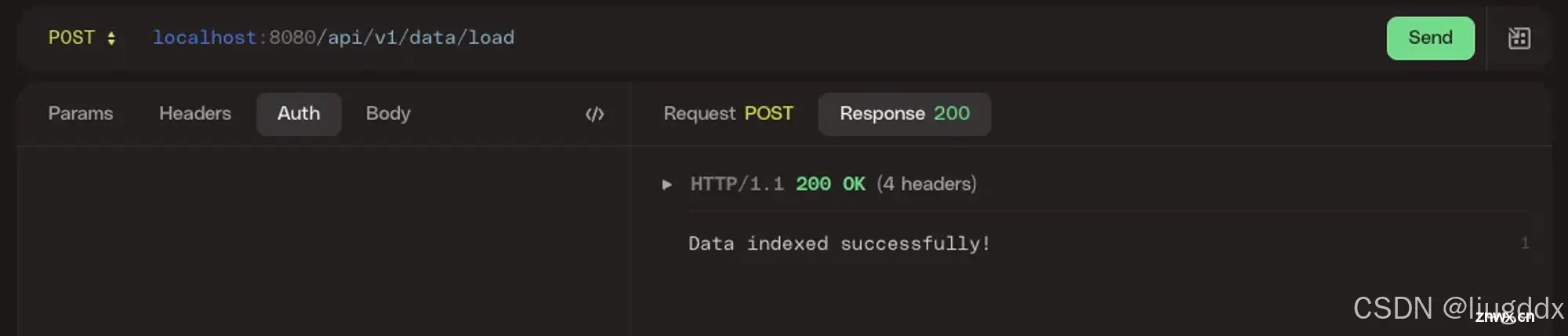
图片中所描绘的架构代表了一种处理和分析复杂文档(如调研报告、财务报告等)的复杂方法。用户首先通过一个称为/load的API上传文档,然后使用另一个称为/ask的API向系统提问。这表明这是一个交互...
ZhipuAILLM_call_llm_type通过插入特定的上下文和问题来生成提示,适用于自然语言处理模型。它确保模型生成的回答简洁明确,并在回答结束时添加template=\"\"\"使用以下上下文来回答最后...

RAGFlow0.9版本发布,正式引入了对GraphRAG的支持。_ragflowgraphrag...
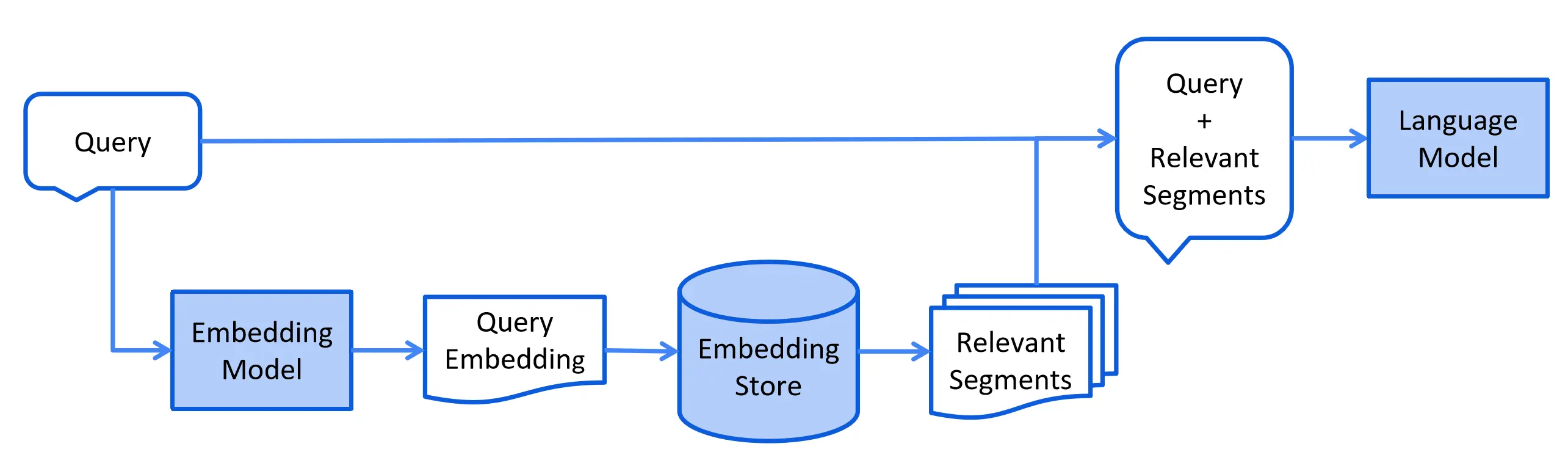
对于矢量搜索,这通常涉及清理文档,用额外的数据和元数据丰富它们,将它们分成更小的片段(也称为分块),嵌入这些片段,最后将它们存储在嵌入存储(又称为矢量数据库)中。这里需要结合官方的示例学习,Metadata算是...

