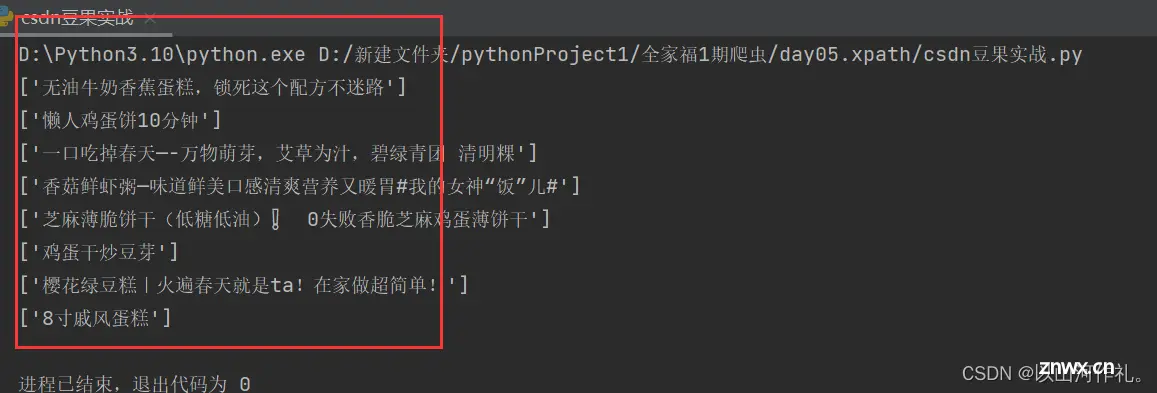
Xpath简介XPath是一种用于在XML文档中定位节点的语言,它可以用于从XML文档中提取数据,以及在XML文档中进行搜索和过滤操作。它是W3C标准的一部分,被广泛应用于XML文档的处理和分析。XPath使...
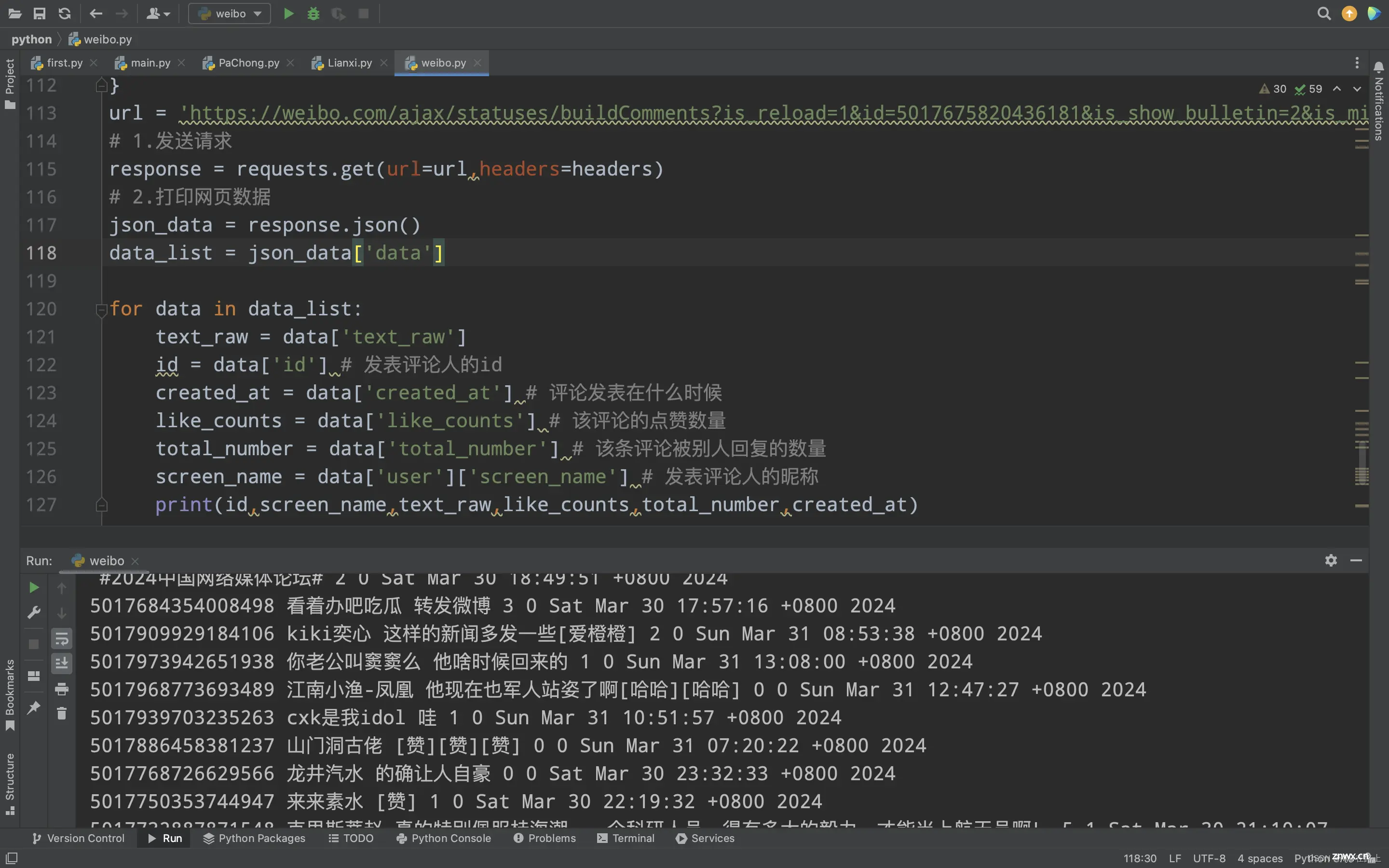
。_微博评论爬取...
