阿里通义千问大模型Qwen2-72B-Instruct通用能力登顶国内第一!
KuaFuAI 2024-08-19 15:01:04 阅读 91
前言:
中国互联网协会副秘书长裴玮近日在2024中国互联网大会上发布《中国互联网发展报告(2024)》。《报告》指出,
在人工智能领域,2023年我国人工智能产业应用进程持续推进,核心产业规模达到5784亿元。
截至2024年3月,我国人工智能企业数量超过4500家,
已有714个大模型完成生成式人工智能服务备案。
中国人工智能领域的论文产出数量位列全球第二,专利申请量超129万件,占比高达64%
今天就来看看国内大模型的翘楚
阿里通义千问大模型Qwen2-72B-Instruct
通用能力登顶国内第一!
全球开源大模型No.1


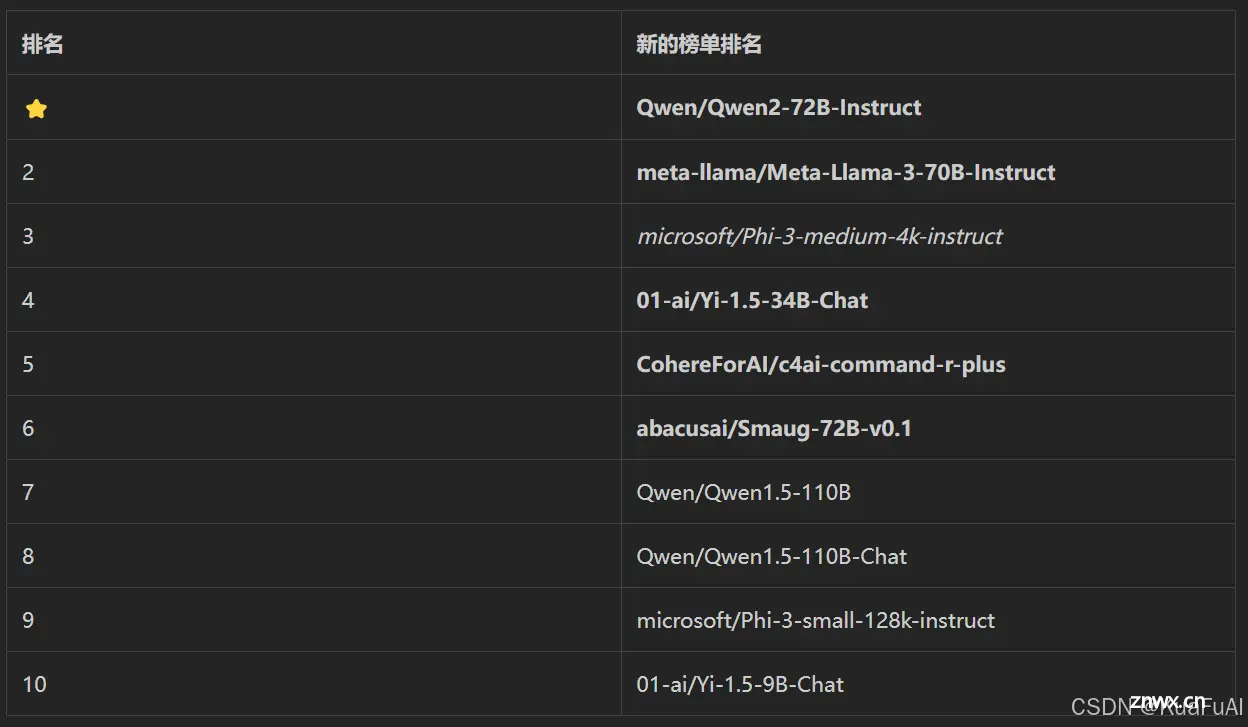
在Hugging Face 发布的开源大模型排行中阿里云开源的通义千问(Qwen)指令微调模型 Qwen2-72B 在开源模型排行榜上荣登榜首。其联合创始人兼首席执行 Clem Delangue,也在X上对中国开源大模型表示了肯定。
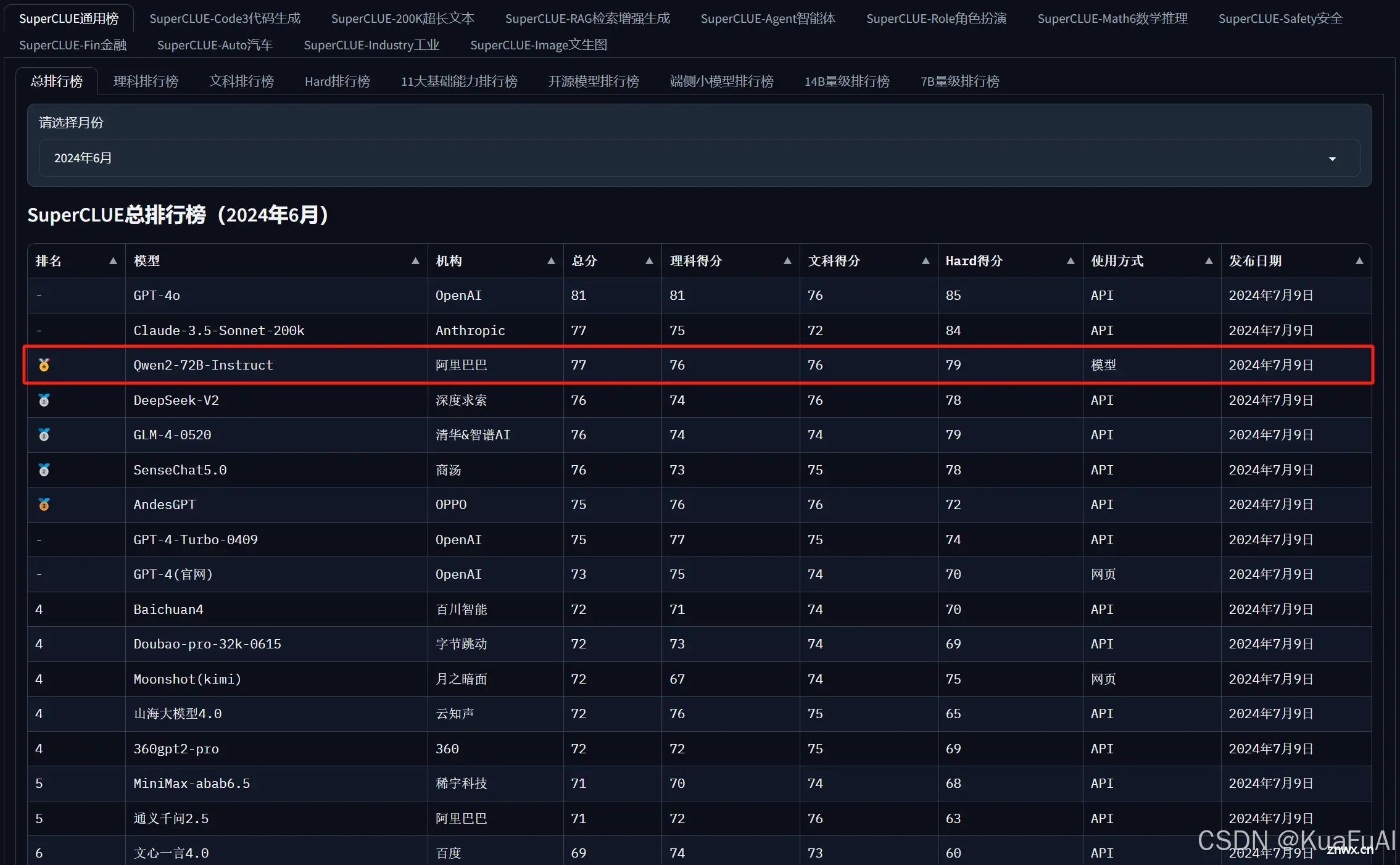
我们再来看一组国内的基准测评数据。
