人工智能原理实验3——产生式推理系统
在半岛铁盒里 2024-10-20 16:31:01 阅读 81
🧡🧡实验内容🧡🧡
以动物识别系统为例,用选定的编程语言建造规则库和综合数据库,开发能进行正确的正向推理或反向推理的推理机。
正向推理过程
从已知事实出发,通过规则库求得结论,或称数据驱动方式。推理过程是:
1.规则集中的规则前件与事实库中的事实进行匹配,得匹配的规则集合。
2.从匹配规则集合中选择一条规则作为使用规则。
3.执行使用规则的后件,将该使用规则的后件送入事实库中。
4.重复这个过程直至达到目标。
规则集
(1)若某动物有奶,则它是哺乳动物。
(2)若某动物有毛发,则它是哺乳动物。
(3)若某动物有羽毛,则它是鸟。
(4)若某动物会飞且生蛋,则它是鸟。
(5)若某动物是哺乳动物且有爪且有犬齿且目盯前方,则它是食肉动物。
(6)若某动物是哺乳动物且吃肉,则它是食肉动物。
(7)若某动物是哺乳动物且有蹄,则它是有蹄动物。
(8)若某动物是有蹄动物且反刍食物,则它是偶蹄动物。
(9)若某动物是食肉动物且黄褐色且有黑色条纹,则它是老虎。
(10)若某动物是食肉动物且黄褐色且有黑色斑点,则它是金钱豹。
(11)若某动物是有蹄动物且长腿且长脖子且黄褐色且有暗斑点,则它是长颈鹿。
(12)若某动物是有蹄动物且白色且有黑色条纹,则它是斑马。
(13)若某动物是鸟且不会飞且长腿且长脖子且黑白色,则它是驼鸟。
(14)若某动物是鸟且不会飞且会游泳且黑白色,则它是企鹅。
(15)若某动物是鸟且善飞且不怕风浪,则它是海燕。
🧡🧡实现🧡🧡
数据结构
self.rule_dict = { } # 规则:key为条件,value为结论
self.fact_list = [] # 事实
self.process = "" # 推导过程
self.conclusion = "" # 结论
self.data_base = set() # 数据库
规则的存储:用字典存储,规则的条件作为key值,规则的结论作为value值,例如,对于规则“若某动物有奶,则它是哺乳动物”和“若某动物会飞且生蛋,则它是鸟”,则它们的存储的字典为:
{
(“有奶”):哺乳动物,
(“会飞”,“生蛋”):鸟
}事实的存储:列表存储,元素为字符串,例如对于事实F1:某动物有毛发、F2:吃肉、F3:黄褐色、F4:有黑色条纹,则存储为
[ “有毛发”,“吃肉”,“黄褐色”,“黑色条纹”]推导过程和结论的存储:均用字符串。数据集的存储:存储推导过程中的已知的条件和已经推导出的结论,用集合存储,防止重复添加。
核心算法
self.fact_list = [fact.strip() for fact in fact_content_list]
self.data_base = set(self.fact_list) # 将事实存入数据库
self.process=""code>
flag = False # 是否能推导成功
n = 0
while n < 2: # 循环两遍
for premise, conclusion in self.rule_dict.items():
premise=set(premise) # tuple 转 set
if premise <= self.data_base: # 集合运算<= 前提是否都在data_base中
if conclusion in self.data_base:
continue
self.data_base.add(conclusion)
self.conclusion = conclusion
self.process += "%s -----> %s\n" % (premise, conclusion)
flag = True
n += 1
1.获取用户输入的事实(facts)。
2.将事实存入数据库(data_base)。
3.遍历规则字典(rule_dict),判断每条规则的前提条件是否在数据库中。
4.如果前提条件满足,将规则的结论加入数据库,并记录推导过程。
5.重复步骤3和4,直到没有新的结论被加入数据库(达到一定的循环次数)。
为什么要外套一层循环while?
