
多模态AI结合文本、图像、音频等多种数据类型,通过特征级、模型级、决策级融合,提升系统智能化水平。在智能助手、医疗诊断、自动驾驶等领域,多模态AI应用广泛。构建过程中面临数据对齐、模态不一致性等挑战。未来的发展将...
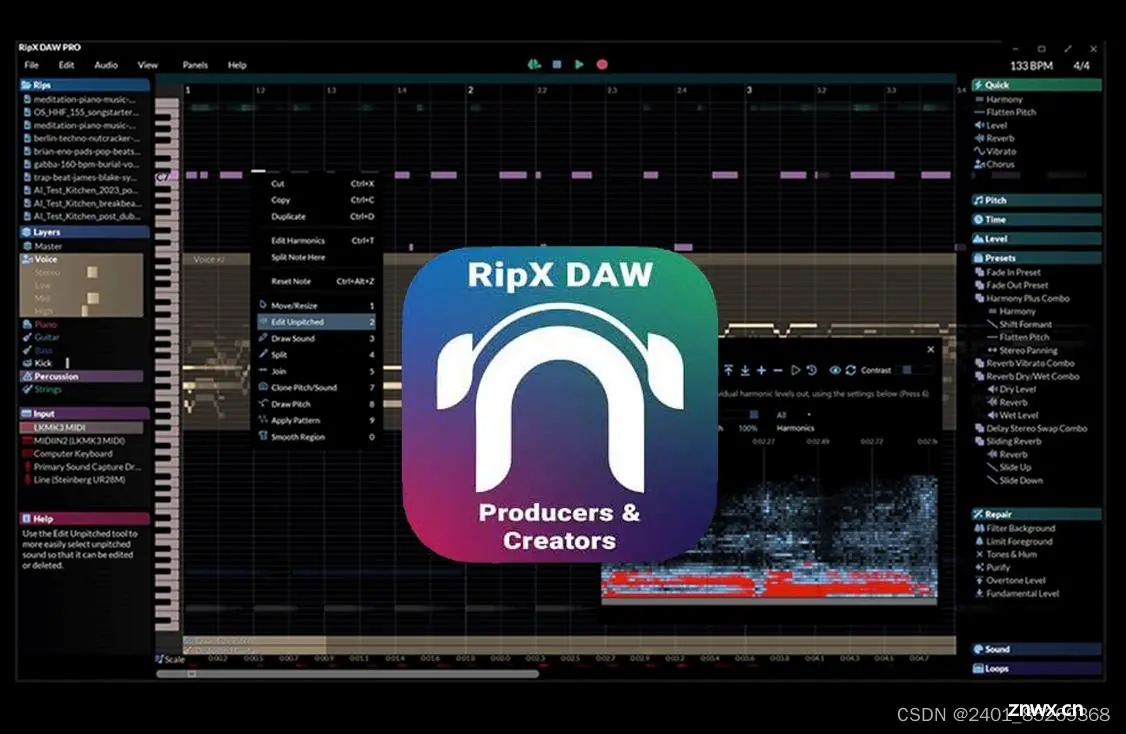
RipXDAWPro是一款功能强大、创新前沿、易于使用的数字音频工作站,它可以让您对音乐进行全方位的控制和创作,无论您是专业的音乐制作人,还是业余的音乐爱好者。RipXDAW会自动分析素材的速度甚至是和弦、音符...
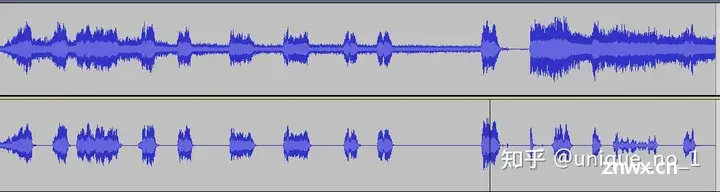
今天我们主要介绍下AI降噪比较,AI降噪目前效果比较好的就属RNNoise算法模型了,我在实际应用过程中,对比过webrtc的降噪算法,在某些背景噪音比较大的情况下,webrtc的降噪算法效果就不是很好了,但是R...
