
网络爬虫(WebCrawler),也称为网页蜘蛛(WebSpider)或网页机器人(WebBot),是一种按照既定规则自动浏览网络并提取信息的程序。爬虫的主要用途包括数据采集、网络索引、内容抓取等。robo...
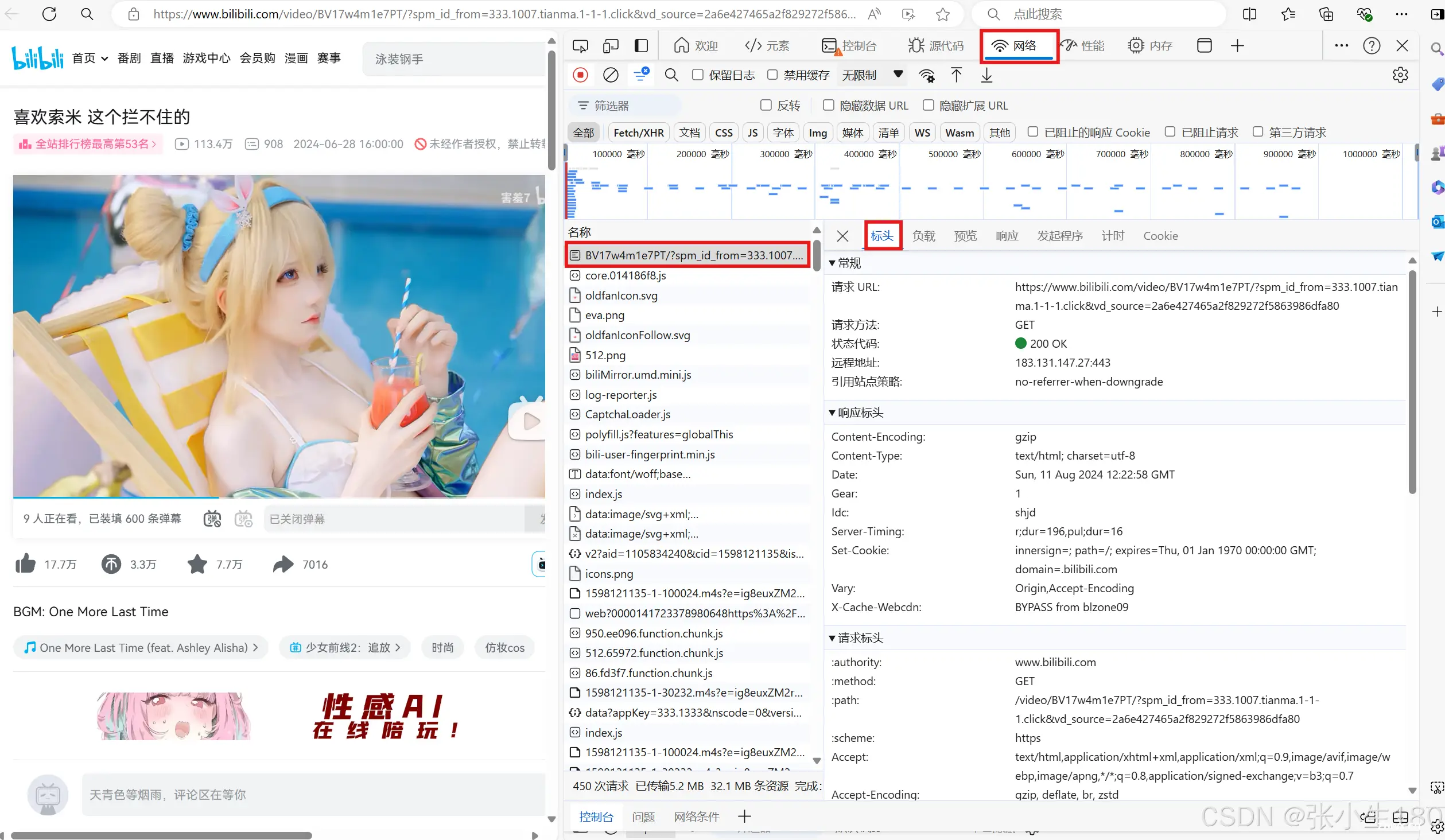
爬取哔哩哔哩中的视频...

本实验数据集来源于房天下官网,通过使用python爬虫获取了长沙市的租房数据获取了房屋租金、交付方式、房屋户型、房屋面积、装修情况、校区、地址、配套设施、房源亮点等字段信息,具体如下图所示。...

DrissionPage是一个基于Python的网页自动化和抓取工具,它通过整合Selenium和Requests的优点,提供了高效、简洁的网页操作和数据抓取解决方案。无论是浏览器自动化控制,还是直接发...
Webbot是一个专为Python设计的库,用于简化网页自动化任务。它基于SeleniumWebDriver,提供了一系列高级接口,使自动化任务更加直观和易于管理。Webbot库的设计理念是将复杂的网页交互抽象为...

想必大家都了解爬虫,也就是爬取网页你所需要的信息相比于网页繁多的爬虫教程,本篇主要将爬虫分为四个部分,以便你清楚,代码的功能以及使用,这四部分分别为1.获取到源代码2.根据网页中的标签特征,获取源代码你所需要的部分3.想一下如何根据页面的逻辑将一系列的...

打开页面F12检查定位关键元素在网络中刷新页面搜索关键字查看在页面中的渲染情况是不是我们想要的数据,可以看到这里列出了200首歌那么就是的在标头中确定数据来源地址及请求方法。...
通过本文的讲解,相信读者已经对Python爬虫有了较为全面的认识。爬虫技能在数据分析、自然语言处理等领域具有广泛的应用,希望读者能够动手实践,不断提高自己的技能水平。同时,请注意合法合规地进行爬虫,遵守相关法律法规。...

很多小伙伴都想知道爬虫到底违法吗,今天博主就给大家科普一下,但使用爬虫采集数据可能涉及违法风险,具体取决于采集行为是否侵犯了他人的合法权益,尤其是隐私权和个人信息权。...

用requets获取的源代码如图,想要的信息就在这里面,我们需要提取出来,因此就要用到Xpath进行解析,要先学习一下Xpath语法和lxml库的使用,可以在网上查找相关资料。鼠标右键,选择”检查“,点击”网络“,ctrl+R刷新页面,点...