保证推导的准确性和完整性。
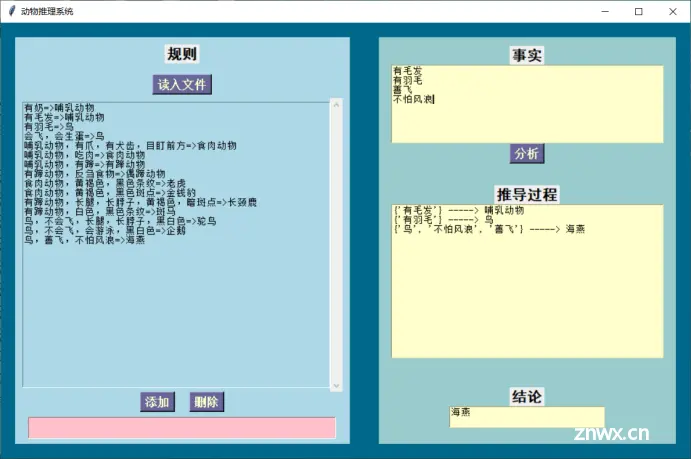
例如,有规则R1、R2、R3如下:
R1:若某动物是哺乳动物且吃肉,则它是食肉动物。
R2:若某动物有毛发,则它是哺乳动物。
R3:若某动物是食肉动物且黄褐色且有黑色条纹,则它是老虎。
有事实如下:
F1:某动物有毛发
F2:吃肉
F3:黄褐色
F4:有黑色条纹
如果只遍历一轮:
对于R1:数据集中现有知识不满足前提条件“哺乳动物”。
对于R2:满足“有毛发”前提条件,将其结论“哺乳动物”加入数据集中
对于R3:数据集中现有知识不满足前提条件“食肉动物”
显然,由于遍历有先后顺序,导致后续的规则可能因为前提条件未满足而无法推导出结论,因此需要多套一层循环,再遍历一轮即可。
结果展示
输入格式说明:
我指定了输入规则的具体格式,以便程序容易识别规则的前提条件和结论。
如下图:=>前面的是条件,且用,分隔开,=>后面的是结论

利用python的tkinter库实现了简单的界面交互,这是初始界面
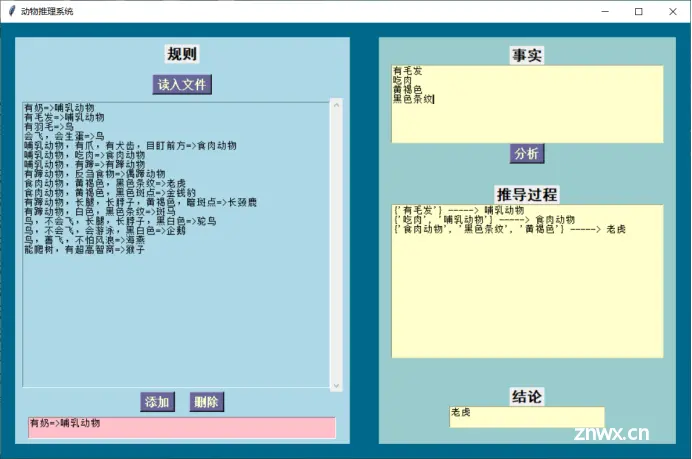
为方便后续增删改查的操作,这里设置了文本框不能输入的状态,只作为展示框,因此需要通过读入文件的形式展示规则。

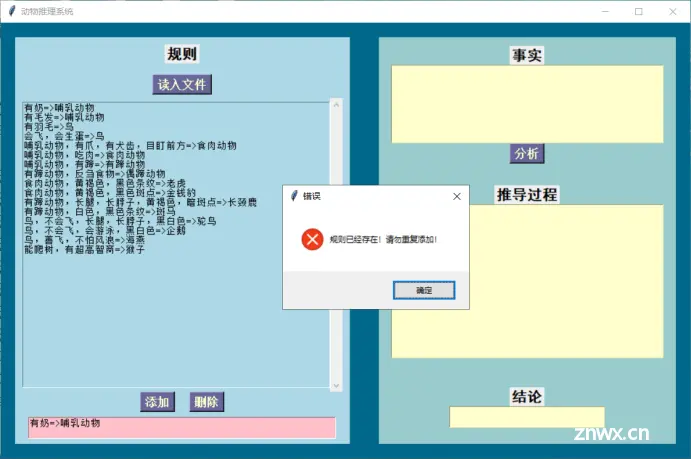
在粉色框中,可以实现增删改的操作,例如,添加一条规则:“如果某动物能爬树,且有超高智商,则它是猴子”。同时,添加前会对规则库进行查询,若规则库已有知识,则会提示不能添加。删除同理。如果想进行修改操作,可以进行先删除后添加的操作。

输入事实,点击按钮进行分析
🧡🧡完整代码🧡🧡
需要安装tkinter库 ~
<code>import re
import tkinter as tk
from tkinter import ttk, filedialog, font
import tkinter.messagebox
class AnimalReasoningSystem:
def __init__(self):
self.rule_dict = { } # 规则:key为条件,value为结论
self.fact_list = [] # 事实
self.process = "" # 推导过程
self.conclusion = "" # 结论
self.data_base = set() # 数据库
# region =======================渲染======================
self.root_win = tk.Tk()
self.root_win.title("动物推理系统")
self.root_win.geometry("950x600+250+100")
self.root_win.config(bg="DeepSkyBlue4")code>
button_style = {
'bg': '#666699',
'fg': '#FFFFCC',
'activebackground': '#FFF5EE',
'activeforeground': '#2F4F4F',
'relief': 'raised',
'anchor': 'center',
'font': font.Font(size=12,weight="bold")code>
}
label_font=font.Font(family="黑体", size=15, weight="bold")code>
# =========左右布局框==========
self.left_frame = tk.Frame(self.root_win, width=550, bg="lightblue")code>
self.left_frame.pack(side="left", fill="y", pady=20, padx=20, ipady=10, ipadx=10)code>
self.right_frame = tk.Frame(self.root_win,
border=2,
bg="#99CCCC")code>
self.right_frame.pack(fill="both",code>
pady=20, ipady=30, padx=20, ipadx=30,
expand=True)
# ========左框组件===========
self.text_label = tk.Label(self.left_frame, text="规则",font=label_font)code>
self.text_label.pack(pady=10)
self.input_button = tk.Button(self.left_frame,
text="读入文件",code>
command=lambda: self.open_txt_file(),
**button_style)
self.input_button.pack(pady=5)
self.input_text_frame = tk.Frame(self.left_frame,bg="lightblue")code>
self.input_text_frame.pack()
self.input_scrollbar = tk.Scrollbar(self.input_text_frame,
orient="vertical",code>
highlightbackground="blue",)code>
self.input_scrollbar.pack(side="right", fill="y")code>
self.input_text = tk.Text(self.input_text_frame,
width=60,
height=30,
bg="lightblue",code>
yscrollcommand=self.input_scrollbar.set)
self.input_scrollbar.configure(command=self.input_text.yview)
self.input_text.pack(pady=5)
