DRAM组件级故障预测模型,如何提升系统可靠性?-2
古猫先生 2024-10-12 11:31:05 阅读 80
一、DRAM原理与可靠性
在深入探讨DRAM系统的可靠性问题前,我们需要明确几个基本概念。首先,故障指的是可能导致系统错误的物理缺陷,而错误则是系统实际状态与期望状态之间的差异。故障可分为暂时性故障和永久性故障:前者由外部因素如高能粒子撞击引发,后者则由持续存在的物理缺陷造成。当系统无法正常提供服务时,则视为发生故障。在错误控制中,若错误可检测但无法纠正,即为可检测不可纠正错误(DUE),而错误被误修正或未被发现时,可能导致静默数据损坏(SDC)。系统的可靠性是指在没有故障发生的情况下持续提供服务的能力,通常以故障间隔时间(FIT)衡量,即每十亿小时操作中发生一次故障。
为了确保数据完整性,DRAM子系统设计中融入了多项可靠性特性,其中最关键的一项便是错误检查与纠正(ECC)机制。ECC通过在数据旁存储冗余校验位来检测和纠正读取DRAM时发生的错误。ECC机制依据其纠正错误类型的不同进行分类,例如,单比特错误纠正(SEC)ECC只能纠正单比特错误,而单符号纠正(SSC)ECC则能纠正单一多比特符号内的多个错误。若单个符号覆盖整个DRAM设备,这就被称为单设备数据纠正(SDDC),ChipKill ECC即属于此类ECC。比特错误常用BCH码纠正,符号错误则常采用里德-所罗门(RS)码。ECC还可以根据编码解码器的位置分类,如行列级ECC使用冗余芯片在内存控制器处操作,而片上ECC则在DRAM芯片内的存储体使用冗余存储单元进行操作。
更多细节参考:数据中心内存RAS技术全景剖析
为预防瞬态故障导致不可纠正错误,DRAM子系统会定期读取每个存储位置进行错误检测和纠正,这一过程称为刷新(scrubbing)。
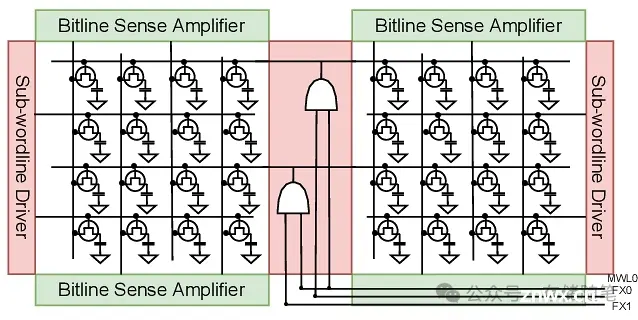
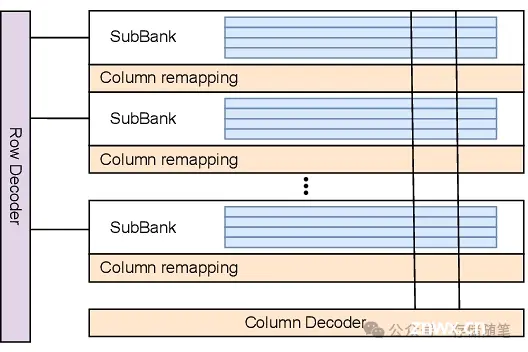
DRAM结构方面,它由多个层级组成,最底层是DRAM单元,单元组成矩阵(mat),矩阵内的单元按列和行排列,同一列的单元通过位线连接到一个位线感知放大器(BLSA)。每个矩阵由行选择器(SWD)通过子字线控制。矩阵被组织成更大的数组单元,即子阵列,多个子阵列构成一个存储体(bank),而一个DRAM设备包含多个存储体。这些存储体共享外部连接通道,但各自独立控制,以便并发执行DRAM指令,隐藏单个指令的长延迟。每个存储体有自己的解码器和互连电路,行解码器分为多个层次,先选择子存储体、再选子阵列,最后选择SWD。数据最终通过列选择器和全局位线传输到DRAM设备的数据引脚(DQs)上。
