20240927 每日AI必读资讯
程序员的店小二 2024-10-18 11:31:01 阅读 63

猛了!Meta震撼发布 Llama 3.2 视觉方面吊打所有闭源模型?
- 性能与GPT4o-mini 相当 能够在边缘设备上高效运行
- Llama 3.2包括适用于边缘和移动设备的小型和中型视觉大语言模型(11B 和 90B)以及轻量文本模型(1B 和 3B)。
- LLaMA 3.2支持同时处理文本、图像和视频,能够理解并生成跨媒体内容。 例如,用户可以在同一交互中结合文字和图像。
- 评估表明,Llama 3.2 的视觉模型在图像识别和一系列视觉理解任务中与领先的基础模型 Claude 3 Haiku 和 GPT4o-mini 竞争。
- 3B 模型在遵循指令、总结、提示重写和工具使用等任务上超越了 Gemma 2 2.6B 和 Phi 3.5-mini 模型,而 1B 模型与 Gemma 竞争力相当。
- 可以轻松在手机上运行并执行任务
🔗详细内容:https://xiaohu.ai/p/14128

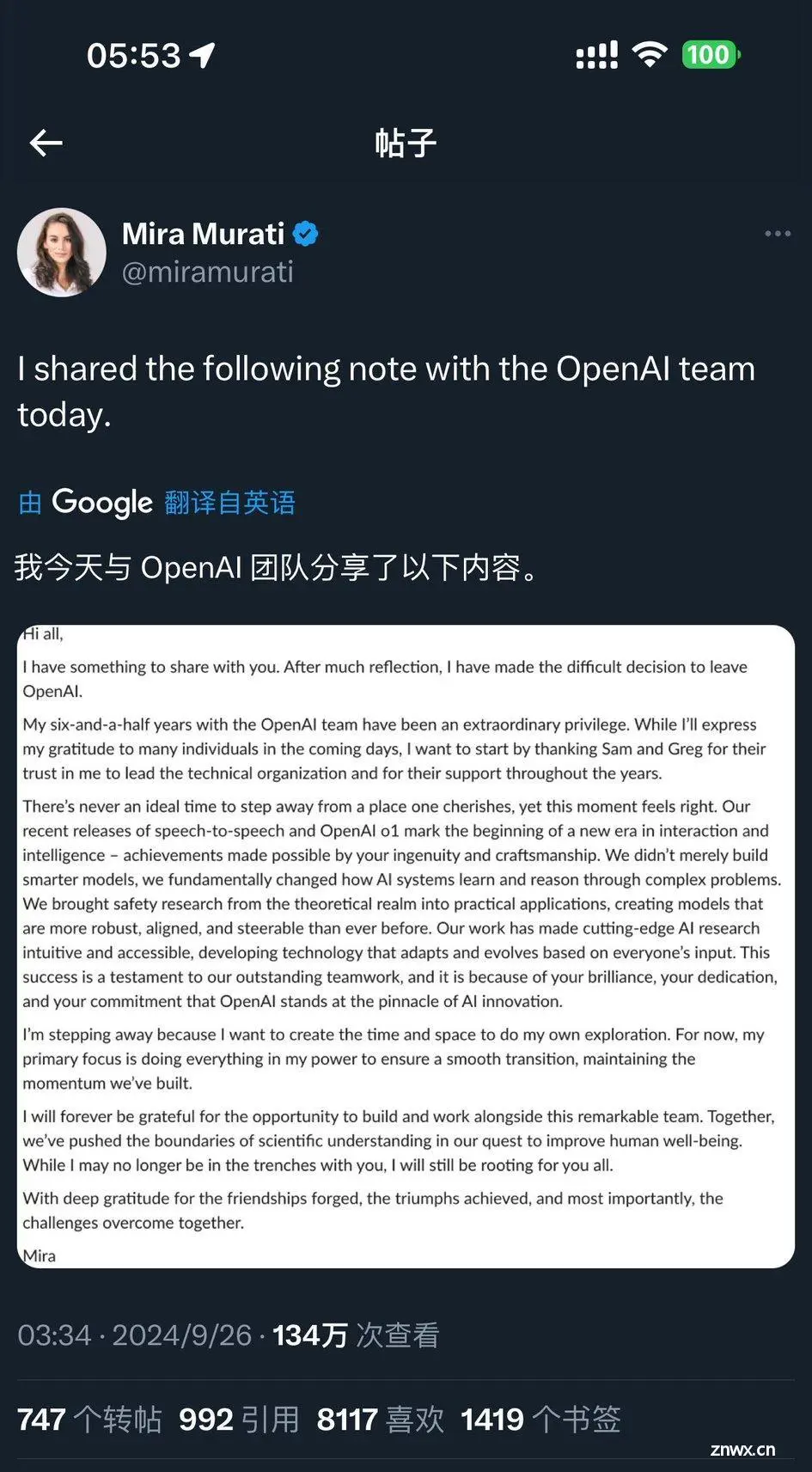
炸了!OpenAI人事大震荡,CTO、首席研究官纷纷宣布离职!
- Mira Murati离职,标志着OpenAI高层人事大变动。
- Mark Chen晋升为新任高级副总裁,负责研究部门领导。
