
广东省人口流动数据分析项目旨在通过Python技术对广东省的人口流动数据进行深入分析,以揭示人口流动的规律和趋势。该项目将收集广东省各地市的人口流动数据,包括流入人口、流出人口、常住人口等指标,并利用Python...
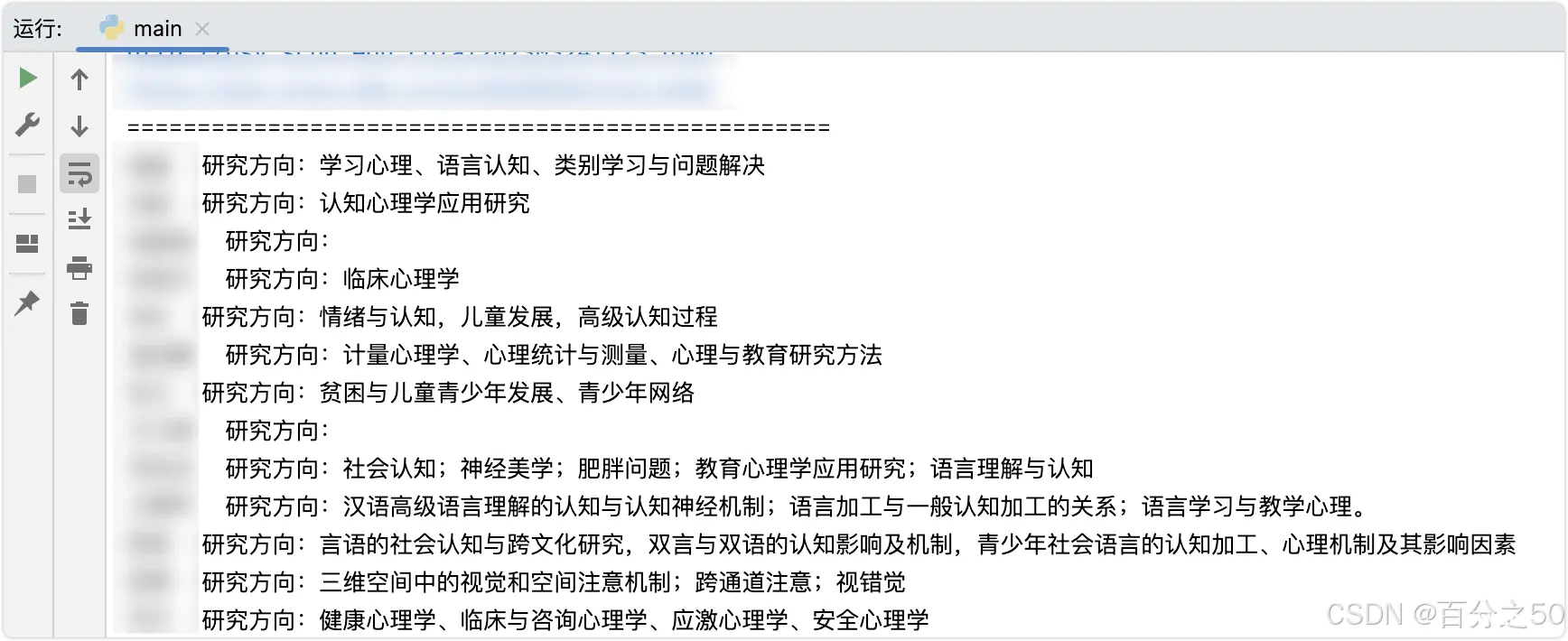
由于网站使用的都是明文,所以抓起来没什么难度,且平时访问量小,很值得用来练习。效果:抓取某个学校网站的教授名录,并获取研究方向。代码如下,解释请见注释。...
