秃姐学AI系列之:Pytorch的多GPU炼丹
不是很强 但是很秃 2024-10-20 12:01:01 阅读 64
目录
引言
策略一:数据拆分,模型不拆分
nn.DataParallel
总结
缺点
策略二:数据不拆分,模型拆分
Model Parallel 基操
对已有的模块使用 Model Parallel
通过 Pipelining Inputs 加速模型并行
策略三:数据拆分,模型拆分
nn.DistributedDataParallel
工作原理
带来的改变
后端的选择
使用方法
使用进阶
Reduce
AllReduce
TreeAllReduce
RingAllReduce
引言
首先,我们需要了解PyTorch是如何支持多GPU训练的。
在PyTorch中,有多种方式可以实现多GPU的并行计算
DataParallelDistributedDataParallel手动模型拆分......
每种方式都有其适用的场景和优缺点,我们需要根据具体的任务和数据集来选择合适的策略。主要分为数据并行和模型并行二种策略。
策略一:数据拆分,模型不拆分
在这种策略中,我们将数据拆分成多个批次,每个批次在一个GPU上进行处理。模型不会拆分,而是复制到每个GPU上。
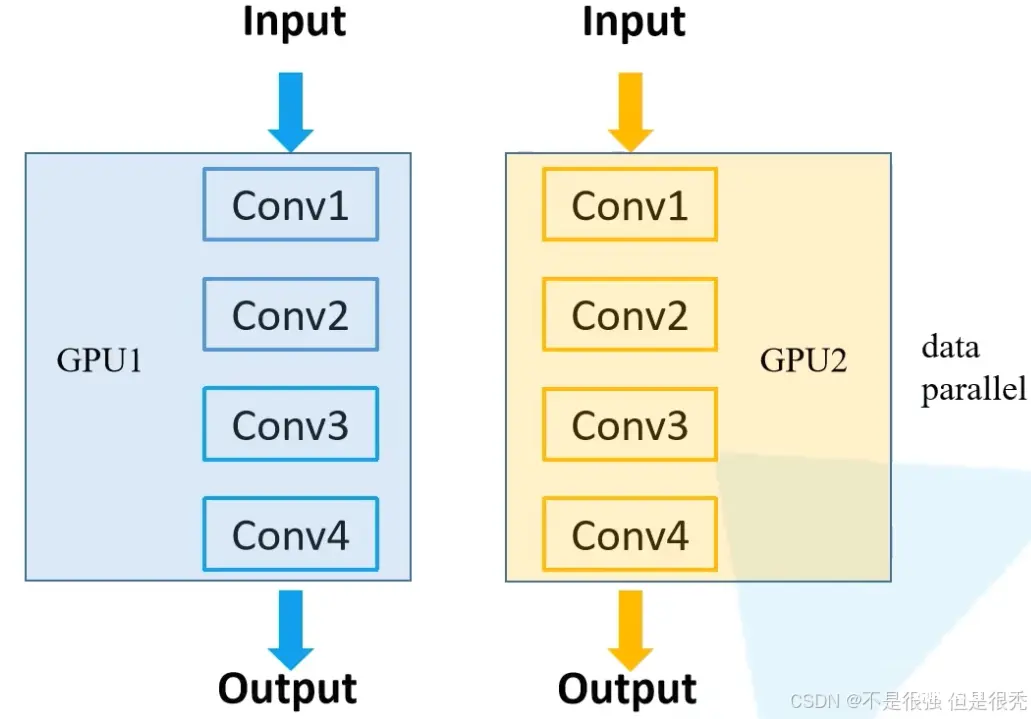
下面手搓一个概念模型看一下流程:
<code>import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torch.nn.parallel import DataParallel # 关键包
# 假设我们有一个自定义的数据集和模型
class MyDataset(Dataset):
# 实现__len__和__getitem__方法
pass
class MyModel(nn.Module):
# 定义模型结构
pass
# 初始化数据集和模型
dataset = MyDataset()
dataloader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)
model = MyModel()
# 检查GPU数量
device_ids = list(range(torch.cuda.device_count()))
model = DataParallel(model, device_ids=device_ids).to(device_ids[0])
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环
for epoch in range(num_epochs):
for inputs, labels in dataloader:
inputs, labels = inputs.to(device_ids[0]), labels.to(device_ids[0])
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
是不是感觉主要是DataParallel这个函数在起作用?
