或边界框输入(概率为25 % )。
我们将8帧序列中每个序列的最大掩码数量限制为3个随机选择的掩码。我们以50 %的概率反转时间顺序,以帮助泛化到双向传播。当我们以10 %的小概率采样纠正点击时,我们从背景真值掩码中随机采样点击,而不考虑模型预测,以允许额外的掩码精化灵活性
损耗与优化。我们分别使用焦点和骰子损失的线性组合来监督模型的预测,用于掩膜预测的平均绝对误差( mean-absolute-error,MAE )损失用于IoU预测,以及用于目标预测的交叉熵损失,比例为20:1:1:1。与预训练时一样,对于多掩码预测,我们只监督分割损失最小的掩码。如果背景真值不包含一帧的掩码,我们不监督任何掩码输出(但总是监督遮挡预测头,预测帧中是否应该存在一个掩码)。

表13超参数和SAM 2预训练和完全训练的细节。值得注意的是,一些设置会随着图像编码器尺寸( T、S、B、L)的变化而变化。
C.3 速度基准测试
我们使用Py Torch 2.3 . 1和CUDA 12.1在单个A100 GPU上运行所有基准测试实验,使用bfloat16进行自动混合精度测试。对于所有SAM 2模型,我们都用炬编译了图像编码器,对于SAM和HQ - SAM也是如此,以便在SA task(表6和表15)上进行直接比较。对SA任务的FPS测量使用了10张图像的批处理尺寸,发现在所有3种模型类型中,FPS都是最高的。对于视频任务,我们在视频分割中使用了遵循通用协议的批大小为1的方法。
D 数据详情
D.1 SA-V 数据集详情
视频。视频分辨率为240p ~ 4K,平均大小为1 401 × 1 037。视频时长从4秒到2.3分钟不等,平均13.8秒,共计4.2 M标注帧,196小时
自动掩膜。类似于Kirillov的做法

图10第一幅图上的注释:( a )只有手动标签( ML ),( b )有自动标签( Auto )。自动标签增加了多样性和覆盖率
D.2 Data engine details
D.2.1 注释协议
我们的数据引擎中使用的注释协议的示意图如图11所示。标注任务被分解为由不同标注器执行的步骤:步骤1和步骤2专注于目标选择,步骤3和步骤4专注于掩码跟踪,步骤5专注于质量验证。SAM 2作为API部署在GPU上,并构建到注释工具中,以实现交互式使用。
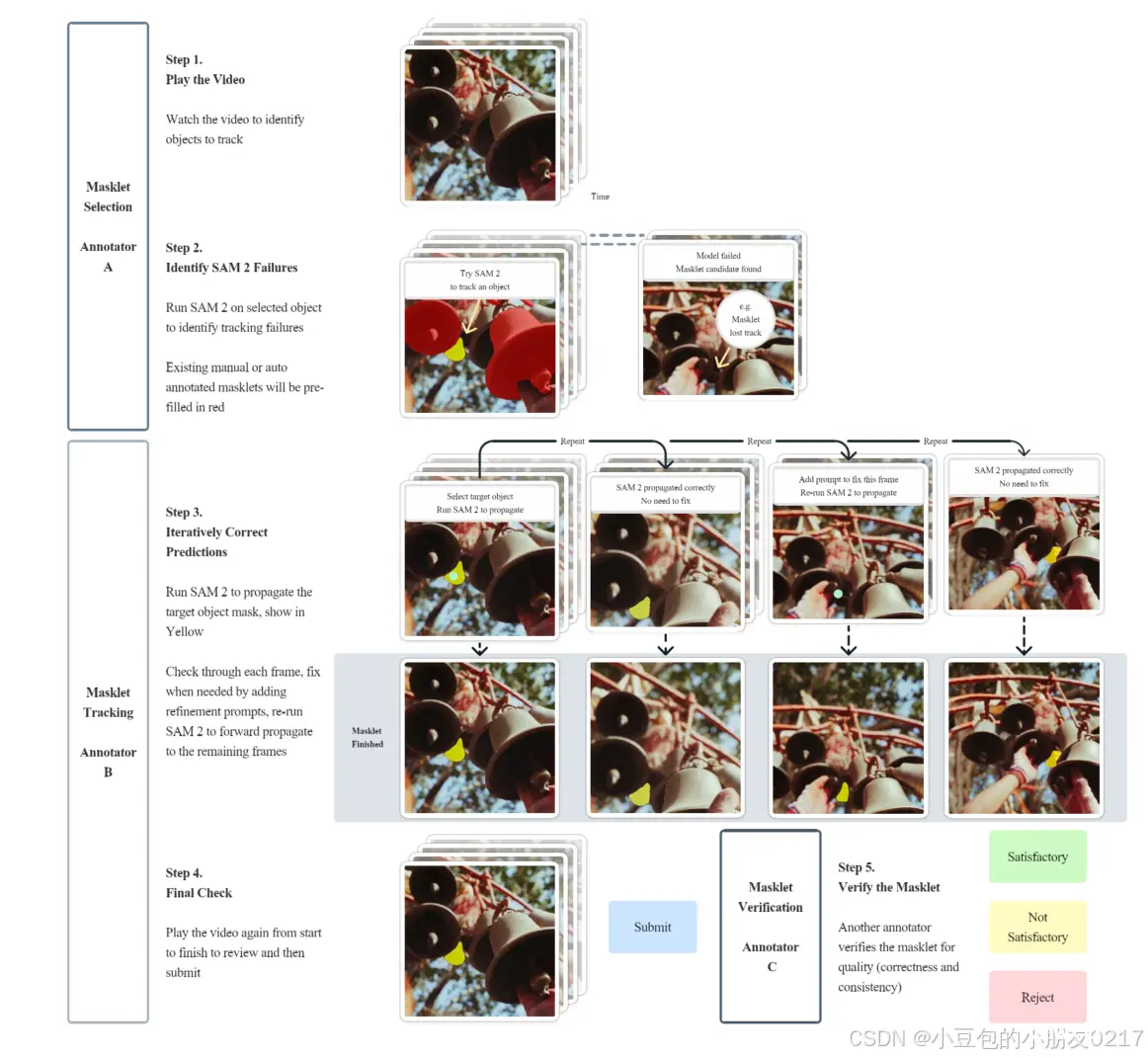
图11注释指南概览。主要有3个标注任务:掩码选择、掩码跟踪和掩码验证。每个任务都有一组不同的注释器在工作。
E 详细介绍了零样本迁移实验
在本节中,我们描述了零样本实验的进一步细节(第6节)。除非另有说明,否则本节中报告的结果遵循我们的默认设置,使用分辨率为1024的Hiera-B+图像编码器,并在数据集的完整组合上进行训练,即表7中的SAM 2(Hiera-B+)。
E.1 零样本学习视频任务
E.1.1 视频数据集详情
