AI翻唱,AI模型训练_rvc模型训练...
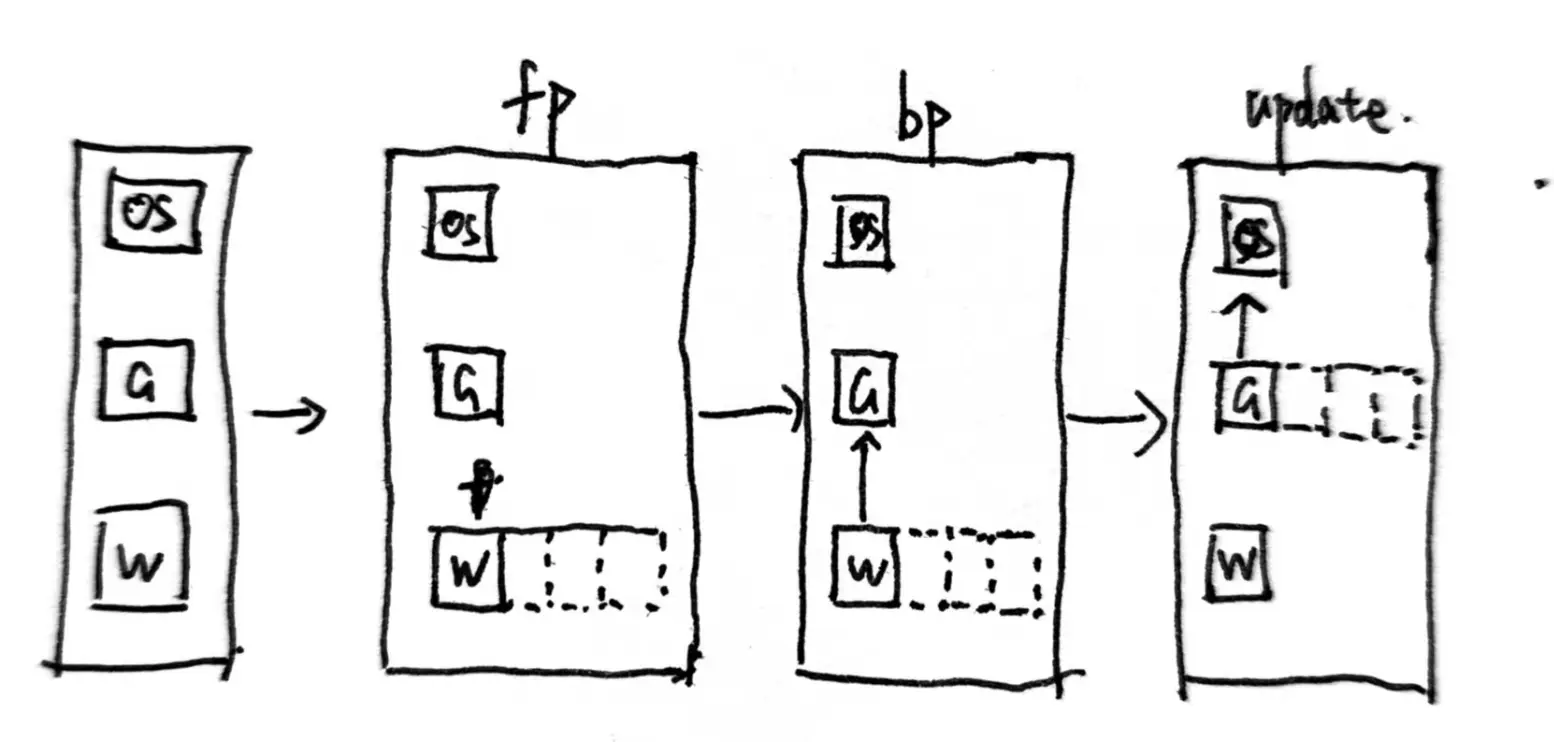
前置知识混合精度训练在参数存储时采取fp32,开始进行fp/bp时转成fp16运算,拿到fp16梯度后再转回fp32更新参数.ZeRO对显存占用的估算:模型状态:Weights(fp16)、grad(fp16)和MasterWeights(f...

