LLM并行训练3-数据并行
cnblogs 2024-06-29 08:13:00 阅读 76
大模型训练 数据并行相关的学习笔记, 主要内容 zero, zero++
前置知识
混合精度训练
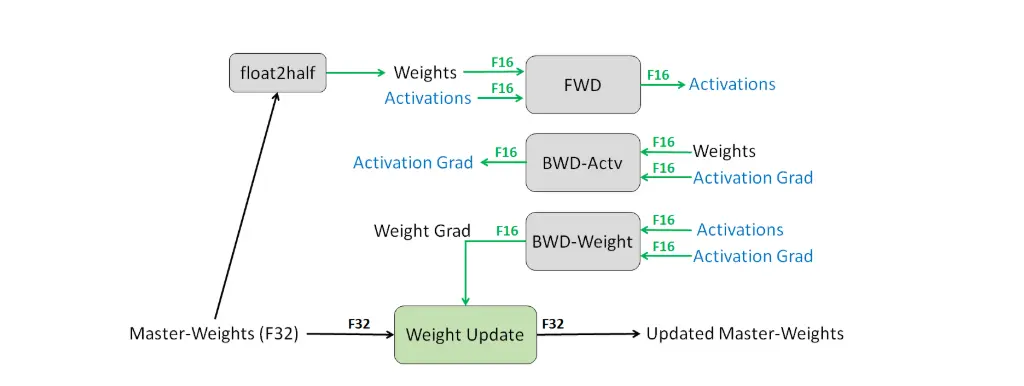
在参数存储时采取fp32, 开始进行fp/bp时转成fp16运算, 拿到fp16梯度后再转回fp32更新参数.
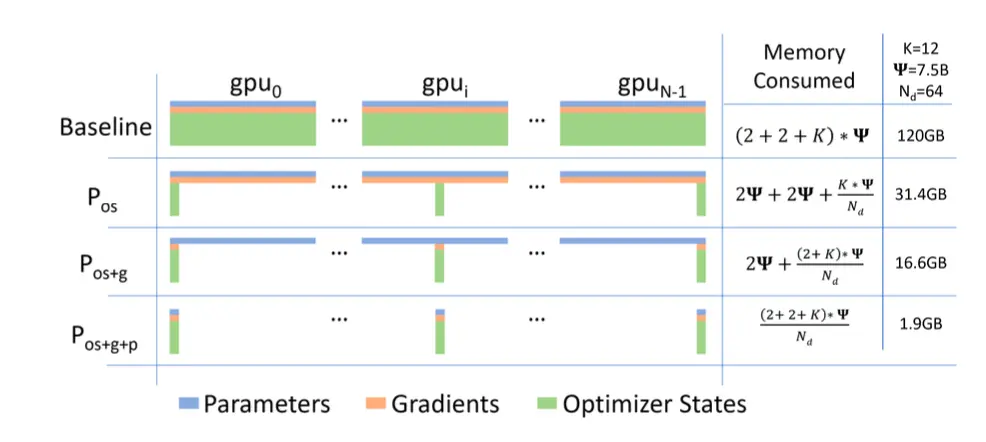
ZeRO对显存占用的估算:
- 模型状态: Weights(fp16)、grad(fp16) 和 MasterWeights(fp32 模型参数备份),momentum(fp32)和variance(fp32)。假设模型参数量 \(\Phi\) ,则共需要\(2\Phi + 2\Phi + (4\Phi + 4\Phi + 4\Phi) = 4\Phi + 12\Phi = 16\Phi\) 字节存储,
- 剩余状态: 除了模型状态之外的显存占用,包括激活值(activation)、各种临时缓冲区(buffer)以及无法使用的显存碎片(fragmentation)
Adam

在adam optimizer的计算状态除了参数, 还有一个\(m_t\)(momentum 梯度均值)和\(v_t\)(variance 梯度未中心化方差)需要存储, 一般被称为optimizer state.