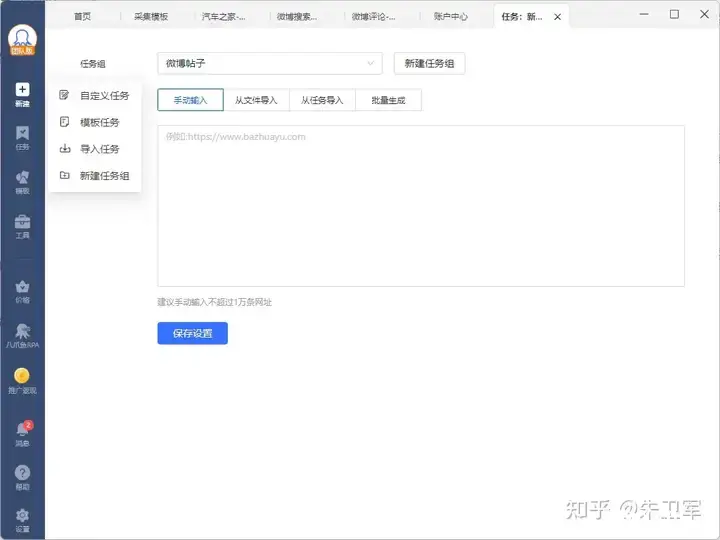
之前,我写过很多Python网络爬虫的案例,使用requests、selenium等技术采集数据,这次尝试去采集小米SU7在微博、汽车之家上的舆论数据,分析下小米SU7的口碑到底怎么样,用户关心和吐槽的点有哪些。...
【点击这里】_动态网页怎样爬取...
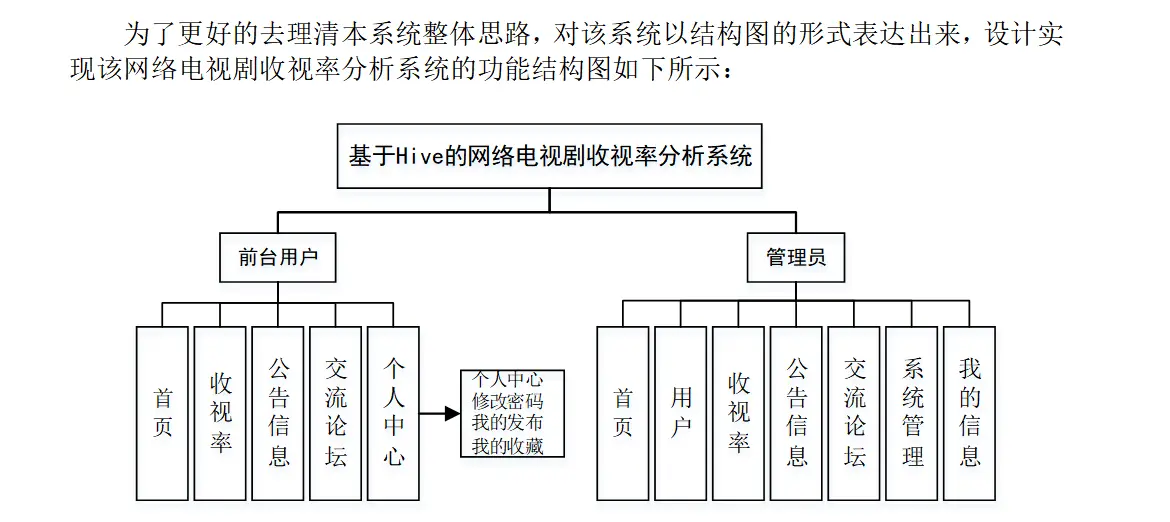
基于Hive的网络电视剧收视率分析系统是一个高效、精确的数据管理与分析平台,旨在为电视传媒机构和观众提供一个全面的收视率数据解决方案。通过利用Hive的大数据处理能力,该系统能够存储和分析海量的收视数据,从而揭示...

简介Selenium是广泛使用的模拟浏览器运行的库,它是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,并且支持大多数现代Web浏览器。函数介绍重点方法1.find_element方法是Sel...
