
DeformableAttention(可变形注意力)首先在2020年10月初商汤研究院的《DeformableDETR:DeformableTransformersforEnd-to-EndOb...

LSKAttention是一种基于大核卷积的注意力机制,通过引入不同尺寸的卷积核来捕获图像中的多尺度特征信息。多尺度信息捕捉:通过大核卷积的感受野,能够有效捕捉目标物体的多尺度特征信息。增强全局特征:相比于小卷积核,大卷积核能够更好地捕...

安装pytorch2.2以上,启用sdpa(–opt-sdp-no-mem-attention,就可以不用安装xformers了。FlashAttention2是FlashAttention的改进...

FocusedLinearAttention是一种改进的注意力机制,旨在通过线性复杂度计算注意力权重,从而在保持高效性的同时提高模型的表现。其主要思想是通过限制注意力计算的范围,使得注意力计算更加集中和高效。在本文中,我们详细探讨了如何通过...

BiFormer(Bi-levelRoutingAttention)是一种新颖的注意力机制,它通过双层路由机制来捕捉局部和全局特征,从而提高模型的检测性能。其主要思想是在特征提取过程中,分别对局部特征和全局特征...

DAttention(DAT)是一种最新的注意力机制,它通过引入动态自适应的注意力权重计算,能够更好地捕捉特征之间的关系,从而提升模型的表示能力。DAT在各种视觉任务中表现出色,尤其是在目标检测中,可以显著提高小目标...
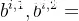
自注意力机制_自注意力机制...
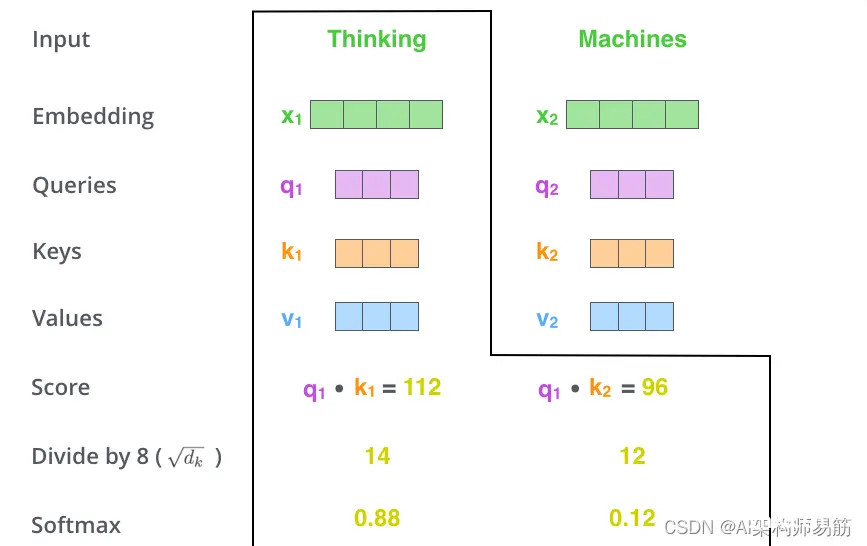
它们是用于计算和思考注意力的抽象概念。一旦你继续阅读下面的注意力是如何计算的,你就会知道几乎所有你需要知道的关于每个向量所扮演的角色。计算self-attention的第二步是计算一个分数。假设我们正在计算本...
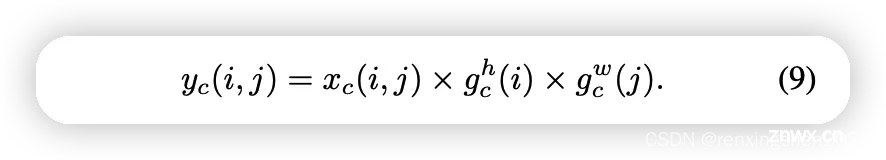
CA(Coordinateattentionforefficientmobilenetworkdesign)发表在CVPR2021,帮助轻量级网络涨点、即插即用。CA不仅考虑到空间和通道之间的关系,...
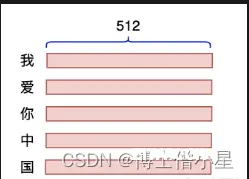
虽然之前写过Attention的文章,但现在回头看之前写的一些文章,感觉都好啰嗦,正好下一篇要写的StableDiffusion中有cross-attention,索性就再单拎出来简单说一下Atte...