【Datawhale AI 夏令营】第四期 浪潮源模型部署测试+解析
如果皮卡会coding 2024-08-19 08:31:01 阅读 85
定位:Datawhale AI 夏令营 第四期 Task1 笔记
内容:小结实践顺序 + 记录过程疑惑点
1. 实践顺序小结
我们先简单梳理一下整个baseline的流程,后面再进行详细的说明。
开通阿里云PAI-DSW试用魔搭社区授权使用克隆仓库+配环境
<code>git lfs install
git clone https://www.modelscope.cn/datasets/Datawhale/AICamp_yuan_baseline.git
pip install streamlit==1.24.0
运行代码
streamlit run AICamp_yuan_baseline/Task\ 1:零基础玩转源大模型/web_demo_2b.py --server.address 127.0.0.1 --server.port 6006
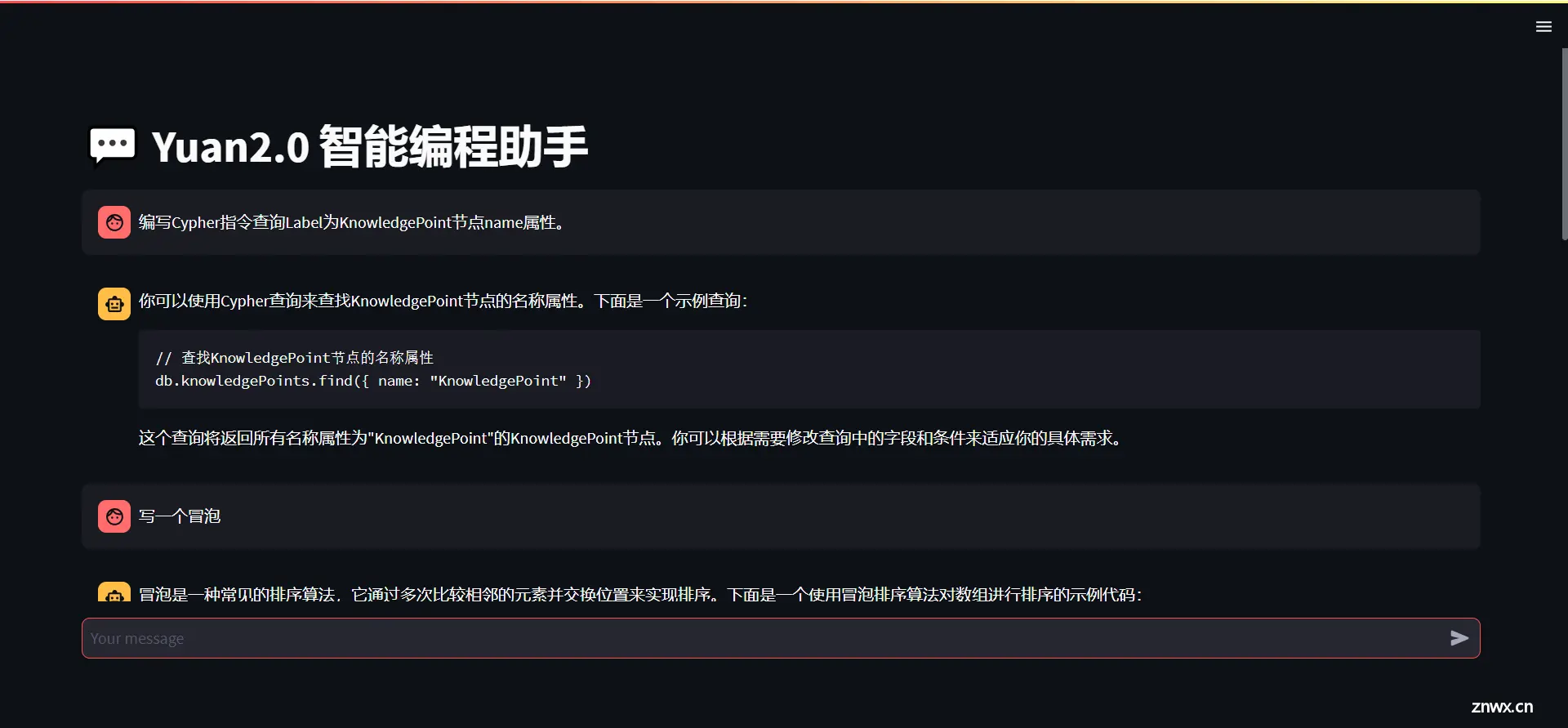
开始对话
实测其实可以发现,一般常见简单的问题可以回答(冒泡排序…),但是小众或者多问几次问题就容易翻车。
2. 问题解析
这里就来讲讲我遇到的那些困惑点吧。(纯属个人推测。)
1. 第一步 要开通试用的 PAI-DSW 是什么意思?
