探索大模型的“心理理论”能力:TMBENCH基准测试
人工智能大模型讲师培训咨询叶梓 2024-10-09 16:31:05 阅读 67
人工智能咨询培训老师叶梓 转载标明出处
心理理论是理解他人信念、意图、情感等心理状态的能力,对人类社会交往至关重要。近期研究引发了关于LLMs是否展现出ToM的辩论。然而,现有的评估方法受限于范围狭窄、主观判断和潜在的数据污染等问题,无法提供充分的评估。为了填补这一空白,清华大学的研究团队及其合作者们提出了TMBENCH,这是一个包含8个任务和31种能力的系统化评估框架,采用多项选择问题格式,支持自动化和无偏见的评估,并构建了全新的双语库存,严格避免数据泄露。
TMBENCH框架

TMBENCH的三个关键特性:系统化评估框架、多项选择问题格式以及从头构建的双语库存。这个框架包括8个任务和31种社交认知能力,并且有2,860个测试样本,涵盖了多样化的真实世界社交场景
TMBENCH的三大特点
系统化评估框架: TMBENCH基于广泛的心理学文献,定义了8个评估ToM能力的社会认知任务,并基于ATOMS(Abilities in the Theory-of-Mind Space)框架,扩展到31种核心ToM能力。多项选择问题格式: 每个测试样本都是一个故事,后面跟着一个问题和几个可能的选项,其中只有一个正确答案,其他都是高质量的误导性错误答案。从头开始构建的库存: 为了避免潜在的数据污染,研究者从头开始创建了2860个原始测试样本,并实施了严格的注释和验证程序。
8个心理理论任务
TMBENCH框架的核心是对大型语言模型(LLMs)在心理理论(ToM)方面的能力进行评估。为此,研究者首先从心理学文献中识别出8个广泛用于评估ToM能力的社交认知任务。这些任务包括:
Unexpected Outcome Test(意外结果测试):评估参与者推断角色在情绪激发情境与实际激发情绪之间明显差异时的心理状态。Scalar Implicature Task(量词含义任务):涉及不完全信息情况下,说话者使用术语如“一些”来暗示“不是全部”。Persuasion Story Task(说服故事任务):评估参与者理解和选择有效说服策略的能力,反映他们如何影响他人的心理状态和态度。False Belief Task(错误信念任务):检验参与者是否能够区分自己的信念(真实信念)和他人的信念(错误信念)。Ambiguous Story Task(模糊故事任务):提供不明确的社交小插曲,随后的问题评估参与者对他人在不确定情境下的心理状态的理解。Hinting Test(暗示测试):评估参与者从社交互动中的间接暗示推断心理状态的能力。Strange Story Task(奇异故事任务):要求参与者推断包含复杂社交交流的故事中的角色的心理状态。Faux-pas Recognition Test(失礼行为识别测试):测试参与者识别社交故事中角色失礼行为的能力。