- 首席研究官Bob McGrew和研究副总裁Barret Zoph也宣布离职。
大家好,
我想与你们分享一些事情。经过深思熟虑,我做出了艰难的决定,离开OpenAI。
我在OpenAI团队的六年半时间是一种非凡的荣幸。在接下来的几天里,我会向许多人表达我的感激之情,但我想首先感谢Sam和Greg对我的信任,让我领导技术组织,并感谢他们多年来的支持。
离开一个自己珍视的地方从来没有理想的时机,但现在这个时刻感觉是对的。我们最近发布的语音到语音转换和OpenAI O1标志着交互和智能的新时代的开始——这些成就是由你们的聪明才智和手艺实现的。我们不仅仅构建了更智能的模型,我们从根本上改变了AI系统学习和推理复杂问题的方式。我们将安全研究从理论领域带入实际应用,创建了比以往任何时候都更加健壮、一致和可控的模型。
我们的工作使尖端AI研究变得直观且易于访问,开发了可以根据每个人的输入进行调整和进化的技术。这一成功证明了我们出色的团队合作,正是因为你们的智慧、奉献和承诺,OpenAI才站在AI创新的顶峰。
我之所以离开,是因为我想创造时间和空间来进行自己的探索。目前,我的首要任务是尽我所能确保平稳过渡,保持我们建立的势头。
我将永远感激有机会与这个卓越的团队一起建设和工作。在一起,我们推动了科学理解的边界,以改善人类的福祉。虽然我可能不再与你们并肩作战,但我仍然会为你们所有人加油。
对于建立的友谊、取得的胜利,以及最重要的,一起克服的挑战,我深表感激。
Mira