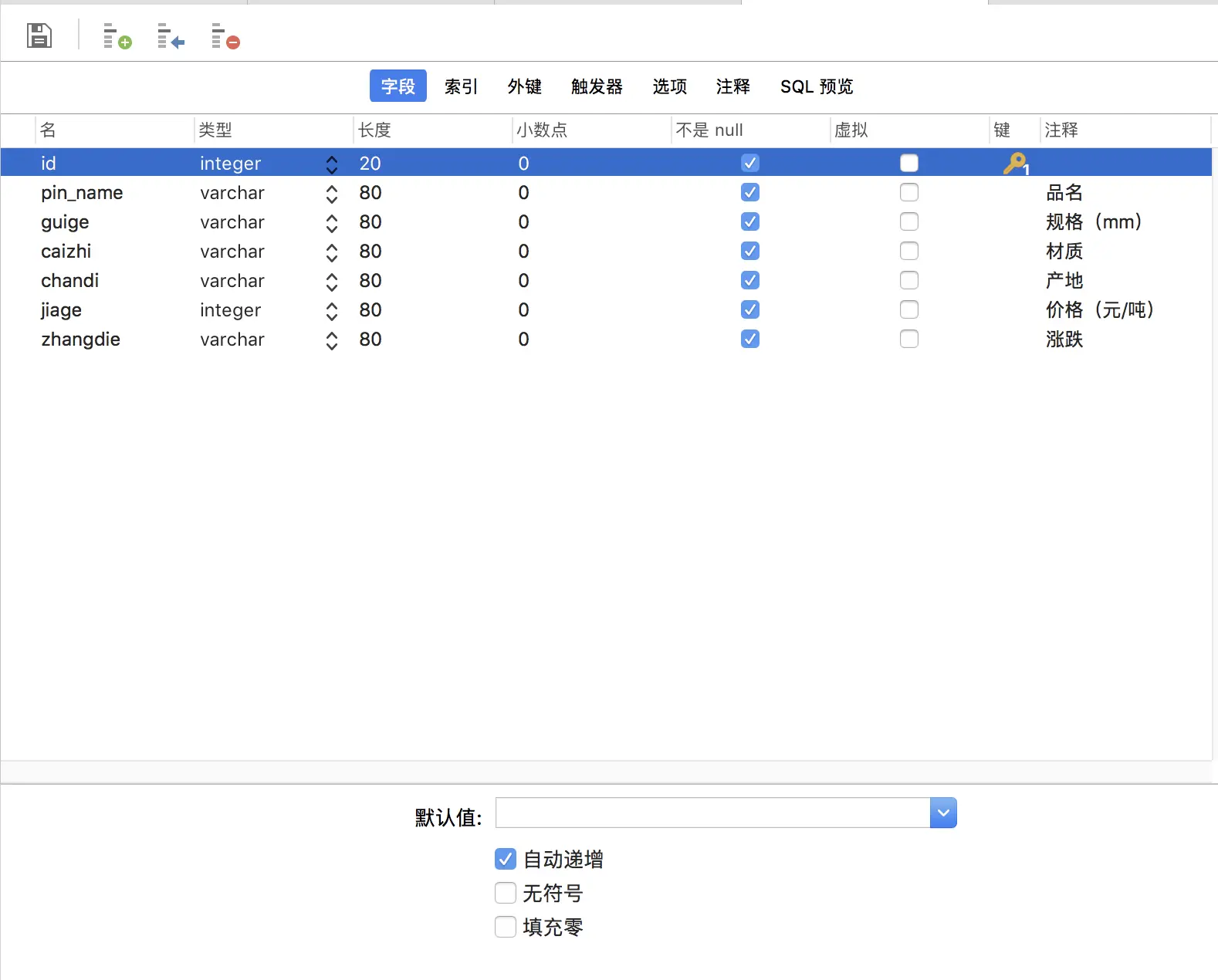
前言此篇接上一篇的内容,在其基础上爬取网站的多行表格数据,以及把数据写入到mysql数据库中目录一、定位表格查找元素二、提取数据三、写入mysql数据库四、附录一、定位表格查找元素首先打开网站,如图需要爬取多行数据的表格,利用查找元素定位,看图...
爬虫这个功能,我个人理解是什么语言都能写的,只要能正常发送HTTP请求,将响应回来的静态页面模版HTML上把我们所需要的数据提取出来就可以了,原理很简单,这个东西当然可以手动去统计收集,但是网络平台毕竟还...