在中文大模型测评基准 SuperCLUE 的总榜单中,阿里通义千问的开源模型成为排名第一的中国大模型,也是全球最强的开源模型。
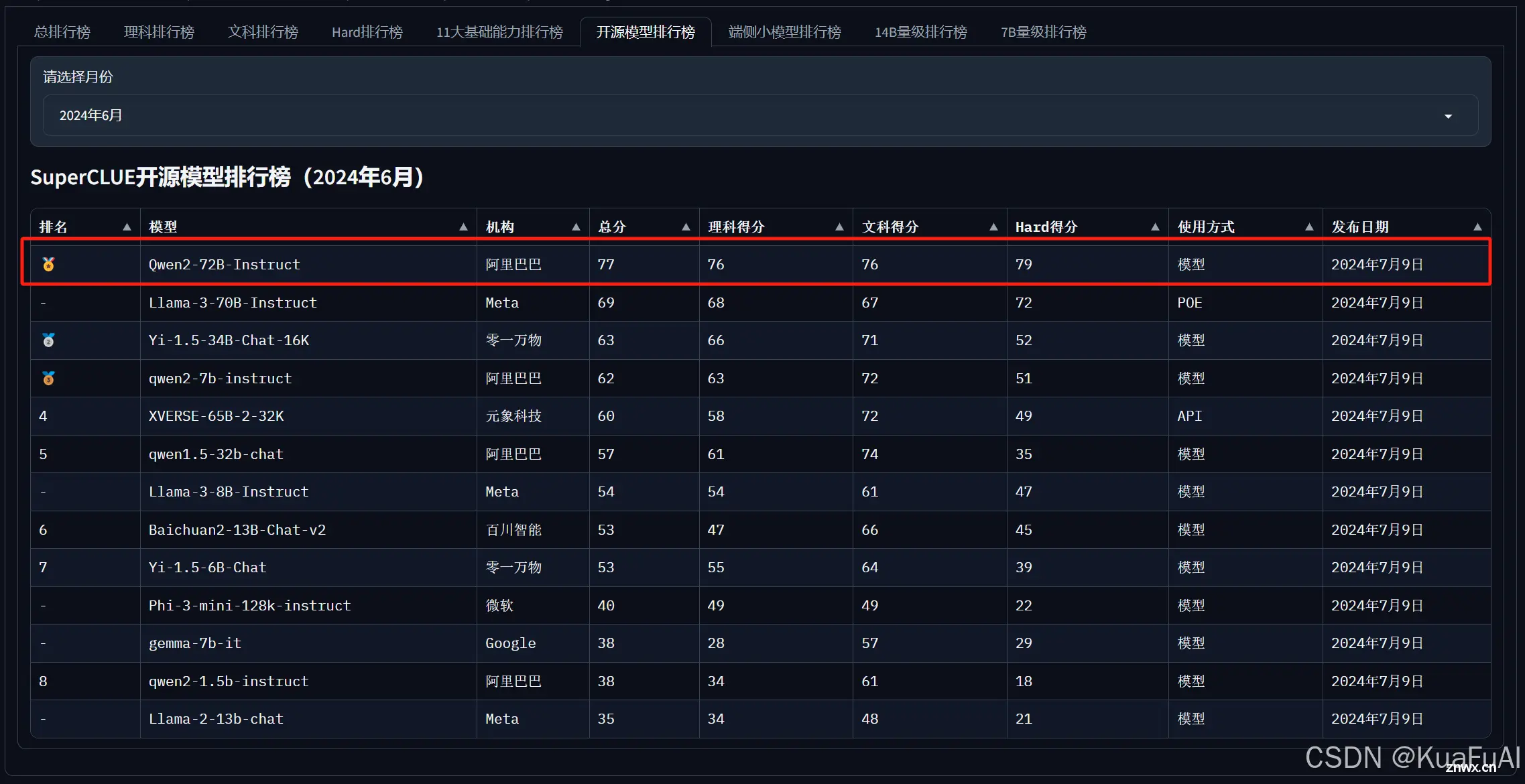
在开源排行榜单中 Qwen2-72B毫无疑问直接干到了第一名的位置。
Qwen2系列包含5个尺寸的预训练和指令微调模型。Qwen2-7B-Instruct和Qwen2-72B-Instruct均实现了长达128K tokens上下文长度的支持。

另外在针对大模型泛化性的问题上,Qwen2特别针对除了中英文之外的27种语言进行了增强,显著提升了Qwen2在多语言上的能力。