这些任务是根据原始心理学文献中的定义、描述和例子构建的测试样本。

8个任务与31个ATOMS(Abilities in the Theory-of-Mind Space)能力之间的映射关系。每个能力后缀表示其在特定任务中的出现,而带有“#”的是未被任务覆盖的能力,将通过额外的测试样本进行评估
31个心理理论能力
TMBENCH框架进一步利用心理学专业知识,认识到任务是手段,而能力是核心。因此研究者参考了一个定义良好的心理学框架“Abilities in the Theory-of-Mind Space (ATOMS)”,它概述了7个不同的能力维度:情感、欲望、意图、感知、知识、信念和非字面沟通,涵盖了39种特定的ToM能力。
在TMBENCH中,由于视觉线索的需要,移除了感知维度和一些混合能力,保留了6个维度和31种能力。这8个任务只涵盖了ATOMS中的19/31能力,因此,为了覆盖剩余的12种能力,研究者参考原始文献补充了额外的能力特定测试样本,从而将TMBENCH的评估范围扩展到完整的31种能力。
这些能力维度包括:
情感(Emotion):涉及理解情境因素如何影响人的情绪状态,人们可以体验复杂情绪,以及人们可以调节情绪表达的能力。欲望(Desire):涉及理解人的主观欲望、偏好和想要影响他们的情绪和行为的能力。意图(Intention):涉及理解人们为了追求目标和意图而采取行动的能力。知识(Knowledge):涉及理解他人基于他们的感知、接收到的信息或对事物的熟悉程度拥有不同知识的能力。信念(Belief):涉及理解人们可以持有与现实不同或与自己信念不同的信念的能力。非字面沟通(Non-literal Communication):涉及理解沟通可以传达超出字面所说意义的能力。
TMBENCH框架通过这些任务和能力,为评估LLMs的ToM能力提供了一个全面和系统化的平台,有助于推动LLMs在社会智能领域的进一步发展。
TMBENCH构建
TMBENCH的构建遵循了从零开始的原则。为了避免数据污染和测试样本数量有限的风险,研究者没有使用心理学文献中现有的任何库存。所有参与构建的工作者都经过了心理学专家的培训,对ToM有了深入的理解,并且严格遵循了任务和能力的具体定义、描述和例子。