列重映射Column Remapping)是一种故障避免机制,允许系统在检测到某个特定列存在错误时,将其逻辑地址映射到预先预留的备用列上。这样,即便某些物理列不可用,也不会影响到整个存储体的功能。
列重映射机制能够绕过硬件故障,避免由此导致的数据丢失或错误,提升了DRAM的整体可靠性。
在制造过程中,每个DRAM芯片都可能含有少量的缺陷。通过列重映射,即使有少数列无法使用,芯片仍可正常工作,从而提高了产品的良品率和利用率。
不同设计中的列解码器和矩阵配置各异,但现代标准如DDR5、LPDDR5和HBM3都定义了特定的DQs与矩阵的对应关系,以及列解码的实现方式。这些细节对于理解和优化DRAM系统的可靠性至关重要。
二、内存故障公开数据集分析
为了构建组件级DRAM故障模型,研究团队对错误日志进行了深入分析,目的是将与每个DRAM模块相关的错误事件映射到其根本的组件级故障。通过识别所有受影响地址的错误模式,并基于最有可能产生该模式的组件故障对其进行分类,如单比特故障、位线感知放大器(BLSA)故障、子字线驱动器(SWD)故障等。通过决策树分类器,能够对99%的报告错误的行列进行分类,并基于影响的列、行、Bank、行列、模块数量,错误地址间的距离,以及是否报告了明确的故障进行判断。

Cell故障是最常见的故障类型,因为DRAM设备中包含数十亿个存储单元。这种故障通常表现为DIMM错误模式中的唯一地址,或是少量完全不相关的地址(1-4个),这些地址在行、列乃至Bank上都不同。这类单比特错误分别占供应商A、B、C所有故障的85%、45%和47%。
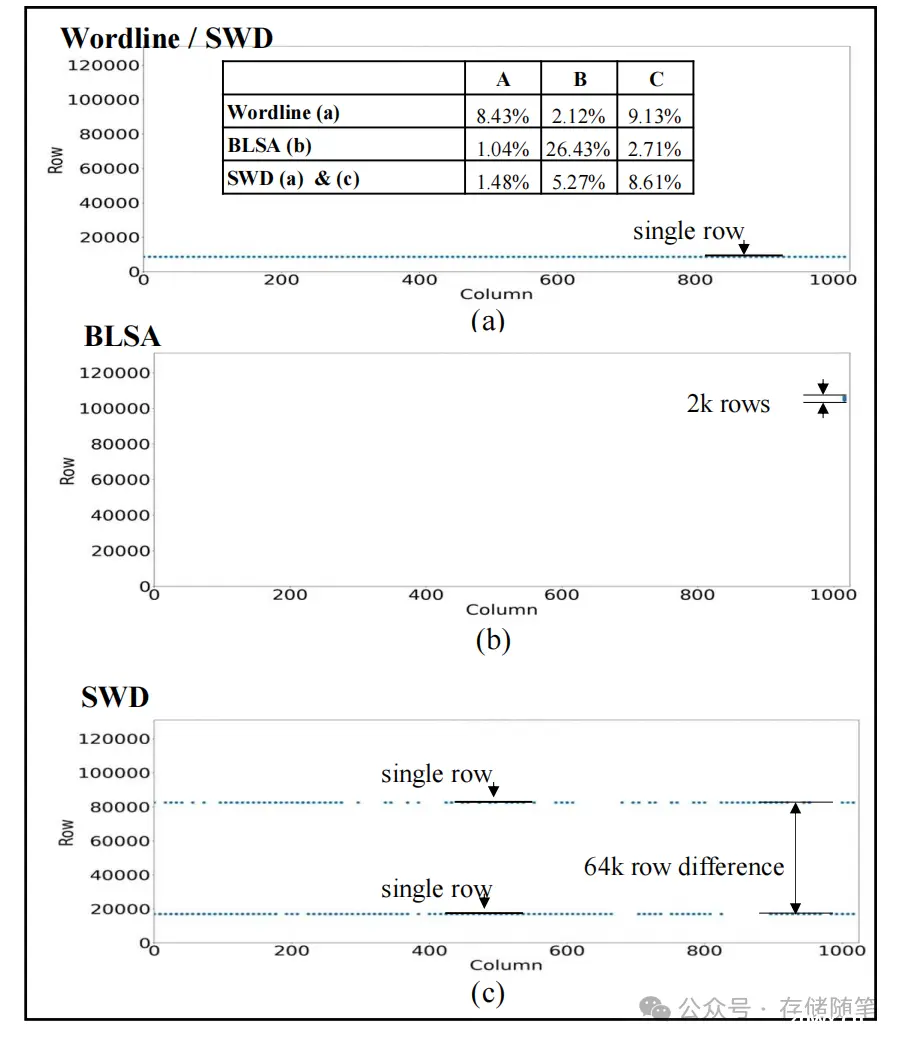
子字线故障影响单个mat中的单行,错误模式表现为单逻辑行地址中的多列错误,影响单个DQ。
位线感知放大器(BLSA)故障影响垂直相邻两个mat的同一列,错误模式体现为限定行地址范围内的单列跨多行错误,与常见mat尺寸相匹配,同样影响单个DQ。
子字线驱动器(SWD)故障影响同一子阵列内两个水平相邻mat的同一行地址。若SWD关联的两个mat属于同一逻辑子阵列,则影响单个逻辑行地址和两个DQ;若跨越两个逻辑子阵列,则影响两个逻辑行地址,且每逻辑行影响单个DQ。

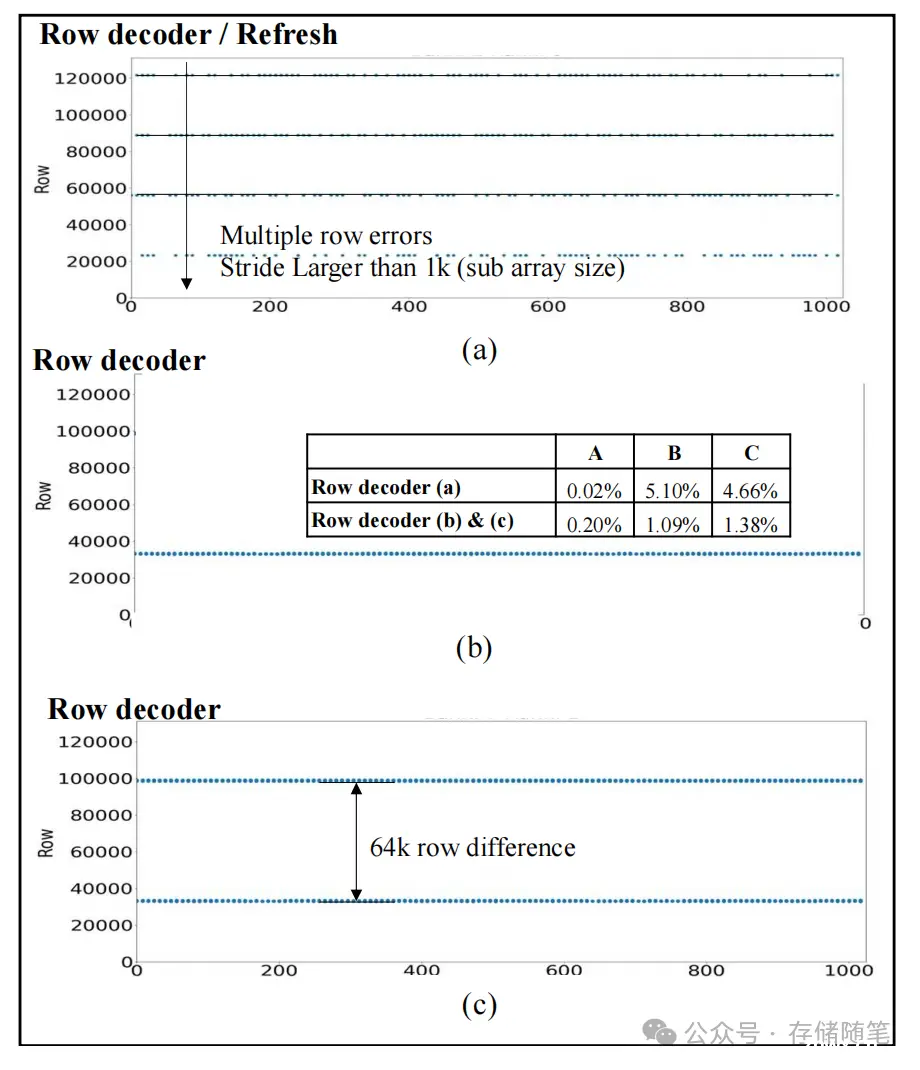
行解码器故障能导致单行、两行半页距离错误、行簇错误等多种模式,影响所有mat和所有4个DQ,且通常会导致故障。行解码器故障涉及一个多层次的解码过程,不同的故障级别会导致不同的错误模式。局部(子阵列级别)解码器负责解码主字线(MWL),并将其前解码的信号转发给各个mat。当解码器或MWL出现故障时,可能会引发以下几种错误模式:
单一行的错误;
两行错误,其间距为半个页面(64K行);
行簇错误;
两组行簇错误,每组间也是半个页面的间距。
上述任何一种情况下,故障都会影响到子阵列内的所有mat,因此影响所有4个DQ。鉴于此,这类故障很可能会导致系统失效。通过分析,约3%的单行故障导致了失效,这些被归因于行解码器故障,而其余单行故障则归咎于字线(wordline)或子字线驱动器(SWD)故障。
另外,还有一种相关的故障,它并非直接作用于MWL或解码器,而是影响到发送到子阵列的预解码位与一组SWD之间的连接。在这种情况下,物理子阵列中相邻两个mat的SWD集群出现故障。这会导致错误模式横跨一或两个行簇,具体取决于这两个受影响的mat是否位于同一个逻辑子阵列中。影响单个簇的行解码器故障会涉及到2个DQ,而影响两个簇的故障则影响单个DQ。观察发现,这类错误模式约有一半涉及两个1K行簇,另一半只涉及一个簇。利用这一特点,可以区分单行SWD故障和字线故障。同时,发现这类SWD连接故障在数据集中不会导致失效,因此将约12%的1K簇模式归因于上述MWL故障,其余归因于SWD连接故障。总体而言,这种簇状模式在供应商A、B、C中分别占比约为0.6%、0.4%、1.2%。
多列错误模式1和2(上图a/b):这些模式展示了一至两个大约16K行大小的簇,沿着单个缓存行粒度的列地址分布。这种模式下的故障很少导致系统失效,因此归因于单个子bank内部的列选择线(CSL)故障或靠近一列mat的两个CSL信号发生翻转的解码器故障。无论哪一种情况,这类故障都会影响单个DQ。虽然这两种情况在分析中未做区分,但导致两列错误的那种情况,按照以往模型会被分类为Bank级错误。
多列错误模式3(上图c):该模式包括两个簇,它们之间相隔半个页面的距离(64K行)。这类错误被归因于列解码逻辑的故障,这种故障错误地映射了一或两列,并影响了子bank内的所有mat。尽管错误模式与CSL故障相似,但预期这类解码器故障会导致失败。观察到约9%的此类模式最终导致了故障,这部分被归因于解码器故障。
多列错误模式4(上图d):与模式3类似,但导致失败的比例更高,约为40%。这同样归因于列解码逻辑的故障,但由于其更频繁地导致系统失效,因此强调了解码器故障在这类模式中的重要性。
通过这些多列错误模式的分析,我们可以看到,不同类型的列解码器或CSL故障如何在物理层面影响DRAM芯片的运行,并如何通过特定的错误模式表现出来。这些模式对于诊断和理解DRAM故障的根源至关重要,同时也帮助设计更有效的错误检测与校正机制,从而提高系统的整体可靠性。
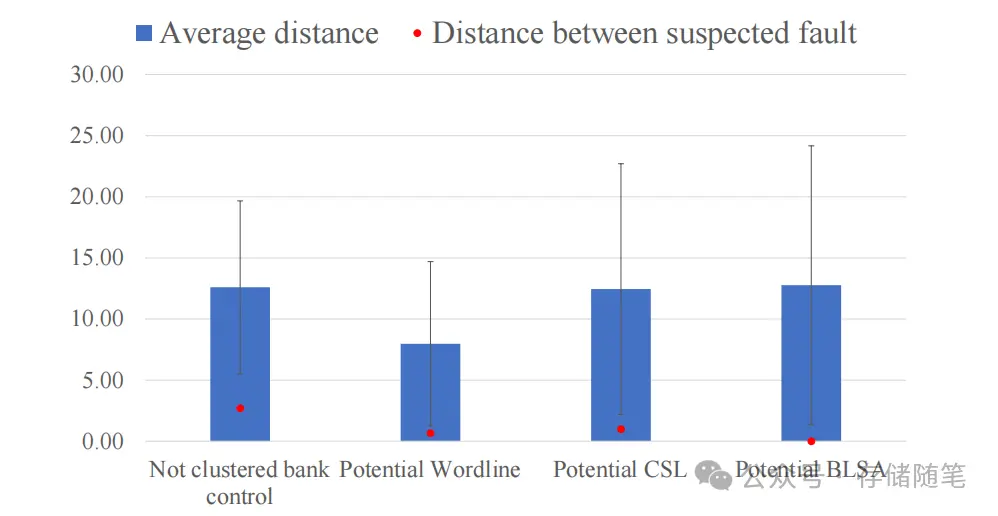
