【LLM】在PAI-DSW上使用 vLLM + Open-WebUI 部署Qwen2.5
Ethan__Lee 2024-10-07 14:33:01 阅读 81
最近在玩LLM,听闻PAI-DSW有三个月免费试用,试了一下感觉还不错,就是有一些学习成本。刚通过vllm+open-webui成功部署了Qwen2.5-7B-Instruct,也是摸索了一段时间,记录一下以便需要使用同样方案的朋友们节省时间,迅速上手。
简便起见,本文所有安装均使用pip工具,不使用docker。
总体思路
从modelscope下载模型,运行vllm serve构建服务器,然后通过Open-WebUI连接并开始对话。
PAI-DSW部署的难点
主要有两个:
不是本机,没法方便地科学上网。特别是无法直连hugging face;镜像不能完全涵盖所需要的环境。不是本机,不能直接用浏览器打开localhost(即0.0.0.0)
展开说一下第二点:vllm需要cuda 12以上才能使用,11.8会提示过旧;open-webui需要使用python 3.11才可以使用pip安装。然而,PAI-DSW的镜像中要么是py310+cu121,要么是py311+cu118,欲哭无泪。最后建议大家选择py310+cu121的方案,我们可以通过安装Anaconda,使用虚拟环境来部署Open-WebUI。
对于第三点,原来我以为是不能直接打开的,还专门用了cpolar做透传,结果发现阿里已经想到这一点了,直接点击终端里的链接就能访问,太贴心了。
具体安装流程
模型下载
这里建议通过modelscope下载,非常快,平均速度在300MB/s左右。
自动下载(略)
据我所知,你可以直接使用vllm通过modelscope下载模型,如果默认用的是hugging face可以通过在终端输入
<code>export VLLM_USE_MODELSCOPE=True
然后运行vllm serve,输入模型地址即可下载。但是我在vllm v0.6.1.post2没有成功,故采取手动下载方式,这样其实也不错,不麻烦。
手动下载(推荐)