那我们来着重看一下这个函数
nn.DataParallel
一般我们会在代码中加入以下这句:
device_ids = [0, 1]
net = torch.nn.DataParallel(net, device_ids=device_ids)
似乎只要加上这一行代码,你在 Ternimal 下执行 watch -n 1 nvidia-smi后会发现确实会使用多个GPU来并行训练。但是细心点会发现其实第一块卡的显存会占用的更多一些,那么这是什么原因导致的?
查阅 Pytorch 官网的 nn.DataParrallel 相关资料,首先我们来看下其定义如下:
CLASS torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
其中包含三个主要的参数:module,device_ids和output_device。官方的解释如下:
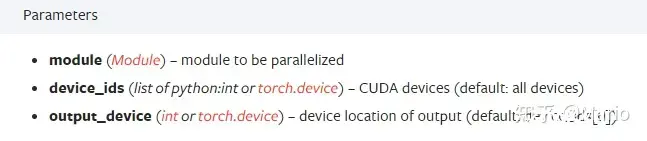
module即表示你定义的模型device_ids表示你训练的deviceoutput_device这个参数表示输出结果的device
而这output_device一般情况下是省略不写的,那么默认就是在device_ids[0],也就是第一块卡上,也就解释了为什么第一块卡的显存会占用的比其他卡要更多一些。
进一步说也就是当你调用 nn.DataParallel 的时候,只是在你的 input 数据是并行的,但是你的 output loss 却不是这样的,每次都会在第一块GPU相加计算,这就造成了第一块GPU的负载远远大于剩余其他的显卡。
下面来具体讲讲nn.DataParallel中是怎么做的。
首先在前向过程中,你的输入数据会被划分成多个子部分(以下称为副本)送到不同的 device 中进行计算
而你的模型 module 是在每个 device 上进行复制一份,也就是说,输入的 batch 是会被平均分到每个 device 中去,但是你的模型 module 是要拷贝到每个 devide 中去的,每个模型 module 只需要处理每个副本即可,当然你要保证你的 batch size 大于你的 gpu 个数。
然后在反向传播过程中,每个副本的梯度被累加到原始模块中。
概括来说就是:
DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总。
注意还有一句话,官网中是这样描述的:
The parallelized <code>module must have its parameters and buffers on device_ids[0] before running this DataParallel module.
意思就是:在运行此 DataParallel 模块之前,并行化模块必须在 device_ids[0] 上具有其参数和缓冲区。
在执行 DataParallel 之前,会首先把其模型的参数放在device_ids[0]上,一看好像也没有什么毛病,其实有个小坑。
我举个例子,服务器是八卡的服务器,刚好前面序号是0的卡被别人占用着,于是你只能用其他的卡来,比如你用2和3号卡,如果你直接指定device_ids=[2, 3]的话会出现模型初始化错误,类似于module没有复制到在device_ids[0]上去。
那么你需要在运行train之前需要添加如下两句话指定程序可见的devices,如下:
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "2, 3"
当你添加这两行代码后,那么 device_ids[0] 默认的就是第2号卡,你的模型也会初始化在第2号卡上了,而不会占用第0号卡了。
这里简单说一下设置上面两行代码后,那么对这个程序而言可见的只有 2 和 3 号卡,和其他的卡没有关系,这是物理上的号卡,逻辑上来说其实是对应 0 和 1 号卡,即 device_ids[0] 对应的就是第2号卡,device_ids[1] 对应的就是第3号卡。(当然你要保证上面这两行代码需要定义在
device_ids = [0, 1]
net = torch.nn.DataParallel(net, device_ids=device_ids)
这两行代码之前,一般放在train.py中import一些package之后。)
或者还可以通过参数设置CUDA_VISIBLE_DEVICES,你可以直接在你的bash输入
