本文介绍了如何使用AmazonBedrock服务中的StableDiffusion模型在JupyterLab中生成图像的详细步骤。用户首先创建并命名notebook,粘贴代码后运行,以生成示例图...

探索Midjourney:AI图像创作的操作指南及通元软件在高校领域的实际应用。...

Vue-Label-Me:一款强大的图像标注工具,助力AI模型训练项目地址:https://gitcode.com/EmilyZhang123/vue-label-meVue-Label-Me是一个基于Vue.j...

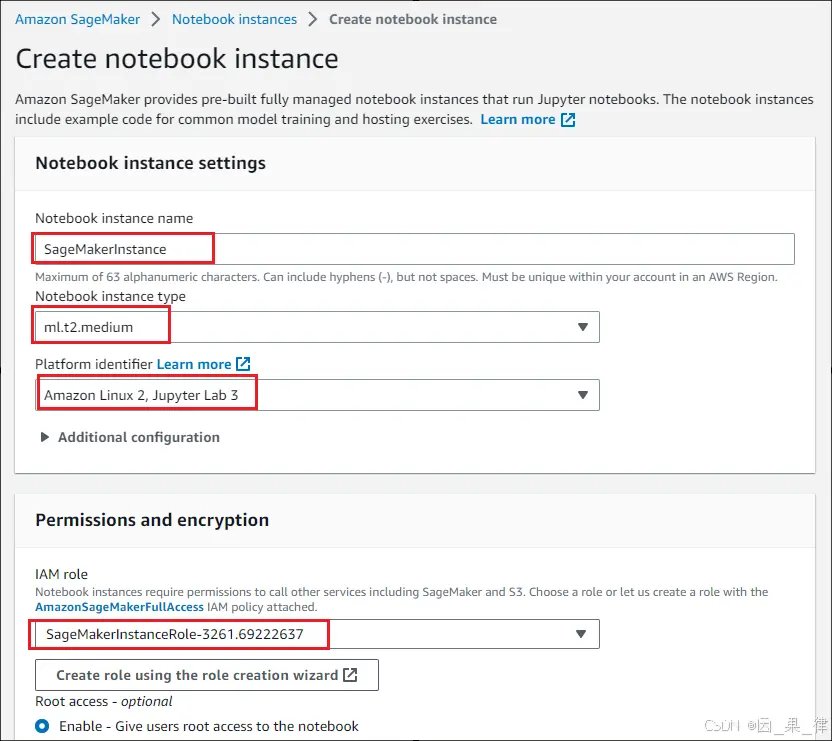
AmazonSageMaker是亚马逊云科技提供的一项全托管机器学习服务,帮助开发者和数据科学家轻松构建、训练和部署机器学习模型。SageMaker提供了全套的工具和基础设施支持,用户无需管理底层的服务器和...

在Diffusion图像生成框架中,使用LoRA(Low-RankAdaptation)微调,难点在于,需要精确控制模型参数的更新以避免破坏预训练模型的知识,同时保持生成图像的多样性和质量,这涉及到复杂的...
使用–no-build-isolation可以避免重复安装依赖、帮助调试构建问题,并确保构建过程与现有环境更好地集成。_sam2部署...

我们使用端到端神经网络Nθ来模仿专家轨迹进行训练,定义数据集为:其中,Q表示预测的轨迹点的长度,R表示RGBcamera的数量。_parkinge2e:camera-basedend-to-endparki...

小白可无副作用服用。本文主要介绍了ComfyUI中ControlNet的基本使用,通过姿态控制和局部重绘两个示例讲解了相关节点的使用。...

CoCoNet:CoupledContrastiveLearningNetworkwithMulti-levelFeatureEnsembleforMulti-modalityImageFus...
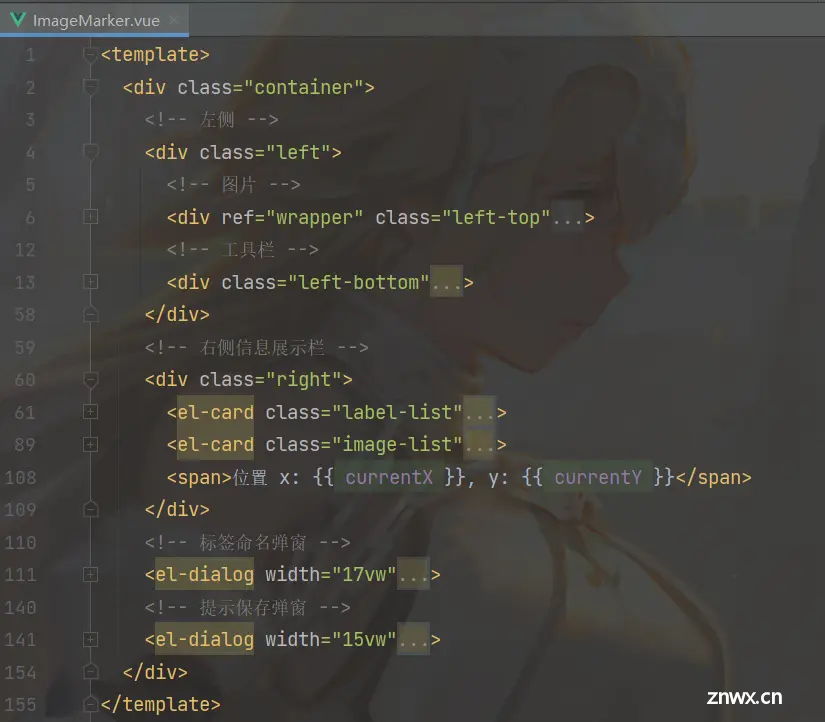
受LabelImg启发的基于web的图像标注工具,基于Vue框架哟,网友们好,年更鸽子终于想起了他的博客园密码。如标题所述,今天给大家带来的是一个基于vue2的图像标注工具。至于它诞生的契机呢,应该是我导pass掉了我的提议(让甲方使用...