我们在17个零样本数据集的不同基准上对SAM 2进行了评估:EndoVis 2018( Allan et al , 2020)包含了带有机器人设备的医疗手术视频。ESD( Huang et al , 2023)包含机器人机械臂相机拍摄的视频,往往存在运动模糊现象。LVOSv2( Hong et al , 2024)是一个长期视频对象分割的基准。LV - VIS( Wang et al , 2023)包含了来自不同开放词汇表对象类别的视频。UVO( Wang et al , 2021b)包含用于开放世界对象分割的视频,而VOST(托克马科夫等, 2022)包含对象经历如鸡蛋破碎或纸张撕裂等大变形的视频。PUMaVOS( Bekuzarov et al , 2023)包含围绕人的脸颊等物体部位进行分割的视频。Virtual KITTI 2( Cabon et al , 2020)是一个包含驾驶场景的合成视频数据集。VIPSeg( Miao et al , 2022)提供了全景视频中的目标分割。
Wildfires从科西康火灾数据库中包含不同条件下的野火视频。VISOR( Darkhalil et al , 2022)包含了厨房场景中的以自我为中心的视频,其中包含了手和活动物体周围的片段。FBMS(布鲁克斯等, 2010)提供了对视频中运动物体的运动分割。Ego - Exo4D(格劳曼等, 2023)是一个包含围绕各种人类活动的自我中心视频的大型数据集。Cityscapes( Cordts等, 2016)包含城市驾驶场景的视频。Lindenthal Camera(Haucke&Steinhage,2021)包含了野生动物公园中的视频,其中包含了周围观察到的动物,如鸟类和哺乳动物的片段。HT1080WT Cells( Gómez-deMariscal et al . , 2021)包含带有细胞片段的显微镜视频。果蝇Heart(菲什曼等, 2023)包含果蝇心脏的显微视频。
在上述17个零样本视频数据集中,其中9个数据集( Endo Vis、ESD、LVOSv2、LV - VIS、UVO、VOST、PUMa VOS、Virtual KITTI 2、VIPSeg)为每一帧视频标注了密集的目标片段。在剩余的8个数据集( Wildfires、VISOR、FBMS、Ego - Exo4D、Cityscapes、林登塔尔Camera、HT1080WTCells、Drosophila Heart)中,仅在视频帧的子集上对目标片段进行稀疏标注,并在有地面真值分割掩膜的帧上计算度量值。在本文的大多数评估中,我们只在9个稠密标注的数据集上评估了零样本性能,而在我们的半监督VOS评估( § 6.1 . 2 )中,我们在上面列出的17个数据集上都进行了评估。
E.1.2 交互线下和线上评价细节
离线评估涉及整个视频的多个通道。我们从第一帧的点击提示开始,分割整个视频中的对象,然后在下一轮中,我们选择分割IoU值最低的帧作为新的提示帧。然后,该模型根据之前收到的所有提示再次分割整个视频中的对象,直到达到N帧通过的最大值(在每一个通道中都有一个新的提示帧)。