是一款快速准确的信息挖掘工具。我们在使用时提前设定好自己的。_wiseflow...
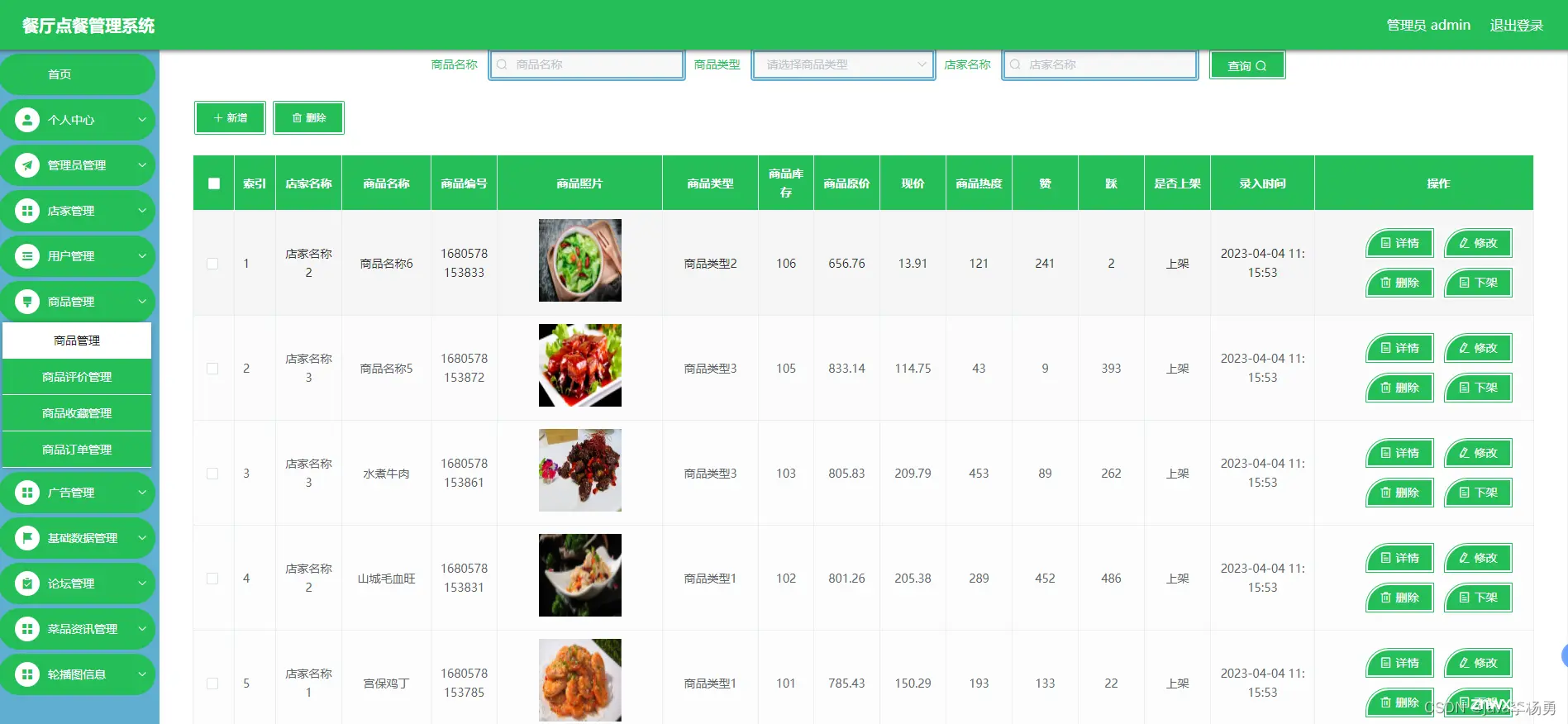
随着经济的发展和人口的增加,能源消耗也在不断增加。电力作为人们生产和生活中不可或缺的一部分,对于能源消耗的贡献也非常大。传统的电力供应模式已经无法满足人们对电力的需求,同时也带来了环境污染等问题。如何优化电力供...