上节研究了SparkStreamingKafka的Offset管理,同时使用Scala实现了自定义的Offset管理。本节继续研究,使用Redis对Kafka的Offset进行管理。Redis作为一个高效的内...
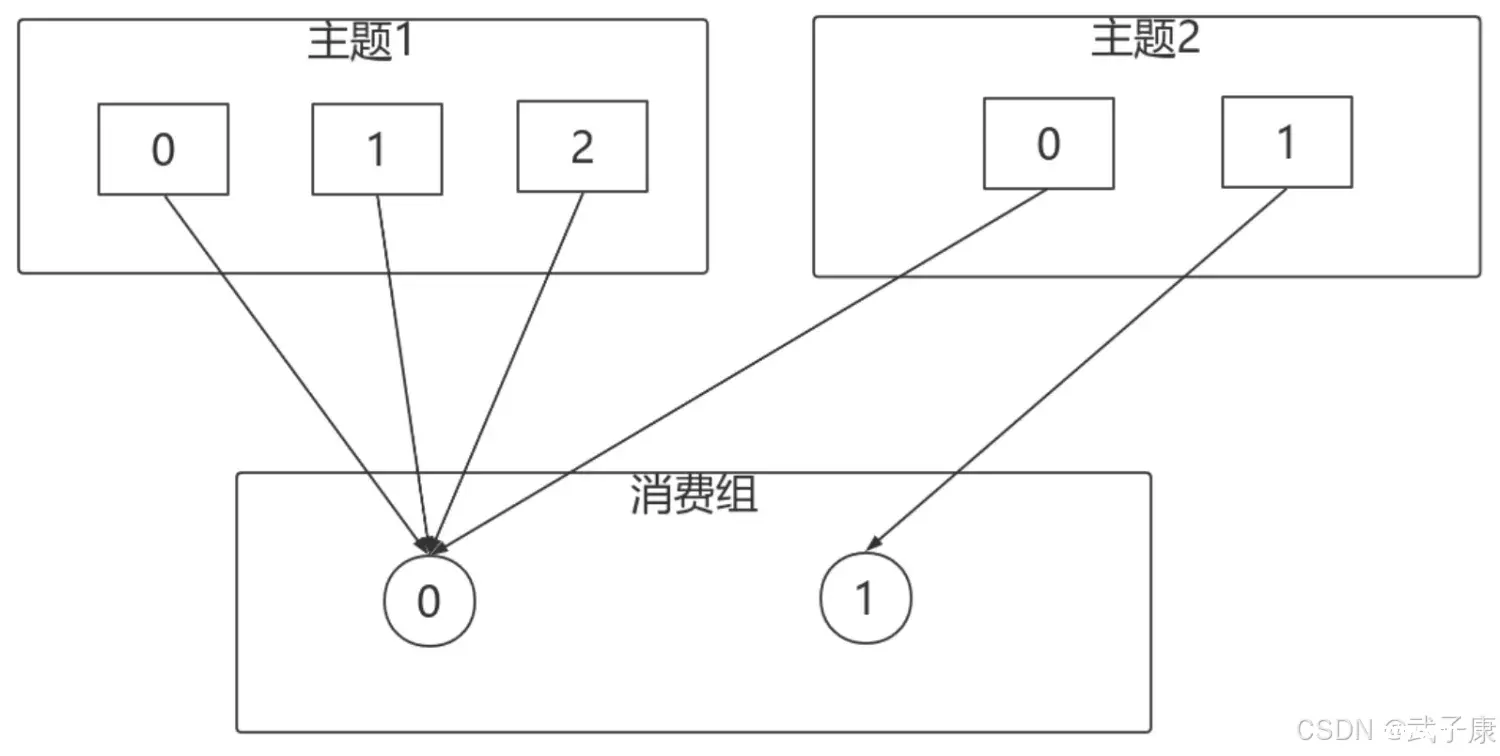
上节Kafka高级特性分区-副本数量调整,业务中遇到副本调整需求,但是无法直接修改,需要JSON+脚本的方式来进行配置。本节分区-分区策略,有Ranger、RoundRobin、Sticky等策略,最后实现自定义...
上节研究了SparkStreaming与Kafka的关系,研究了08、10版本的不同的,研究了Producer、KafkaDStream,并且附带实例代码。在DStream初始化的时候,需要指定每个分区的Off...