在线评价只涉及整个视频的一次传递。我们从第一帧的点击提示开始,并在视频中传播提示,当遇到低质量预测的( IoU < 0.75 ,符合基本事实)帧时,暂停传播。然后,我们在暂停帧上添加额外的点击提示,以纠正该帧上的片段,并恢复向前传播,直到到达另一个IoU < 0.75的低质量帧。当提示帧数小于最大N帧时,重复上述过程。与之前的离线评估不同,在这种设置下,新的提示只影响当前暂停帧之后的帧,而不影响当前暂停帧之前的帧。
在这两种设置下,我们在§ E.1.1 ( Endo Vis、ESD、LVOSv2、LV - VIS、UVO、VOST、PUMa VOS、Virtual KITTI 2、VIPSeg)中的9个注释密集的数据集上进行评估。如果一个视频包含多个待分割对象,在其背景-真值标注中,我们独立地对每个对象进行推理。我们模拟每帧Nclick = 3点击的交互式视频分割,假设用户会通过视觉定位物体来标注it(初始点击量)或者细化当前it(用更正点击)的分割预测。具体来说,在开始第一遍(其中,尚未有任何现有的预测)时,首先在物体真值掩码的中心1处点击第一帧的初始点,然后根据错误区域(在ground - truth mask和第一帧的预测片段之间)的中心交互地添加两个点击。然后在后续的pass(其中已经有预测的片段)中,我们基于错误区域(在地面真值掩码与被提示帧上的预测段之间)的中心交互地添加三个点击。
我们报告了基于以下假设,在视频上的8个交互帧和不同注释时间下的J&F度量:
在每一帧上,注释器需要Tloc = 1秒来视觉定位帧中的一个对象,并且按照Delatolas et al ( 2024 )的方法,每增加一个点击,需要Tclick = 1.5秒。
在离线模式下,对一个300帧的视频进行Texam = 30秒的测试,以检查每一轮视频的结果,包括找到分割质量最差的帧来添加修正值(而对于更长或更短的视频,这个时间与视频长度L成正比,假设注释器可以以10FPS的速度检查结果)。
在在线模式下,在300帧视频中,需要Texam = 30秒,才能跟踪整个视频的结果,包括暂停在低质量的帧,以便进一步修改(并且这个时间正比于与离线模式类似的视频长度L)。
一个对象的标注时间为离线模式下的( Texam · ( L / 300 ) Tloc Tclick · Nclick ) · Nframein和在线模式下的Texam · ( L / 300 ) ( Tloc Tclick · Nclick ) · Nframein,其中L为视频中的总帧数,Nframe = 1,…,8为标注(即,交互轮数)的帧数,Nclick = 3为每帧的点击次数2。
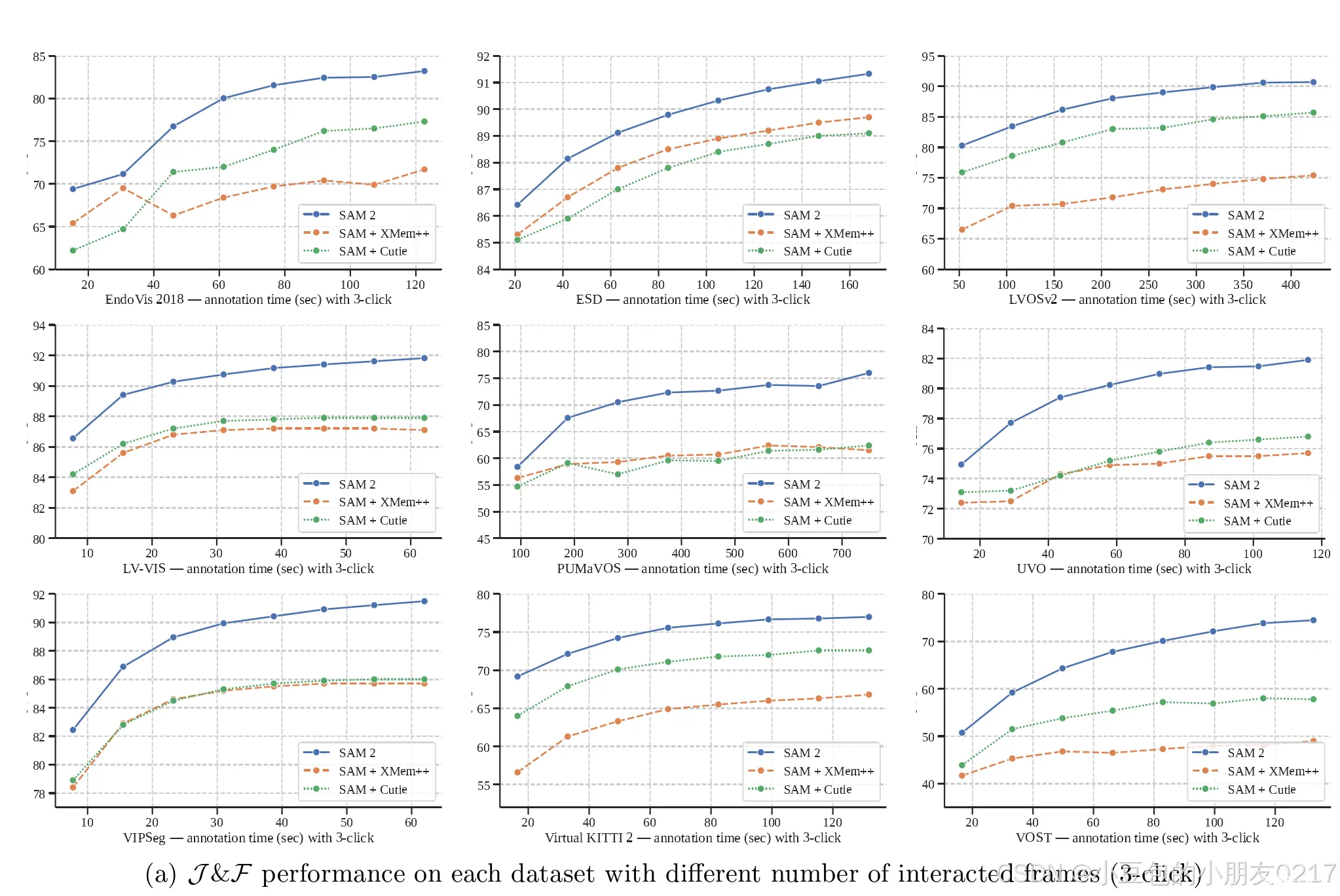

图12在不同交互帧数的交互离线评估下,SAM 2 vs baselines ( SAM XMem和SAM Cutie)的零样本学习性能,每个交互帧使用3个点击。详见§ E.1.2。
我们在图12和图13中展示了SAM 2和两个基线( SAM XMem和SAM Cutie ,详见下文)的离线和在线交互评估的逐数据集结果。SAM 2在所有数据集和设置上都显著优于两个基线。