AllToAll通信原语
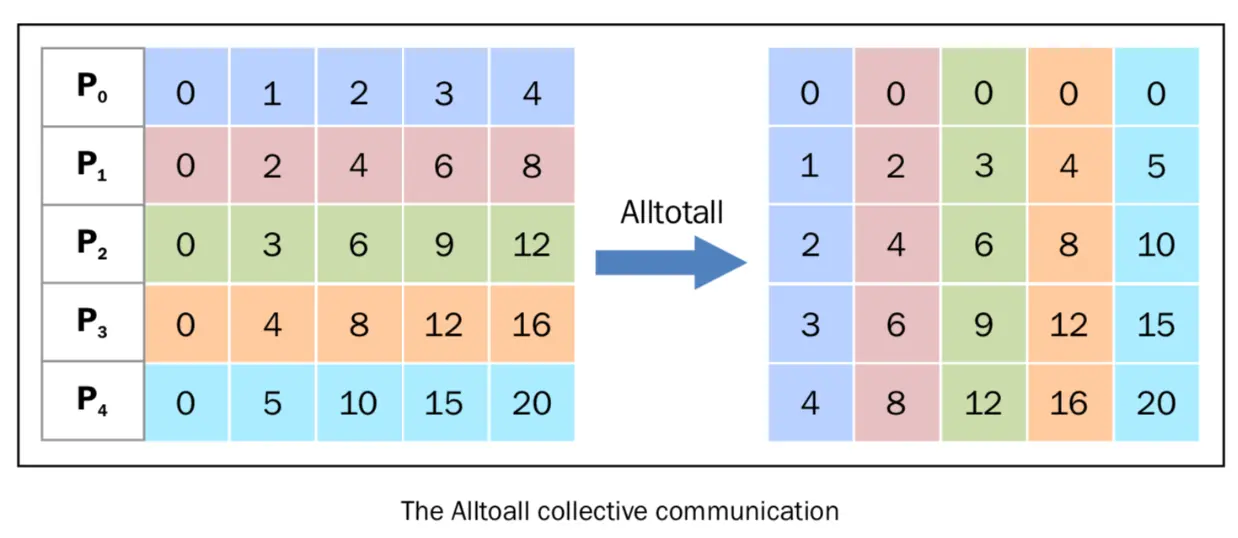
allToall类似于矩阵转置. 相当于我们需要先把每个节点里的数据按照他们要传递给哪个节点排好序, 然后根据切分好的顺序推给对应的节点. 可以看到如果每个节点的数据量是\(M\), 节点数是\(N\), 最终通信总量就是\(M * N\)
ZeRO
在传统的训练方法里, 每张卡里存储一份完整的模型状态, 完成bp后allReduce grad,再更新每张卡里的副本. 这样子有N张卡就会多出\((N-1)\)份冗余的参数存储. 当参数规模急剧增大时这种方法就完全不适合训练. ZeRO1 主要是将这些冗余的模型状态干掉, 通过增加通信来解决冗余参数的问题. ZeRO原理动态图

- ZeRO1: 只保留一份
