SuperCLUE:中文大模型基准测评2024年上半年报告
CSDN 2024-08-17 10:01:10 阅读 73
SuperCLUE是一个中文通用大模型的综合性评测基准,其前身是CLUE(The Chinese Language Understanding Evaluation),自2019年成立以来,CLUE基准一直致力于提供科学、客观和中立的语言模型评测。SuperCLUE继承并发展了CLUE的测评体系,构建了一个多层次、多维度的综合性测评基准,以适应通用大模型在学术、产业与用户侧的广泛应用。
官方网址:CLUE中文语言理解基准测评
1 国内大模型关键进展及趋势
国内大模型的发展经历三个阶段:

1.1 具体进展
1.2 发展趋势
2 SuperCLUE通用能力测评
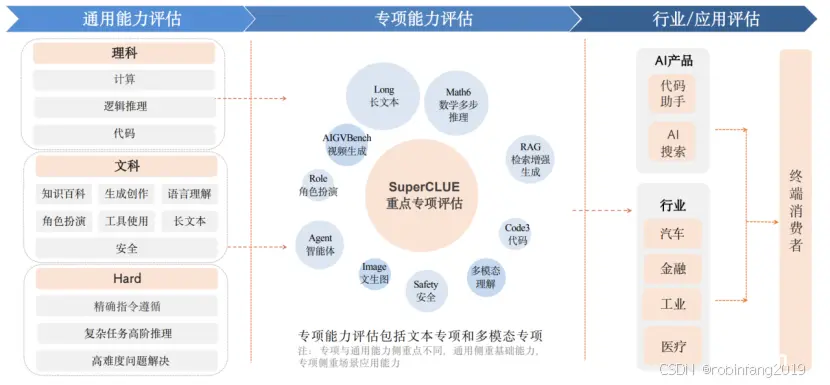
2.1测评维度
2.2 数据集
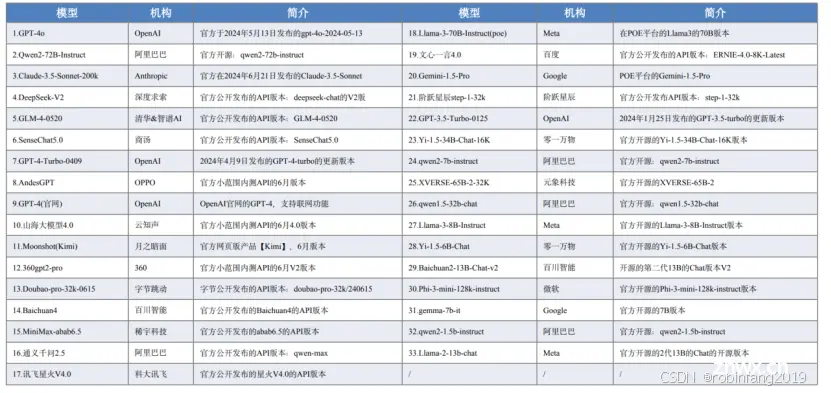
2.3 测评模型
2.4 测评结果
准备期 (2022年12月 - 2023年2月): ChatGPT的发布引发了全球范围内对大模型的关注,国内产学研界迅速形成共识,积极布局大模型技术。成长期 (2023年2月 - 2023年12月): 国内大模型数量和质量开始逐渐增长,多家企业和研究机构发布了各自的大模型产品,例如百度文心一言、清华ChatGLM等。爆发期 (2023年12月至今): 各行各业开源闭源大模型层出不穷,形成“百模大战”的竞争态势,例如阿里云通义千问、华为盘古3.0、字节跳动豆包等。通用大模型: 国内外通用大模型数量持续增长,能力不断提升,例如GPT系列模型、文心一言、通义千问、GLM系列模型等。行业大模型: 各行各业开始探索大模型在特定场景的应用,例如医疗、金融、教育、工业等,例如岐黄问道、MindGPT、蚂蚁金融大模型、轩辕大模型等。开源模型: 开源大模型蓬勃发展,例如阿里云Qwen系列模型、百川智能Baichuan系列模型、零一万物Yi系列模型等。端侧小模型: 端侧小模型进展迅速,例如qwen2系列模型、Yi系列模型等,为在设备端侧本地运行大模型提供了可能性。差距缩小: 国内外大模型差距正在缩小,尤其在中文能力方面,国内模型取得了显著进步。开源崛起: 开源大模型发展迅速,在中文场景下展现出强大的竞争力。端侧发展: 端侧小模型发展潜力巨大,为在设备端侧本地运行大模型提供了可能性。场景应用: 大模型在各个行业的应用场景不断拓展,推动产业升级和数字化转型。通用能力评估: 考察大模型的基础能力,例如语言理解、生成创作、逻辑推理、代码能力等。专项能力评估: 考察大模型在特定场景下的应用能力,例如数学多步推理、检索增强生成、智能体、安全等。行业/应用评估: 考察大模型在特定行业或应用场景下的表现,例如医疗、汽车、金融、工业等。理科任务: 计算题、逻辑推理题、代码题等,考察大模型的数理逻辑能力和编程能力。文科任务: 知识百科题、语言理解题、长文本题、角色扮演题、生成与创作题、安全题、工具使用题等,考察大模型的语言理解能力、知识储备、文本生成能力等。Hard任务: 精确指令遵循题、复杂任务多步推理题、高难度问题解决题等,考察大模型的极限能力。
