天翼云完成首个国产化万卡训练,MFU达到国内领先水平!
cnblogs 2024-10-11 11:13:00 阅读 61
天翼云自研国内首个单集群万卡国产化全功能预训练云服务平台发布上线,并完成万卡规模Llama3.1-405B大模型训练。Llama3.1-405B作为4000亿参数的模型,在息壤训推服务平台的支持下经过多轮优化,MFU达到国内领先水平;另外,700亿参数模型Llama2-70B在万卡规模下完成训练,MFU也处于业界领先水平。
天翼云自研国内首个单集群万卡国产化全功能预训练云服务平台发布上线,并完成万卡规模Llama3.1-405B大模型训练。Llama3.1-405B作为4000亿参数的模型,在息壤训推服务平台的支持下经过多轮优化,MFU达到国内领先水平;另外,700亿参数模型Llama2-70B在万卡规模下完成训练,MFU也处于业界领先水平。
万卡纳管、并行训练
大模型训练效率大幅提升
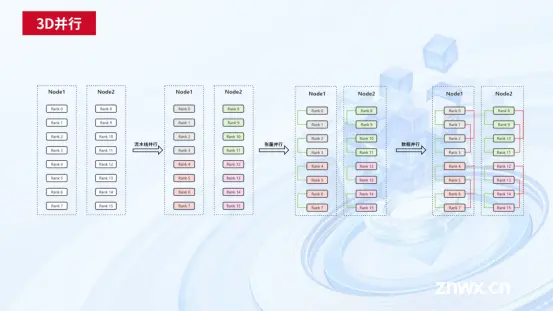
平台具备万卡纳管和并行训练能力,基于HPFS的PB级并行文件系统和CTCCL的RDMA高速卡间互联技术、基于Gang策略与拓扑感知的智算容器调度,以及慧聚自研分布式训练框架TeleFormers和平台,实现万卡资源纳管和万卡规模并行训练。
天翼云自研了AI框架Teleformers,对算子、通信、数据处理进行优化,以及并行策略的自适应调整,显著提升大模型训练的训练效率,在目前业内最大参数规模开源单体稠密模型Llama3.1-405B大模型训练测试中,性能表现达到国际同等水平。
算子优化方面:
针对昇腾芯片的特性,在网络结构层面对诸多高频算子进行了定制化改造,构建了高性能算子集。以matmul算子为例,天翼云利用昇腾芯片的计算亲和性,将算子输入padding到特定的维度,大幅提升执行效率,从而明显缩短了训练时间。
数据处理和流水线方面:
通过设置合理的数据分片策略和HPFS条带化优化,结合数据预取与数据下沉技术,大幅提升数据流的处理效率和稳定性;对预处理后的数据集进行了二次分片并提供就近缓存能力,减少GPU空闲时间。

自适应并行策略:
基于对3D并行中各类计算单元的分析,天翼云设计了多种自适应的3D并行策略,依据模型规模和硬件资源的不同可以自动选择合适的并行策略,充分利用计算资源和显存资源,缩短模型训练中每轮的迭代时间。
多项技术突破,实现万卡训练故障
秒级定位、分钟级处理、分钟级恢复
天翼云息壤训练服务平台基于软硬件协同设计,提供全链路故障监控、基于主动感知的全链路故障监控和定位、CheckPoint秒级多级高速存储系统、容错优雅调度和模型编译缓存等系统,将万卡规模故障发现和解决问题缩短到业内前沿的分钟级,大幅提升有效训练时间。
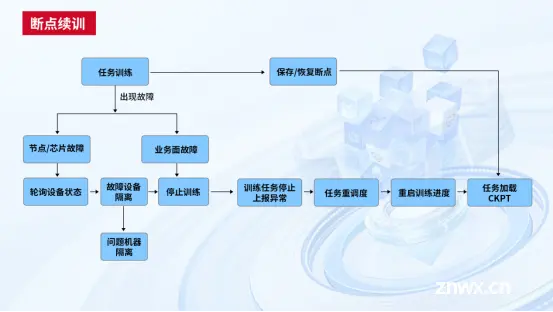
自动断点续训系统:
建设丰富的故障库,基于此构建了多维故障感知系统,能够快速主动感知相关故障事件和潜在的故障风险,并通过精准的故障隔离和调度手段,快速隔离处理故障节点并重新调度新节点接手任务继续训练,实现无人干预式断点续训,有效减少GPU闲置时间。
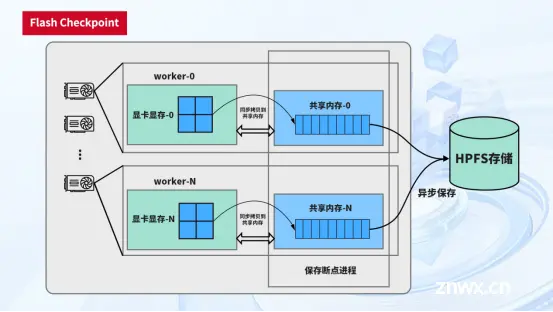
高速多级CheckPoint系统:
天翼云设计基于多级存储的高速CheckPoint系统,通过两阶段异步存储,实现高速写入内存,并最终异步写入远端系统;针对断点恢复场景,提供进程级故障原地快恢和远端快速恢复能力,最终实现对CheckPoint的秒级读写能力,大幅降低断点恢复时间、提升训练效率。
全链路检测工具链:
天翼云开发了全链路故障监控工具链,能够基于主动感知实现全链路的故障监控和定位。该工具链可以主动发现设备故障,并降低训练中断的频次,确保训练过程的连续性和稳定性。
天翼云国产化万卡智算中心训推服务平台的方案,适用于千亿/万亿级参数规模大语言模型训练,如Llama3、Qwen等超大规模语言模型,以及多模态模型开发、虚拟现实与元宇宙等。
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。