研究者首先为8个任务制作样本,每个任务至少由一个工作者负责,总共覆盖19种能力。由于任务和能力的自然难度,确保每个任务至少有100个样本,每个任务内的能力至少有20个样本。这一步骤产生了2470个样本。随后,为之前未覆盖的剩余12种能力添加额外的样本,每种能力至少20个样本,使得样本总数达到2860个。
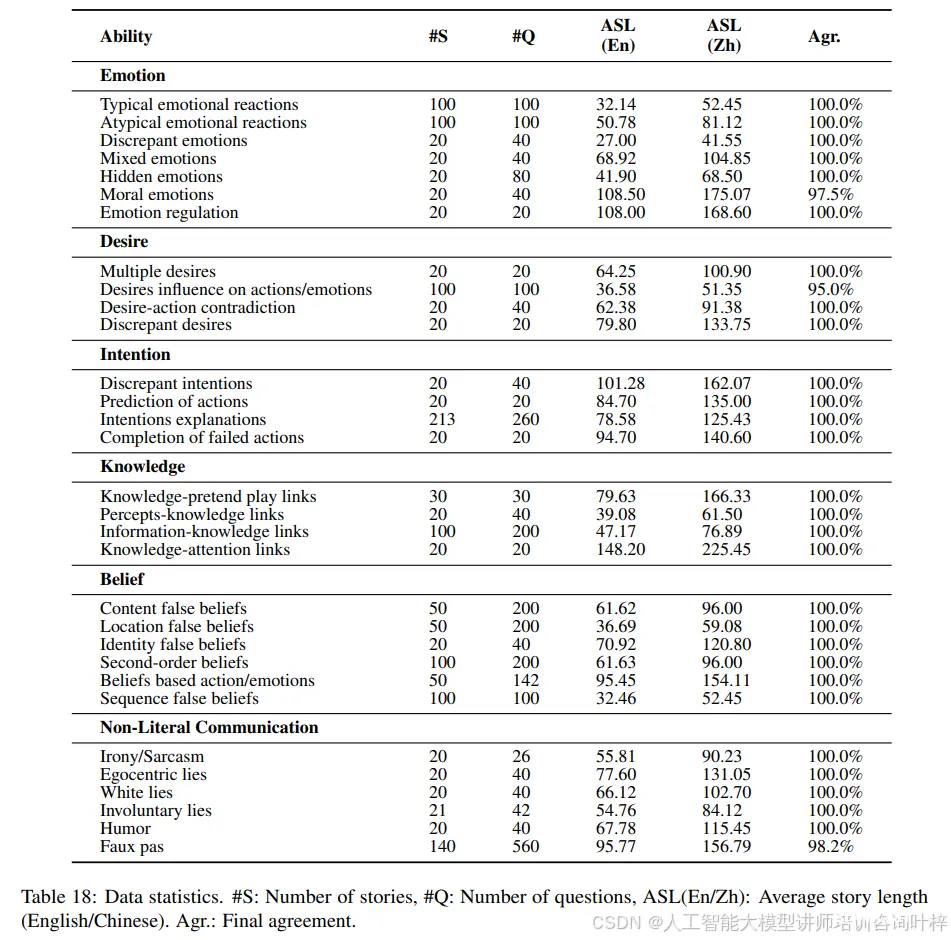
在表1中,展示了TMBENCH的数据统计信息。表18提供了TMBENCH评估框架中31种心理理论能力的详细统计数据。
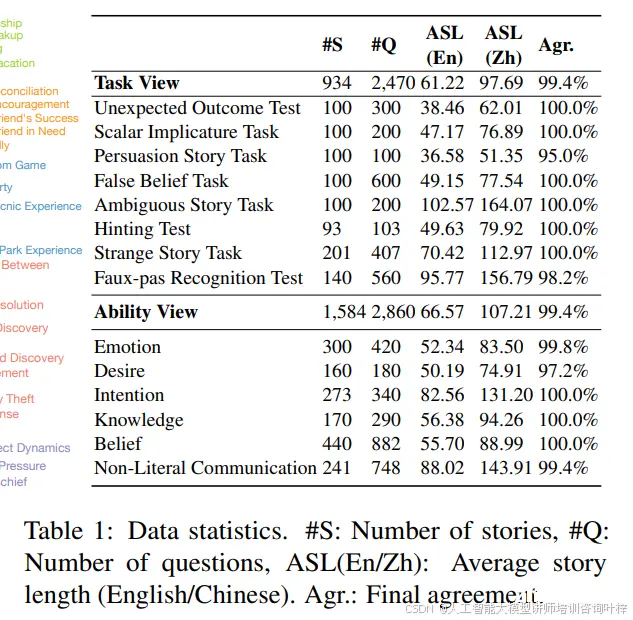
TMBENCH的数据统计信息,包括故事数量、问题数量、英文和中文的平均故事长度(ASL),以及最终的一致性同意率

31种能力的详细统计数据
如图3所示,TMBENCH包含了多样化的日常主题,如学校、工作场所、家庭、社区等。这些现实生活社交场景对于有效的ToM评估至关重要。
TMBENCH中社交场景的话题分布,包括9个主要话题和每个话题下的5个子话题。这些真实生活社交场景对于有效的ToM评估至关重要
TMBENCH构建为多项选择题形式,以避免手动评分的高成本,并确保评估的公正性和一致性。每个样本定义为一个故事、一个问题和几个选项的组合。
故事:描述来自日常生活的情境,包括角色的行动和互动,为评估设置上下文。故事的灵感主要来自Reddit、Twitter、知乎和微博等社交平台上的帖子。
问题:要求受试者理解故事的特定方面,严格遵循ToM任务和能力的心理定义。每个问题都被设计为人类可以回答的。一个故事可以对应多个问题,每个问题探索社交情境的不同方面,以评估全面的理解。
选项:包括一个正确答案和几个误导性的错误答案。错误选项被设计为看似合理,避免了容易被排除的离群值。选项通常有两种类型:对于是非问题,如“PersonA说的是真的吗?”选项仅为是/否。对于解释性问题,如“PersonB为什么这么说?”则提供四个选项。
在数据收集后,进行两轮验证以确保数据质量。第一轮中,工作者A首先完成工作者B创建的所有样本。对于故事、问题和选项存在分歧的地方,工作者A和B会讨论并修改它们,尽可能达成共识。第二轮中,对于仍未达成共识的样本,另一名工作者C将与A和B讨论,以确定最终答案。两轮讨论后,最终平均一致性达到了99.4%。
最初以中文制作的库存。然后,研究者仔细使用GPT-4-0613将其翻译成英文,并手动检查所有翻译样本,以支持双语ToM评估。注意,在翻译中没有提供正确答案,因此没有数据泄露。翻译提示可以在附录E中找到。