self.input_text.config(state="disabled")code>
self.func_frame = tk.Frame(self.left_frame, bg="lightblue")code>
self.func_frame.pack()
self.add_btn = tk.Button(self.func_frame, text="添加",code>
command=lambda: self.add_rule(),
**button_style)
self.del_btn = tk.Button(self.func_frame, text="删除",code>
command=lambda: self.del_rule(),
**button_style)
self.add_btn.grid(row=0, column=0, padx=10)
self.del_btn.grid(row=0, column=1, padx=10)
self.func_text=tk.Text(self.left_frame,bg="pink",width=60)code>
self.func_text.pack(pady=7)
# ========右框组件===========
self.right_top = tk.Frame(self.right_frame, width=400, height=150, bg="#99CCCC")code>
self.right_top.pack(padx=10, pady=10)
self.right_middle = tk.Frame(self.right_frame, width=400, height=300, bg="#99CCCC")code>
self.right_middle.pack(padx=10, pady=20)
self.right_bottom = tk.Frame(self.right_frame, width=400, height=50, bg="#99CCCC")code>
self.right_bottom.pack(padx=10, pady=20)
self.top_label = tk.Label(self.right_top, text="事实",font=label_font)code>
self.top_label.pack()
self.top_text = tk.Text(self.right_top, height=8, width=60,bg="#FFFFCC")code>
self.top_text.pack(padx=5)
self.analyse_button = tk.Button(self.right_top,
text="分析",code>
command=lambda: self.analyse(),
**button_style)
self.analyse_button.pack(padx=10)
self.middle_label = tk.Label(self.right_middle, text="推导过程",font=label_font)code>
self.middle_label.pack()
self.middle_text = tk.Text(self.right_middle, height=16, width=60,bg="#FFFFCC")code>
self.middle_text.pack(padx=5)
self.bottom_label = tk.Label(self.right_bottom, text="结论",font=label_font)code>
self.bottom_label.pack()
self.bottom_text = tk.Text(self.right_bottom, height=5, width=30,bg="#FFFFCC")code>
self.bottom_text.pack(padx=5)
# ==========保持主循环===========
self.root_win.mainloop()
# endregion
def show_rule(self): # 展示规则
self.input_text.config(state="normal")code>
text_content=""code>
for premises,conclusion in self.rule_dict.items():
for idx,p in enumerate(premises):
text_content+=p
if idx==len(premises)-1:
continue
text_content+=","
text_content += "=>"+conclusion+"\n"
self.input_text.delete(1.0, tk.END)
self.input_text.insert(tk.END,text_content)
self.input_text.config(state="disabled") #code>
def open_txt_file(self): # 使用文件对话框选择要打开的文件
filepath = filedialog.askopenfilename(filetypes=[('Text Files', '*.txt')])
if filepath:
# 读取文件内容
with open(filepath, 'r', encoding='utf-8') as file:code>
txt_content = file.read()
# 存入rule_dict中
txt_content = txt_content.split("\n")
# print(txt_content)
for line in txt_content:
line = line.strip()
if not line: # 忽略空行
continue
if "=>" not in line: # 如果该行不包含"=>"
print(f"error: { line}")
tkinter.messagebox.showerror("错误", "规则格式错误!")