E.1.3 半监督VOS评估细节
在§ 6.1 . 2中,我们还在半监督VOS设置( Pont-Tutset et al , 2017)的情况下与以前的视频跟踪方法进行了比较,其中(可以是前/后台系统点击、包围盒,也可以是背景-真值对象掩码)仅在视频的第一帧提供提示。当使用点击提示时,我们在第一个视频帧上交互地采样1、3或5个点击,然后根据这些点击来跟踪对象。遵循先前工作(基里洛夫et al , 2023 ; Sofiiuk et al , 2022)中基于点击的评估,初始点击放置在对象中心,随后的点击从错误区域的中心获得。
与交互设置类似,这里我们也使用SAM XMem和SAM Cutie作为两个基线。对于点击或方框提示,首先使用SAM处理点击或包围框输入,然后将其输出掩码作为XMem或Cutie的输入。对于掩码提示,第一个帧上的真实物体掩码直接作为XMem和Cutie的输入,这是标准的半监督VOS设置,在不使用SAM的情况下对XMem和Cutie进行评估。
在此设置下,我们在§ E.1 . 1中的所有17个零样本视频数据集上进行评估。如果一个数据集不遵循标准的VOS格式,我们将其预处理为类似MOSE(丁一汇等, 2023)的格式。在处理过程中,我们确保每个视频中的所有对象在第一帧上都有一个有效的非空分割掩码,以兼容半监督的VOS评估。如果物体在第一帧中没有出现,我们从物体出现的第一帧开始为它创建一个单独的视频。
我们报告了本次评估的标准J&F指标(Pont Tuset等人,2017)。如果一个数据集提供了一个官方的评估工具包,我们使用它进行评估( (在VOST数据集上,我们报告了J度量,遵循其官方协议(托克马科夫et al , 2022 )) )。结果如表4所示,SAM 2在不同类型提示的17个数据集中的大部分数据集上的表现都优于两个基线。我们在图14中展示了SAM 2和两个用于半监督VOS评估的基线( SAM XMem和SAM Cutie ,详见下文)的每一个数据集的结果。在不同类型的提示信息中,SAM 2在大多数数据集上都优于这两个基线。
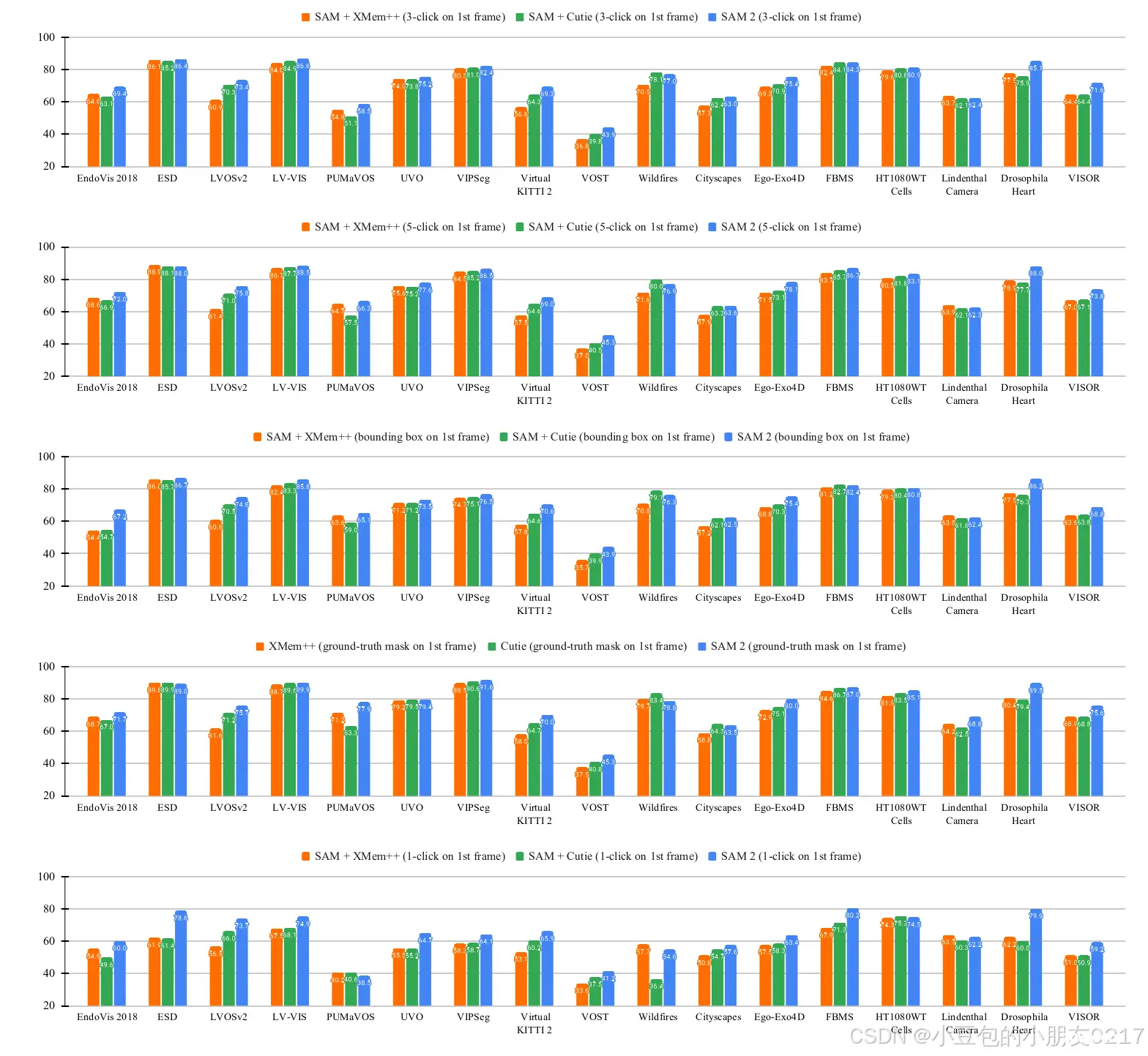
图14零样本学习在SAM的17个视频数据集上的表现( 2 )相对于两个基线( SAM XMem和SAM Cutie),使用不同的提示(在第一个视频帧中, 1、3或5次点击、边界框或真实值掩码)进行半监督VOS评估,各类型提示在数据集上的平均表现如正文表4所示。详见§ E.1 . 3。
E.1.4 SAM XMem和SAM Cutie基线详细信息
我们采用SAM XMem和SAM Cutie作为提示视频分割的两条基线,其中点击(或框选)提示首先被SAM处理以获得对象掩码,然后XMem / Cutie模型在视频中跟踪这个SAM掩码以获得最终的掩码。在这两条基线中,SAM既可以用于提供第一帧的初始目标掩码,也可以用于校正XMem或Cutie输出的现有目标掩码。这被用于交互离线和在线评估过程中的后续交互帧,其中提供了新的正点击和负点击,作为对现有掩码的更正。