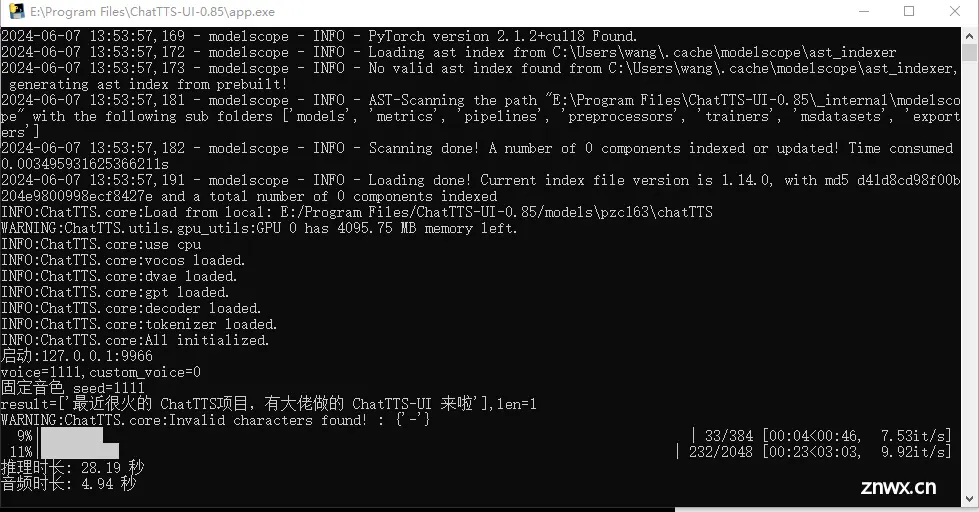
本篇文章主要介绍如何快速地在Windows系统电脑中本地部署ChatTTS开源文本转语音项目,并且我们还可以结合Cpolar内网穿透工具创建公网地址,随时随地远程访问本地搭建的ChatTTSAI语音合成模型。最...

音乐制作和混音:对于音乐制作人来说,ResembleEnhance可以帮助去除录制音乐中的环境噪声,如背景风声、噪音等,让音乐听起来更加纯净。电影和游戏音频后期处理:在电影和游戏的音频后期处理中,Resemble...
![[2024.5]小白进 pixelbook2017刷Windows11音频,键盘背光,全驱动+国内网络详细图文教程](/uploads/2024/08/07/1723000024043006865.webp)
chromebook原生bios不能从U盘启动,所以得给chromebook刷入支持从U盘启动的bios,但是谷歌为防止用户刷机安装第三方系统,chromebook主板都有写保护锁WP,来保护bios...