export CUDA_VISIBLE_DEVICES=1
代表程序将只能看到你的编号为1的显卡(这里默认从0开始编号,所以其实就是只能看到你的第二张卡),你也可以设置多张:
export CUDA_VISIBLE_DEVICES=0,1,2,3
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
这条代码是让设备ID=物理ID,在CUDA_VISIBLE_DEVICES之前用,不过一般不需要这个,默认的就是正常的顺序。
那么在训练过程中,你的优化器同样可以使用 nn.DataParallel,如下两行代码:
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
optimizer = nn.DataParallel(optimizer, device_ids=device_ids)
其次你还需要在你的模型这里设置:
model = nn.DataParallel(model).cuda()
剩余的就和单卡的设置是一样的了。
那么使用 nn.DataParallel 后,事实上 DataParallel 也是一个 Pytorch 的 nn.Module,那么你的模型和优化器都需要使用 .module 来得到实际的模型和优化器,如下:
# 保存模型:
torch.save(net.module.state_dict(), path)
# 加载模型:
net=nn.DataParallel(Resnet18())
net.load_state_dict(torch.load(path))
net=net.module
# 优化器使用:
optimizer.step() --> optimizer.module.step()
还有一个问题就是,如果直接使用nn.DataParallel的时候,训练采用多卡训练,会出现一个warning:
UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars;
will instead unsqueeze and return a vector.
首先说明一下:每张卡上的 loss 都是要汇总到第 0 张卡上求梯度,更新好以后把权重分发到其余卡。
为什么会出现这个warning,这其实和 nn.DataParallel 中最后一个参数 dim 有关,其表示 tensors被分散的维度,默认是 0,nn.DataParallel将在 dim = 0(批处理维度)中对数据进行分块,并将每个分块发送到相应的设备。单卡的没有这个warning,多卡的时候采用 nn.DataParallel 训练会出现这个warning,由于计算loss的时候是分别在多卡计算的,那么返回的也就是多个loss,你使用了多少个gpu,就会返回多少个loss。
有人建议DataParallel类应该有reduce和size_average参数,比如用于聚合输出的不同loss函数,最终返回一个向量,有多少个gpu,返回的向量就有几维。
前期探讨中,有人提出求 loss 平均的方式会在不同数量的 gpu 上以微妙的方式影响结果。模块返回该 batch 中所有损失的平均值,如果在 4 个 gpu 上运行,将返回 4 个平均值的向量。然后取这个向量的平均值。但是,如果在 3 个GPU或单个GPU上运行,这将不是同一个数字,因为每个GPU处理的 batch size 不同!举个简单的例子(就直接摘原文出来):
A batch of 3 would be calculated on a single GPU and results would be [0.3, 0.2, 0.8] and model that returns the loss would return 0.43.
If cast to DataParallel, and calculated on 2 GPUs, [GPU1 - batch 0,1], [GPU2 - batch 2] - return values would be [0.25, 0.8] (0.25 is average between 0.2 and 0.3)- taking the average loss of [0.25, 0.8] is now 0.525!
Calculating on 3 GPUs, one gets [0.3, 0.2, 0.8] as results and average is back to 0.43!