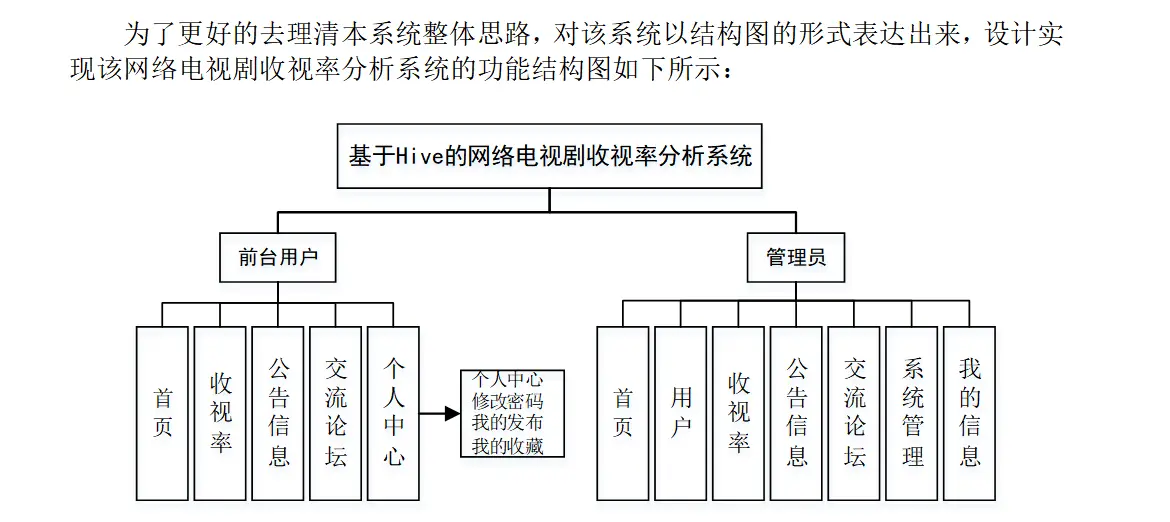
基于Hive的网络电视剧收视率分析系统是一个高效、精确的数据管理与分析平台,旨在为电视传媒机构和观众提供一个全面的收视率数据解决方案。通过利用Hive的大数据处理能力,该系统能够存储和分析海量的收视数据,从而揭示...
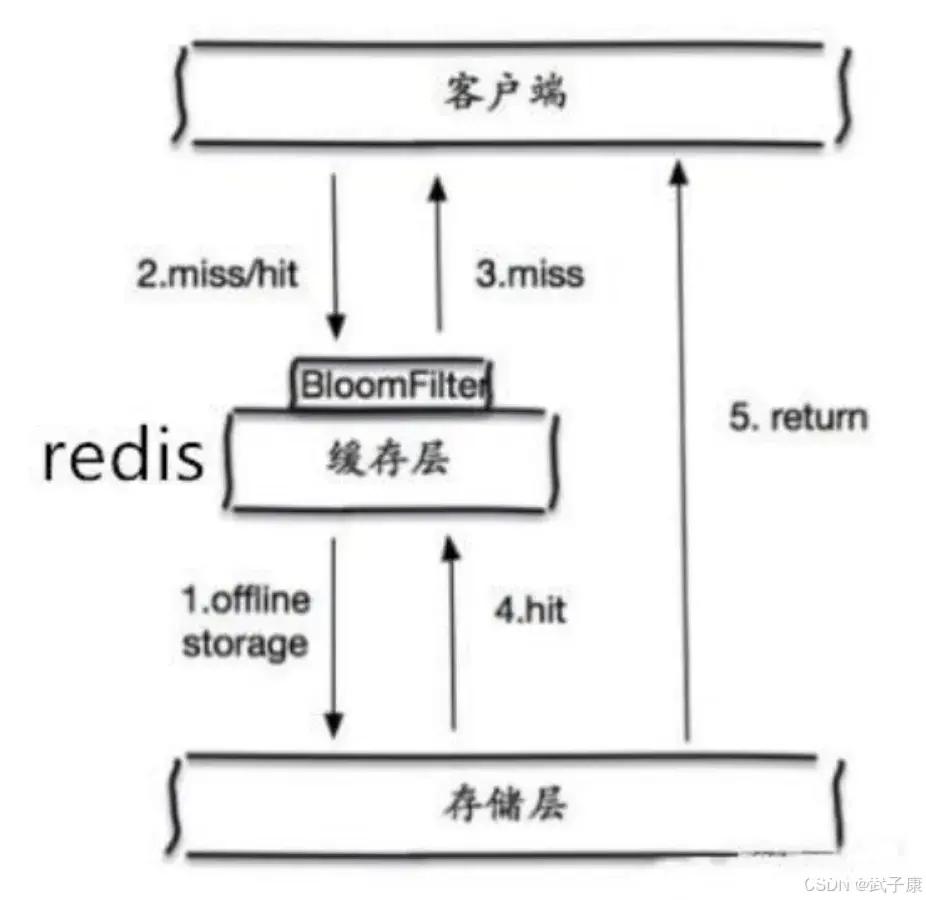
上节完成了Redis的通信协议、响应模式、数据格式、多路复用。本节我们学习缓存的问题,比如穿透、雪崩、击穿、数据不一致性、HotKey、BigKey等,并提出解决方案。对于一些设置了过期时间的key,如果这些ke...