个人比较好奇这些字母是什么的缩写。
PAI是指阿里云人工智能平台PAI(Platform of ArtificialIntelligence),面向企业客户及开发者,提供轻量化、高性价比的云原生机器学习平台,涵盖 PAI-DSW 交互式建模、PAI-Designer 拖拽式可视化建模、PAI-DLC 分布式训练到 PAI-EAS 模型在线部署的全流程。
DSW(Data Science Workshop)是为算法开发者量身打造的一站式AI开发平台,集成了JupyterLab、WebIDE、Terminal多种云端开发环境,提供代码编写、调试及运行的沉浸式体验。
(再说下去就像广告了…)
片面总结:一个可以用于搞机器学习的notebook云环境。
2. 第三步 为什么代码仓库是以魔搭社区的数据集形式发布的?
地址:https://www.modelscope.cn/datasets/Datawhale/AICamp_yuan_baseline
Maybe: 在第二步骤中,我们创建的交互环境本身是魔搭社区授权的notebook实例,相比连接社区的速率和稳定性应该算是比较有保障的。
没准以后要推代码除了github、gitee、还能以数据集的形式存在这里。🤣
3. 如何调用浪潮源大模型
<code># 源大模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('IEITYuan/Yuan2-2B-Mars-hf', cache_dir='./')code>
通过代码可知,我们下载的是魔搭社区的IEITYuan/Yuan2-2B-Mars-hf页面
该页面也给出了模型的调用方式。
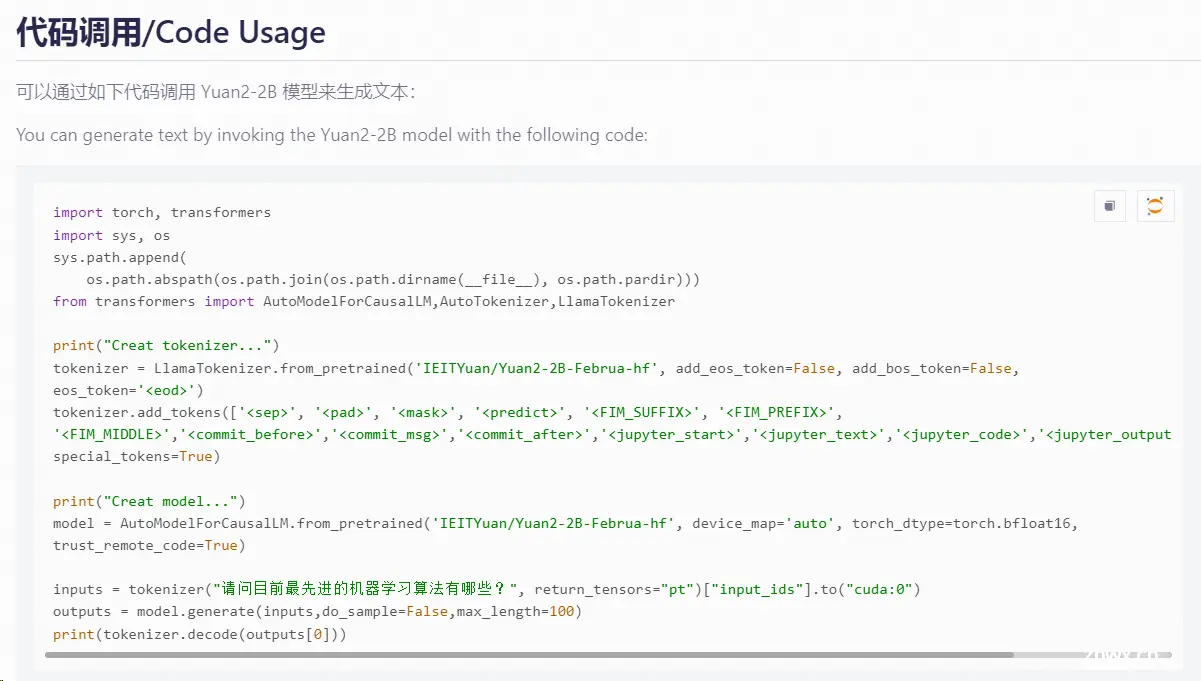
通过阅读baseline代码可知,我们将其封装为了一个返回tokenizer和model的函数。
// ...