似乎一看,这么求 平均loss 确实有不合理的地方。那么有什么好的解决办法呢,可以使用size_average=False,reduce=True 作为参数。每个GPU上的损失将相加,但不除以GPU上的批大小。然后将所有平行损耗相加,除以整批的大小,那么不管几块GPU最终得到的平均loss都是一样的。
总结
这种方式只有一个进程,假设我们有一个8卡的机器,然后设置的batchsize是128,那么单卡的batchsize就是32,在训练的时候,他把我们的模型分发到每个GPU上,然后在每个GPU上面对着32张图进行前向和反向传播得到loss,之后将所有的loss汇总到0卡上,对0卡的参数进行更新,然后,非常重要的一点:他再把更新后的模型传给其他7张卡,这个操作是在每个batch跑完都会执行一次的。
可以想象一下,每个batch,GPU之间都要互相传模型,GPU的通信显然成为了一个极大的瓶颈,直接导致GPU在一段时间是闲着的,也就导致了GPU的利用率低的问题。
缺点
GPU利用率低不支持多机多卡不支持混合精度
策略二:数据不拆分,模型拆分
在这种策略中,整个数据集在每个GPU上都会有一份副本,但模型会被拆分成多个部分,每个部分在一个GPU上运行。这种策略通常不常见,因为数据复制会消耗大量内存,而且模型拆分也可能会导致通信开销增加。
Model Parallel 基操
不过,这里还是提供一个简化的示例:
注意:这个示例可能不适用于所有模型,因为模型拆分通常涉及到复杂的并行和通信策略。
这里只是为了演示目的。
比如现在有一个包含2个 Linear layers 的模型,我们想在2块 GPU 上 run 它,办法可以是在每块 GPU 上放置1个 Linear layer,并且把得到的中间结果在 GPU 之间移动。代码可以是这样子:
import torch
import torch.nn as nn
import torch.optim as optim
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = torch.nn.Linear(10, 10).to('cuda:0')
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to('cuda:1')
def forward(self, x):
x = self.relu(self.net1(x.to('cuda:0')))
return self.net2(x.to('cuda:1'))
注意,上述 ToyModel 看起来与在单个 GPU 上的实现方式非常相似,除了四个 to(device) 的调用,将 Linear layer 和张量放在适当的设备上。这是该模型中唯一需要改变的地方。backward() 和 torch.optim 将自动处理梯度问题,就像模型是在一个 GPU 上一样
你只需要确保在调用损失函数时,标签和输出是在同一个设备上。像下面这样:
model = ToyModel()
loss_fn = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = model(torch.randn(20, 10))
labels = torch.randn(20, 5).to('cuda:1')
loss_fn(outputs, labels).backward()
optimizer.step()
这里应该把标签 labels 放在1号 GPU 上面,因为模型的输出就在1号 GPU 上。
对已有的模块使用 Model Parallel
这段我们介绍如何在多个 GPU 上运行一个现有的单 GPU 模块,只需做几行修改即可。
下面的代码显示了如何将 torchvision.models.resnet50() 分解到两个 GPU。这个想法是继承现有的 ResNet 模块,并在构建过程中将各层分割到两个 GPU 上面。
然后,overwrite forward() 方法,通过相应地移动中间输出来缝合两个子网络。
from torchvision.models.resnet import ResNet, Bottleneck
num_classes = 1000
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(
Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1,
self.bn1,
self.relu,
self.maxpool,
self.layer1,
self.layer2
).to('cuda:0')
self.seq2 = nn.Sequential(
self.layer3,
self.layer4,
self.avgpool,
).to('cuda:1')
self.fc.to('cuda:1')
def forward(self, x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0), -1))
上述实现解决了模型太大,无法装入单个GPU的情况下的问题。然而,对于运行速度而言,它将比在单个 GPU 上运行的速度要慢。
这是因为,在任何时候,两个 GPU 中只有一个在工作,而另一个则是坐在那里啥也不干。由于中间输出需要在第二层和第三层之间从 cuda:0复制到 cuda:1,所以性能会进一步恶化。
通过 Pipelining Inputs 加速模型并行
因为我们知道两个 GPU 中的一个在整个执行过程中是闲置的。一个选择是将每个批次的 images 进一步划分为一个个的 splits,这样当一个 split 到达第二个子网络时,下面的 split 可以被送入第一个子网络。通过这种方式,两个连续的 splits 可以在两个 GPU 上同时运行。
要理解这波操作,就得首先学习一个 torch.split 函数:
torch.split - PyTorch 1.10.0 documentationpytorch.org/docs/stable/generated/torch.split.html
torch.split(tensor, split_size_or_sections, dim=0)
Parameters
tensor (Tensor) – tensor to split.split_size_or_sections (int) or (list(int)) – size of a single chunk or list of sizes for each chunkdim (int) – dimension along which to split the tensor.
它的作用的官方描述是:Splits the tensor into chunks. Each chunk is a view of the original tensor.