在TMBENCH中,测试样本从两个角度组织:任务视图将它们分为8个理论心智任务,能力视图将它们归类为31种特定的理论心智能力。前者更通用,通常用于心理学研究;后者更全面,允许检查每种特定能力的表现。相应地,通过平均与特定任务或能力相关的样本来报告任务导向和能力导向的结果。对于评估,向LLMs展示一个故事、一个问题和几个选项,然后要求它们选择正确答案。
这个构建过程确保了TMBENCH的评估既全面又具有深度,能够从多个角度考察LLMs的ToM能力,并通过严格的验证和翻译流程保证了评估的质量和公正性。
实验
实验设置
实验评估了共10种流行的大型语言模型(LLMs),包括GPT-4的不同版本以及其他几种模型,例如ChatGLM3-6B、LLaMA2-13B-Chat、Baichuan2-13B-Chat等。对于GPT*和其他开放的LLMs,研究者通过官方API和模型权重严格遵循其条款进行访问。
实验采用了两种提示方法:直接询问LLMs进行选择的“vanilla prompting”(普通提示),以及通过逐步推理来引导答案的“CoT prompting”(链式推理提示)。
为了避免选项ID带来的偏差,对于所有模型(GPT-4-*除外),研究者将选项顺序随机打乱五次,并选择最常被选择的选项作为最终答案。对于e GPT-4-*模型,由于初步实验显示不同选项顺序下的答案非常一致,因此只使用一轮回答的结果。准确性被用作评估指标。
为了建立人类基线,研究者招募了20名母语为中文的研究生完成中文TMBENCH。没有提供额外的教程或示例以确保公平比较。
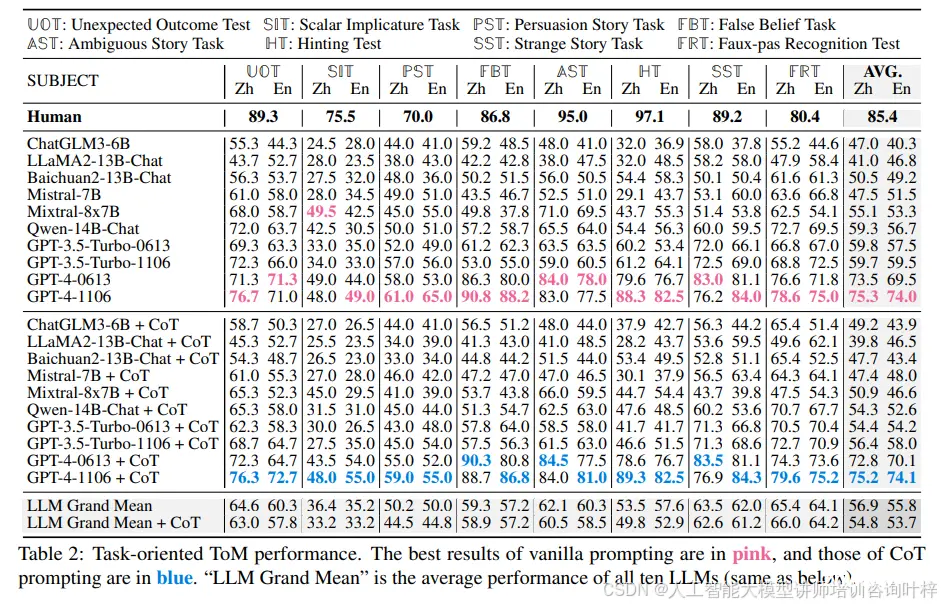
主要结果
人类与LLMs的比较:所有LLMs的平均ToM表现显著低于人类,最小的差距在任务视图中为10.1%(人类85.4%对GPT-4-1106 75.3%),在能力视图中为10.8%(人类86.1%对GPT-4-0613 + CoT 75.3%)。有趣的是,在错误信念任务(FBT)中,像GPT-4-1106这样的LLMs甚至超过了人类,这被认为是可以解释的。现有的ToM库存中有相对丰富的FBT样本,例如Sally-Anne测试和Smarties测试。另外FBT中使用的故事严格遵守模板,这进一步有利于LLMs在现有样本上训练后的泛化。
任务导向的ToM性能,列出了人类与不同LLMs在8个任务上的表现对比
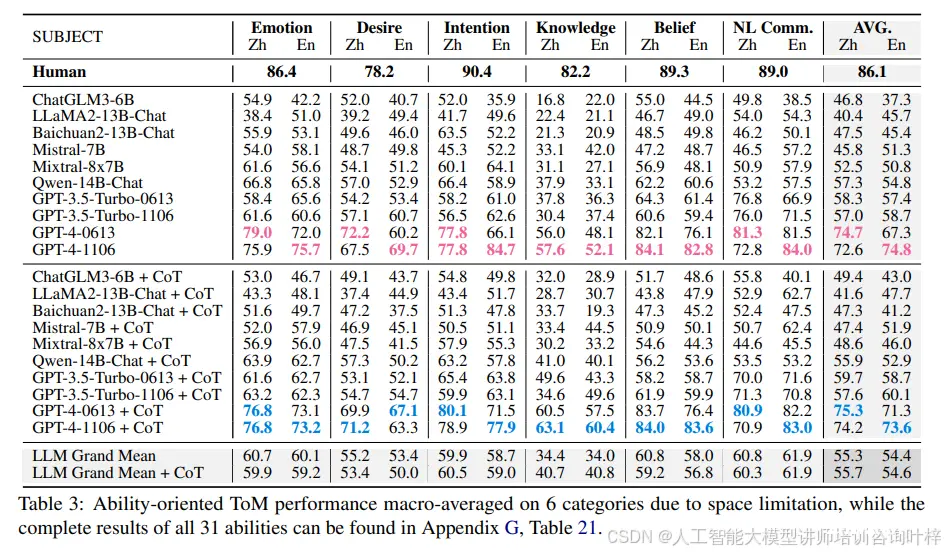