return
premise, conclusion = line.split("=>") # 解析条件和结论
premise = [p.strip() for p in premise.split(",")] # 将条件用逗号分隔成列表
conclusion = conclusion.strip()
self.rule_dict[tuple(premise)] = conclusion
# print(self.rule_dict)
self.show_rule()
def analyse(self): # 根据事实和规则进行推导
fact_content = self.top_text.get("1.0", tk.END)
fact_content_list = fact_content.split("\n")
fact_content_list.pop() # 去除\n分割出的最后一行空白“”
self.fact_list = [fact.strip() for fact in fact_content_list] # 去除每行的前后空格
# print(self.fact_list)
self.data_base = set(self.fact_list) # 将事实存入数据库
self.process=""code>
flag = False # 是否能推导成功
n = 0
while n < 2: # 循环两遍
for premise, conclusion in self.rule_dict.items():
premise=set(premise) # tuple 转 set
if premise <= self.data_base: # 集合运算<= 前提是否都在data_base中
if conclusion in self.data_base:
continue
self.data_base.add(conclusion)
self.conclusion = conclusion
self.process += "%s -----> %s\n" % (premise, conclusion)
flag = True
n += 1
if flag:
self.middle_text.delete("1.0", tk.END) # 清空
self.bottom_text.delete("1.0", tk.END)
self.middle_text.insert(tk.END, self.process) # 添加
self.bottom_text.insert(tk.END, self.conclusion)
else:
tkinter.messagebox.showerror("错误", "推导失败!请再完善规则或检查事实!")
def find_rule(self, premise_list): # 查找规则
flag = False
for premises in self.rule_dict.keys():
if tuple(premise_list) == premises:
flag = True
break
return flag
def add_rule(self): # 添加规则
text_content=self.func_text.get("1.0",tk.END) # str
text_content.strip()
print(text_content)
if "=>" not in text_content:
return
premise, conclusion = text_content.split("=>") # 解析条件和结论
premise_list = [p.strip() for p in premise.split(",")] # 将条件用逗号分隔成列表
if not self.find_rule(premise_list):
self.rule_dict[tuple(premise_list)]=conclusion
self.show_rule()
tk.messagebox.showinfo("提示","添加成功!")
else:
tk.messagebox.showerror("错误", "规则已经存在!请勿重复添加!")
def del_rule(self): # 删除规则
text_content=self.func_text.get("1.0",tk.END) # str
text_content.strip()
if "=>" not in text_content:
return
premise, conclusion = text_content.split("=>") # 解析条件和结论
premise_list = [p.strip() for p in premise.split(",")] # 将条件用逗号分隔成列表
if self.find_rule(premise_list):
del self.rule_dict[tuple(premise_list)]
self.show_rule()
tk.messagebox.showinfo("提示", "删除成功!")
else:
tk.messagebox.showerror("错误", "要删除的规则不存在!")
if __name__ == '__main__':
AnimalReasoningSystem()
🧡🧡总结🧡🧡
心得体会
从知识的理论层面:这个产生式推导实验主要模拟了正向推理,熟悉和掌握了产生式系统的运行机制,掌握了基于规则推理的基本方法,实现了动物分类系统,更加了解了人工智能领域的知识表示和推理方法。
从实践代码的角度:实验本身的正向推理的实现逻辑并不复杂,但是关键是要选好合适的数据结构,以及合适的语言实现,对于这个实验,python的便捷性就显现出来了,一来python有强大的数据处理能力,如列表、字典、集合等数据结构,以及灵活的迭代器,使得我可以方便的存储和操作大量的规则和事实,并进行高效的规则查询和推理。此外,我再次练习了tkiner GUI库的组件方法,增强了代码的交互性,方便规则的增上改查。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。