MasterWeights+momentum+variance. - ZeRO2: 在ZeRO1的基础上去除了grad的冗余
- ZeRO3: 在ZeRO2的基础上去掉了weights的冗余
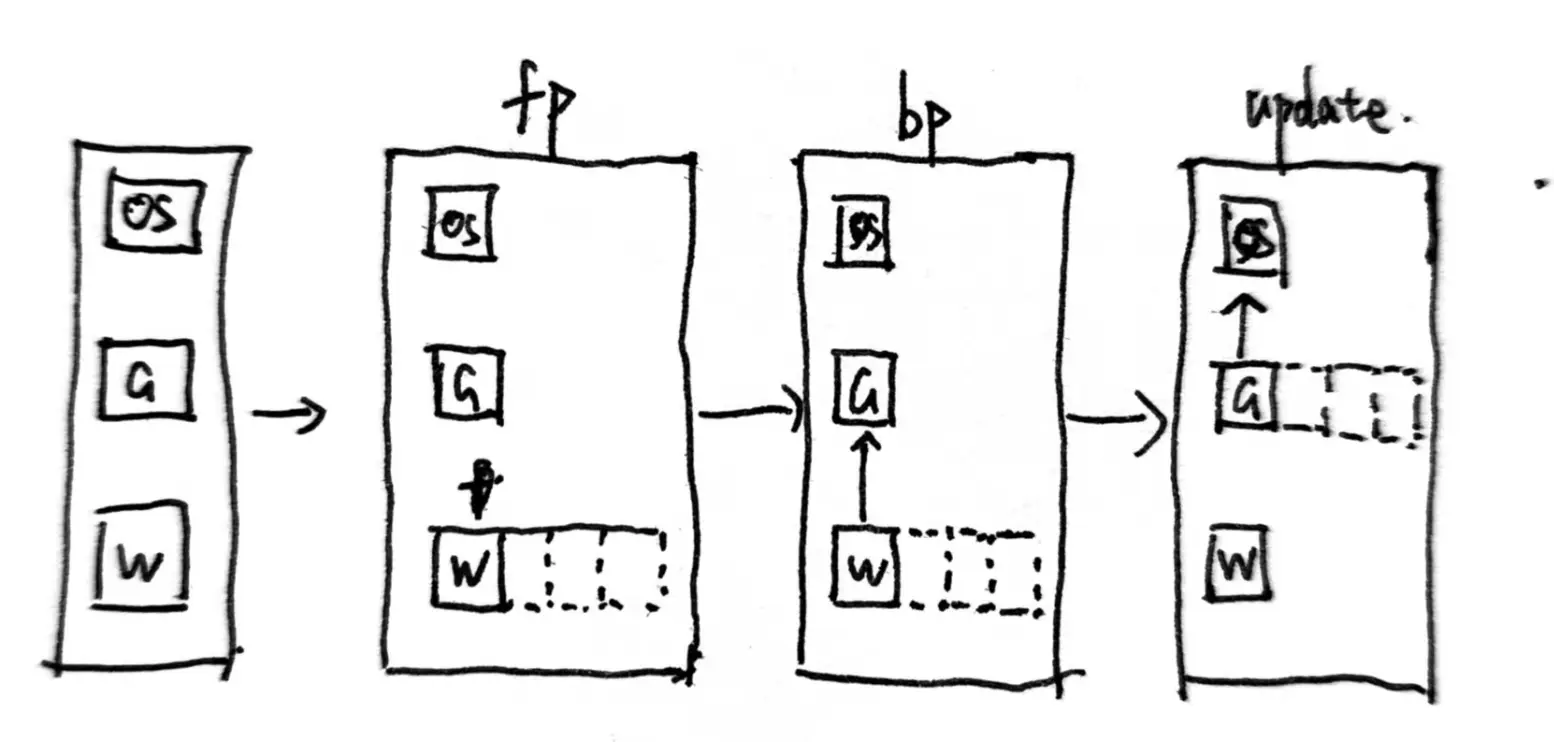
训练流程
以ZeRO3为例. 主要分为5步, 假设使用了4张卡进行训练:
- 每张卡上存1/4的W, OS和grad. 每张卡训练自己分配到的batch.
- fp时, AllGather所有卡上的W,取到全量的W(fp16)进行fp, 完成后只保留自己需要维护的1/4 W, 其他显存释放回池
- bp时, AllGather所有卡上的W进行bp, 完成后再抛弃其他卡维护的W
- 完成bp后, ReduceScatter所有卡的G, 从其他卡上取到需要需要更新的梯度增量, 然后释放不是自己维护的G.
- 使用自己维护的OS和G来更新W, 不需要通信.