当使用SAM对给定帧中的现有掩码预测进行校正时,我们遵循EVA - VOS( Delatolas et al , 2024)中的策略,首先使用XMem或Cutie输出掩码初始化SAM,然后再加入新的校正点击。具体来说,我们首先重构XMem或Cutie输出重构的掩码通过XMem或Cutie输出掩码达到IoU > 0.8。然后,为了融合新的正反向点击进行校正,我们将这些额外的校正点击与掩码构建时采样的初始点击进行串联,并将串联后的联合列表作为输入输入到SAM中,得到最终的校正掩码。我们发现这种策略的效果要好于几种替代方案(例如将XMem或Cutie输出掩码作为掩码提示与新的更正点击一起送入SAM ,或者只将更正点击作为SAM的输入而忽略XMem或Cutie输出掩码)。
E.2 DAVIS interactive benchmark
我们还在DAVIS交互式基准测试集( Caelles et al , 2018)上进行了评估,这与我们在§ 6.1 . 1中的交互式离线评估类似,在每一轮交互中,评估服务器都会在分割性能最差的帧上提供新的注释。官方的DAVIS评估工具包提供了交互过程中的点击提示,而其他工作如CiVOS(乌贾西诺维奇等, 2022)也扩展了这一点,以涵盖点击提示。
在这里,我们遵循CiVOS使用正负点击作为输入提示,并采用相同的策略进行点击采样。我们报告了评估者提供的该基准的J&F@60s和AUC-J&F指标,并将其与两个基线进行了比较:MiVOS(Cheng等人,2021b),它通过scribble-to-mask直接使用提供的涂鸦(在Vujasinović等人(2022)中也扩展到点击提示),以及CiVOS,它从提供的涂鸦中采样点击。结果如表14所示,其中SAM 2(基于点击输入)在点击输入下优于两个基线。我们注意到,SAM 2通常倾向于在第一次点击时分割对象部分(例如一个人的手臂),而DAVIS数据集主要包含整个对象(例如一个完整的人),这可能会影响SAM 2在此基准上的J&F性能。我们通过观察在较少的部分注释上训练的早期模型的更高精度(0.86 AUC-J&F和0.89 J&F@60s,点击输入)来验证这一点。
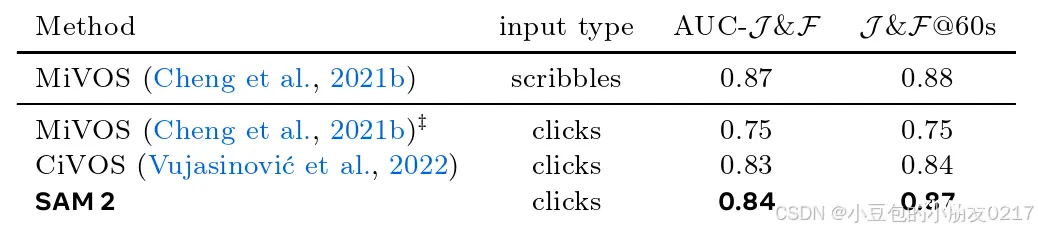
表14 SAM 2和其他模型在DAVIS交互基准上的性能。对于SAM 2,我们使用点击作为输入,遵循CiVOS(乌贾西诺维奇等, 2022)的点击采样策略。详见§ E.2 for Details( ć : Vujasinović et al . ( 2022 )的业绩报告) )。
Code 解析
code地址: https://github.com/facebookresearch/segment-anything-2/tree/main
git clone https://github.com/facebookresearch/segment-anything-2.git
cd segment-anything-2
pip install -e .