上图是关于DRAM故障类型诊断的统计图表,它通过总变分距离(Total Variational Distance, TVD)来评估疑似错误故障与所有可能故障类别之间的相似性或差异性。TVD是一种衡量两个概率分布之间差异的方法,值越小表示两个分布越接近,反之则差异越大。在这里,TVD被用来量化疑似故障原因与实际可能的故障源之间的匹配程度。
条形本身:表示所有可能故障类别相对于疑似故障的TVD平均值。一个较低的条形高度意味着疑似故障与某些故障类型的平均距离较小,暗示着较高的匹配可能性。
垂直线:代表一个标准差,它反映了数据的离散程度。如果垂直线较短,说明数据较为集中,意味着TVD值相对稳定;反之,如果垂直线较长,则说明数据分散,TVD值波动较大。
红色圆点:表示针对疑似故障根本原因计算出的具体TVD值。这个点相对于条形的位置非常关键。如果红点位于条形的底部附近,表明疑似故障与计算出的最可能故障类别非常吻合,几乎确认了该疑似故障的原因。相反,如果红点远离条形底部,位于较高位置,这可能意味着当前的疑似原因并不准确,需要重新考虑或进一步调查。
在深入分析内存错误及其成因的过程中,我们发现了诸多新的见解,其中特别引人注目的是由解码器故障引发错误的相对普遍性。以往的研究通常从逻辑层面来描述故障,简单地将解码器故障归类为Bank级错误。然而,解码器故障的影响更为微妙,对于依赖On-Die ECC保护的系统来说,这一点尤为关键。
过往的特性分析主要集中在DDR DRAM通道上,其中访问操作会跨越整个rank中的多个设备。解码器故障仅影响单个设备,因此仅从该设备读取的数据会出现错误。在这种情况下,强大的纠错码(如RS码)能够轻易检测并修正这些错误。
然而,当ECC集成在芯片上时,所有数据及其冗余信息均源自单一的子阵列。一旦解码器出现错误,将导致整个纠错码词(包括数据和冗余信息)从错误位置读取。尽管片上ECC仍然接收到一个看似有效的码词,但从软件角度来看,数据实际上是错误的,从而导致严重的单比特纠正错误(SDC)失效。相比之下,如果我们把这些解码器故障视为Bank级错误,最可能的ECC结果将是检测到双比特不确定错误(DUE)。
为了提升系统可靠性,我们提议通过将行地址和列地址纳入ECC码词中,将解码器错误引起的SDC转换为可检测的DUE,从而避免此类问题。我们借鉴了All-Inclusive (AI) ECC扩展数据ECC的方法,并对其进行调整以适应片上ECC。具体做法是使用行地址和列地址的异或运算来降低解码器的复杂度,并支持位级别的ECC。编码时,ECC编码器隐式地将行地址和列地址与数据一起作为编码消息的一部分。数据和地址共同生成片上冗余位,但只有数据和冗余信息被存储在内存中。读取时,从读命令中再次获取地址并加入从内存中检索到的码词中,ECC解码器尝试纠正任何错误。如果检测到错误或尝试对隐含附加的地址信息进行纠正,即报告DUE。