首先安装modelscope包。由于DSW是有预装的镜像文件的,故建议使用裸python环境进行配置,省去配置的时间。
pip install -U modelscope
然后在modelscope上打开你要下载的模型,这里以Qwen2.5-7B-Instruct为例。点击右上角的下载模型,向下滑动到命令行下载界面,你会看到
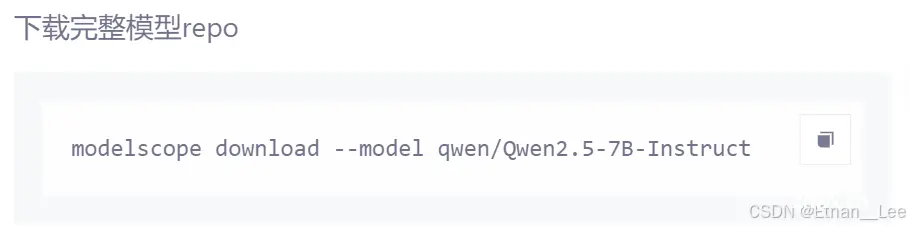
此时你可以复制并运行这条语句,然后服务器就会猛猛下载。当然,如果你想指定下载路径,可以添加–local_dir参数,例如:此时你可以复制并运行这条语句,然后服务器就会猛猛下载。当然,如果你想指定下载路径,可以添加–local_dir参数,例如:
<code>modelscope download --model qwen/Qwen2.5-7B-Instruct --local_dir /mnt/workspace/models/Qwen2.5
你可以输入
modelscope download --help
以查看更多参数。
Vllm部署
一样使用pip进行安装
pip install -U vllm
这次可能有点久,等待安装完成后,输入如下命令,观察是否正常运行:这次可能有点久,等待安装完成后,输入如下命令,观察是否正常运行(注意修改模型路径):
vllm serve YOUR/PATH/TO/MODEL --dtype auto --api-key token-abc123
如果出现报错

则说明模型长度过长(32768),通过指定–max-model-len(<=18656)来指定长度,命令如下。
<code>vllm serve models/Qwen2.5-7B-Instruct/ --dtype auto --api-key token-abc123 --max-model-len 8192
随后,我们运行如下命令,观察openai api是否启动成功。openai api是Open-WebUI所需要使用的工具。
curl http://localhost:8000/v1/models -H "Authorization: Bearer token-abc123" | jq