尽管报道中没有提供详细的对比数据,如英伟达GPU的具体型号(A100、H100或H200),以及训练负载是否一致(MT-infini-3B与Llama3-3B等模型的训练可能差异较大),但摩尔线程MTTS4000集...

在自然语言处理(NLP)领域,预训练模型的应用已经越来越广泛。预训练模型通过大规模的无监督学习,能够捕捉到丰富的语言知识和上下文信息。然而,由于预训练模型通常需要大量的计算资源和时间进行训练,因此在实际使用时,我...

为了解决这一问题,我们提出了V-Express方法,通过一系列渐进的Dropout操作平衡不同的控制信号,使得较弱信号也能有效控制生成过程,从而兼顾姿态、输入图像和音频的生成能力。Qwen2系列包含五种规模的预训练和...

切分方式前置知识矩阵乘法求导\[Y=f(AB)=f(C)\]\[\frac{\partialY}{\partialA}=\frac{\partialY}{\partialC}\cdotB^{T}\]\[\frac{\partialY...
随着人工智能的迅猛发展,自然语言处理(NLP)在近年来取得了显著的进展。大型语言模型(LLMs)在多种NLP任务中展现了卓越的性能,这得益于它们在大规模文本数据集上进行的预训练和随后的微调过程。这些模型不仅能够理...
本文详细介绍了如何在Linux系统上部署StableDiffusionWebUI,首先介绍了StableDiffusion和LoRA模型的基本概念,然后完成WebUI的下载、安装和配置。在部署过程中,作者分享了...
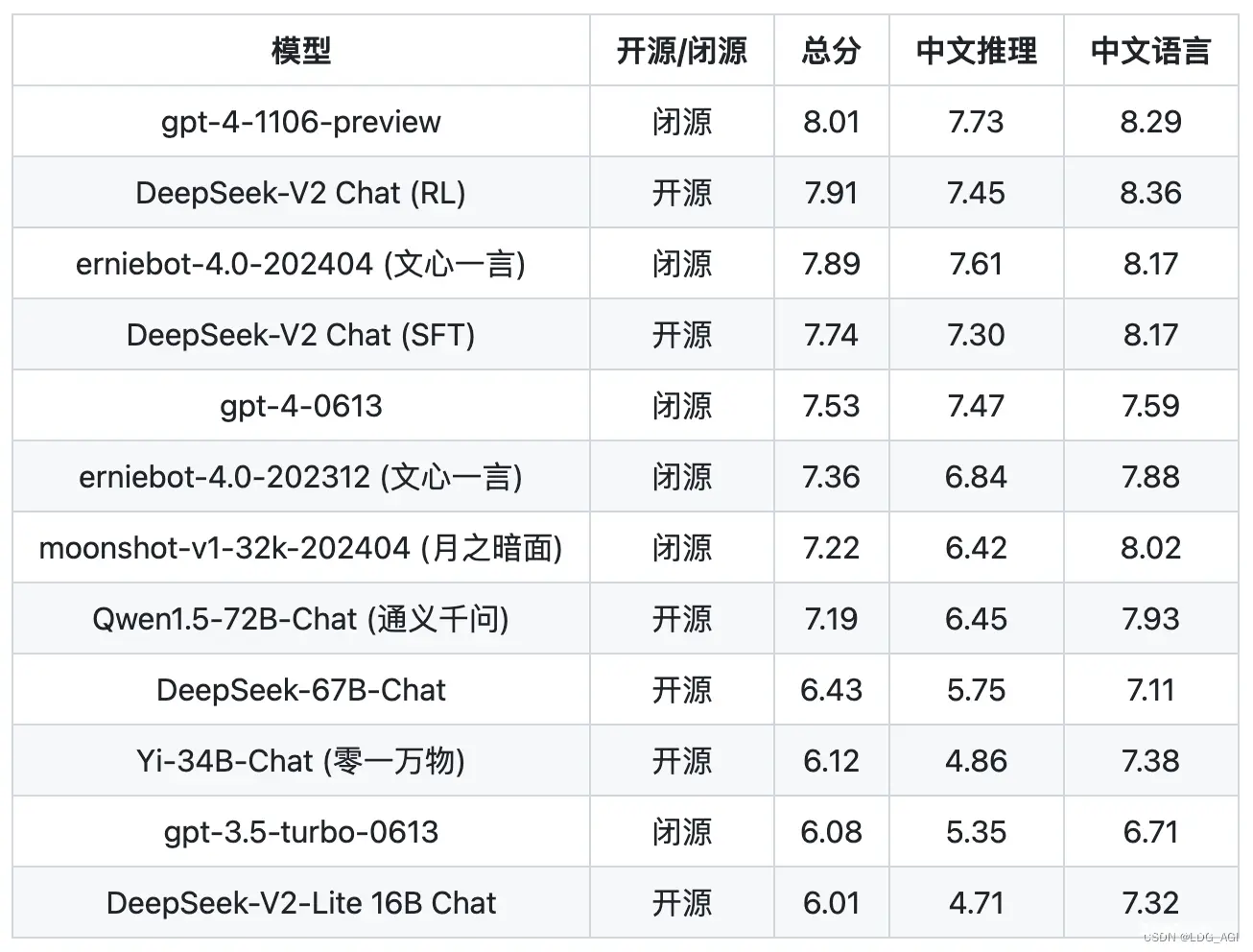
本文首先针对deepseek-v2-chat这个大模型价格屠夫的模型特点和技术架构进行介绍,之后以LLaMA-factory为训练和推理框架,进行SFT微调训练和Infer推理测试。deepseek-v2-cha...
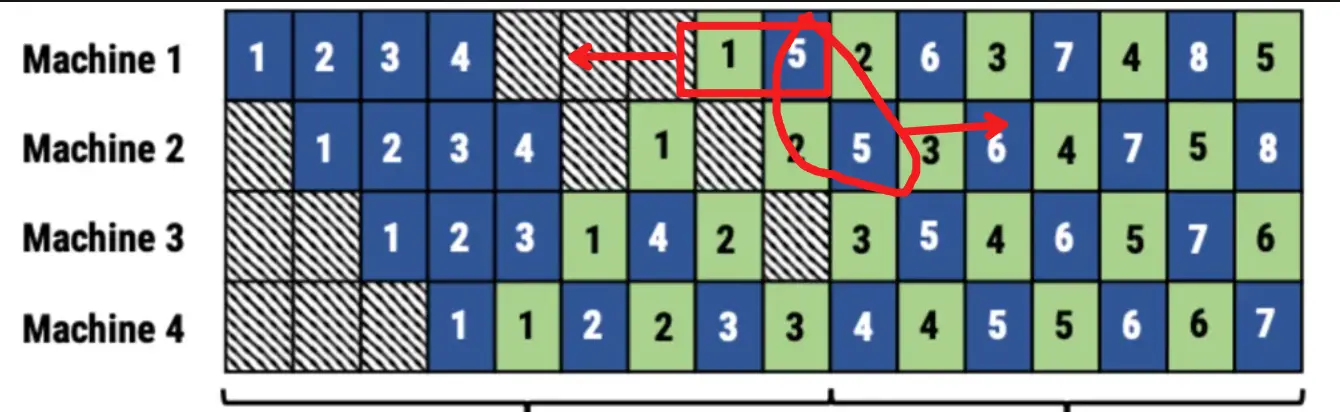
并行训练-流水线简述并行训练主要有三种策略:数据并行训练加速比最高,但要求每个设备上都备份一份模型,显存占用比较高,但缺点是通信量大。张量并行,通信量比较高,适合在机器内做模型并行。流水线并行,训练设备容易出现空闲状态,加速效率没有DP高;但能减少通...