通信量分析
定义单卡数据量为\(\Phi\)
传统DP: bp完成后需要对梯度进行一次AllReduce, 一共\(2\Phi\)
ZeRO1: 只舍弃了OS, bp时需要AllReduce G(Scatter+Gather 共\(2\Phi\)). 另外在使用每张卡各自更新W时, 因为W每张卡都存储的全量, 需要从存储OS的卡上把对应更新后的W再拉回来, 所以需要一次Gather(\(\Phi\)), 一共需要\(3\Phi\)
ZeRO2: 舍弃了OS和G, bp时AllGather G(\(\Phi\)), 更新W时从其他卡拉W, 再Gather一次(\(\Phi\)), 一共需要\(2\Phi\)
ZeRO3: 上面训练过程分析过, 共需要2次Gather和1次Scatter, 一共需要\(3\Phi\)
可以看到ZeRO在通信量只增加了1.5倍的情况下, 显存降了60倍. 效果非常显著
ZeRO++
ZeRO存在的问题是会在GPU之间产生大量数据传输开销,降低了训练效率. 主要有两种情况:
全局batch size较小,而 GPU数量多,这导致每个 GPU 上batch size较小,需要频繁通信
在低端集群上进行训练,其中跨节点网络带宽有限,导致高通信延迟。