这里加个清华源会快很多
pip install -e . --index-url https://pypi.tuna.tsinghua.edu.cn/simple
然后就会遇到
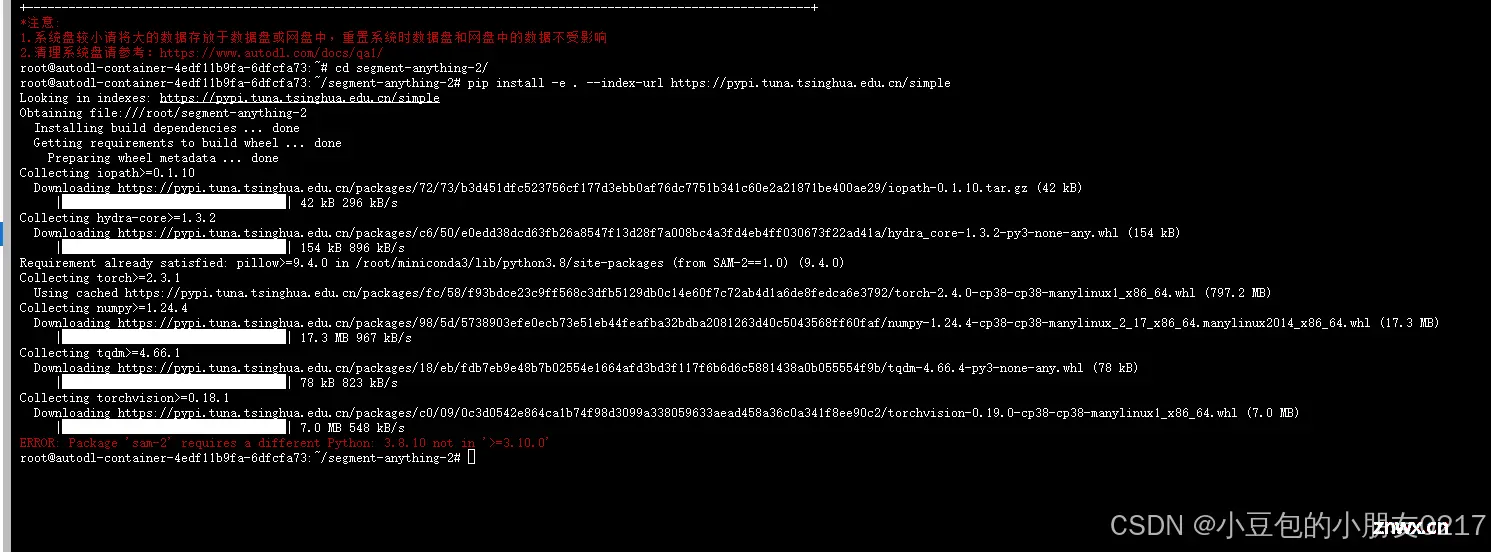
这是因为在setup.py文件里规定了各个包的版本,以及python的版本
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
from setuptools import find_packages, setup
from torch.utils.cpp_extension import BuildExtension, CUDAExtension
# Package metadata
NAME = "SAM 2"
VERSION = "1.0"
DESCRIPTION = "SAM 2: Segment Anything in Images and Videos"
URL = "https://github.com/facebookresearch/segment-anything-2"
AUTHOR = "Meta AI"
AUTHOR_EMAIL = "segment-anything@meta.com"
LICENSE = "Apache 2.0"
# Read the contents of README file
with open("README.md", "r") as f:
LONG_DESCRIPTION = f.read()
# Required dependencies
REQUIRED_PACKAGES = [
"torch>=2.3.1",
"torchvision>=0.18.1",
"numpy>=1.24.4",
"tqdm>=4.66.1",
"hydra-core>=1.3.2",
"iopath>=0.1.10",
"pillow>=9.4.0",
]
EXTRA_PACKAGES = {
"demo": ["matplotlib>=3.9.1", "jupyter>=1.0.0", "opencv-python>=4.7.0"],
"dev": ["black==24.2.0", "usort==1.0.2", "ufmt==2.0.0b2"],
}
def get_extensions():
srcs = ["sam2/csrc/connected_components.cu"]
compile_args = {
"cxx": [],
"nvcc": [
"-DCUDA_HAS_FP16=1",
"-D__CUDA_NO_HALF_OPERATORS__",
"-D__CUDA_NO_HALF_CONVERSIONS__",
"-D__CUDA_NO_HALF2_OPERATORS__",
],
}