# 定义一个函数,用于获取模型和tokenizer
@st.cache_resource
def get_model():
print("Creat tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(path, add_eos_token=False, add_bos_token=False, eos_token='<eod>')code>
tokenizer.add_tokens(['<sep>', '<pad>', '<mask>', '<predict>', '<FIM_SUFFIX>', '<FIM_PREFIX>', '<FIM_MIDDLE>','<commit_before>','<commit_msg>','<commit_after>','<jupyter_start>','<jupyter_text>','<jupyter_code>','<jupyter_output>','<empty_output>'], special_tokens=True)
print("Creat model...")
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch_dtype, trust_remote_code=True).cuda()
print("Done.")
return tokenizer, model
# 加载model和tokenizer
tokenizer, model = get_model()
4. 这里的@st.cache_resource是什么意思?
参阅streamlit关于这个api的文档:st.cache_resource docs
关键点:
这里的@表示 Decorator 装饰器,用于缓存返回全局资源(例如数据库连接、ML 模型)的函数。
缓存对象在所有用户、会话和重试之间共享。它们必须是线程安全的,因为它们可以从多个线程同时访问。如果线程不安全,就用st.session_state 来存储每个会话的资源。
可以使用func.clear()清除函数的缓存 ps: 这里的func是函数的名字
也可以使用st.cache_resource.clear()清除整个缓存。
要缓存数据,就改用st.cache_data。
示例如下:
import streamlit as st
@st.cache_resource
def get_database_session(url):
# Create a database session object that points to the URL.
return session
s1 = get_database_session(SESSION_URL_1)