此方法以极高的概率检测解码器错误,有效避免了数据在无明显迹象的情况下被悄悄破坏,而且无需额外的冗余存储或昂贵的冗余解码器。我们的评估结果显示,通过地址保护措施显著降低了LPDDR5等内存技术的预期SDC发生率,改善程度达到数个数量级。
三、内存故障模拟器
故障与错误模拟器是一种高级工具,它通过精确模拟DRAM组件级的故障及其导致的错误,来预测现代及未来DRAM系统中操作性故障和内在故障的影响。相较于先前仅依据逻辑分类的模拟器,该模拟器更进一步,考虑了源于物理组件的重要相关性和界限,从而提供更为精准的故障分析。
精细的故障模拟:模拟器采用蒙特卡洛方法,对代表性的内存通道(例如DDR5的一个rank)进行故障注入实验,直至通道出现故障或模拟运行满五年(内存预期寿命)。这一过程中,即使出现仅能被纠正的错误,故障注入也会持续,以便评估由故障重叠导致的失败率。
高级可靠性评估:与仅理论验证错误纠正能力的模拟器不同,本模拟器通过额外的嵌套蒙特卡洛试验,对由注入故障产生的实际错误模式进行分析,并执行错误纠正码(ECC)来精确评估可靠性。这种方法尤其适用于模拟工艺尺寸缩放导致的故障影响及精确估计单比特纠正错误(SDC)率。
故障模型与组件级分析:模拟器依据组件级别的实证模型构建故障模型,并根据所评估的不同内存技术进行了调整。例如,它区分了与解码器相关的故障,避免了高估两行或矩阵级故障与其他故障间的潜在重叠,因为模型并未将这些故障归类为“bank”级。
内存技术的扩展:为了将基准DDR4设备的故障模型扩展到32Gb × 4 DDR5、×16 LPDDR5和HBM3,采用了两种方法。一种是保持每设备总的故障率不变,根据新内存技术中各组件数量与DDR4相比的变化来调整故障频率。另一种是直接从DDR4设备推导每个组件的故障率,再基于相同组件数量的增减,为新内存技术生成具有更高总故障率的模型。

ECC方案对比:针对不同内存技术,模拟器评估了多种ECC方案的可靠性,包括DDR5的SEC(136,128)片上ECC、HBM3的RS16(19,17)及简化版等,并考察了提出的地址保护机制对这些方案性能的影响。对于LPDDR5,尽管没有公开的片上ECC信息,但基于其访问粒度与HBM3相似,模拟器也评估了RS8(36,32)代码的可靠性,该代码具有12.5%的冗余度。
总之,该故障与错误模拟器通过精细的组件级分析和高级的可靠性评估方法,为DRAM系统的设计和优化提供了强大的支持,特别是在预测故障行为、评估ECC策略的有效性以及推动内存系统可靠性提升方面展现出巨大价值。