如果 split_size_or_sections 是一个整数类型,那么张量将被分割成同等大小的块。如果张量沿着给定的维度 dim 的大小不能被 split_size 整除,那么最后一个块会更小。
如果 split_size_or_sections 是一个列表,那么张量将被分割成 len(split_size_or_sections) 个小块,其大小与 split_size_or_sections 相同。
举例:
>>> a = torch.arange(10).reshape(5,2)
>>> a
tensor([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> torch.split(a, 2)
(tensor([[0, 1],
[2, 3]]),
tensor([[4, 5],
[6, 7]]),
tensor([[8, 9]]))
>>> torch.split(a, [1,4])
(tensor([[0, 1]]),
tensor([[2, 3],
[4, 5],
[6, 7],
[8, 9]]))
接下来,我们回到 PipelineParallelResNet50 模型,进一步将每个 batch 的 120 张图片分成 20 张图片的 split,这步操作可以通过 splits = iter(x.split(self.split_size, dim=0)) 来完成。
由于PyTorch是异步启动CUDA操作的,因此该实现不需要催生多个线程来实现并发。代码如下,简单梳理一下代码的含义:
class PipelineParallelResNet50(ModelParallelResNet50):
def __init__(self, split_size=20, *args, **kwargs):
super(PipelineParallelResNet50, self).__init__(*args, **kwargs)
self.split_size = split_size
def forward(self, x):
# 对输入的 batch=120 的图片分成相同大小为20的 splits
splits = iter(x.split(self.split_size, dim=0))
# 从头开始,每次取出一个 split
s_next = next(splits)
# 把第1个 split 通过第1段模型
s_prev = self.seq1(s_next).to('cuda:1')
ret = []
# for 循环可以看做每次循环做2件事
for s_next in splits:
# A. 前半段模型的输出传到后半段并前向传播
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
# B. 下一个 split 输入前半段模型
s_prev = self.seq1(s_next).to('cuda:1')
s_prev = self.seq2(s_prev)
ret.append(self.fc(s_prev.view(s_prev.size(0), -1)))
return torch.cat(ret)
setup = "model = PipelineParallelResNet50()"
pp_run_times = timeit.repeat(
stmt, setup, number=1, repeat=num_repeat, globals=globals())
pp_mean, pp_std = np.mean(pp_run_times), np.std(pp_run_times)
plot([mp_mean, rn_mean, pp_mean],
[mp_std, rn_std, pp_std],
['Model Parallel', 'Single GPU', 'Pipelining Model Parallel'],
'mp_vs_rn_vs_pp.png')
同一个 batch 的数据,有些提前进入后半段模型 Model Part 2,而不用等待全部数据走完前半段模型 Model Part 1之后再统一进入后半段模型 Model Part 2。这样子节约了运行时间
策略三:数据拆分,模型拆分
在这种策略中,我们同时使用数据并行和模型并行。数据被拆分成多个批次,每个批次在不同的GPU上进行处理,同时模型也被拆分成多个部分,每个部分在不同的GPU上运行。这通常用于非常大的模型,单个GPU无法容纳整个模型的情况。
import torch
import torch.distributed as dist # 重点
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset, DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
# 自定义数据集和模型
class MyDataset(Dataset):
# 实现__len__和__getitem__方法
pass
class MyModel(nn.Module):
# 定义模型结构,可能需要考虑如何拆分模型
pass
# 初始化分布式环境
dist.init_process_group(backend='nccl', init_method='tcp://localhost:23456', rank=0, world_size=torch.cuda.device_count()) code>