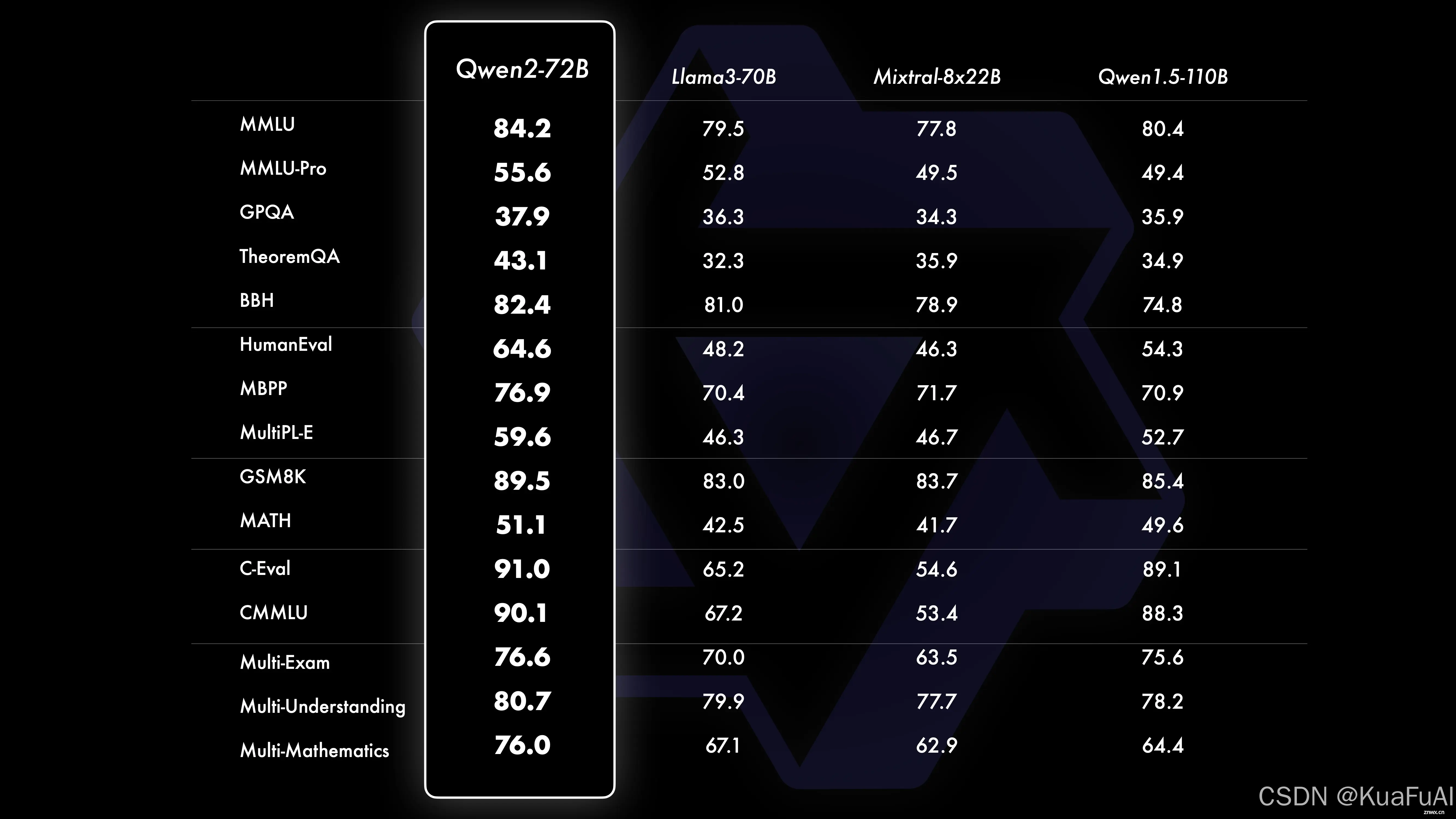
这是官方发布的Qwen2-72B和其它两个同量级开源大模型以及自身前代版本的测试。
从结果上来看,我们能清晰的看到Qwen2-72B在自然语言理解、知识、代码、数学及多语言等多项能力上均显著超越当前领先的模型。
Qwen2-72B-Instruc(指令微调),可以理解为Qwen2-72B 的一个特化版本,它在指令遵循、代码理解、数学解题以及多语言处理方面进行了优化和提升。
所以,我们再来看一下优化后的版本对比