通过模拟含有DDR4内存的服务器系统,研究者验证了数据集中机器主要使用的ECC方案并非Chipkill级别。
模拟结果显示,如果使用Chipkill级别的ECC,八个月内预计的故障数少于10次(接近1次),而数据集中观察到541次故障,因此可以排除Chipkill ECC的可能性。
相反,当模拟较弱的ECC(只能纠正2-DQ错误)时,预测的故障数为870次,接近观测值,考虑到研究系统中采取了Page-offline和DIMM替换措施以降低故障风险,这一预测更为合理。此外,由于缺乏DQ级错误报告的限制,研究者通过比较不同假设下的模拟结果来进一步验证模型,发现模型在细粒度故障分析上具有优势。
开源的模拟器和模型:https://github.com/lpharch/DRAM_FAULT_SIM
参考文献: https://dl.acm.org/doi/fullHtml/10.1145/3613424.3614294
如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
当CXL遇到NVMe,计算存储会发生什么?
浅析SSD性能与NAND速率的关联
浅析SSD性能与NAND速率的关联
浅析MPS对PCIe系统稳定性的影响
DPU:值不值得托付下一代存储加速架构?
论文解读|数据中心内存RAS技术全景剖析
硬盘HDD:AI时代的战略金矿?
断电的固态硬盘数据能放多久?
CXL-GPU: 全球首款实现百ns以内的低延迟CXL解决方案
万字长文|下一代系统内存数据加速接口SDXI解读
数据中心:AI范式下的内存挑战与机遇
WDC西部数据闪存业务救赎之路,会成功吗?
属于PCIe 7.0的那道光来了~
深度剖析:AI存储架构的挑战与解决方案
浅析英伟达GPU NCCL P2P与共享内存
3D NAND原厂:哪家芯片存储效率更高?
大厂阿里、字节、腾讯都在关注这个事情!
磁带存储:“不老的传说”依然在继续
浅析3D NAND多层架构的可靠性问题
SSD LDPC软错误探测方案解读
关于SSD LDPC纠错能力的基础探究
存储系统如何规避数据静默错误?
PCIe P2P DMA全景解读
深度解读NVMe计算存储协议
浅析不同NAND架构的差异与影响
SSD基础架构与NAND IO并发问题探讨
字节跳动ZNS SSD应用案例解析
CXL崛起:2024启航,2025年开启新时代
NVMe SSD:ZNS与FDP对决,你选谁?
浅析PCI配置空间
浅析PCIe系统性能
存储随笔《NVMe专题》大合集及PDF版正式发布!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。