上节研究Kafka事务配置,事务语义、事务协调器等内容,本节继续研究Kafka高级事务,事务操作Java调用,实现生产者仅发送一次消息。只要Producer生产消息,这种场景需要事务的介入消费消息和生产消息并存,比如...

Pandas是一个强大的数据分析库,广泛用于数据清洗和分析。它提供了高效的数据结构和数据操作功能,特别适用于处理小到中等规模的数据集。Pandas的核心数据结构是DataFrame,这是一种类似于数据库表的二维数...
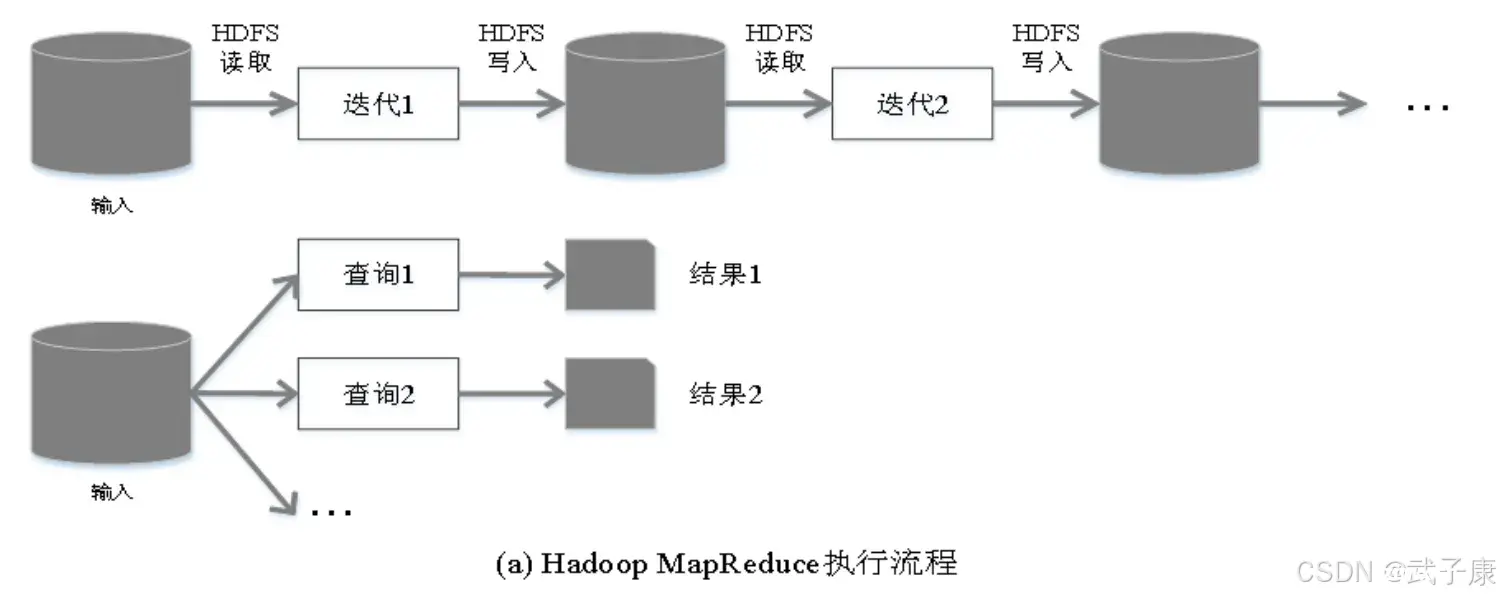
上节我们终于到了Kafka最后一个内容,集群的可视化方案,JConsole、KafkaEagle等内容,同时用JavaAPI获得监控指标。本节研究Spark的简要概述,系统架构、部署模式、与MapReduce进行对...
