20240729 每日AI必读资讯
程序员的店小二 2024-08-17 10:01:02 阅读 76

Meta科学家最新采访,揭秘Llama 3.1是如何炼成的
- Llama 3.1都使用了哪些数据?其中有多少合成数据?为什么不使用MoE架构?后训练与RLHF流程是如何进行的?模型评估是如何进行的?
- 受访者Thomas Scialom现任Meta的人工智能研究科学家,领导了Llama 2和Llama 3的后训练,并参加了CodeLlama、Toolformer、Bloom、GAIA等多个项目。
- 关于Llama 3.1研发思路
如何决定参数规模
重新审视Scaling Law
模型架构 关于合成数据
LLM的评估与改进
🔗 Llama 4训练已开启!Meta科学家最新采访,揭秘Llama 3.1是如何炼成的-CSDN博客


阿里大模型元老杨红霞去向官宣:入职香港高校!被曝创业项目也在推进
- 杨红霞是AI领域知名科学家。曾在IBM T.J.沃森研究中心担任研究人员,并在雅虎担任首席科学家。2016年加入阿里巴巴,就职于达摩院智能计算实验室;2023年3月入职字节跳动。
- 在达摩院期间领导了通义千问前身M6大模型的研发,是M6大模型从百亿、千亿参数量进化到万亿规模的主要功臣,并领导通义大模型核心技术“统一学习范式OFA-M6”的开发。
- 杨红霞的下一站被猜测是“端侧模型创业”,布局AI Agent。
🔗https://blog.csdn.net/techforward/article/details/140751269


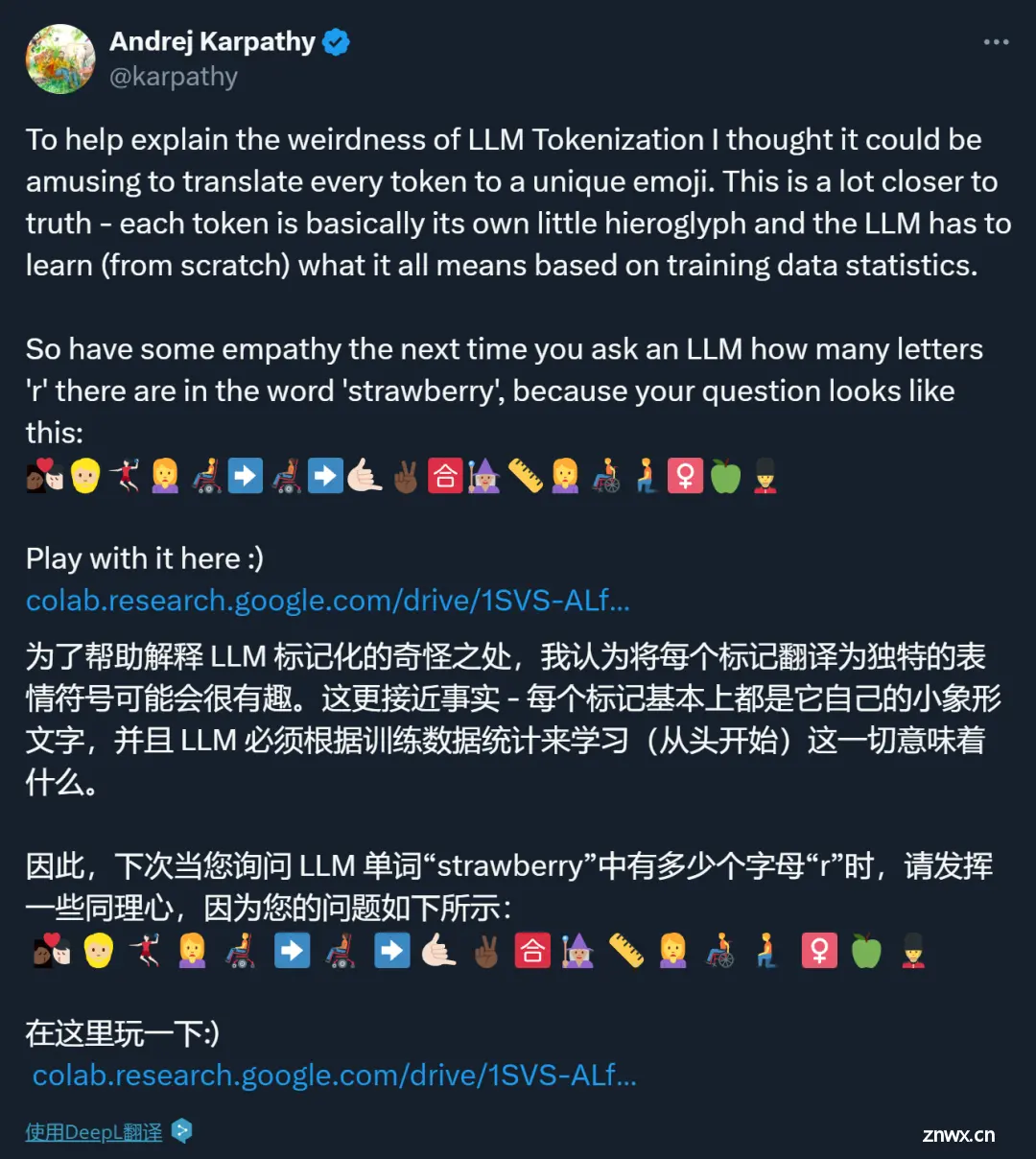
AI数不清Strawberry里有几个r?Karpathy:我用表情包给你解释一下
- AI大模型低级错误背后的本质是什么?普遍认为,是 Token 化(Tokenization)的锅。
- Karpathy 认为,AI参差不齐的智能表现和人类是不一样的。
- 核心在于目前的大模型缺乏「认知自我知识(cognitive self-knowledge)」( 模型自身对其知识和能力的自我认知 )
- 应该致力于让模型只完成他们擅长的任务,不擅长的任务由人类及时接手。
🔗 为什么AI数不清Strawberry里有几个 r?Karpathy:我用表情包给你解释一下-CSDN博客
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。