全新Notion AI发布!一站式 集成搜索、生成内容、分析数据等功能
- 所有操作都可以在 Notion 内部完成,不需要跳转到其他工具。
- 可以随时使用在 Notion 页面右下角找到 AI 图标,点击即可开始使用。
- 还可以使用快捷键(Mac: Shift + Cmd + J,Windows: Shift + Ctrl + J)快速打开 Notion AI。
- 智能助手:Notion AI 可以快速回答问题,提供有针对性的建议。它不仅可以帮你找到信息,还能生成任务计划、草拟邮件,自动化完成简单任务,节省你的时间。
- 跨平台搜索:通过连接 Slack、Google Drive 等应用,Notion AI 能从多个平台汇总信息,帮助你快速找到需要的答案,不用手动切换应用查找数据。
- 强大的写作能力:Notion AI 可以帮你起草文档、创建大纲,并根据需要进行修改。你只需提供基本内容或要求,AI 会帮你完善格式和结构,让写作更简单。
- 文件与图片分析:它可以分析 PDF 文档或图片,提取关键信息,并为你提供有价值的建议和总结,帮助你更快理解复杂内容。
🔗详细的操作指南:https://xiaohu.ai/p/14060


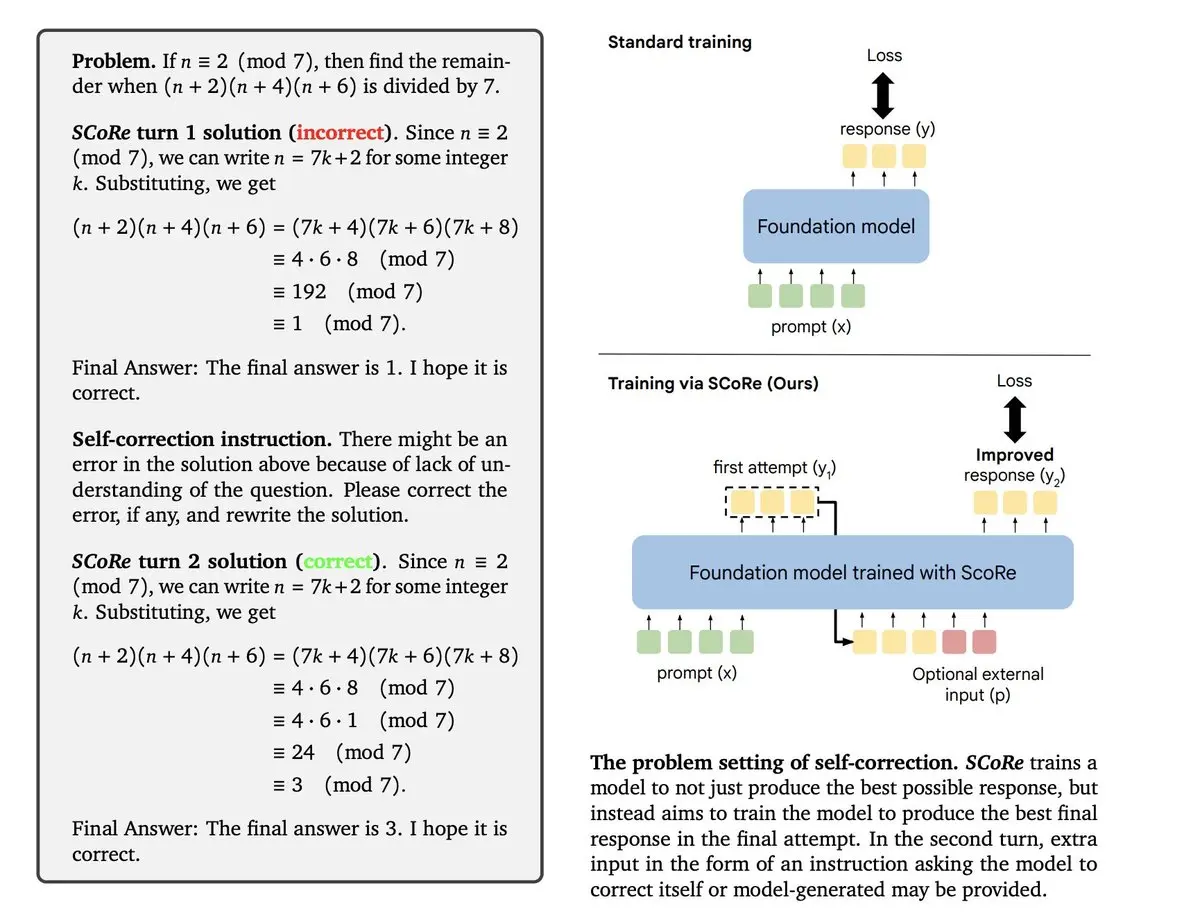
Google DeepMind 提出一种通过强化学习实现自我纠正(SCoRe)的训练方法
- SCoRe通过自生成数据来训练模型进行多轮自我纠正的强化学习方法。
- 该方法通过两阶段的强化学习过程训练LLMs,使它们能够在没有外部输入或监督的情况下,检测并修正自己的错误。
- 第一阶段:训练AI学会发现错误
在这个阶段,SCoRe 先训练AI模型生成初始答案,并为它提供学习机会,让它能知道什么时候需要纠正自己的答案。这个阶段的重点是让AI明白哪些地方出错了,并且不会只做一些很小的、无关紧要的修改,而是能够真正找到并改正大的错误。
- 第二阶段:强化学习,让AI学会纠正自己
在第二阶段,SCoRe 通过一种叫“强化学习”的方法继续训练AI。在这个过程中,AI会通过多次尝试得到反馈。SCoRe 会给AI设置“奖励”,当AI成功改正错误时,AI会得到正面的奖励;如果它把正确答案改成了错误答案,则会受到惩罚。这个机制鼓励AI不断改进自己的答案,而不是仅仅重复第一次的错误。
- 举个例子
假设AI在解决一个数学问题时第一次出错了,但它有解决问题的所有知识。SCoRe会引导AI回头检查自己的回答,找出错误,并在第二次尝试时修正。每次尝试后,AI会获得反馈(奖励或惩罚),通过这样的多轮练习,AI逐渐学会如何自己找到并修正错误。


Reecho睿声公司针对“三只羊录音门”发布声明!
- 三只羊录音门嫌疑人使用其公司产品,利用AI克隆伪造卢某声音进行造谣,并晒出了警方的证据调取通知书
- 睿声公司称犯罪嫌疑人通过此前卢某直播片段约30秒录音进行克隆,并通过文本生成。

声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。