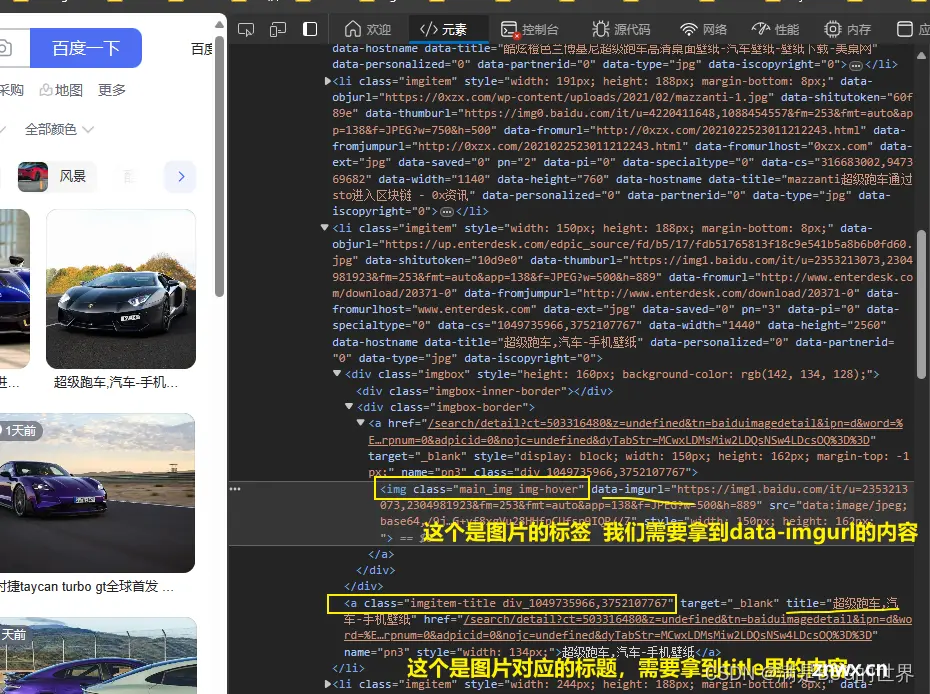
Pyhon使用selenium库的webdriver实现爬取百度图片,爬取其他网站的方式基本差不多,window上可以直接粘贴代码使用_爬取百度搜索的图片selenium...
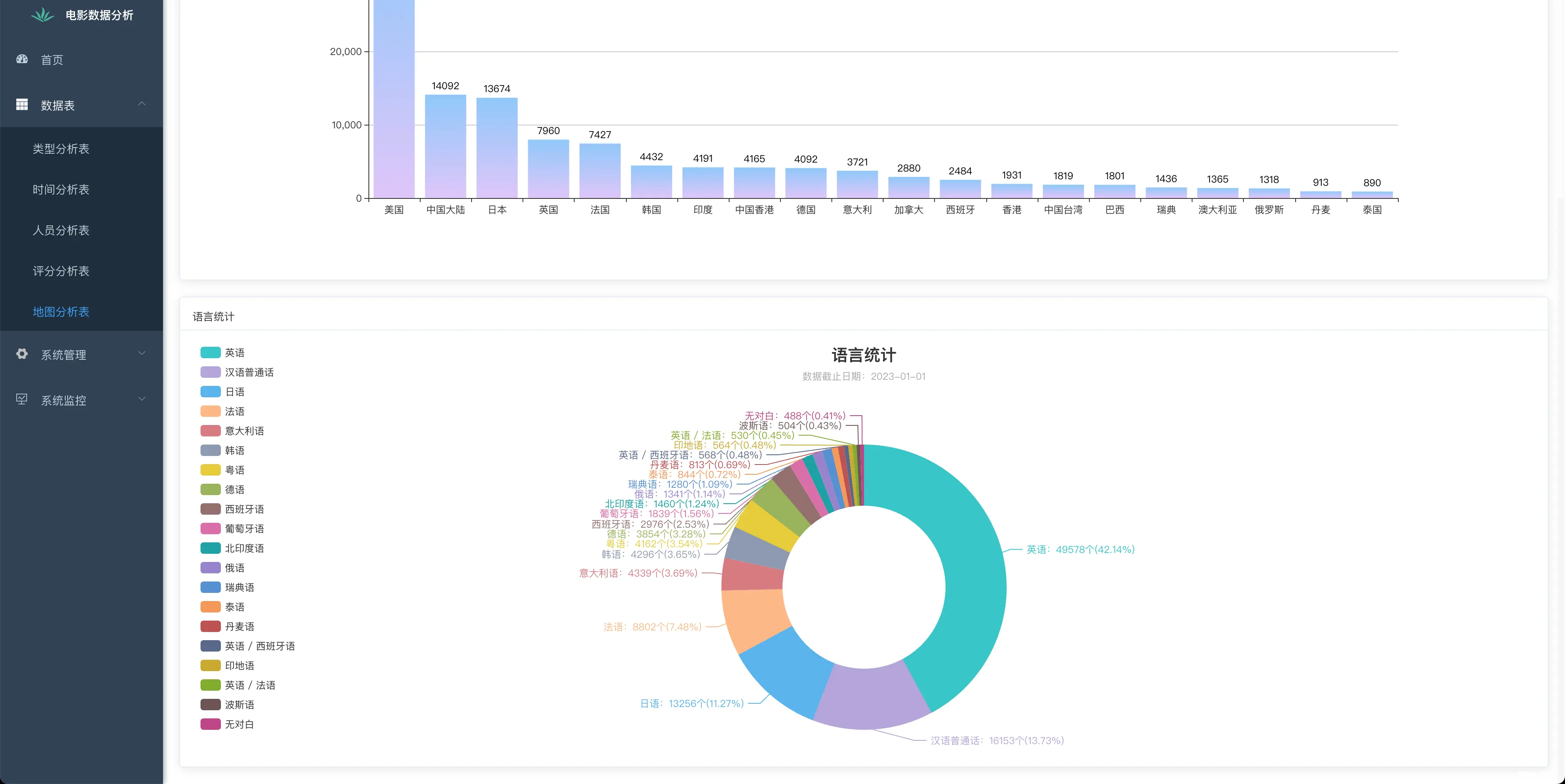
在电影行业,通过爬取电影网站的数据,并结合机器学习算法进行分析,可以实现多维度的电影信息可视化,为观众、制片方和发行方提供有价值的参考信息。本文旨在综述基于网络爬虫的电影数据可视化分析系统的设计与实现过程,重点介...