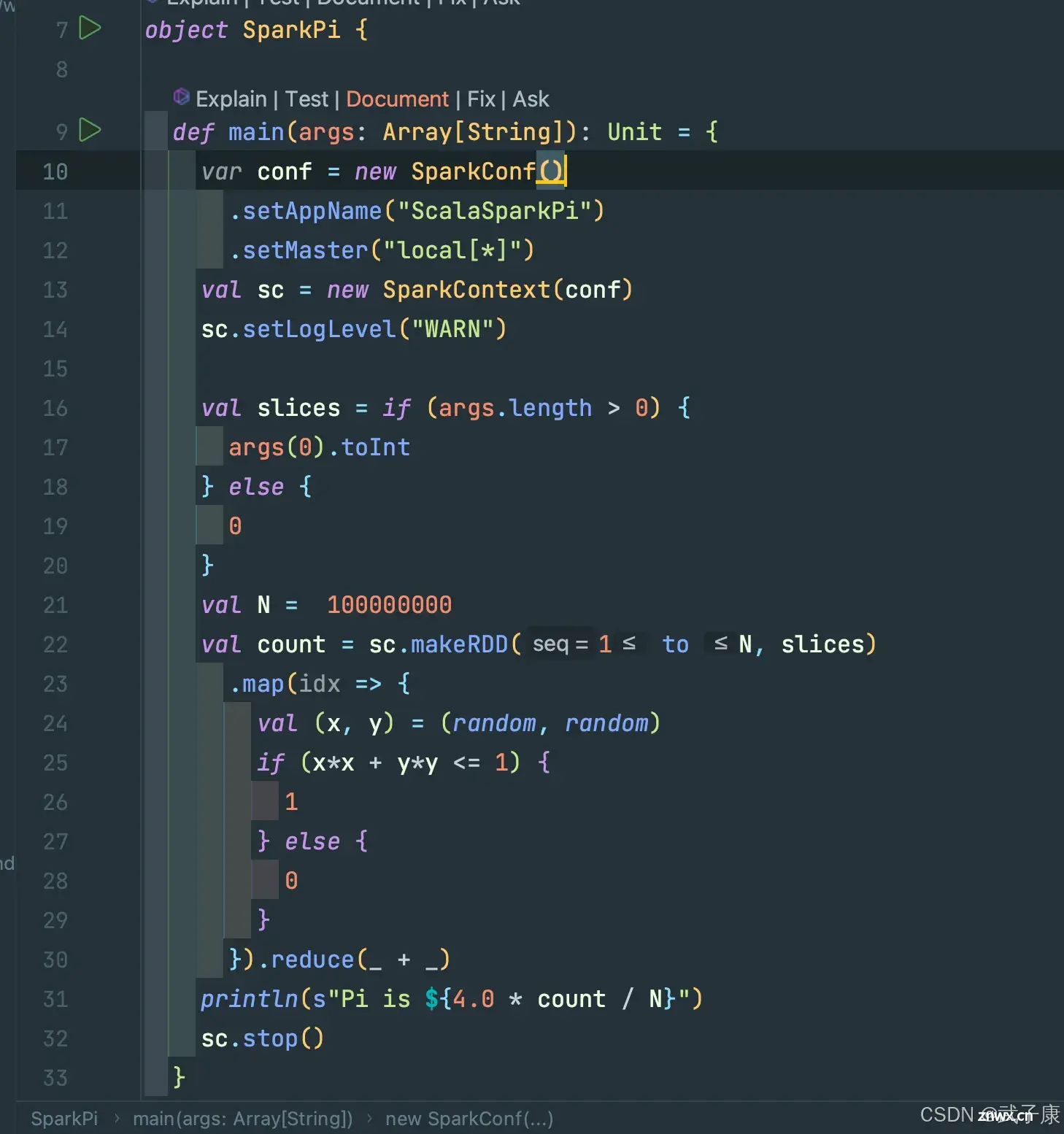
上节完成了SparkWordCount的学习,并用Scala和Java分别编写了WordCount的计算程序。本节研究Spark的案例,手写计算圆周率和寻找计算共同好友。main方法是Scala应...
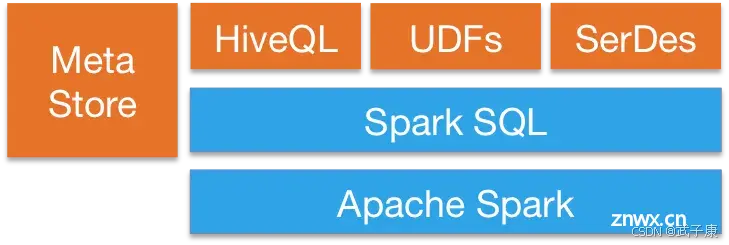
上节研究了SparkSQL的核心操作,Action详细解释+测试案例,与Transformation详细解释+测试案例。本节研究SparkSQL的数据源操作,输入与输出数据。df.write.format(“jd...