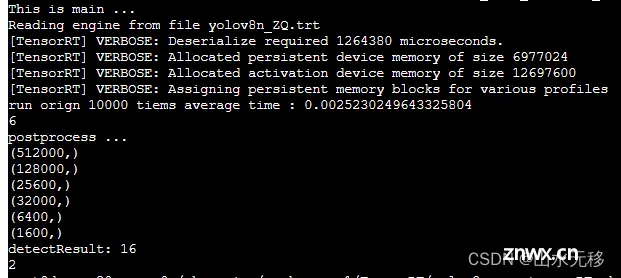
模型和完整仿真测试代码,放在github上参考链接。因为之前写了几篇yolov8模型部署的博文,存在两个问题:部署难度大、模型推理速度慢。该篇解决了这两个问题,且是全网部署难度最小、模型运行速度最快的部署方式。相...

AI大模型的推理过程与优化技术是一个复杂而庞大的体系,涉及多个层面的技术和策略。通过深入研究和实践这些优化技术,我们可以不断提升AI大模型的推理效率和性能,为人工智能的广泛应用奠定坚实的基础。未来,随着技术的不断进...
本文通过docker的方式搭建yolov8运行环境,并成功训练了化学仪器数据集,其中训练数据215张,验证数据65张,类别14。_yolov8docker...

MiniCPM-V2.0,这是MiniCPM系列的多模态版本。MiniCPM-V2.0显示出强⼤的OCR和多模态理解能⼒,在开源模型中的OCRBench上表现出⾊,甚⾄在场景⽂本理解上可以与GeminiPr...

毫无疑问,AI是当下最热的话题之一,而大模型又是当前AI的主角。几年前,正当深度学习进入瓶颈时,以GPT为首的LLM的横空出世让之似乎又找到了“第二增长曲线”。当模型规模大到一定程度时,它所表现出来的涌现能力(Em...
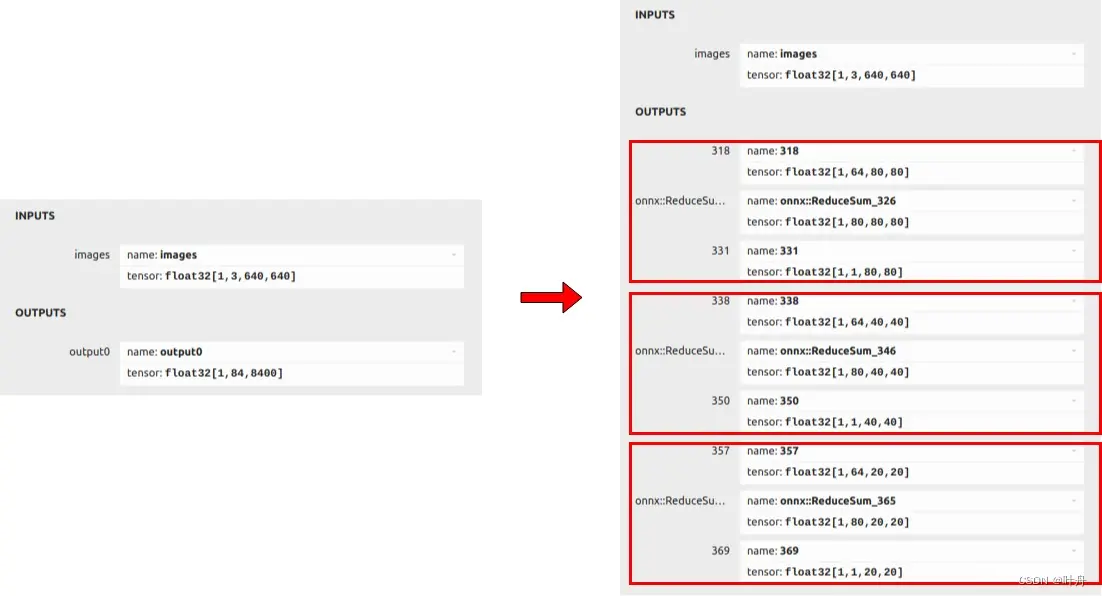
记录了“yolov8的torch模型转onnx再转rknn,并在瑞芯微RK3588上进行推理验证”的过程。_yolov8rknn...
AI模型规模不断剧增已是不争的事实。模型参数增长至百亿、千亿、万亿甚至十万亿,大模型在算力推动下演变为人工智能领域一场新的“军备竞赛”。这种竞赛很大程度推动了人工智能的发展,但随之而来的能耗和端侧部署问题限制了大...