# 实际执行了该函数,因为是第一次执行
s2 = get_database_session(SESSION_URL_1)
# 未执行该函数。而是返回其先前计算的值。
# 这意味着现在 s1 中的连接对象与 s2 中的相同。
s3 = get_database_session(SESSION_URL_2)
# 参数不同,所以还是执行了这个函数
不过封装的get_model本身就没参数,所以哪怕后续重复打开页面,也相当于只执行一次,加载同一个模型。
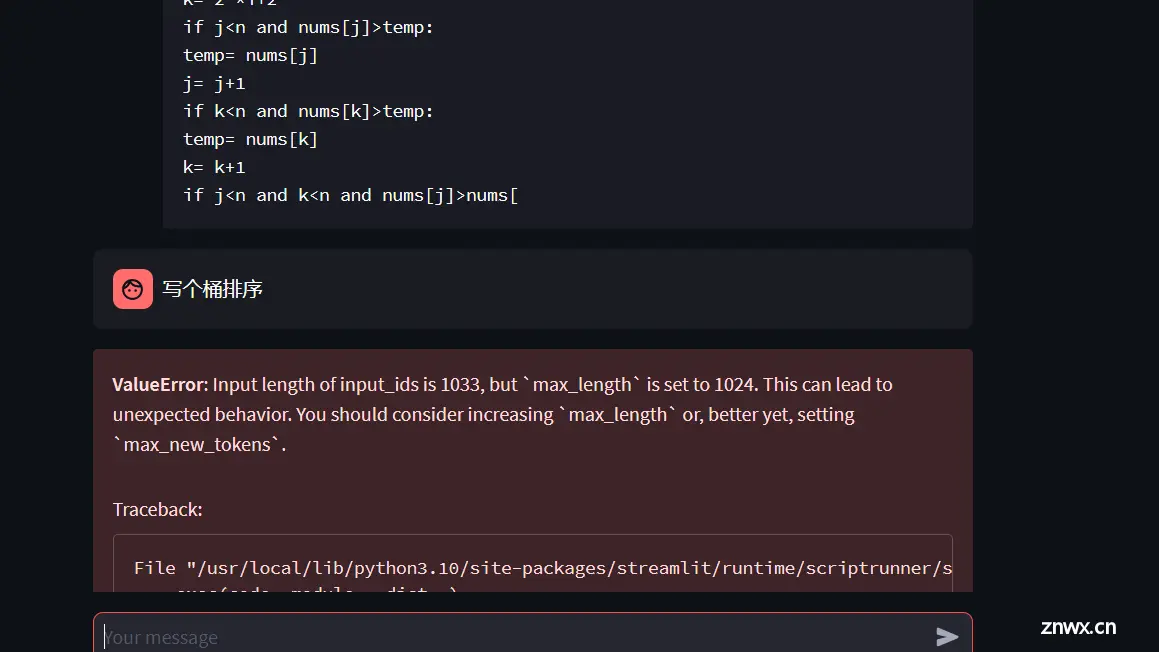
5. 为什么对话三四轮之后会报错。(详见上述截图示例。)
初看报错不难猜测是输入过长,对于baseline最后的主干部分(也就是输入问题后的显示逻辑),我们额外显示输入的长度。
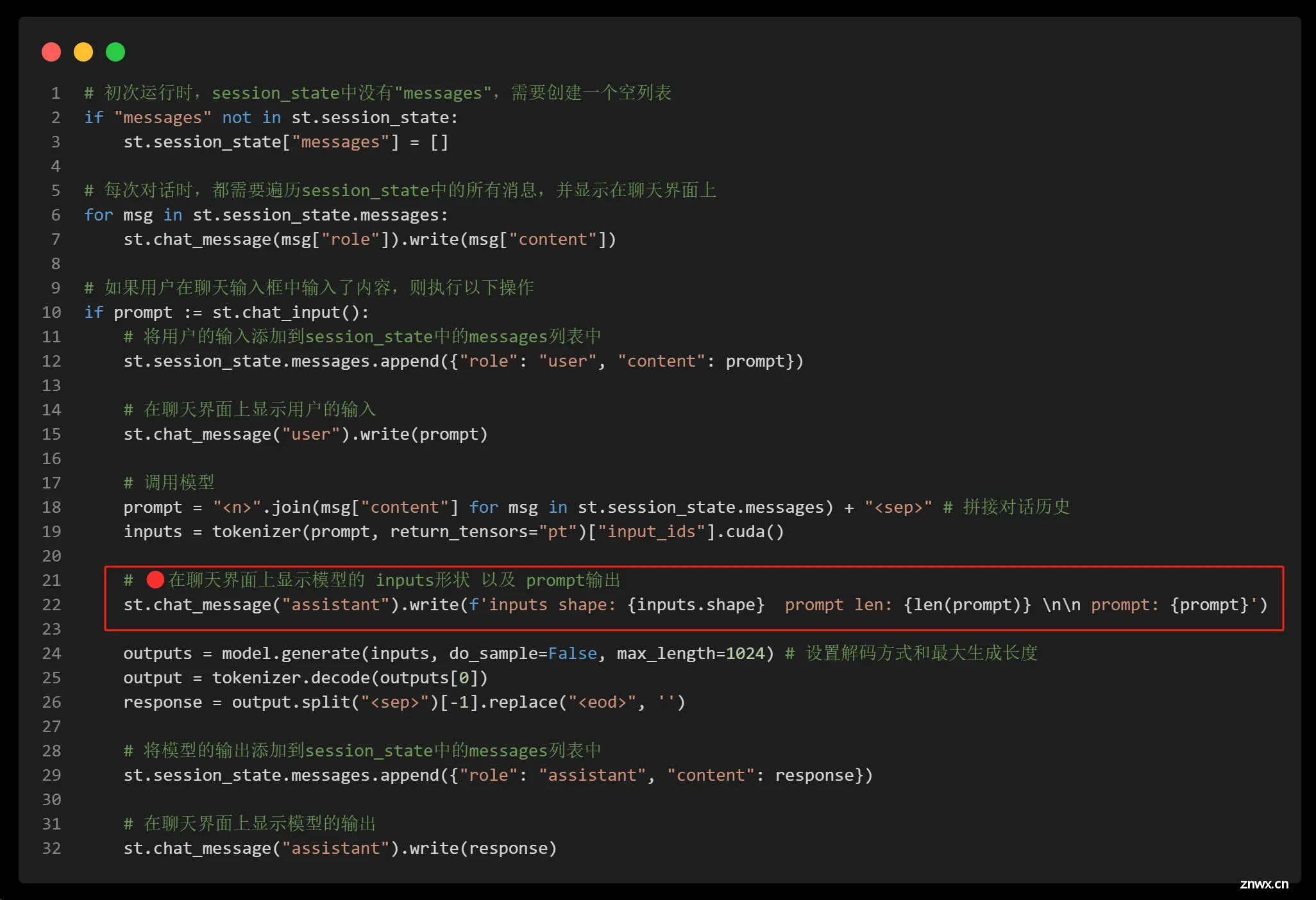
第一次提问,正常。

第二次提问,可见传入tokenizer的prompt是靠特殊标记符<code><n>拼接的。并且第二次回复模型开始复读。

我们不断重复这个过程,随着提问次数的增加,模型的input_ids的形状也逐渐增加。当然,可以发现,当inputs shape 长度超过1024时,错误的情况即发生了。
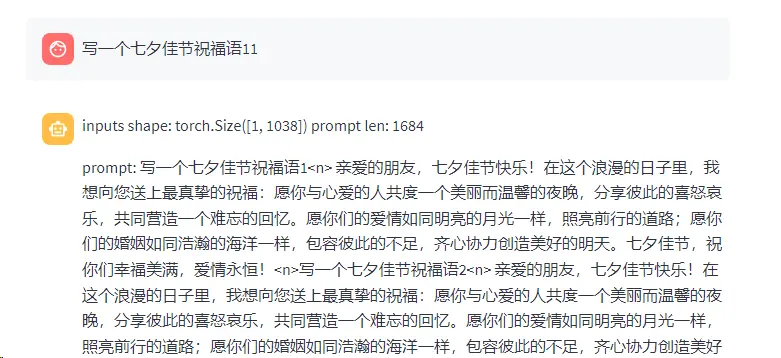

ValueError: Input length of input_ids is 1038, but max_length is set to 1024. This can lead to unexpected behavior. You should consider increasing max_length or, better yet, setting max_new_tokens.
解决方案有几种:
最直接:设置max_length 为更大的数值 4096 或者 8192 等。但是仍有溢出风险。
<code>outputs = model.generate(inputs, do_sample=False, max_length=2048) # 设置更大的最大生成长度
更好的方案:指定 max_new_tokens 参数来控制生成的新令牌数,而不是设置 max_length。
outputs = model.generate(inputs, do_sample=False, max_new_tokens=1024) # 设置生成的最大新令牌数
方案一的优化:在调用 model.generate 之前,截断输入张量,使其符合 max_length 参数的限制。
if inputs.shape[1] > 1024:
inputs = inputs[:, -1024:] # 截断输入张量,使其长度不超过1024