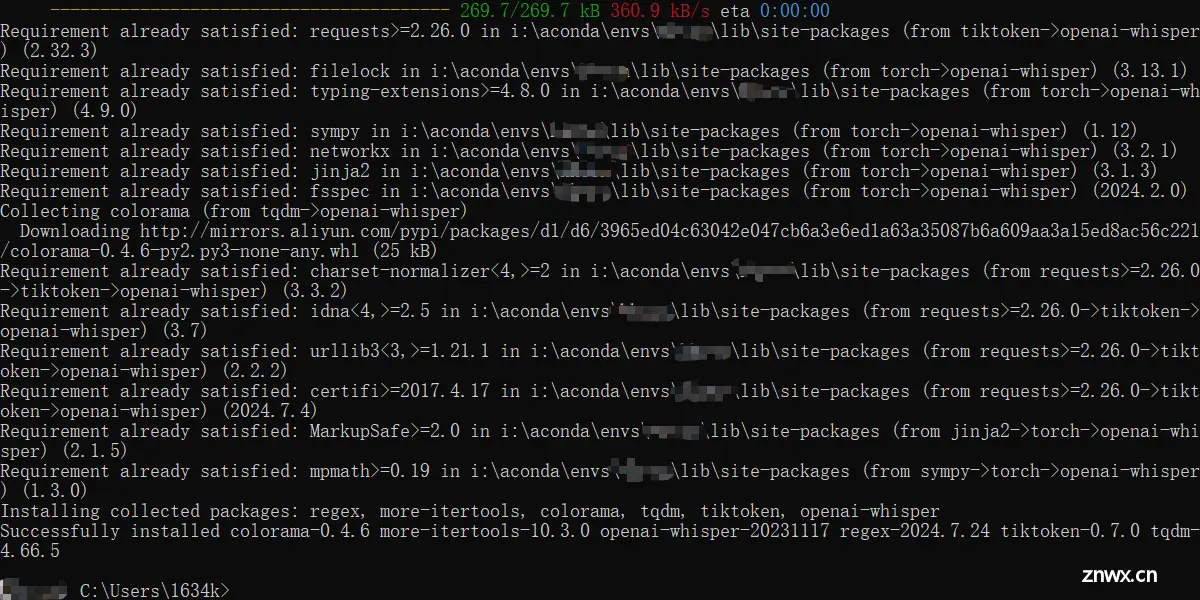
提取PPG特征之——whisper库的使用(2.1)1安装对应的包方法一(自用):直接pip即可:pipinstallopenai-whisper成功后如下图所示方法二:当时用了他这个方法环境直接崩了,已老实condainstall-...

此外,RodinHD通过计算更细粒度的层次表示来优化肖像图像的指导效果,这些表示捕捉了丰富的二维纹理信息,并通过交叉注意力在多个层次上将其注入3D扩散模型中。该模型在经过优化噪声调度的46,000个虚拟头像上训练...
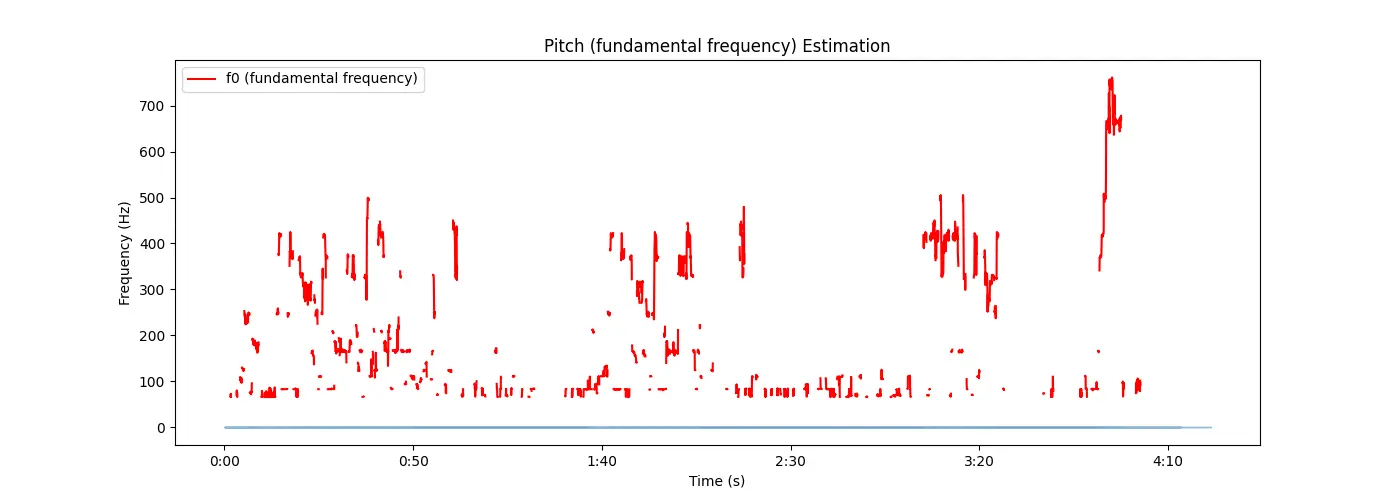
python音频处理音高提取f0提取pitch基频特征torchaudioresample重采样...

以下是一个简单的案例,展示如何在后端提供音频文件数据,并在前端通过JavaScript获取并播放该音频。_后端向前端传音频...