若显示“jq:未找到命令”,则使用apt install安装,然后再次运行指令。如果观察到输出
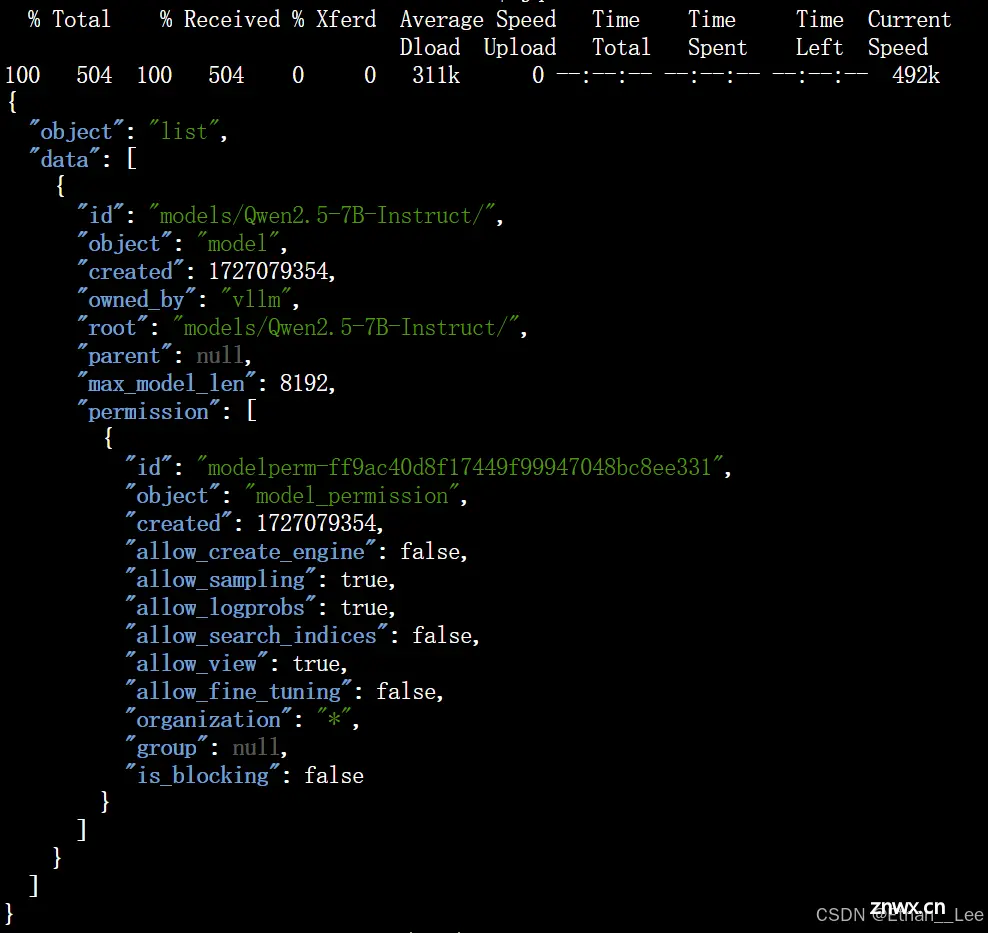
则说明服务启动成功。我们进行下一步。
(这里做个解释,通过打印输出auth_headers即可得到{‘Authorization’: ‘Bearer token-abc123’},Bearer是不变的,后面的token根据你的参数设置而改变。)
Open-WebUI部署
安装Anaconda
首先,上Anaconda官方仓库下载符合你设备的安装工具,这里我使用的是https://repo.anaconda.com/archive/Anaconda3-2024.06-1-Linux-x86_64.sh。然后上终端,使用wget下载:
<code>wget https://repo.anaconda.com/archive/Anaconda3-2024.06-1-Linux-x86_64.sh
添加操作权限并运行
chmod +x Anaconda3-2024.06-1-Linux-x86_64.sh
./Anaconda3-2024.06-1-Linux-x86_64.sh
随后按照安装提示进行安装即可(建议同意conda init)。
创建虚拟环境并安装Open-WebUI
前文提到,我们需要创建一个python 3.11的环境:
conda create -n oi python=3.11
确认后回车,等待安装完成,然后激活环境并安装Open-WebUI
conda activate oi
pip install open-webui
等待安装完成,然后运行
open-webui serve
这个时候,不能科学上网的弊端就来了,Hugging face可能会访问超时!由于安装好了,我这里无法提供截图,语言描述一下大致的报错:非常非常长的五颜六色的报错,还有表格之类,输出很多信息,在报错的最底下会显示Network之类的字样,同时给出“huggingface.co"还有403等字样。这就是网络连接出问题了,此时我们需要使用这条语句:
export HF_ENDPOINT=https://hf-mirror.com
用以接入到国内的镜像站。此时再次运行open-webui serve,可以看到开始下载配置,直到出现:用以接入到国内的镜像站。此时再次运行open-webui serve,可以看到开始下载配置,直到出现:
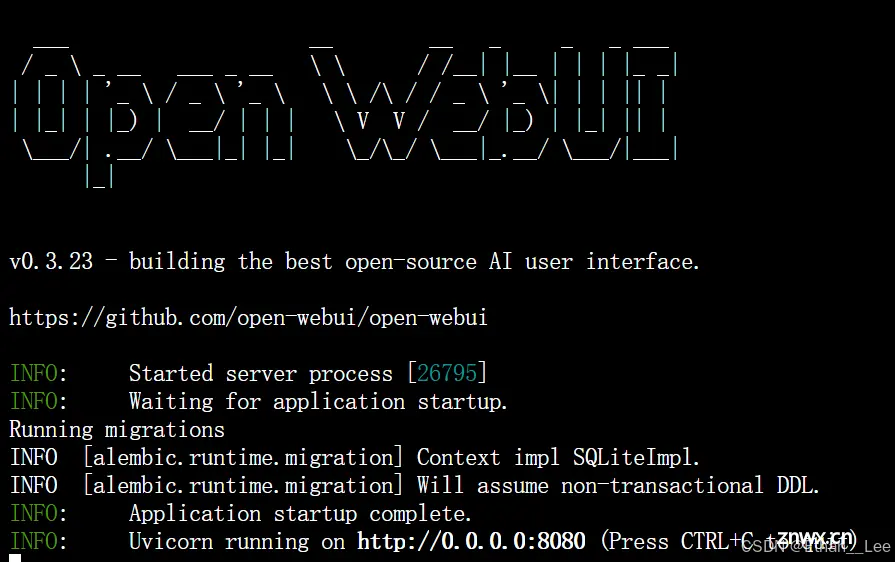
恭喜!你已经完成了大部分工作,距离成功仅有一步之遥!点击输出的链接http://0.0.0.0:8080即可进入open-webui
注册并登录,我们进行最后一步。
获取模型
首先,使用你之前的参数重新运行vllm serve。等待服务完全运行起来后,会周期地进行输出,此时我们回到Open-WebUI,点击右上角头像,选择“管理员面板”,点击左上角的“设置”,然后点击外部连接:
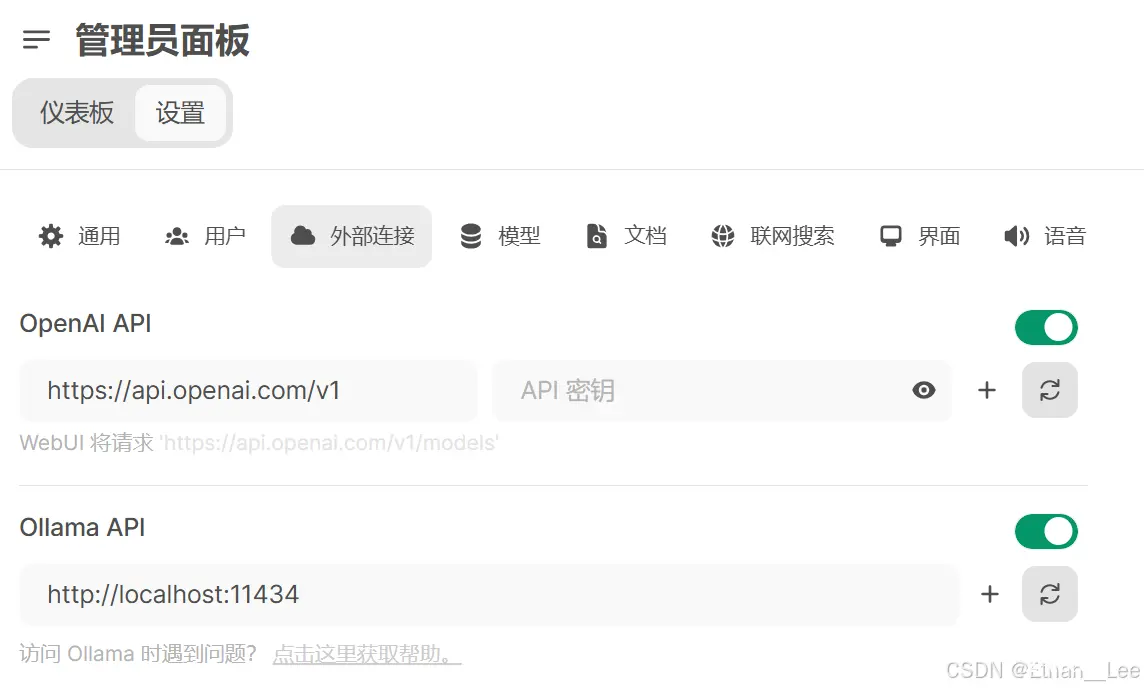
然后将vllm的地址“http://0.0.0.0:8000/v1”替换掉默认的OpenAI API。注意加上“/v1”。输入你所配置的token密钥
因为我们是vllm部署,没有用到ollama,可以将其关闭。
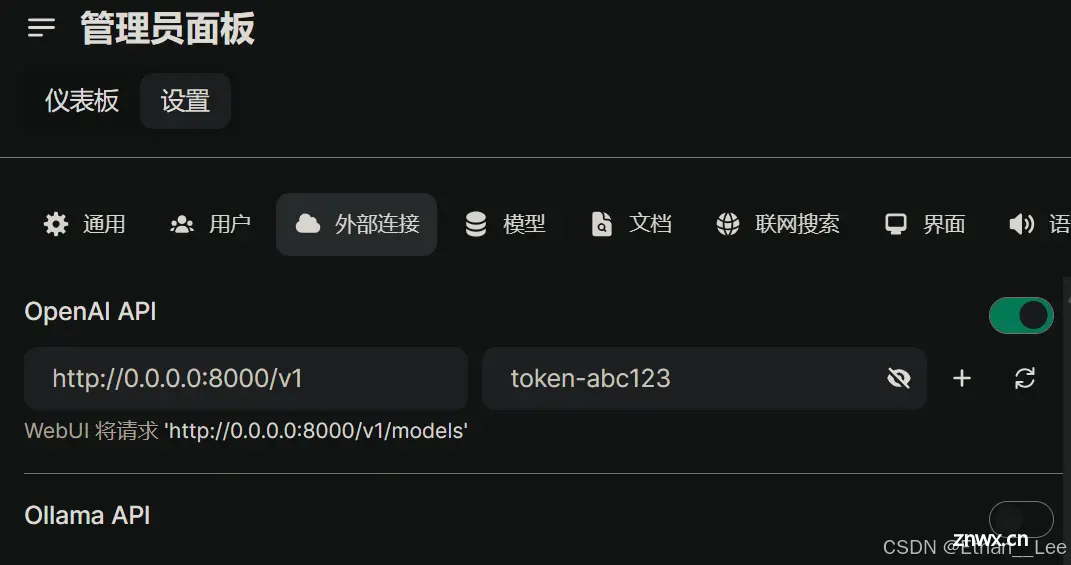
输入完成后,点击右边的刷新按钮测试连接,如果显示已验证服务器连接,则点击右下角保存。 如果显示Network problem,则检查拼写,是否是写了https或打错字。
点击保存后,如果弹出“保存设置成功”一类的字样,那么恭喜你,大功告成!
此时回到主页面,点击左上角选择模型,就应该出现已加载的模型:
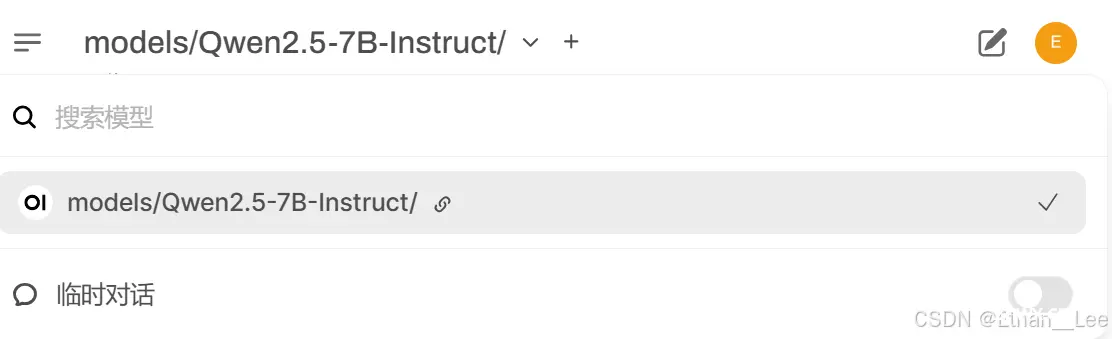
启动,并开始第一次对话!
回到Open-WebUI的主页面,选择模型,然后开始第一次对话!

注意,每次使用模型进行对话前,都需要先启动vllm,然后启动open webui。
愉快地对话吧!
声明
本文内容仅代表作者观点,或转载于其他网站,本站不以此文作为商业用途
如有涉及侵权,请联系本站进行删除
转载本站原创文章,请注明来源及作者。