# 初始化数据集和模型
dataset = MyDataset()
sampler = DistributedSampler(dataset)
dataloader = DataLoader(dataset, batch_size=32, shuffle=False, sampler=sampler)
model = MyModel()
# 拆分模型(这通常需要根据模型的具体结构来手动完成)
# 例如,如果模型有两个主要部分,可以将它们分别放到不同的设备上
model_part1 = model.part1.to('cuda:0')
model_part2 = model.part2.to('cuda:1')
# 使用DistributedDataParallel包装模型
model = DDP(model, device_ids=[torch.cuda.current_device()])
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环
for epoch in range(num_epochs):
for inputs, labels in dataloader:
inputs, labels = inputs.to(model.device), labels.to(model.device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 销毁分布式进程组
dist.destroy_process_group()
请注意,上面的代码只是一个非常基础的示例,用于说明如何使用 torch.distributed 进行分布式训练。此外,还有一些高级库,如PyTorch Lightning,可以简化分布式训练的设置和管理。
nn.DistributedDataParallel
分布式的数据并行在很大程度上解决了上面我们 nn.DataParallel 数据并行的问题,支持多机多卡,支持混合精度,是现在非常实用的一种方式。
工作原理
nn.DistributedDataParallel 和 nn.DataParallel 最大的区别是,不再来回同步模型了,太麻烦了,我们需要同步的其实只有梯度,梯度同步后,每个GPU做自己的参数更新就行,那么在每个GPU有独立工作的需求后,多进程就被拿了出来,每个进程控制一块GPU。
每个进程控制一个GPU,然后每个GPU计算自己分得的数据的梯度后,通过进程之间的通信进行综合所有梯度的操作(all-reduce),每个GPU独立更新参数(实际上就是同样的东西算了好多遍),但是这里更新完每个GPU的模型参数是一样的。
插一句话:这里其实体现了计算机科学现在的一个瓶颈,就是IO瓶颈超越了计算速度瓶颈,多计算比使用IO同步要更快
带来的改变
从原理上看其实就只是添加了一个多进程,但是其实多进程的添加,给整个训练添加了很多的改变。
设置seed,如果每个进程的模型使用不同的seed,那就没办法同步,整个训练就没有意义了每个进程需要知道自己是第几个进程(rank),以及一共有多少个进程(word_size)每个进程需要知道自己load哪部分数据,因为每个进程load的数据是不一样的。
这里有个坑,估计很少有人会提,laod data的时候 Pytorch 是有一个num_worker,这个代表使用多进程加载,而我们现在已经使用了多进程,那么其实一共跑在机器上的是
n*num_worker,如果这个太多,也会出一些问题,也就是在已经多进程的基础上就不用再搞很多进程了。
后端的选择
使用了多进程,就意味着需要进行进程之间的通信,Pytorch 提供给的后端有三种:
基于mpigloo基于nccl
但是其实能够用的只有一种,也就是 nccl,因为 mpi 的需要本地编译 Pytorch,里面必然有很多坑,估计也没什么人用;基于 gloo 的对 GPU 的支持很差,基本只支持 CPU,所以现在绝大多数的人都用的是基于 nccl 的,所以我们后面介绍的也是基于nccl。
使用方法
首先需要import一些东西
import torch.distributed as dist
在这种方式下最重要的就是获得几个重要的信息,第一是 word_size,第二个是 rank,第三个是使用 nccl 时使用 tcp通信 的 ip 和 port。
我们先假设我们有四个节点,每个节点有 8 块 GPU,我们需要在 main 获取完 args 后进行下面的操作:
args.world_size = args.gpus * args.nodes
os.environ['MASTER_ADDR'] = '10.57.23.164'
os.environ['MASTER_PORT'] = '8888'
mp.spawn(train, nprocs=args.gpus, args=(args,))
word_size 是节点数 * 每个节点的GPU数量,addr 和 port 直接设置成为环境变量,你也可以用下面的方式在bash里面设置。
export MASTER_ADDR=10.57.23.164
export MASTER_PORT=8888
最后再开启多进程传入参数即可。
然后是进入def train(gpu, args)里面:
torch.manual_seed(0)
rank = args.nr * args.gpus + gpu
dist.init_process_group(