outputs = model.generate(inputs, do_sample=False, max_length=1024) # 设置解码方式和最大生成长度
此处提供一个硬截断的思路,也可以判断溢出之后按对话记录进行删除。
个人观点:方案2是优雅解法。
6. tokenizer加载的那些符号是什么意思?
上述遇到st装饰器的时候也看到了这行代码。
tokenizer.add_tokens(['<sep>', '<pad>', '<mask>', '<predict>', '<FIM_SUFFIX>', '<FIM_PREFIX>', '<FIM_MIDDLE>','<commit_before>','<commit_msg>','<commit_after>','<jupyter_start>','<jupyter_text>','<jupyter_code>','<jupyter_output>','<empty_output>'], special_tokens=True)
当前理解:训练模型时使用这些特定的标记符(tokens),用于区分、处理特定的任务或场景。
以下是每个 token 的含义和可能用途:
<sep>:
用于分隔不同部分的文本。在多轮对话或句子对中,使用这个标记可以明确区分不同的句子或发言。例如:
User: What is the weather today?<sep>Assistant: The weather today is sunny.
优化baseline 新想法:是否可以构造prompt的时候不要靠分隔句子,而是如示例用法追加身份标识User、Assistant呢?
(后面的内容只是猜测,简单了解)
<pad>: 用于填充序列,当模型处理长度不同的输入序列时,使用 <pad> 标记来填充较短的序列,使得所有序列长度一致。
<mask>: 在遮盖语言模型(如 BERT)中使用,用于表示被遮盖的标记,模型需要预测被遮盖的部分。
<predict>: 可能用于表示需要模型进行预测的部分。这在一些自监督学习任务中可能很有用。
<FIM_SUFFIX>, <FIM_PREFIX>, <FIM_MIDDLE>: 这些标记与“填充中间”(Fill-in-the-Middle, FIM)任务相关,其中模型需要在给定前缀和后缀的情况下填充中间的内容。
<commit_before>, <commit_msg>, <commit_after>: 在处理版本控制提交信息时,可以使用这些标记来区分提交前后的代码和提交消息。
<jupyter_start>, <jupyter_text>, <jupyter_code>, <jupyter_output>, <empty_output>: 这些标记用于处理 Jupyter Notebook 中的不同单元。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。