
本次挑战是为了应对各种类型的Deepfake攻击,而设计的一个检测模型,task1的任务就是跑通预设模型。我将学习预设模型的代码,并附上对应理解。首先先设置三个类,前两个用于监控和报告训练过程中的指标的实用工具。后者...

用1-N进行标识,即1为数据集最近一天,其中1-10为测试集数据。数据集由字段id(房屋id)、dt(日标识)、type(房屋类型)、target(实际电力消耗)组成。本场以“电力需求预测”为赛题的数据算法挑战赛。...

其中id为房屋id,dt为日标识,训练数据dt最小为11,不同id对应序列长度不同;type为房屋类型,通常而言不同类型的房屋整体消耗存在比较大的差异;target为实际电力消耗,也是我们的本次比赛的预测目标。下...
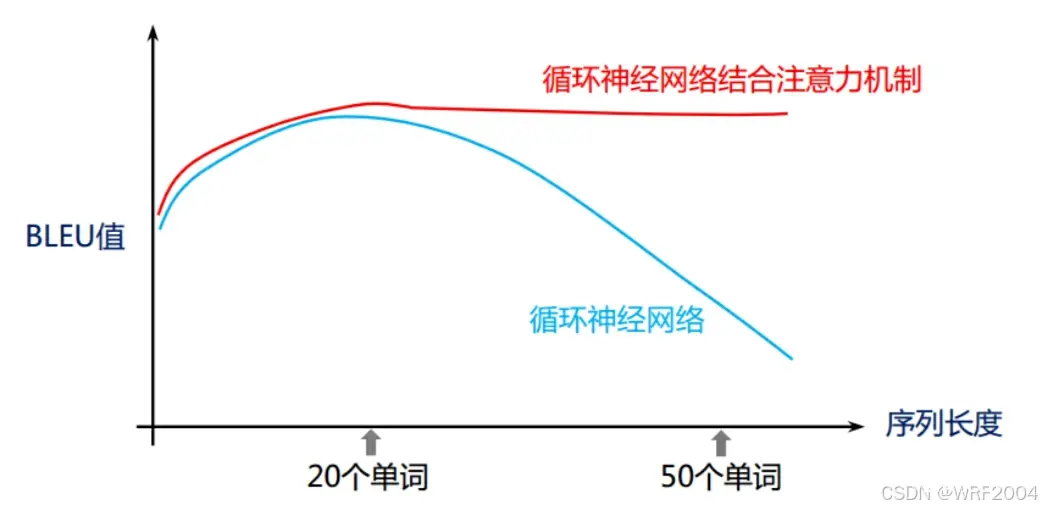
结构基本上和编码器是一致的,在基于循环神经网络的翻译模型中,解码器只比编码器多了输出层,用于输出每个目标语言位置的单词生成概率,而在基于自注意力机制的翻译模型中,除了输出层,解码器还比编码器多一个编码解码注意力子层,...
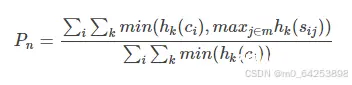
经过这次预测模型的学习与实践,我深刻体会到了机器学习,特别是LightGBM这一高效梯度提升框架在解决回归与分类问题中的强大能力。理论基础:首先,我巩固了梯度提升算法的基本原理,理解了它是如何通过迭代地构建弱学习器(...

昨天我已经用了将近25分钟的时间把baseline按照说明文档的要求跑了一遍,过程较为顺利,除了手机验证码和网络出现了一点意外,整个过程非常丝滑,runall完整跑下来用了13分钟,最后的结果在群里也算还不错,是0...

自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。第二阶段(90年代开始):基于统计的机器学习...

DatawhaleAI夏令营2024·第二期(Deepfake攻防挑战赛-图像赛道)赛题分析和任务解读...