ext_modules = [CUDAExtension("sam2._C", srcs, extra_compile_args=compile_args)]
return ext_modules
# Setup configuration
setup(
name=NAME,
version=VERSION,
description=DESCRIPTION,
long_description=LONG_DESCRIPTION,
long_description_content_type="text/markdown",
url=URL,
author=AUTHOR,
author_email=AUTHOR_EMAIL,
license=LICENSE,
packages=find_packages(exclude="notebooks"),
install_requires=REQUIRED_PACKAGES,
extras_require=EXTRA_PACKAGES,
python_requires=">=3.10.0",
ext_modules=get_extensions(),
cmdclass={ "build_ext": BuildExtension.with_options(no_python_abi_suffix=True)},
)
选择创建conda虚拟环境
conda create --name sam2 python=3.10
source activate
conda activate sam2
再次安装
pip install -e . --index-url https://pypi.tuna.tsinghua.edu.cn/simple
又会报错
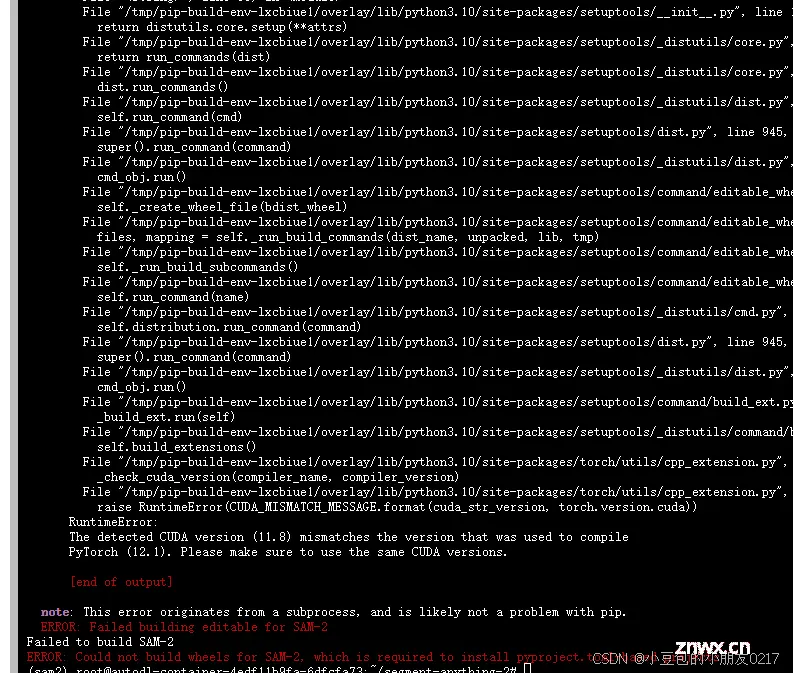
这是因为cuda版本不匹配,这里setup.py里面torch>=2.3.0,要求cuda版本要12.1。给torch降级是没用的,sam2这个包要求cu12
可以用
nvcc --version
查看自己的cuda版本

下载cuda12.1,但是用conda直接加载会报找不到,所以可以手动下载。
conda search cudatoolkit

手动下载,官方网站 https://developer.nvidia.com/cuda-toolkit-archive
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda_12.1.0_530.30.02_linux.run
chmod +x cuda_12.1.0_530.30.02_linux.run
export PATH=/usr/local/cuda-12.1/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH
然后使用
nvcc --version
查找,就可以看到12.1
不知道装在哪里的可以查找一下