任务和能力的表现差异:在表2中,展示了LLMs在8个任务(UOT、SIT、PST、FBT、AST、HT、SST、FRT)上的表现,并在表3中展示了6个能力类别的表现。表3可以看到,表现最好的能力维度是非字面沟通(与FRT重叠)和情感,这与任务导向的结果一致。表现最弱的类别是知识(与SIT重叠),这并不指LLMs自身的知识,而是测试它们是否理解故事中角色之间的信息传播,这通常是LLMs的弱项。
基于能力的ToM性能宏观平均值
深入分析
更难的连贯性测试:在评估任务导向的ToM表现时,研究者使用所有相关问题的简单平均准确率。然而,对于一个故事,如果参与者要展示完整的理解,他们需要正确回答所有相关问题,而不仅仅是做出有根据的猜测。因此研究者进一步设计了一个更具挑战性的故事级连贯性测试,如果LLM在与该故事相关的任何问题上回答错误,则被认为测试失败。

在连贯性测试下所有LLMs的性能变化。在这个测试中,如果LLM在与某个故事相关的任何问题上回答错误,则认为它未能理解该故事
LLMs在简单ToM问题上的失败:研究者深入探讨了LLMs表现特别差的一个能力——知识/知识-假装链接。这个任务直观而直接,对人类来说(准确率达到93.3%)很简单,但对LLMs来说却很困难。GPT-4-1106和GPT-4-0613在英文样本上的准确率分别只有26.7%和3.3%,这几乎等同于甚至比随机猜测还要差。为了理解这种糟糕表现背后的原因,研究者在图5中可视化了一个开放的LLM,ChatGLM3-6B的决策过程,当它生成了错误的选项A时,研究者平均了20层注意力头的注意力分数,并确定了ChatGLM3-6B在回答问题时关注的前10个关键词。显然,LLMs仍然依赖于语义关联来回答问题,这与之前关于LLMs虚幻ToM的研究一致。

人类与LLM(以ChatGLM3-6B为例)在处理ToM问题时的注意力差异。图中通过颜色强度表示注意力权重,揭示了LLMs依赖于语义关联来回答问题,而不是像人类那样的认知过程
通过这些实验,研究者能够更全面地评估和理解LLMs在社会认知任务中的能力,并为未来的研究提供了有价值的见解和数据。尽管TMBENCH在评估LLMs的ToM能力方面迈出了重要一步,但仍存在一些局限性,如评估协议的广泛性、库存规模、语言覆盖范围以及LLMs的ToM理解和应用差异。未来的研究可以扩大ToM评估的范围,包括更多的任务和能力,以及探索更复杂的人机交互场景。
论文链接:https://arxiv.org/abs/2402.15052
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。