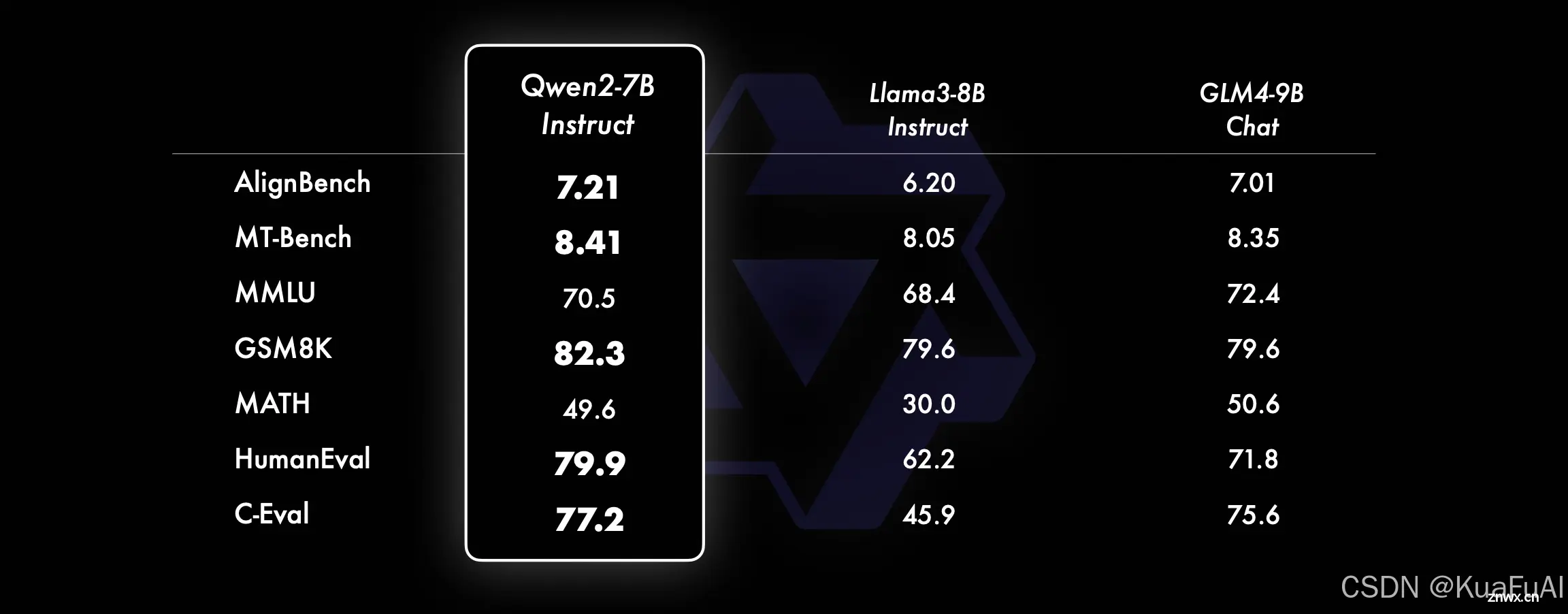
看这数据,依旧超过同等开源大模型甚至比更大规模的模型还要强,直接就是一个降维打击。
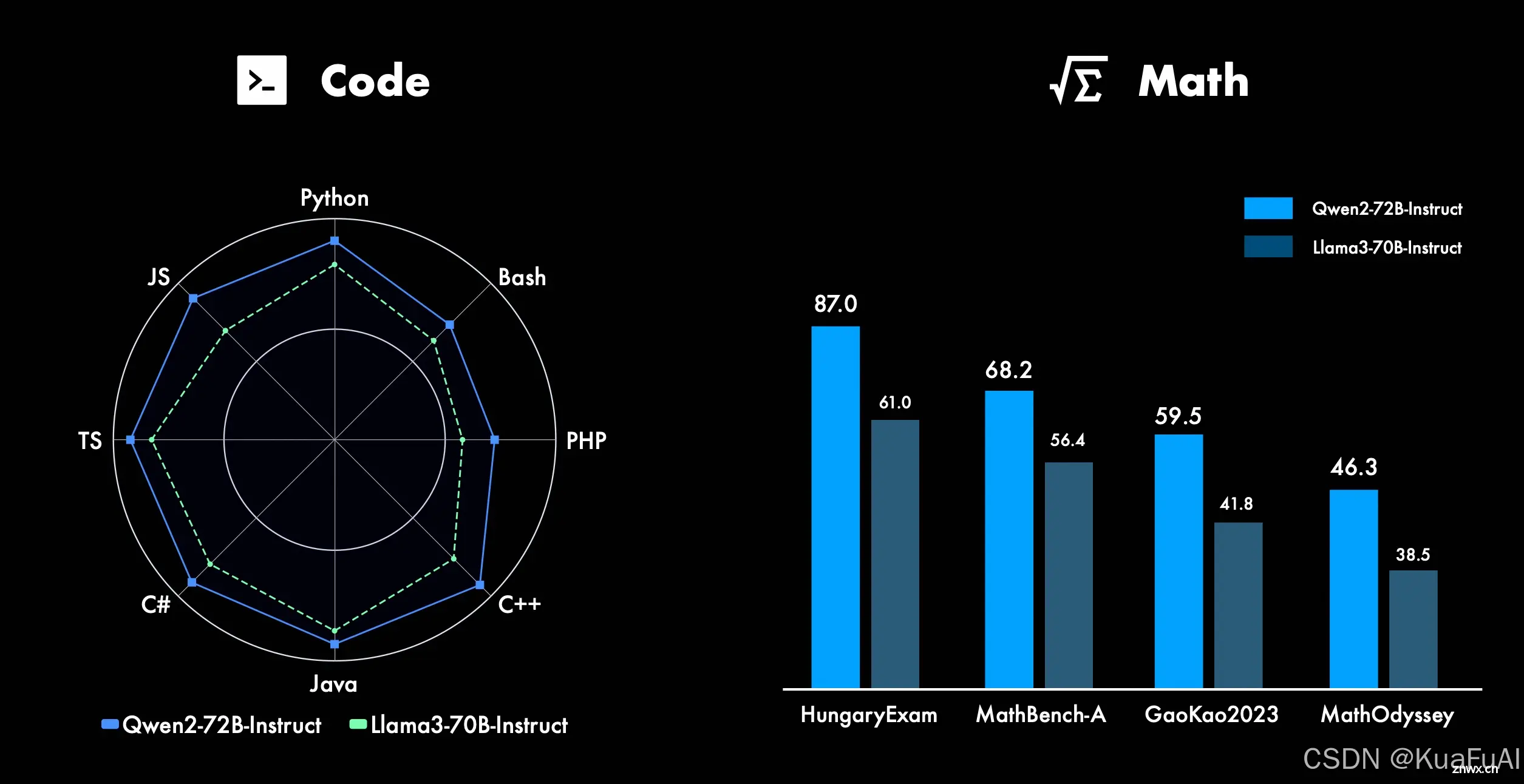
需要特别指出的是Qwen2-72B尤其在代码和数学能力上得到了显著的提升。在python、js、java、c++等编程语言上去全面优于之前号称地标最强的Llama3-70B 。数学能力就不多说了,同样是吊打。
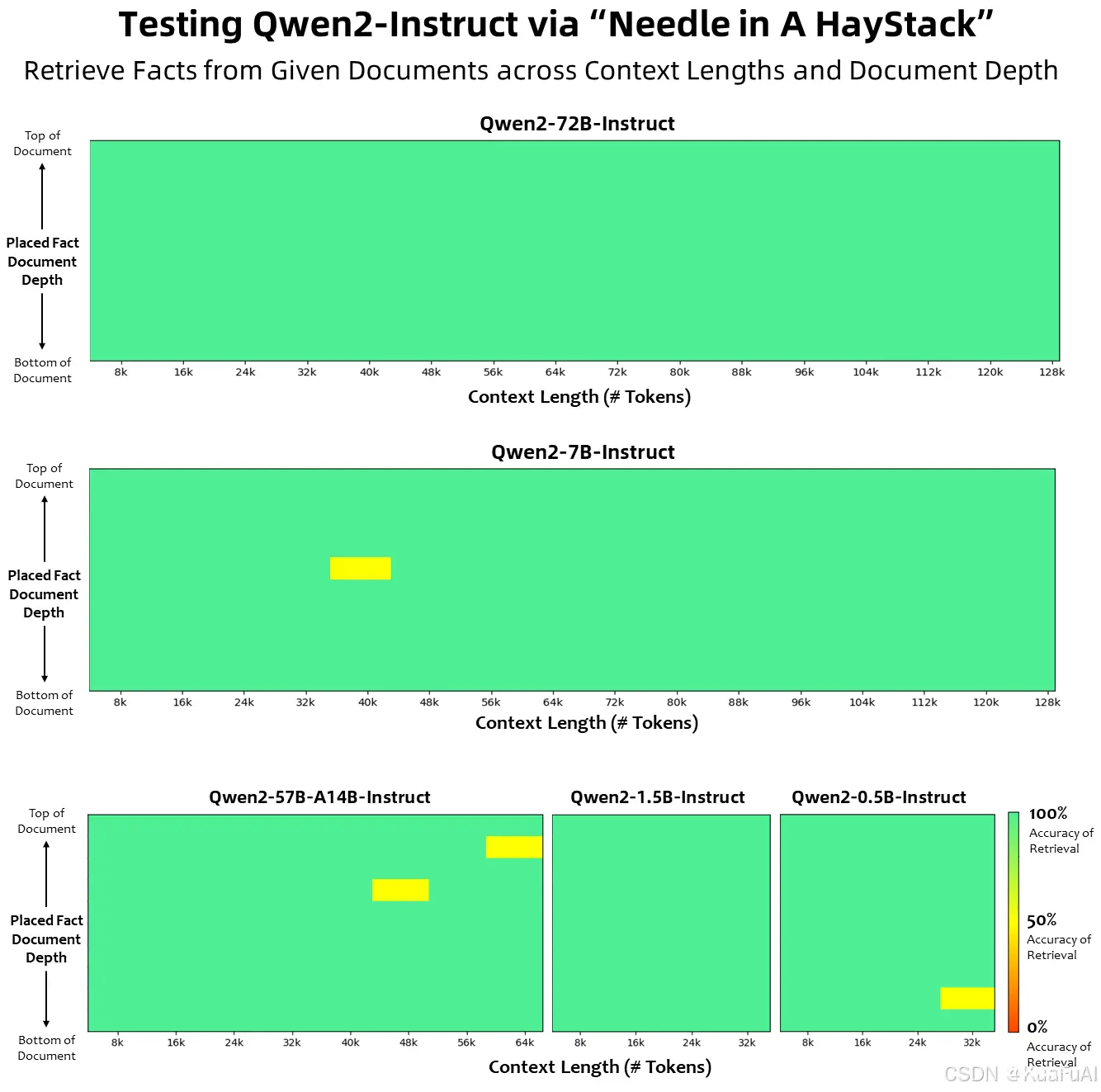
再来看看大海捞针的测试。
有的小伙伴可能不太了解什么是大海捞针:"大海捞针"测试是指在大量数据中寻找特定的信息或模式。在大模型领域,"大海捞针"测试通常是一个比喻,用来形象地描述在海量数据中找到特定信息点的难度和复杂性。这种测试可以用于评估大型语言模型(LLMs)在处理和检索大量文本数据时的性能。
从图中我们不难看出,Qwen2-72B-Instruct模型在所有测试的上下文长度中,无论是事实检索还是文档深度检索,都展现出了较高的准确性,特别是在较短的上下文长度下。
Qwen2-72B-Instruct能够完美处理128k上下文长度内的信息抽取任务。
当然其他几个模型的也不差:Qwen2-57B-A14B-Instruct能处理64k的上下文长度;而该系列中的两个较小模型则支持32k的上下文长度。
今天的分享到这里就结束啦~
Qwen2-72B-Instruct的发布,是中国大模型语言首次登顶全球no1(尽管是开源)。这款由阿里巴巴推出的模型,在多项性能指标上超越了当前领先的开源模型,尤其在代码理解、数学解题和多语言处理方面表现出色。
目前Qwen2已经在Hugging Face和ModelScope上开源,有感兴趣的小伙伴们可以去试一下~
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。