sudo find / -name "*cuda*"
装好之后再安装就可以成功了
pip install -e . --index-url https://pypi.tuna.tsinghua.edu.cn/simple
cd checkpoints
./download_ckpts.sh
总结
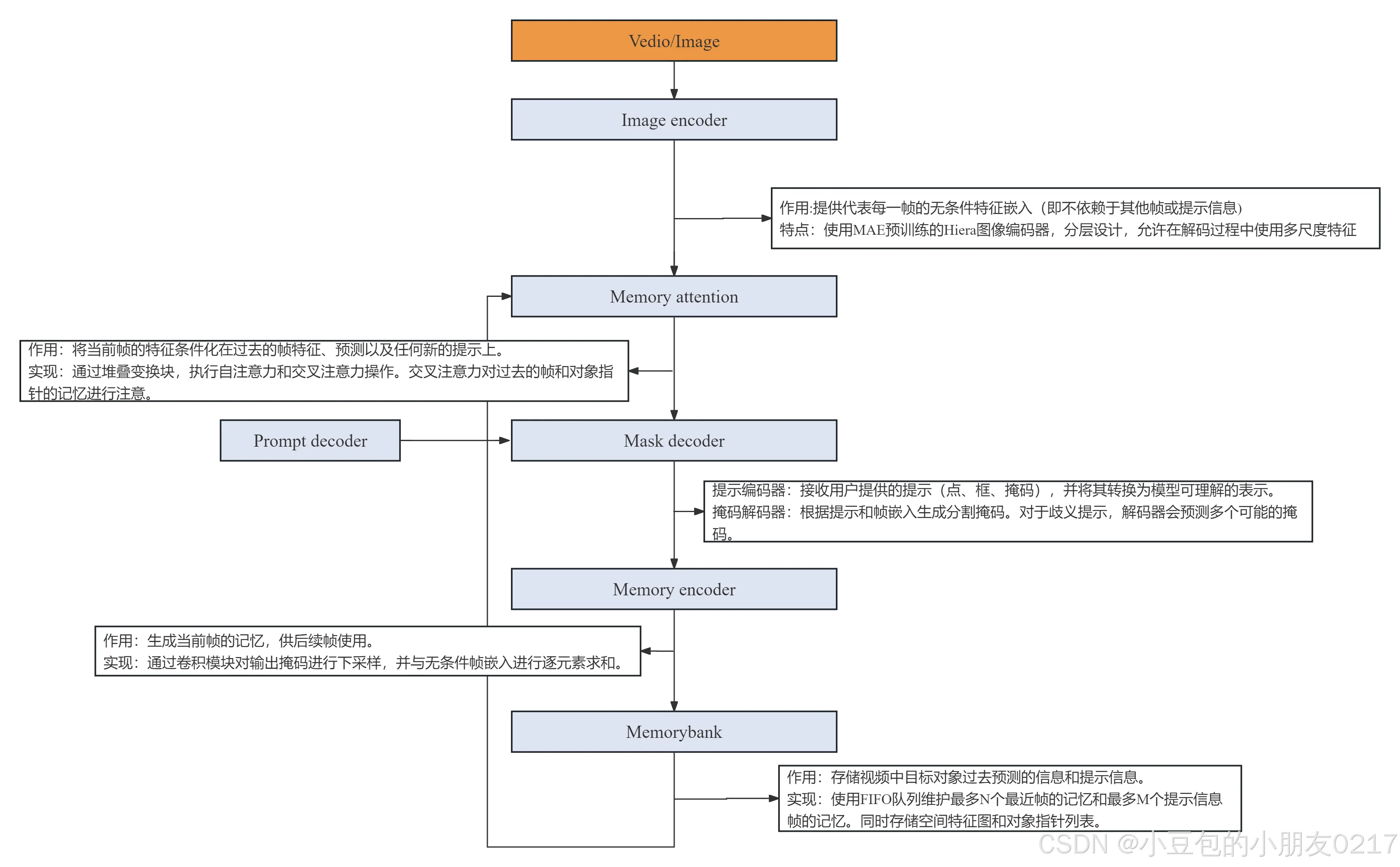
图像编码器
作用:图像编码器负责将每一帧视频图像转换为高维特征嵌入(令牌),这些特征嵌入包含了图像的重要信息,供后续处理使用。技术细节:
使用了MAE预训练的Hiera图像编码器,这是一个分层的编码器,允许在解码过程中使用多尺度特征。特征金字塔网络(FPN)被用来融合不同尺度的特征,以生成每一帧的图像嵌入。高分辨率特征(如步长为4和8的特征)被直接添加到掩码解码器的上采样层中,以产生更精细的分割细节。使用了窗口绝对位置嵌入和全局注意力来增强特征的空间感知能力。
记忆注意机制
作用:记忆注意机制通过结合当前帧的特征与过去帧的特征和预测,以及任何新的提示信息,来增强对当前帧的处理能力。技术细节:
堆叠了多个变换块,每个块执行自注意力和交叉注意力操作。自注意力关注当前帧的特征,而交叉注意力则关注存储体中的记忆特征和对象指针。使用了高效注意力核来优化性能。引入了二维空间旋转位置嵌入(RoPE)来增强位置信息的表达。
提示编码器和掩码解码器
作用:提示编码器将用户的交互提示(如点击、边界框、掩码)转换为模型可理解的格式。掩码解码器则根据图像编码器的输出和记忆库中的信息,预测当前帧的分割掩码。技术细节:
提示编码器与SAM类似,能够处理不同类型的提示。掩码解码器设计遵循SAM,但进行了必要的修改以适应视频分割任务。例如,对于歧义性提示,模型会预测多个掩码,并根据预测IoU选择最合适的掩码进行传播。引入了遮挡预测头,用于预测当前帧中目标对象的存在性。
记忆编码器和存储体(记忆库)
作用:记忆编码器将预测的掩码与图像嵌入结合,生成记忆特征,存储在记忆库中。存储体维护过去帧的记忆和提示信息,供后续帧处理时使用。技术细节:
记忆编码器复用了图像编码器的输出,并与预测的掩码信息融合,生成记忆特征。存储体通过FIFO队列维护最近帧的记忆和提示信息。除了空间记忆特征外,还存储了对象指针列表,作为目标对象的高层语义信息。记忆库中的特征被投影到较低的维度,并与对象指针一起用于交叉注意力操作。
总结
SAM 2通过整合上述组件,实现了对视频中目标对象的实时、交互式分割。图像编码器提供了每帧的高维特征表示,记忆注意机制利用过去帧的信息和当前提示来增强对当前帧的处理,提示编码器和掩码解码器负责将用户提示转换为分割掩码,而记忆编码器和存储体则维护了目标对象在视频中的连贯性。这种设计使得SAM 2能够处理复杂视频中的遮挡、模糊性和歧义性,生成高质量的分割结果。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。