ZeRO++主要采用了3部分优化: 权重量化 (qwZ), 分层分割存储 (hpZ), 梯度量化 (qgZ). 对比ZeRO通信量减少了4倍, 主要的难点都在减小量化带来的训练误差上
权重量化
def _quantize_int8(self, tensor: Tensor) -> Tuple[Tensor, Tensor, Tensor]:
q_range = 2**self.config['num_bits'] - 1
min_value = tensor.amin(dim=self.config['group_dim'] + 1, keepdim=True)
max_value = tensor.amax(dim=self.config['group_dim'] + 1, keepdim=True)
scale = q_range / (max_value - min_value)
tensor = tensor.sub_(min_value).mul_(scale)
tensor = tensor_round(tensor_clamp(tensor, 0, q_range)).to(torch.uint8) #对称式量化
return tensor, scale, min_value
量化代码在deepspeedcsrc/quantization/quantize.cu cached_quantization 这个kernel里.
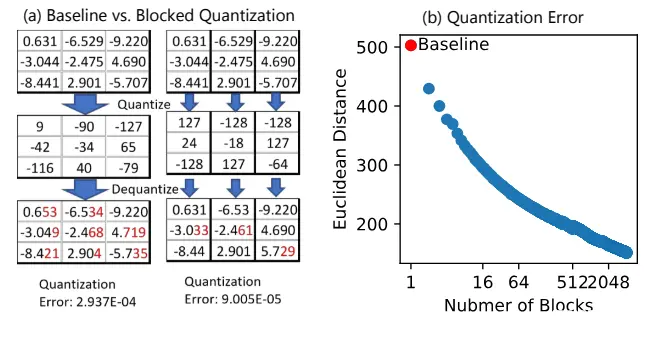
如果采用全局fp16->int8的量化会导致极大误差. deepspeed采用了分区量化的方法, 把参数分为固定大小的block后, 先根据这个block的max/min计算出scale(量化系数), 在把这个参数传入量化函数里. 另外在通信的时候应该也需要每个block对应的系数传给接收节点用于反量化.
\[量化公式: clip(round(scale * x), -2^{b-1}+1, 2^{b-1}-1)
\]
通过这种方式在通信量减半的同时还能保证精度, 很nice的思路.
分层分割存储
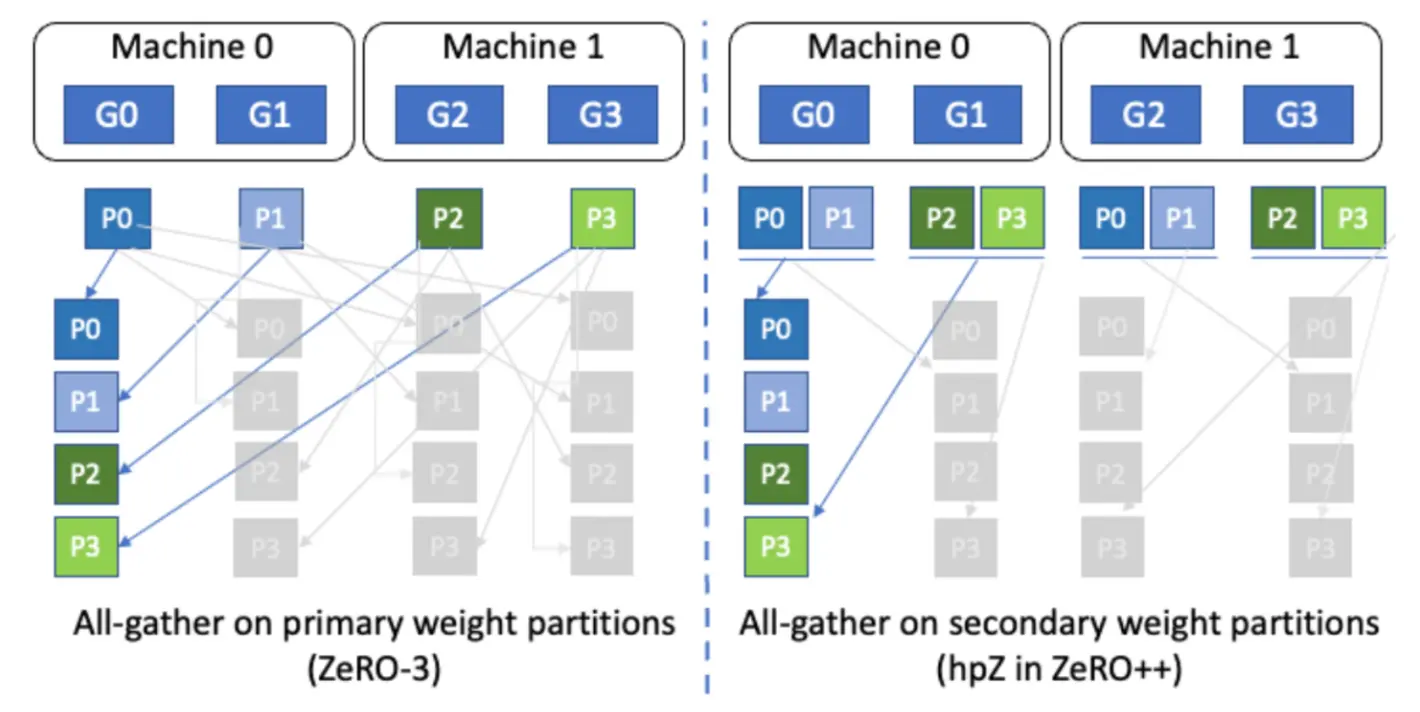
之前ZeRO的W切分方法是根据卡数均分. 在fp/bp之前进行AllGather拉取, 后来发现在机器间进行Gather通信是比较严重的瓶颈. 所以最后W的切分变成了每个节点内存储全量的W, 节点内根据卡数进行切片. 避免跨节点经过网卡的通信, 通过增加显存使用的方式解决通信瓶颈.
显存消耗: ZeRO3的单卡显存消耗为\(\frac{(2+2+K)*\Phi}{N}\), 这里每个节点多存了一份W, 如果有\(\alpha\)个物理节点, 那么每张卡使用的显存就多了 \(\frac{\alpha * \Phi}{N}\)