阿里云百炼平台发布推文,提供30天免费算力额度,助力玩转Llama3.1训练推理。老牛同学首当其冲,去体验一把,本文详细记录了整个过程,同时给出了老牛同学的一些想法,欢迎交流学习……...
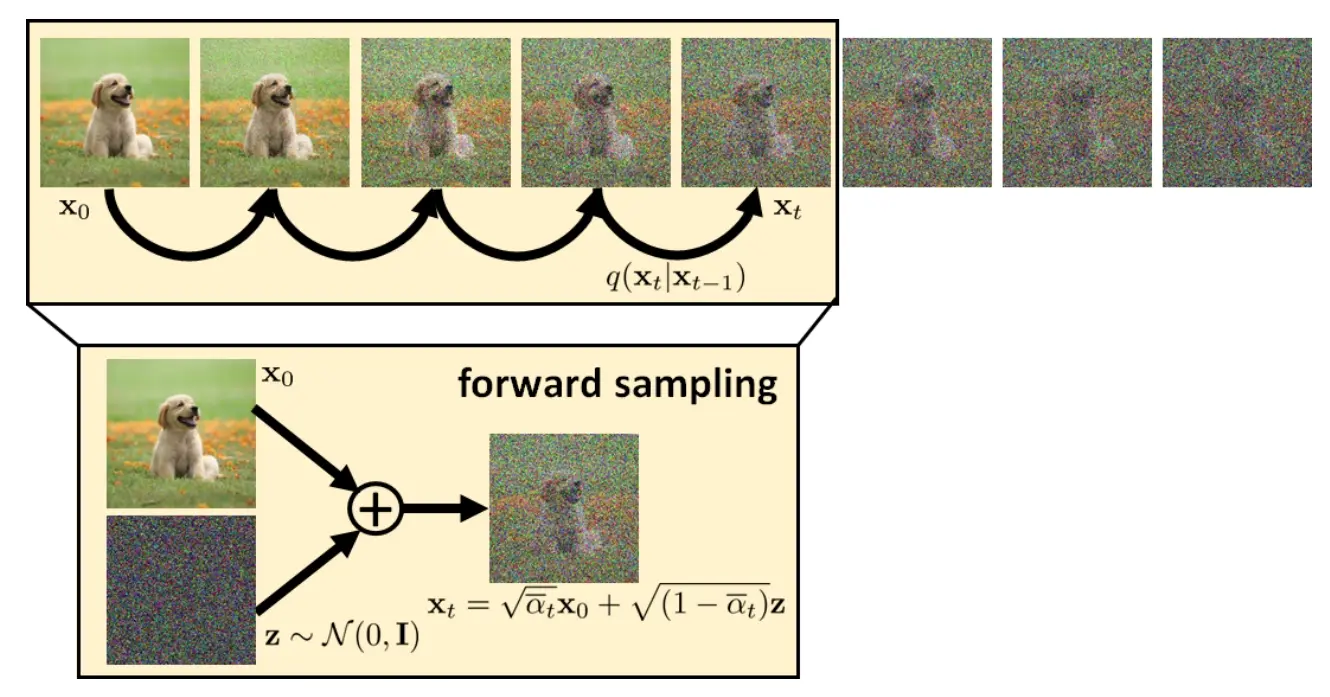
从DDPM到DDIM(三)DDPM的训练与推理前情回顾首先还是回顾一下之前讨论的成果。扩散模型的结构和各个概率模型的意义。下图展示了DDPM的双向马尔可夫模型。其中\(\mathbf{x}_T\)代表纯高斯噪声,\(\mathbf{x}_t,0<...
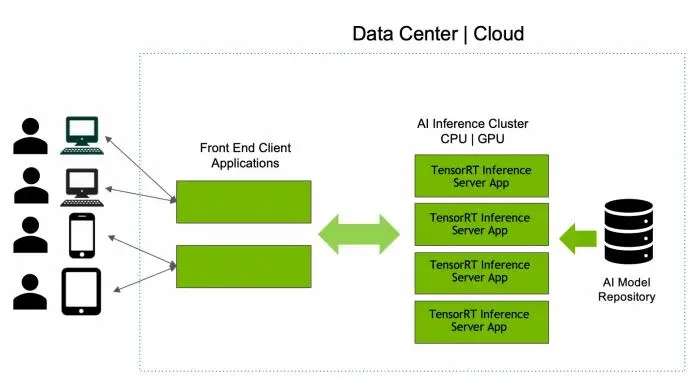
模型库中的每个模型都必须包含⼀个模型配置,该配置提供有关模型的必需和可选信息。)配置,使⽤当前最新的NVIDIA官⽅提供的镜像tritonserver:23.12-trtllm-python-py3,此版本镜像部...