第七步,社群检查,通过前面的步骤,可以从所有文本单元中抽取出所有的实体信息、关系信息、事件信息,社群检查就是利用这些信息将实体进行分类,比如周瑜和孙策属于吴国,曹操和司马懿属于魏国,刘备和关羽属于蜀国,而吴国、魏国、蜀...

vue3中使用vue-draggable实现拖拽式的快捷方式配置,一般用于后台管理系统中的首页或者工作台页面_vue3vuedraggable...

两种方式:内置。_llama-agentic-system...
今天,开始写一个新的系列《大模型RAG实战》。上个月我在2篇文章中,介绍了如何使用LlamaIndex框架,通过少量代码,实现本地可部署和运行的大模型RAG问答系统。我们要开发一个生产级的系统,还需要对LlamaI...
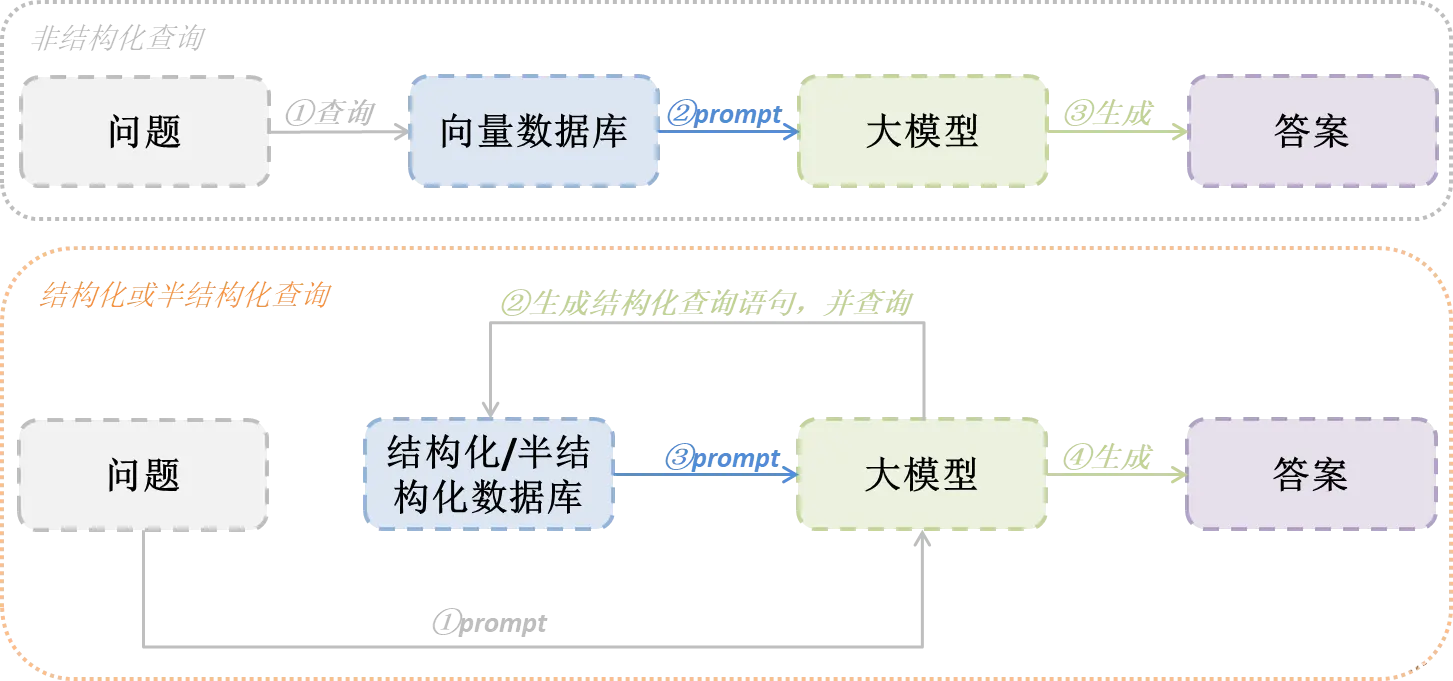
在系列3文档处理中,我们着重讲解了文档解析,但是我们说的文档都是大部分是非结构化的文档或者说它就是以一个文档的形式存储。而现实中我们很多有价值的数据可能以结构化(关系型数据库、图形数据库等)或者半结构(关系型数据库...
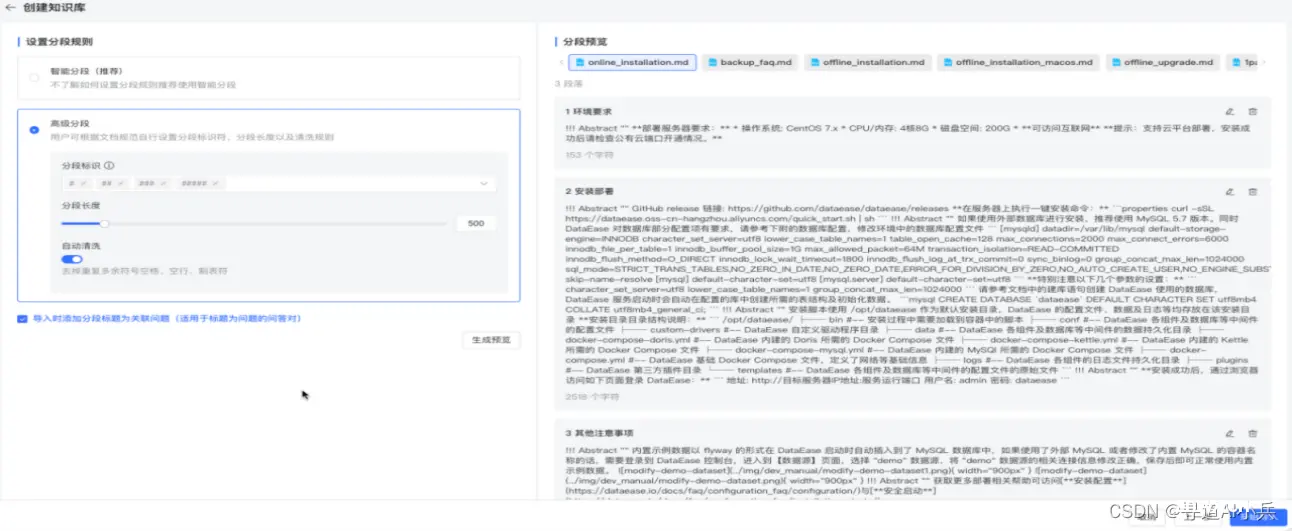
我们生活在一个信息爆炸的时代,数据的增长速度前所未有,企业每天产生的数据量呈指数级增长。这些数据中蕴含着巨大的价值,但同时也带来了前所未有的挑战:如何从海量的数据中快速提取有价值的信息,转化为企业的竞争优势?...