梯度量化
如果直接在之前zero RingAllReduce的通信方式上加量化和反量化, 如下图左, 可以看到需要节点个数次量化/反量化. 而每次量化都是有损的, 这样会导致无法接受的训练误差. 为了解决这个问题zero++使用了一次量化->AllToAll通信->一次反量化的操作. 而因为直接进行AllToAll通信量从\(M\)(参数量)变成了\(\frac{M*N}{Z}\)(N: 节点数, Z:量化压缩率), 这个通信量的增长过大. deepspeed设计了2-hpop all-to-all方法来解决通信问题.
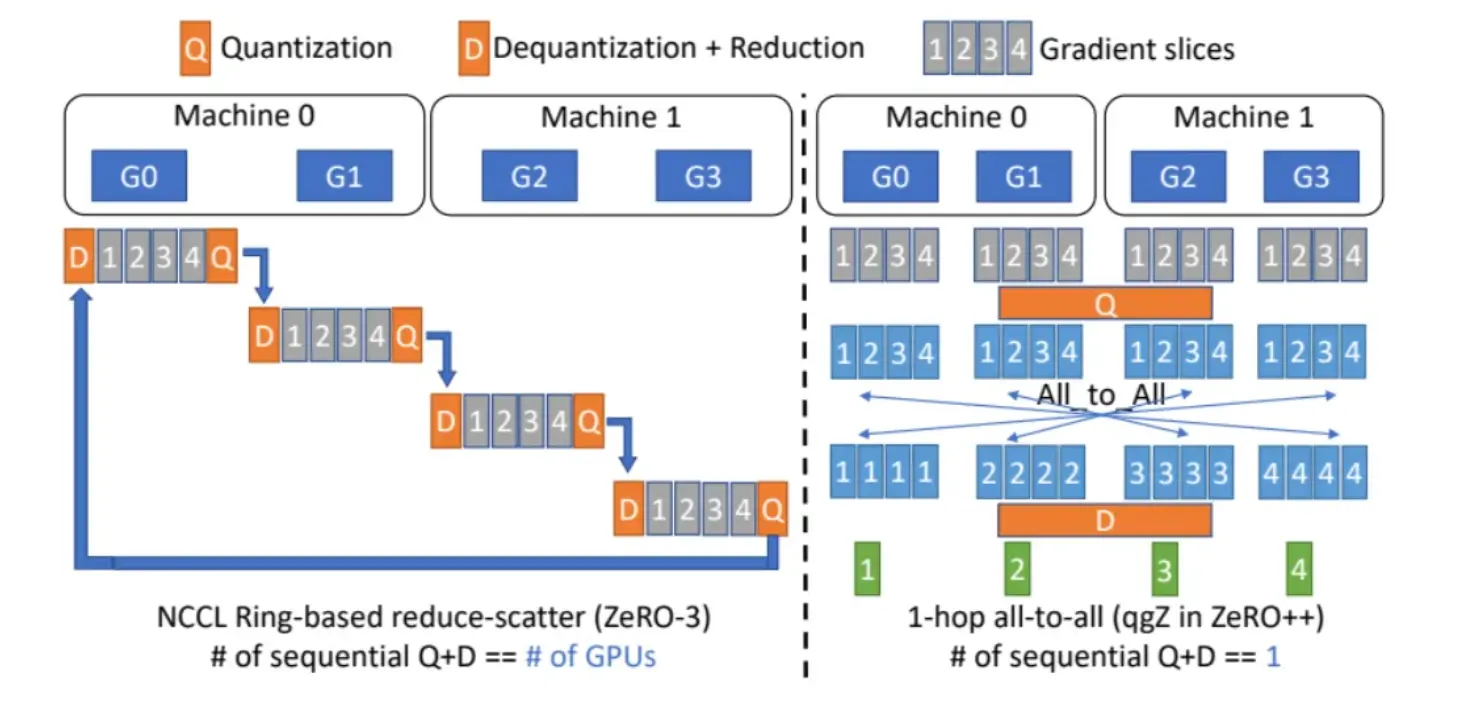
具体图示流程可以参考Deepspeed的blog动态图, 文字版步骤:
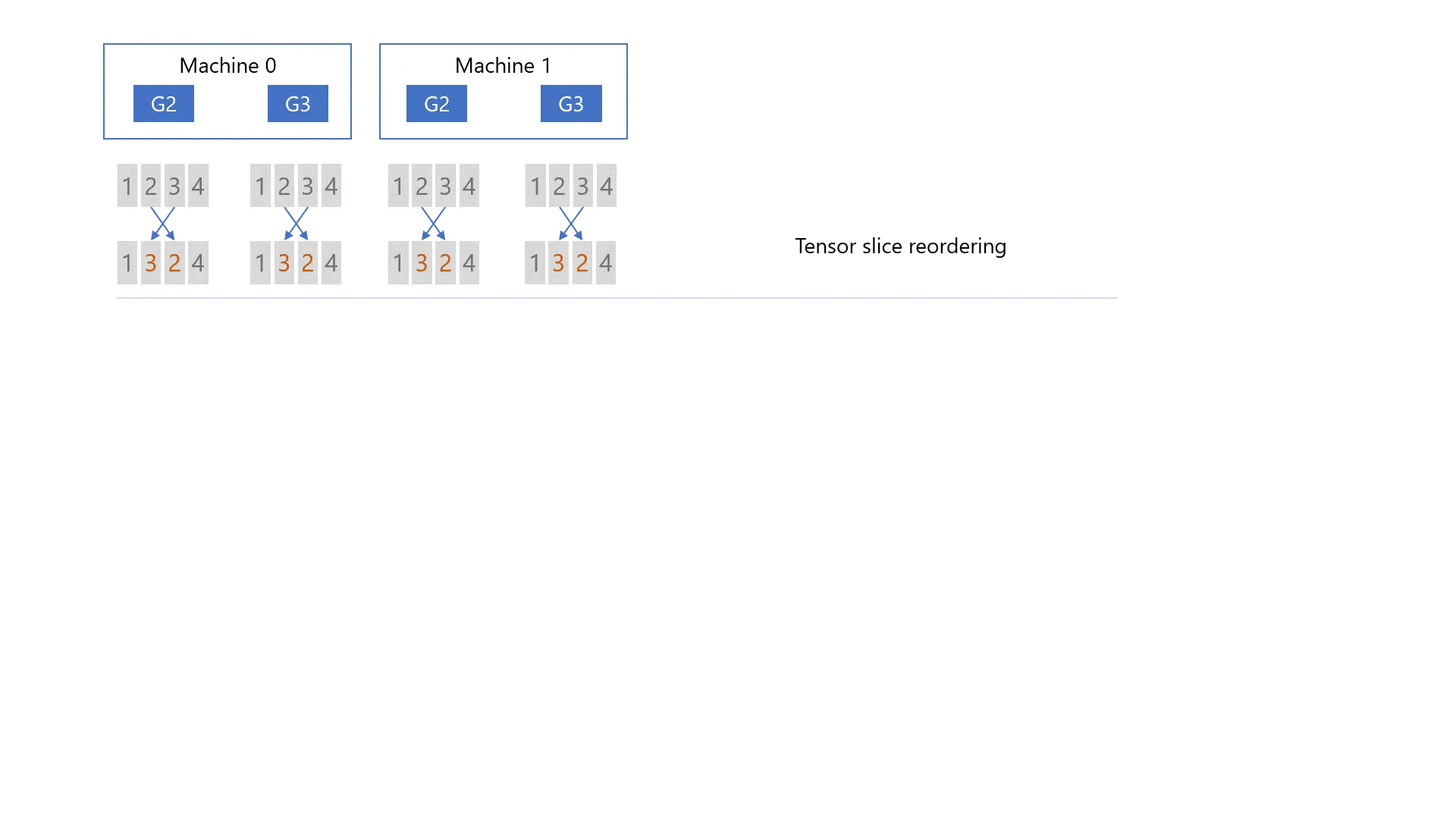
节点内的卡间张量切片重排. 主要是因为alltoall切分成了两步, 如果不重排如下图左. 最后顺序会变错位, 然后进行参数量化
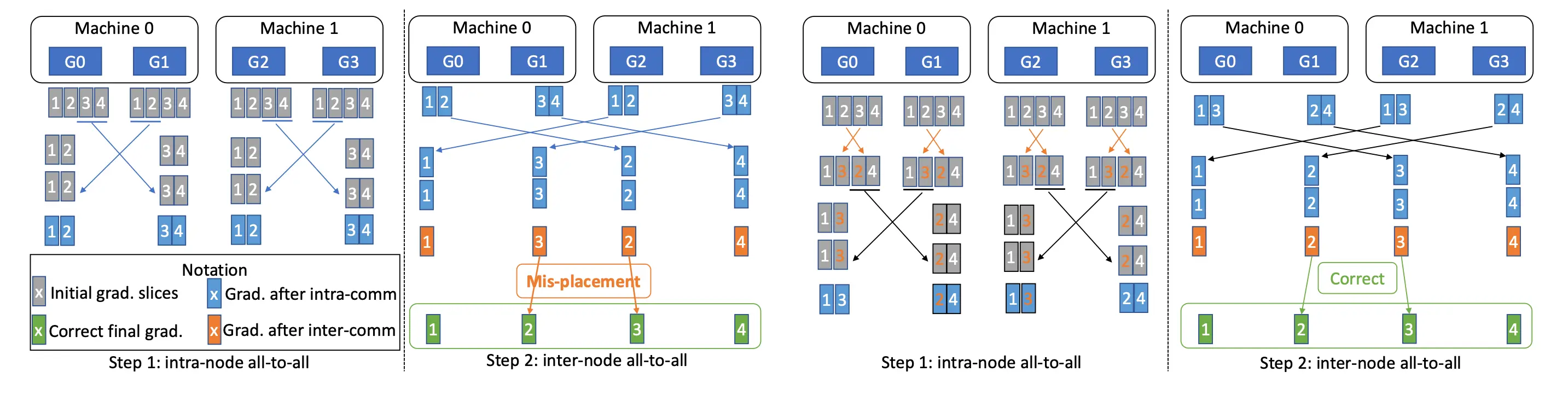
再次量化后, 节点间进行allToAll
拿到通信结果, 反量化后再次reduce. 得到最终的梯度.