backend='nccl', code>
init_method='env://', code>
world_size=args.world_size,
rank=rank
)
先拿到这个进程的 rank,rank=第几个节点 x 8 + 这个节点的第几个进程,根据这些关键按信息对Pytorch分布式进行初始化。
model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
模型初始化,以及GPU分配
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=args.world_size,
rank=rank
)
sampler 记得使用分布式的 sampler,要传入 rank,这样就能只加载这个进程需要的数据。train_loader 的参数 shuffle=False, sampler=train_sampler这里就不能 shffle 了。
最后是跑,因为我们有四个节点,所以需要启动四次,在第0个节点上这样跑
python main.py -n 4 -g 8 -nr 0
在1、2、3节点上这样跑
python main.py -n 4 -g 8 -nr i
就是告诉程序一共有几个节点,每个节点有几个GPU,目前终端是第几个节点。
注意,在 dist.init_process_group 这里是阻塞的,也就是会等待所有参与的进程都准备就绪才会继续开始,所以不用担心四个终端启动时间的问题,但是还是要先0后1、2、3。
使用进阶
很显然,上面四个节点分四个终端启动的方式是很蠢的,实际上肯定不会这么做,并且实际上节点都会有其任务管理系统,不会和上面这样这么简单,因此这部分就以 slurm 这个任务调度工具为例,说说在 slurm 下,pytorch 的多进程怎么做。
其实跟上面的核心是一样的,使用 slurm 的主要区别是获取那些关键信息的方法,其他的并没有大的区别。
我们在启动 srun 的时候指定-n:进程总数以及 --ntasks-per-node:每个节点进程数,就能在os里面拿到上面需要的一些东西了
rank = int(os.environ['SLURM_PROCID'])
local_rank = int(os.environ['SLURM_LOCALID'])
world_size = int(os.environ['SLURM_NTASKS'])
# get_ip是个字符串处理函数,需要根据自己的集群的名字等等信息调试一下
ip = get_ip(os.environ['SLURM_STEP_NODELIST'])
这里面的 rank 就是上面的 rank 的值,word_size 也是上面的那个,ip 和我们上面设置的 ip 是一样的作用,local_rank 其实就是前面 train 传入的 gpu 参数,也就是在这个节点上的进程值。
这些信息有着落了之后,其他的就和前面的方法一样了,最后只需使用类似的命令开始 task 即可:
srun -n32 --gres=gpu:8 --ntasks-per-node=8 python main.py
这里附上Slurm的官方文档:Slurm Workload Manager - Documentation (schedmd.com)
Reduce
Reduce 其实是 map-reduce 中的那个 reduce,也就是综合的意思,在分布式的GPU中,可以理解成把每个GPU的梯度求和算出来。
AllReduce
AllReduce 就是让每个进程都 reduce,假设四个GPU里面分别是1、2、3、4四个值,Reduce 是求和得到10,AllReduce 是每个GPU得到的都是10,即10、10、10、10,显然我们多进程分布式训练的时候需要的就是这个AllReduce操作来让每个进程拥有全局的梯度。
TreeAllReduce
TreeAllReduce 就是使用一个主进程取得所有GPU的梯度,然后求和,再发送给剩余的GPU,显然这种方式的速度跟GPU的数量 N 是有关系的,随着 N 的变大,效率必然越来越低。当然这里也可以使用分治将复杂度降级到 log 数量级,但依然与 N 有关。
RingAllReduce
RingAllReduce 是现在大家使用的一种方法,具体的想法是将GPU看成一个环,将自己的数据 K 分成 N 份,大家按照顺时针发一份数据给下家,显然,经过 N-1 次,每个GPU都会有一部分是受到了全部的数据的,然后再经过N-1次的发送,让所有的GPU的所有部分都收到了全部的数据。这样算起来流量就与 N 无关了:
如果对这部分的详细的有疑问的话,可以去看https://www.zhihu.com/question/57799212/answer/612786337 这个回答,里面有大佬画了非常详细的图来说明。
文章参考:
1、Pytorch的nn.DataParallel - 知乎 (zhihu.com)
2、【多GPU炼丹-绝对有用】PyTorch多GPU并行训练:深度解析与实战代码指南_torch上使用多gpu并行训练模型-CSDN博客
3、Pytorch Distributed - 知乎 (zhihu.com)
4、PyTorch 81. 模型并行 (Model Parallel) - 知乎 (zhihu.com)
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。