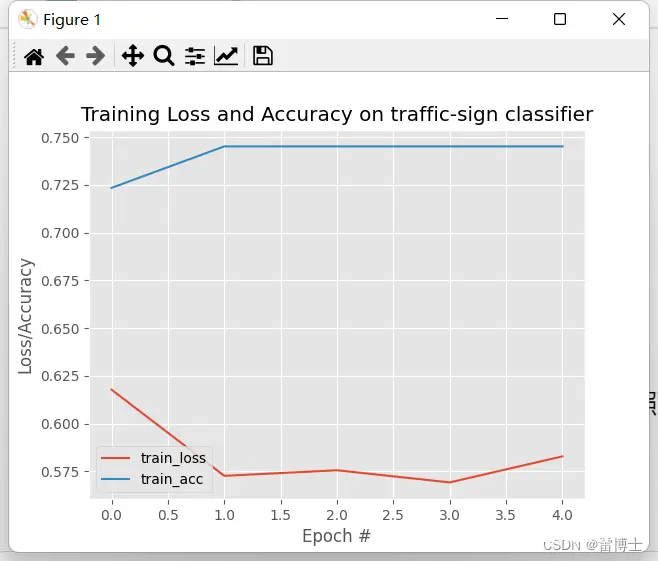
通过切片和提取,我们获取了肺癌的恶性程度评级,这些评级在1到5之间。我们将大于3的评级归类为恶性,小于3的评级归类为良性。为了让模型更好地理解这些标签,我们用1表示良性,0表示恶性,最后将标签数据转换为one-h...

在人工智能领域,大型预训练模型(如GPT-3、BERT等)已经取得了显著的成果。然而,这些模型通常需要大量的标注数据进行微调(Fine-tuning),以适应特定的任务和领域。为了降低数据标注的成本和时间,研...

近日,中国移动智慧网络人工智能开放创新平台新发布了8项AI精品数据集,为网络+AI能力研发孵化提供亿级规模核心资源。本次上新的系列数据集包含了中国移动自建的现网特色数据,以及携手新华三、北京邮电大学等产学...

1、CMLR2、LRW-10003、其他数据集4、视频收集与处理与训练5、资料Wav2Lip实现的是视频人物根据输入音频生成与语音同步的人物唇形,使得生成的视频人物口型与输入语音同步。不仅可以基于静态图像来输出与...
有用户反馈称使用微软必应搜索和谷歌搜索发现存在不少知乎乱码内容,即搜索结果里知乎内容的标题和正文内容都可能是乱码的,但抓取的正文前面一些段落内容可以正常查看。从最开始知乎屏蔽其他搜索引擎只允许百度和搜狗到必应搜索结果...

【Tensorflow+自然语言处理+LSTM】搭建智能聊天客服机器人实战(附源码、数据集和演示超详细)_聊天客服机器人实战开源...
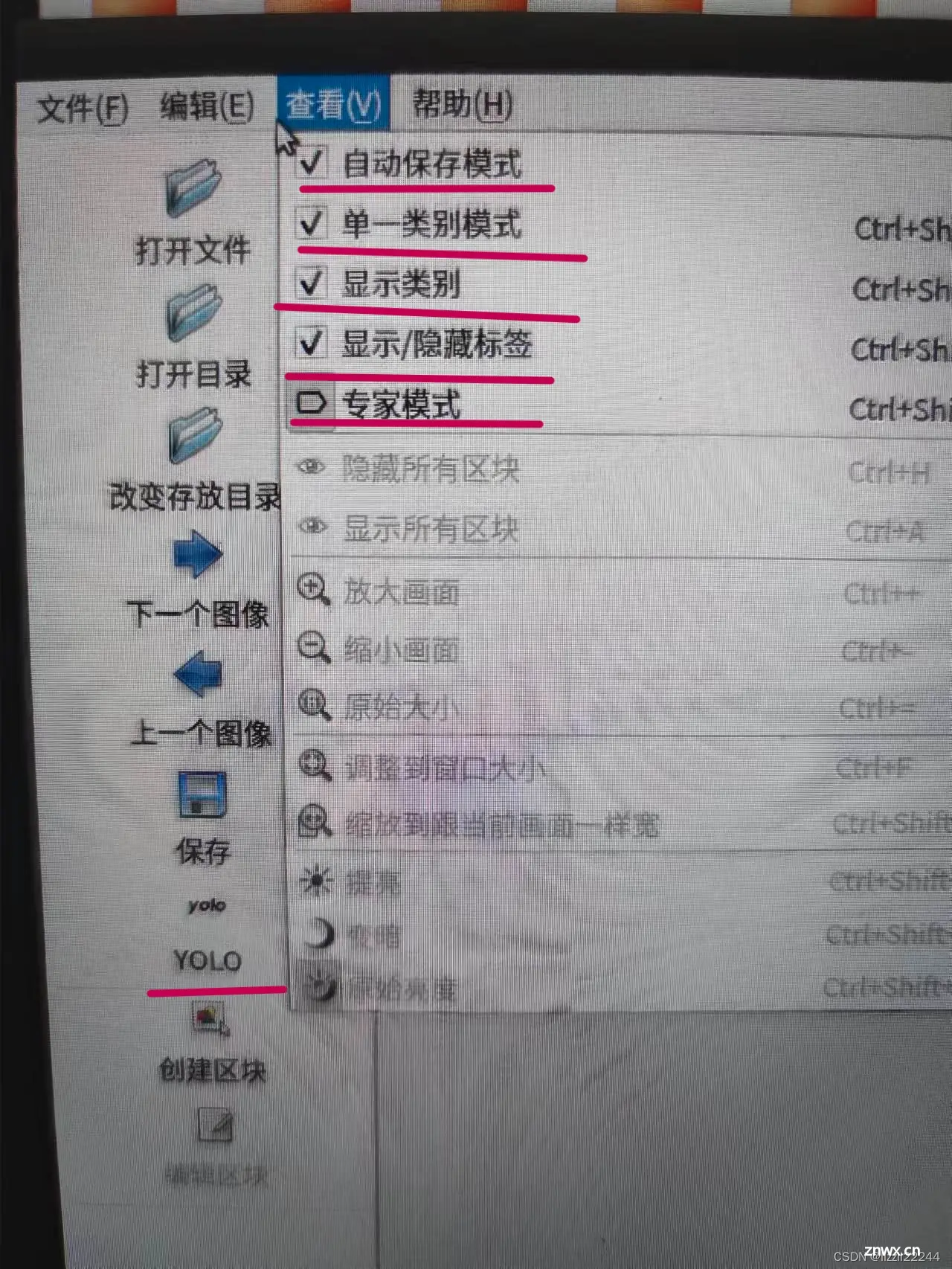
本文基于ubuntu18.04使用自己制作的数据集在YOLOv5上进行训练,记录了一个完整的过程_ubuntu18.04使用yolov5...

【Tensorflow深度学习】实现手写字体识别、预测实战(附源码和数据集超详细)_手写体识别代码...

本文将手把手教你用YoloV8训练自己的数据集并实现手势识别。_yolov8手势识别...

【Keras+计算机视觉+Tensorflow】OCR文字识别实战(附源码和数据集超详细必看)_ocr源代码...