这里要进行两次alltoall的原因主要是, 第一次卡间alltoall之后梯度累加可以减少卡数倍的通信规模. 实际deepspeed在实现的时候还把重分片和量化kernel进行了fuse, 进一步优化性能
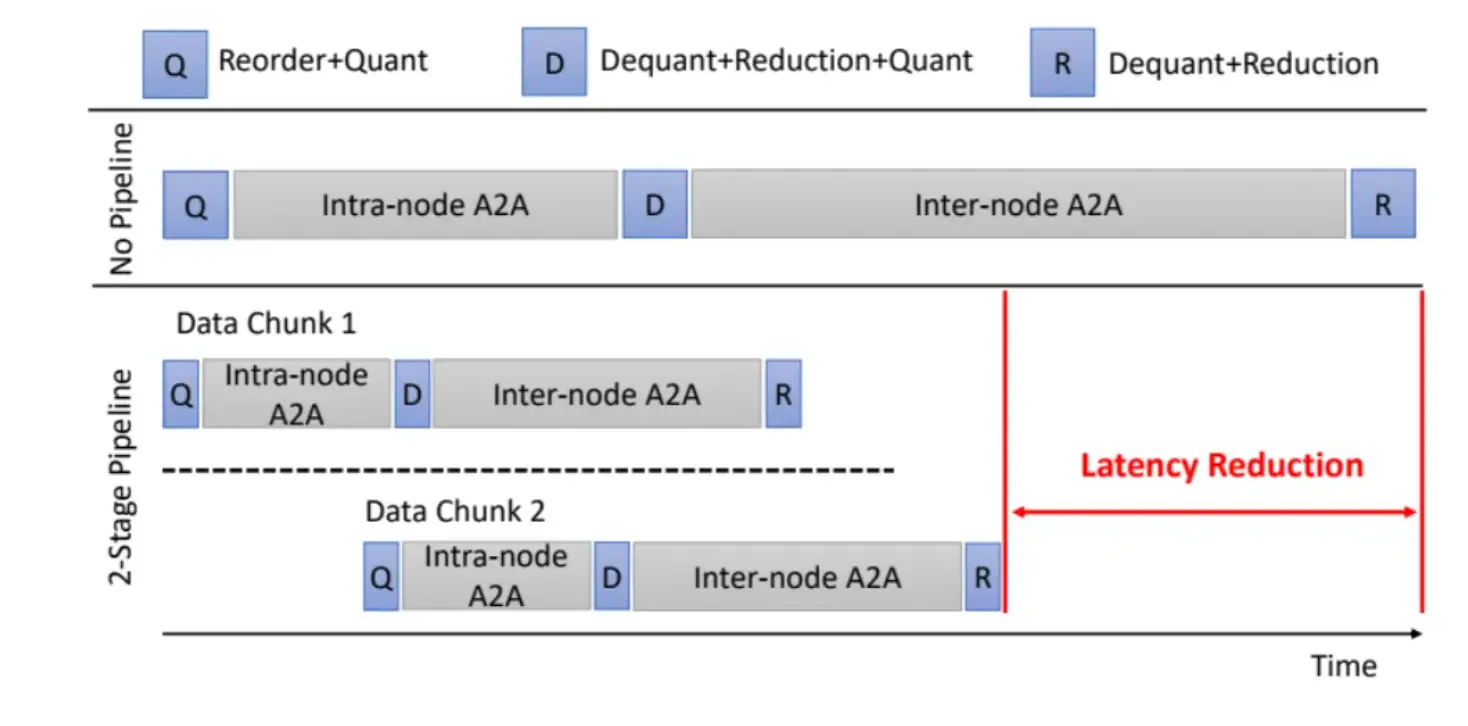
还有下图的方法, 在通信当前层的时候, 通过多流异步量化下一层要通信的数据. 避免同步等待的浪费
参考
zero: https://arxiv.org/pdf/1910.02054
混合精度训练: https://arxiv.org/pdf/1710.03740
zero++: https://arxiv.org/abs/2306.10209
Deepspeed blog: https://github.com/microsoft/DeepSpeed/blob/master/blogs/zeropp/chinese/README.md
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。