在互联网时代,数据已经成为了重要的资源。Web爬虫作为一种自动化获取数据的工具,在数据分析、市场调研、价格监控等领域发挥着越来越重要的作用。简单来说,Web爬虫是一种程序,它模拟人类在浏览器中的行为,自动访问...
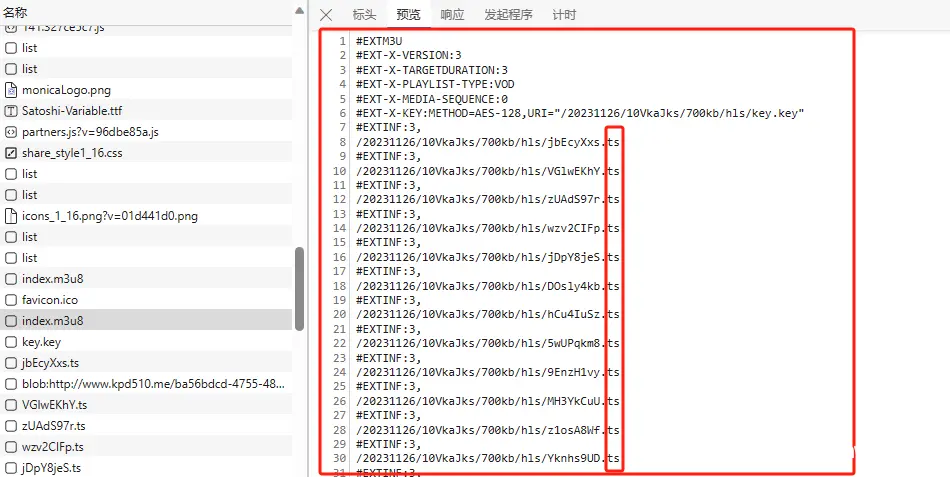
别在图书馆测试这段代码!_m3u8解密秘钥...

原创Aitrainee|公众号:AI进修生:AI算法工程师/Prompt工程师/ROS机器人开发者|分享AI动态与算法应用资讯,提升技术效率。🌟ScrapeGraphAI是一个网络抓取Pyt...