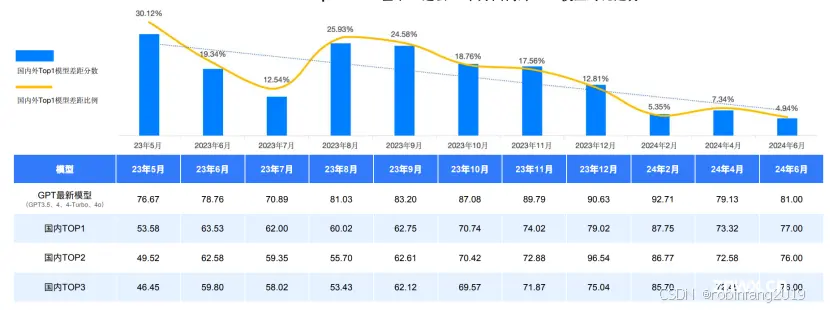
2.4.1 国内外差距缩小

国内外第一梯队大模型在中文领域的通用能力差距持续缩小,从 2023 年 5 月的 30.12% 缩小至 2024 年 6 月的 4.94%。GPT-4o 依然领跑 SuperCLUE 基准测试,是唯一超过 80 分的大模型,展现出强大的语言、数理和指令遵循能力。国内大模型上半年发展迅速,例如 Qwen2-72B、AndesGPT、山海大模型 4.0 等模型,在多个维度上表现出色。
2.4.2 开源崛起
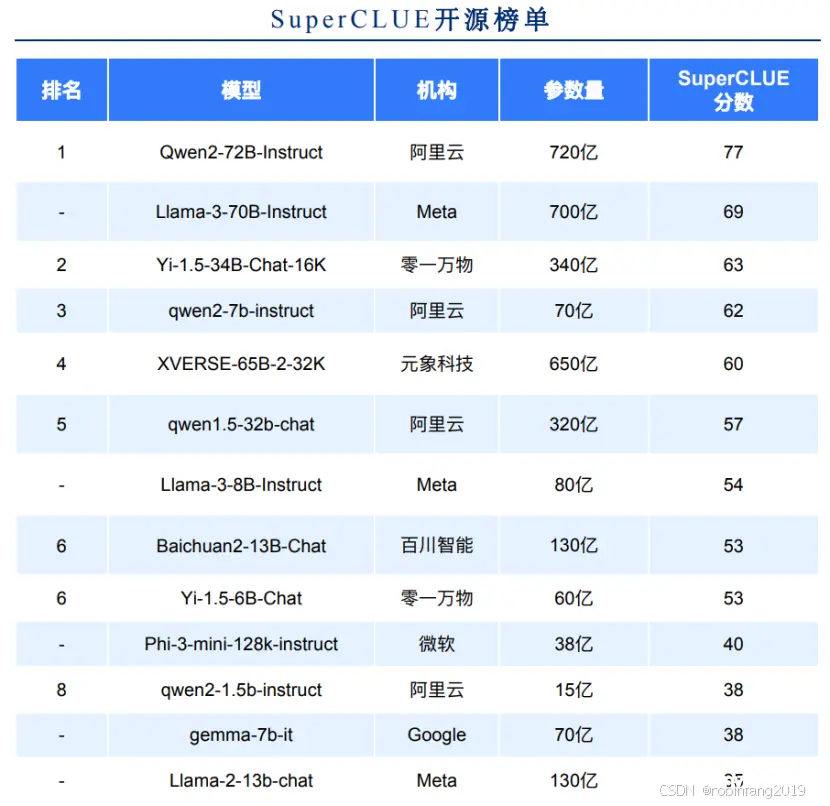
开源模型 Qwen2-72B 在 SuperCLUE 基准中表现非常出色,超过众多国内外闭源模型,与 Claude-3.5 持平,与 GPT-4o 仅差 4 分。零一万物推出的 Yi-1.5-34B 在开源领域表现不俗,有超过 60 分的表现,较为接近部分闭源模型。
3 SuperCLUE专项与行业基准测评
3.1 专项基准测评
SuperCLUE 推出了多个专项基准测评,详情如下:
SuperCLUE-Math6: 中文数学多步推理测评基准,旨在评估和提升中文大模型在数学推理方面的核心能力。SuperCLUE-Code3: 中文原生等级化代码能力测评基准,通过功能性单元测试,评估和提升中文大模型在代码生成方面的核心能力。SuperCLUE-Agent: 中文智能体测评基准,评估大语言模型在核心 Agent 能力上的表现,包括工具使用、任务规划和长短期记忆能力。SuperCLUE-Safety: 中文大模型多轮对抗安全基准,检验模型在遵守基本道德法律标准、与人类价值观的对齐,以及抵御潜在攻击等方面的能力。SuperCLUE-RAG: 中文原生检索增强生成测评基准,全方位、多角度地对 RAG 技术水平进行测评。SuperCLUE-200K: 中文超长文本测评基准,考察大模型在超长文本中的处理能力。SuperCLUE-Role: 中文角色扮演测评基准,评估和提升中文大模型在角色扮演方面的心智模拟、场景应用和人际交往等能力。
3.2 行业基准测评
SuperCLUE 还推出了多个行业基准测评,详情如下:
SuperCLUE-Auto: 汽车行业中文大模型测评基准,评估大模型在汽车场景下的各项能力,例如车辆使用指南、智能座舱与交互等。SuperCLUE-Industry: 工业行业中文大模型测评基准,评估大模型在工业场景下的各项能力,例如设备维护、生产计划等。SuperCLUE-Fin: 金融行业中文大模型测评基准,评估大模型在金融场景下的各项能力,例如风险控制、投资决策等。SuperCLUE-ICabin: 汽车智能座舱大模型测评基准,评估大模型在汽车智能座舱场景下的各项能力,例如语音交互、图像感知等。
如要进一步了解测评细节可以下载PDF文件,下载地址如下:
https://download.csdn.net/download/robinfang2019/89534923
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。